
GitHub Copilotのような生成系AIコーディングツールの急速な進歩が、ソフトウェア開発現場に打ち寄せる次の波を加速させています。この記事では今、皆さんが知っておくべきことをご紹介します。
コンピューターを計算のためだけに使っていた時代、エンジニアのDouglas Engelbartは、コンピューターを「人類の最も複雑な問題を解決するコラボレーションツール」として捉え直し、「すべてのデモの母」を実施しました。デモの冒頭で、彼は聴衆に「自分の行動に即座に反応するコンピューターがあれば、どれだけの価値を得られるだろうか」と問いかけました。
それと同じ質問を、生成系AIモデルにも投げかけることができます。新しいアイデアのブレインストーミングを行ったり、大きな構想を小さなタスクに分けたり、問題に対する新たな解決策を提案してくれる、反応性に優れた生成系AIコーディングツールがあれば、どれだけ創造性と生産性が高まるのでしょうか。
これは仮定の質問ではありません。新しい生成系AIコーディングツールは自然言語プロンプトや既存のコードに対応してコードを提案したり、関数全体を提供でき、こうしたツールを活用したAI支援エンジニアリングワークフローが急速に出現しています。また、こうしたツールそのものやツールの活用によって開発者が達成できることも、急速に変化しています。そのため、今、何が起きていて、現在のソフトウェア開発方法と今後の変化が意味するものを理解することが、すべての開発者にとって重要な時を迎えているのです。
この記事では、ソフトウェア開発における生成系AIの現状を、以下の点について掘り下げながらお伝えします。
- <生成系AIが開発者ワークフローにもたらす独自の価値
- 生成系AIコーディングツールの設計と構築
- 開発者がTransformerと大規模言語モデル(LLM)にこだわるべき理由
- 開発者による生成系AIコーディングツールの活用
生成系AIが開発者ワークフローにもたらす独自の価値
AIと自動化は、以前から開発者のワークフローの一部となっています。機械学習(ML)を使用したセキュリティチェックからCI/CDパイプラインまで、GitHub上のCodeQLなど様々な自動化ツールやAIツールが活用されています。
以下のすべてのカテゴリーには重複する部分がありますが、生成系AIが自動化や他のAIコーディングツールとは異なる点をご紹介します。
| A自動化:🛤 実行すべき内容とそれを毎回確実に実行する方法がわかっている。 |
ルールベースのロジック: 🔎 最終的な目標はわかっているが、それを達成する方法が複数存在する。 |
機械学習(ML): 🧠 最終的な目標はわかっているが、それを達成する方法が指数関数的に増えていく。 |
生成系AI:🌐 コーディングしたい大きな目標があり、それを自由に実現する。 |
| リポジトリにプッシュされた新しいコードがフォーマット仕様に従っていることを確認してから、メインブランチにマージする場合、手動でコードを検証する代わりに、GitHub ActionsなどのCI/CDツールを使って、選択したイベント(コミットやPull Requestなど)の発生時に自動ワークフローを起動します。 | SQLインジェクションパターンの一部はわかっているものの、コードを手動でスキャンするには時間がかかる場合、CodeQLなどのツールを使えば、ルール化されたシステムを使用してコードの分類とパターンの検出を行うことで、手動作業の必要がなくなります。 | Yセキュリティの脆弱性を常に把握しておきたくても、SQLインジェクションのリストは増え続けています。CodeQLなど、MLモデルを使用するコーディングツールは、既知のインジェクションを検出するだけでなく、そのインジェクションに類似した初めて見るパターンもデータから検出するようトレーニングされています。これにより、確認された脆弱性の認識率を高め、新たな脆弱性を予測できるようになります。 | 生成系AIコーディングツールは、MLを活用して新たな答えを生成し、コードシーケンスを予測します。GitHub Copilotなどのツールは、IDEから切り替えてボイラープレートコードを調べる回数を減らし、コーディングソリューションのブレインストーミングを支援します。生成系AIは、開発者の役割を暗記型の記述から戦略的な意思決定へとシフトさせ、より高度かつ抽象的なレベルでコードを検討できるよう支援します。そのため、「何」を開発するかに集中し、「どのように」開発するかについて悩む時間を減らすことができます。 |
生成系AIコーディングツールの設計と構築
生成系AIコーディングツールを開発するには、ディープラーニングによって、様々なプログラミング言語の大量のコードでAIモデルをトレーニングする必要があります(ディープラーニングとは、限られたガイダンスでパターンを認識し、結合させ、推論を行うことで、私たちと同じようにデータを処理するようコンピューターをトレーニングする手法です)。
これらのAIモデルでは、人間がパターンを学習する方法を模倣するために、広大なノードネットワークを使用します。入力データを処理し、重みを算出するノードネットワークは、ニューロンのように機能するよう設計されています。大量のデータでトレーニングされて有用なコードを生成できるようになったAIモデルは、ツールやアプリケーションに組み込まれます。コードエディターやIDEに組み込むと、自然言語プロンプトやコードに応じて、新しいコード、関数、フレーズを提案します。
生成系AIコーディングツールの開発方法について説明する前に、まず生成系AIとは何かを定義しましょう。生成系AIは、大規模言語モデル(LLM)から始まります。LLMは、大量のコードと人間の言語でトレーニングしたアルゴリズムのセットです。前述の通り、生成系AIは、既存のコードや自然言語プロンプトを使用してコードシーケンスを予測し、新しいコンテンツを生成することができます。
現在の最先端のLLMはTransformerです。つまり、Attention機構と呼ばれるものを使って、ユーザの入力に含まれる様々なトークンと、モデルが既に生成した出力の間を柔軟に関連付けます。これにより、点と点をつなぐことや大局的な思考を得意とするLLMは、従来のAIモデルよりも文脈に即した回答ができます。
ここで、Transformerの仕組みの例をご紹介します。仮に、コードの中にlogという単語があったとします。その場所にあるTransformerノードは、Attention機構を使って次にどのような種類のlogが来るかを文脈的に予測します。
たとえば下の例では、from math import logと入力しています。生成系AIモデルは、これは対数関数を意味していると推論します。
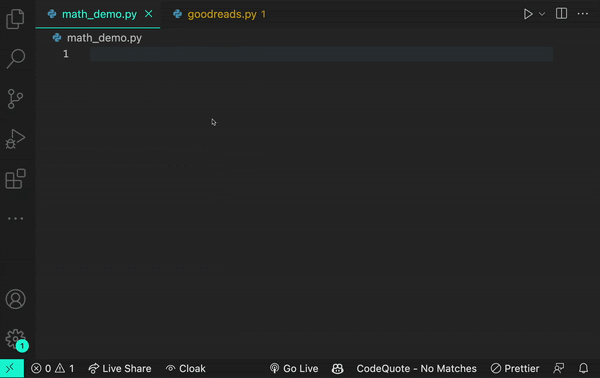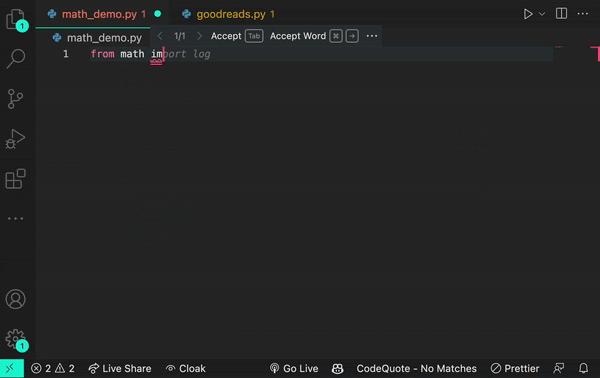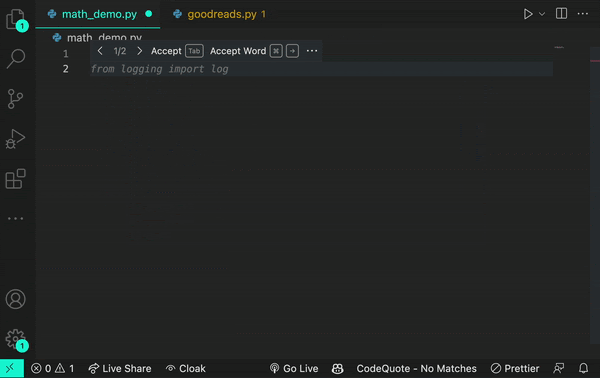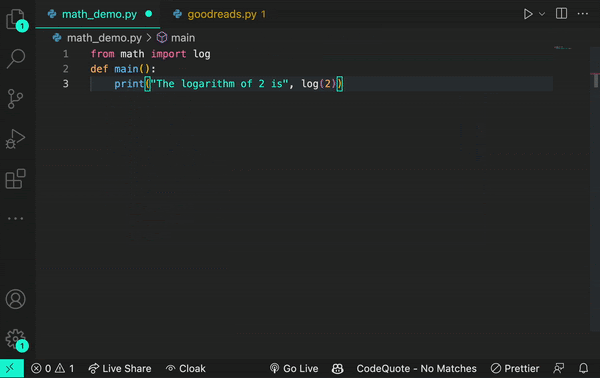
また、from logging import logというプロンプトを追加すると、ログ関数を使用していると推論します。
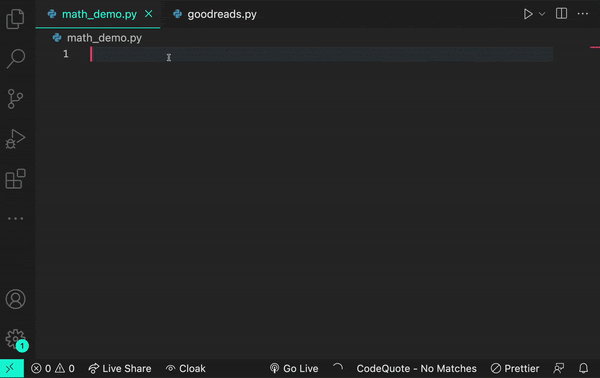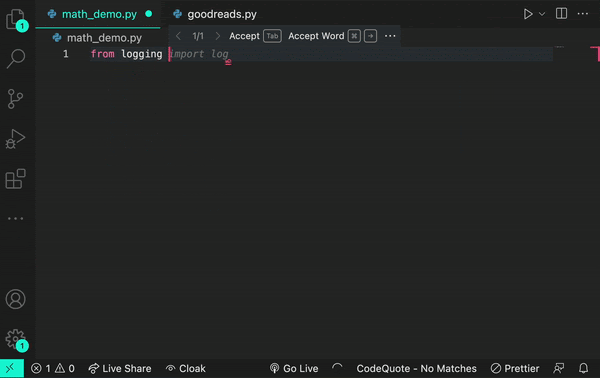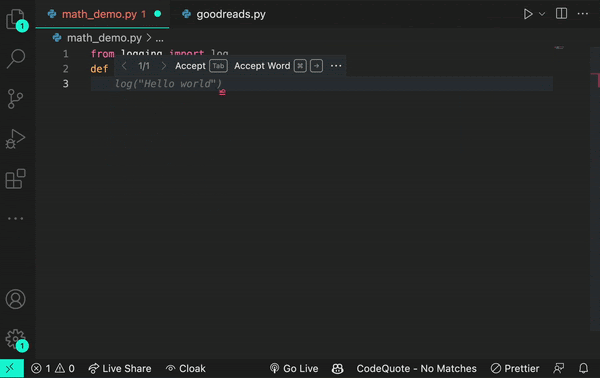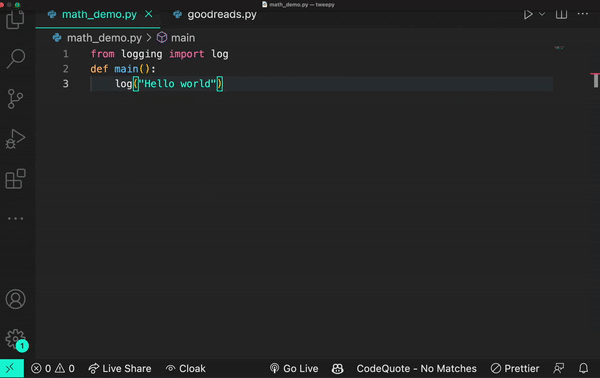
あるいは、ただのログでしかない場合もあります。
LLMはTransformer以外にもフレームワークを使って構築できます。ただし、再帰型ニューラルネットワークや長・短期記憶のようなフレームワークが使われているLLMは、長文や段落の処理に長けていません。また、通常はラベル付きデータでの学習が必要となります(学習に労力がかかります)。そのため、出力の複雑さや関連性、学習できるデータが制限されます。
一方、Transformer LLMは、ラベルなしデータで自己学習が可能です。基本的な学習目標が与えられると、LLMは新しい入力データの一部を取り出し、学習目標を達成するために使用します。入力データの一部で学習目標を達成すると、学習したことを応用して残りの入力データを理解します。この「自己教師あり学習」プロセスによって、Transformer LLMは大量のラベルなしデータを分析することが可能になります。LLMのトレーニングに使うデータセットが大きければ大きいほど、そのデータを処理することでより規模が大きくなります。
開発者がTransformerと大規模言語モデル(LLM)にこだわるべき理由
OpenAIのGPT-3、GPT-4、CodexモデルのようなLLMは、膨大な量の自然言語データと公開されているソースコードでトレーニングされています。これらのモデルをベースに作られたChatGPTやGitHub Copilotなどのツールが、文脈に即した正確な出力を生成できる理由の一部はここにあります。
GitHub Copilotのコード提案の仕組みをご紹介します。
- これまでに書かれたコードやIDEでカーソルの前に位置するコードはすべて、一連のアルゴリズムに入力され、GitHub Copilotによる処理対象となる部分が決められます。
- GitHub CopilotはTransformerベースのLLMを使用しているため、学習データから抽出したパターンを、入力されたコードに適用します。
- その結果、文脈に即した独自のコードが提案されます。GitHub Copilotは、既知のセキュリティの脆弱性、脆弱なコードパターン、他のプロジェクトと一致するコードなどを除外することもできます。
ポイント:テキスト、コード、画像など新しいコンテンツを制作が、生成系AIの核となるものです。LLMが得意とするのは、学習データからパターンを抽出して既存の言語に適用し、そのパターンに沿った言語やコードを生成することですが、LLMの規模が非常に大きければ、まだ存在しない言語やコードシーケンスを生成する可能性もあります。同僚のコードをレビューするのと同様に、AIが生成したコードも評価、検証する必要があります。
AIコーディングツールにとって文脈が重要である理由
コードは、すべてのTransformerベースのLLMに存在する「コンテキストウィンドウ」から入力が必要なため、優れたプロンプト作成テクニックを身に付けることが重要です。コンテキストウィンドウは、LLMが処理できるデータ量を表したものです。無限の量のデータを処理することはできませんが、拡大することは可能です。現在、Codexモデルは、数百ステップものコードを処理できるコンテキストウィンドウを備えており、コード補完やコード変更の要約といったコーディング作業は既に高度化と高速化が進んでいます。
コードに文脈情報を添えるには、Pull Requestの詳細、プロジェクト内のフォルダー、オープンなIssueなど、多くの情報を用います。そのため、コンテキストウィンドウが限られているコーディングツールに関しては、コードに加えてどのようなデータが最良の提案につながるかを見極めることが課題となります。
データの順序も、モデルの文脈理解に影響します。最近、GitHubはペアプログラマーをアップデートし、カーソルの直前のコードだけではなく、カーソルの後のコードの一部も考慮するようにしました。このパラダイムはFill-In-the-Middle (FIM)と言い、コードの中にGitHub Copilotが埋められる隙間を作り、開発者の意図するコードとプログラムの残りの部分との整合性について、より多くの文脈をツールに提供します。これにより、さらに遅延を生じさせることなく、質の高いコード提案を生成することができます。
映像でコードを文脈化することもできます。マルチモーダルLLM (MMLLM)は、テキストだけでなく画像や動画も処理できるように、Transformer LLMを拡張します。OpenAIは最近、新しいGPT-4モデルをリリースし、Microsoftは、Kosmos-1という独自のMMLLMを公開しました。これらのモデルは、代替テキストと画像、画像と字幕のペア、テキストデータなど、自然言語と画像に対応するよう設計されています。
GitHubのシニアデベロッパーアドボケイトであるChristina Warrenが、GPT-4の最新情報と開発者にもたらす創造的な可能性を紹介していますので、ご覧ください。
| GitHub Nextの研究開発チームは、GitHub Copilot XでAIをエディター以上のものにしようと取り組んでいます。この新しいビジョンでは、AIを活用したソフトウェア開発の未来を見据えて、OpenAIの新しいGPT-4モデルを採用しただけでなく、チャットと音声機能を導入し、Pull Request、コマンドライン、ドキュメントにGitHub Copilotを組み込んでいます。AIを活用したソフトウェア開発の未来に対する調査はこちら > |
開発者による生成系AIコーディングツールの活用法
生成系AIの分野では、積極的な実験と探求を通じて、このテクノロジーが持つすべての能力、さらにはこのテクノロジーを活用して効率的な開発者ワークフローを実現する方法を明らかにする取り組みが進んでいます。生成系AIツールは、生産性を高めるだけでなく、開発者がより大きな問題に集中できるようにするなど、開発現場でのコードの書き方やソフトウェアの開発方法での変化を既に起こしています。
ソフトウェア開発における生成系AIの応用の定義はまだ活発に議論されているところですが、現在、開発の現場では生成系AIのコーディングツールの活用により以下が実現されています。
- 複雑なコード変換タスクを有利に始める。2021年発表調査『International Conference on Intelligent User Interfaces』によると、生成系AIは、開発者が古いソースコードをPythonに変換するための骨格となっています。提案が常に正しいとは限らなくても、コードを一から手作業で変換するより、その間違いを評価して修正するほうが簡単であるとわかったのです。また、このレビューと修正のプロセスは、同僚が作成したコードに対して行う作業とさほど変わらない、ということもわかりました。
コードの異なる言語への変換は、GitHub Copilot Labsで行うことができます。GitHub Copilot Labsでは、付属のVS Code拡張機能(GitHub Copilot拡張機能とは別のものですが、依存関係があります)を使用します。GitHubデベロッパーアドボケイトのMichelle Manneringが、GitHub Copilot Labsを使ってPythonのコードをわずか数ステップでRubyに変換したケースを、こちらで紹介しています。
- より効率的にコードを書く。Auto Complete機能は何年も前から最新のIDEに装備されていますが、LLMのほうが関連性の高い、より長いコードを、時には数ステップのコードの提案から生成が可能です。2022年に『Proceedings of the Association for Computing Machinery on Programming Languages (PACMPL)』に掲載された調査では、GitHub Copilotを利用した20人のプログラマーを対象に観察を行い、その結果、関数の呼び出しや引数の入力候補が行末で提案されるおかげで、開発者はより速くコーディングし、より長くワークフローに留まることができるとわかりました。
GitHub独自の調査もこれらの結果を裏付けています。前述のとおり、GitHub Copilotを使うと、使わなかった場合との比較では、コーディングの時間が最大55%短縮されたという調査結果が出ています。しかも、生産性の向上によって、開発のスピードが速くなっただけでなく、74%の開発者がコーディング時のイライラが減り、より満足度の高い仕事に集中できるようになったと回答しています。
- 新たな問題に取り組み、創造力を発揮する。PACMPLの調査では、開発者が進め方を迷っているときに、GitHub Copilotを使って創造的な解決策を見つけていることも判明しました。こうしたケースでは、開発者は次に可能性のあるステップを探し、生成系AIコーディングツールを活用して、詳しくない構文の書き方をサポートしてもらい、正しいAPIを調べ、正しいアルゴリズムを見つけていました。
私はGitHub Copilotの開発者の1人ですが、この仕事をする前は、TypeScriptを一行も書いたことがありませんでした。ですが、それはまったく問題になりませんでした。GitHub Copilotの最初のプロトタイプを使って言語を学び、最終的には世界初の大規模な生成系AIコーディングツールのリリースに貢献できたのですから。
– Albert Ziegler、マシーンラーニング担当プリンシパルエンジニア // GitHub
- IDE内で答えを探す。PACMPL調査の参加者の中には、GitHub Copilotのマルチ提案ペインをStack Overflowのように扱った人もいました。自然言語で目標を記述できたため、参加者は目標を実装するアイデアを生成するようGitHub Copilotに直接指示し、Ctrl/Cmd + Enterキーを押して、10個の提案のリストを見ることができました。このような探索が深い知識につながるわけではありませんが、ある開発者は使い慣れていないAPIを効果的に利用できるようになりました。
GitHubが『ACM Queue』誌で発表(2023年実施調査)でも、生成系AIコーディングツールは、オンラインで答えを探す開発者の手間を軽減することができるとしています。これにより、開発者はより明快な答えを得たり、コンテキストの切り替えを減らしたり、精神的なエネルギーを維持することができます。
AIを活用したソフトウェア開発の未来に対するGitHubの新しいビジョンの1つとして、「エディターで直接ChatGPTのような体験ができる」というものがあります。GitHubのデベロッパーリレーション担当バイスプレジデントであるMartin Woodwardが、GitHub Copilot Chatを使ってどのようにコードのバグを発見、修正したかを、こちらで紹介しています。
- より優れたテストカバレッジを開発する。一部の生成系AIコーディングツールは、パターン認識と補完を非常に得意としています。こうしたツールは、ユニットテストや機能テスト、セキュリティテストを自然言語プロンプトで開発する際に使われています。また、中には、セキュリティ脆弱性フィルタリング機能を備えたツールもあり、開発者が自分のコードの脆弱性に気づかなかった場合に、アラートが表示されます。
実際の活用例として、GitHubのデベロッパーアドボケイトであるRizel Scarlettが、GitHub Copilotを使ってコードベースのテストを開発する様子を、こちらの記事で紹介しています。
- 必要であることに気づかなかったコツやソリューションを発見する。Scarlettはまた、開発者が使えるGitHub Copilotの8つの意外な活用方法についても言及しています。例えば、2文字のISO国コードと国名の辞書を作成するよう指示することや、終了処理に注意を要するエディターであるVimの終了を支援することを挙げています。詳細については、ガイドをご覧ください 。
まとめ
生成系AIは、人間に新たな操舵作用(インタラクション)を提供し、ソフトウェア開発の退屈な部分を軽減するだけではありません。開発者に刺激をもたらし、創造性の向上、大きな問題に取り組む強い意欲、今まで不可能だった方法での大規模かつ複雑なソリューションのモデル化などを可能にします。ソフトウェア開発現場における次の波に期待すべき理由はたくさんあります。生産性の向上や代替ソリューションの提供に加えて、新しい言語やフレームワークの習得、明確なコメントやドキュメントの作成など、新たなスキルの習得にも役立ちます。今は、まだその始まりに過ぎません。