
Git のリポジトリが大きくなると、新しい開発者がクローンして作業を始めるのが難しくなります。Git は 分散 バージョン管理システムとして設計されています。つまり、リポジトリとのやりとりを管理する中央サーバーに接続しなくても、自分のマシンで作業ができるということです。これが完全に実現できるのは、すべての到達可能なデータがローカルリポジトリにある場合だけです。
もっと良い方法があったらどうでしょうか?Git の全履歴にあるすべてのファイルのすべてのバージョンをダウンロードしなくても、リポジトリで作業を始めることができたらどうでしょうか?Git の パーシャルクローンやシャロークローンという機能は、こういったケースで役立ちます。その一方でこれらの機能にはトレードオフもあります。これらの選択肢は Git の分散という性質によってもたらされる可能性を少なくとも一つは壊してしまうため、こうしたトレードオフは受け入れられないと思うかもしれません。
もしあなたが非常に大規模なモノレポを扱うのであれば、これらのトレードオフは価値がある可能性が高いですし、時にはその規模の Git リポジトリでは 必須 であると言えます!
このトピックを掘り下げていく前に、Git がどのようにデータを保存しているのか、コミットやツリー、ブロブオブジェクトをよく理解しておきましょう。GitHub Universe での私のセッション Optimize your monorepo experience では、これらのアイデアやその他の役立つヒントを紹介しました。
概要
GitHub でホストされているリポジトリのクローンサイズを小さくするには、三つの方法があります。
git clone --filter=blob:none <url>は ブロブレスクローン を作成します。このクローンは、到達可能なすべてのコミットとツリーをダウンロードする一方、ブロブは必要に応じて取得します。このクローンは、開発者や複数回ビルドを実行するようなビルド環境に最適です。git clone --filter=tree:0 <url>は ツリーレスクローン を作成します。このクローンは、到達可能なすべてのコミットをダウンロードする一方、ツリーとブロブは必要に応じて取得します。このクローンは、一度ビルドを実行した後に削除される予定で、コミット履歴にはアクセスしたいというビルド環境に最適です。git clone --depth=1 <url>は シャロークローン を作成します。このクローンはコミット履歴を切り捨ててクローンのサイズを小さくします。これによって、想定外の問題を引き起こしたり、利用可能な Git コマンドが制限されます。また、このクローンは後からのフェッチに過度のストレスを与えることになるので、開発者が使用することは強くお勧めしません。一度ビルドした後にリポジトリを削除するビルド環境では便利です。
フルクローン
これからさまざまなクローンの種類について議論するにあたり、各 Git オブジェクトを以下の記法で表します。
- 四角はブロブです。ファイルの内容を表します。
- 三角はツリーです。ディレクトリを表します。
- 円はコミットです。ある時間におけるスナップショットを表します。
オブジェクト間の関係を表すために矢印を使用します。基本的にある OID B が、あるコミットもしくはツリー A の中に現れた場合、オブジェクト A はオブジェクト B への矢印を持ちます。あるオブジェクト A から別のオブジェクト C へ複数の矢印を辿って到達することができれば、C は A から 到達可能 と言います。こういった矢印を辿るプロセスは時に オブジェクトを渡り歩く とも言われます。
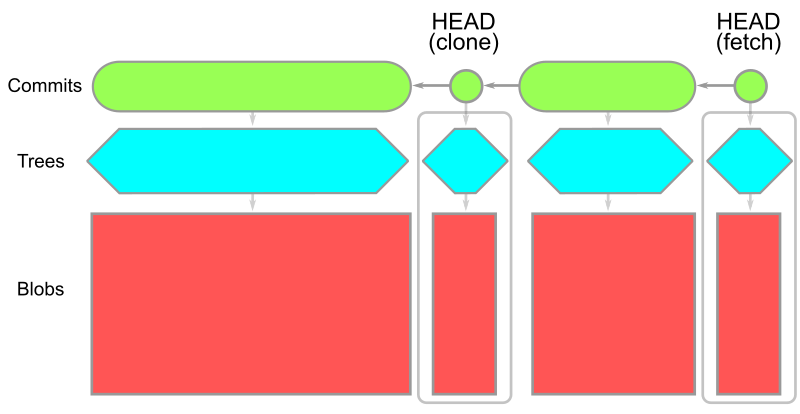
これで、 git clone コマンドでダウンロードしたデータを記述できるようになりました!クライアントはサーバーに最新のコミットを要求し、サーバーはそれらのオブジェクトとそこから 到達可能なすべてのオブジェクト を提供します。これには、コミット履歴全体のすべてのツリーやブロブが含まれます。
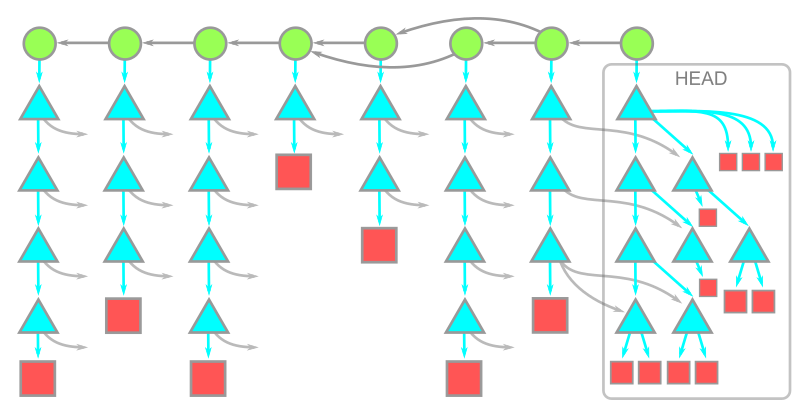
この図では、時間は左から右に向かって経過していきます。コミットからその親への矢印は右から左に向かっています。各コミットは一つのルートツリーを持っています。HEAD コミットのルートツリーは、その下に完全に展開されており、残りのツリーにはこれらのオブジェクトを指す矢印があります。
この図は意図的にシンプルにしていますが、リポジトリが非常に大きい場合は、多くのコミット、ツリー、ブロブが履歴の中に存在することになります。おそらく、過去のデータがデータの大部分を形成するでしょう。本当にすべて必要なのでしょうか?
最近では、多くの開発者は常にネットワーク接続を利用して作業をしているので、必要に応じてサーバに少しのデータを要求することは、トレードオフとしては許容できるかもしれません。
これがパーシャルクローンによってもたらされる重要な設計上の変更点です。
パーシャルクローン
Git のパーシャルクローン機能は、git clone コマンドで --filter オプションを指定することで有効になります。git rev-list のドキュメントにフィルタオプションの全リストがあります。 git rev-list --filter=<filter> --all を使用すると、リポジトリ内のどのオブジェクトがフィルタにマッチするかを確認できます。フィルタはいくつか用意されていますが、サーバーはフィルタを拒否してフルクローンを実行することもできます。
github.com と GitHub Enterprise Server 2.22 以降では、二つのオプションが利用できます。
- ブロブレスクローン:
git clone --filter=blob:none <url> - ツリーレスクローン:
git clone --filter=tree:0 <url>
それぞれのオプションを見てみましょう。
ブロブレスクローン
--filter=blob:none オプションを指定すると、最初の git clone は到達可能なすべてのコミットとツリーをダウンロードし、git checkout を行ったコミットのブロブだけをダウンロードします。これには、 git clone 操作の中での最初のチェックアウトも含まれます。結果のオブジェクトモデルは以下のようになります。
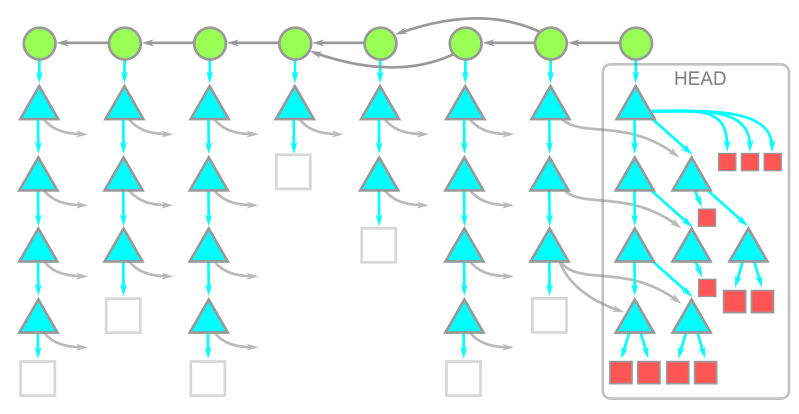
注意すべき重要な点は、HEAD にはすべてのブロブのコピーがある一方で、履歴上のブロブは存在しないということです。リポジトリの履歴が多く、大きなブロブがたくさんあるような場合は、このオプションを使うことで git clone の時間を大幅に短縮することができます。コミットやツリーのデータはそのまま残っているので、それ以降の git checkout では欠落しているブロブをダウンロードするだけで済みます。Git クライアントは、欠落しているブロブだけをサーバーに要求するリクエストをまとめて実行することができます。
さらに、ブロブレスクローンで git fetch を実行すると、サーバーは新しいコミットとツリーだけを送信します。新しいブロブがダウンロードされるのは、git checkout の実行時です。git pull は git fetch を実行してから git merge を実行するので、それによって必要なブロブが自動的にダウンロードされる点に注意しましょう。
ブロブレスクローンを使用しているときは、ファイルの 内容 が必要なときはブロブのダウンロードがトリガーされますが、ファイルの OID だけが必要なときはダウンロードは実行されません。これは、余分なデータをダウンロードしなくても git log はどのコミットが指定したパスを変更したかを検出できることを意味します。
つまり、ブロブレスクローンは git merge-base や git log、さらには git log -- <path> のようなコマンドをフルクローンと同じパフォーマンスで実行できるということです。
git diff や git blame <path> のようなコマンドは、差分を計算するためにパスの内容を必要とします。そのため、これらのコマンドを初めて実行する際にはダウンロードがトリガーされます。しかし、良いニュースは、一度ダウンロードをしてそれらのブロブをリポジトリに保存したあとは、二度目のダウンロードは不要になるということです。ほとんどの開発者は、 git blame を実行する必要があるのはごく少数のファイルだけです。そのため、 git blame コマンドがわずかに遅くなる代わりにクローンやフェッチが速くなるというこのトレードオフは理にかなっています。
ブロブレスクローンは、最も広く使われているパーシャルクローンのオプションです。私自身も何ヶ月も問題なく使っています。
ツリーレスクローン
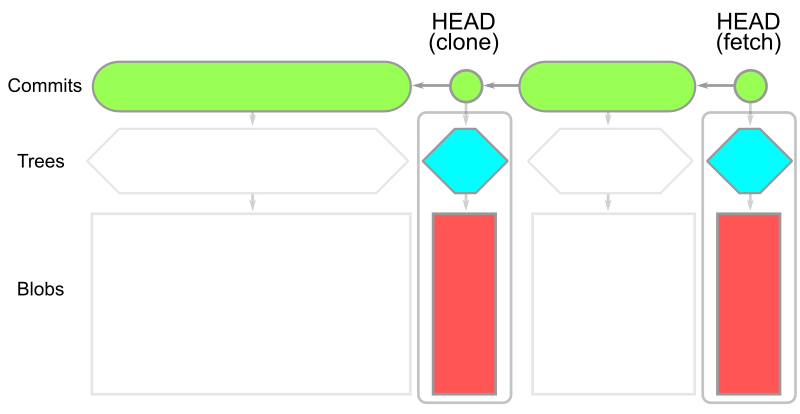
リポジトリによっては、ツリーデータが履歴のかなりの部分を占めるかもしれません。--filter=tree:0 で得られるツリーレスクローンは、到達可能なすべてのコミットをダウンロードし、必要に応じてツリーとブロブをダウンロードします。結果のオブジェクトモデルを以下に示します。
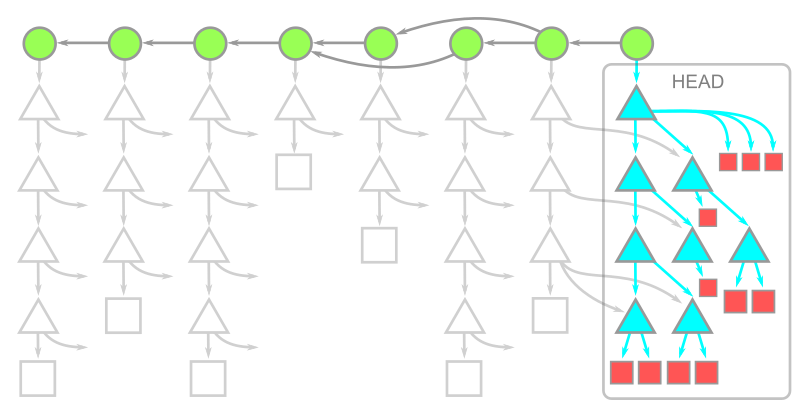
HEAD のすべてのデータはありますが、それ以外はコミットデータしかないことに注意してください。これは、ツリーレスクローンでは最初のクローンが、ブロブレスクローンやフルクローンよりも はるかに 高速に作成できることを意味します。さらに、 git fetch を実行して最新のコミットのみをダウンロードすることもできます。しかし、欠落しているツリーが必要になった際のダウンロードはコストが高いため、ツリーレスクローンでの作業はより難しいものとなります。
たとえば、 git checkout コマンドは HEAD コミットを変更します。そして、大抵の場合、そのコミットのルートツリーは持っていないでしょう。Git クライアントは、サーバーに OID を指定してルートツリーを要求するだけでなく、そのルートツリーから到達可能なすべてのツリーを要求します。現在のところ、このリクエストはクライアントがすでに持っているルートツリーについてサーバーに伝えません。そのためサーバーはクライアントがローカルにすでに持っているツリーをたくさん送ってしまうかもしれません。ツリーがダウンロードされた後、クライアントはどのブロブが足りていないかを検出し、それらをまとめてリクエストします。
ツリーレスクローンで余分なデータを要求することなく作業を行うことはできますが、ブロブレスクローンよりも制限が多くなります。
たとえば、git merge-base や git log (追加オプションなし) のような履歴操作は、コミットデータのみを使用します。これらの操作では、追加のダウンロードは行われません。
しかし、git log -- <path> のようなファイル履歴のリクエストを実行すると、ツリーレスクローンは履歴のほとんどすべてのコミットに対してルートツリーのダウンロードを開始します!
開発者の皆さんには、日々の作業にツリーレスクローンを使わないよう強くお勧めします。ツリーレスクローンが本当に役に立つのは、自動ビルドで素早くクローンを作成してプロジェクトをコンパイルし、リポジトリを捨てたいときだけです。パブリックランナーを使った GitHub Actions のような環境では、クローン時間を最小限に抑えて、ソフトウェアを実際にビルドするためにマシンの時間を使いたいでしょう!そのような環境では、ツリーレスクローンは優れた選択肢かもしれません。
警告: この記事を書いていて、私たちはツリーレスクローンの限界を超えてテストしてしまいました。 サブモジュール を含むリポジトリでは、ツリーレスクローンの挙動が非常に悪いことに気づきました。具体的には、ツリーレスクローンで git fetch を実行すると、変更されたサブモジュールを探す Git のロジックが、新しいコミットごとにツリーへのリクエストを引き起こしてしまうのです!この挙動は、ツリーレスクローンで git config fetch.recurseSubmodules false を実行することで回避できます。私たちは、Git クライアントへのより強固な修正に取り組んでいます。
シャロークローン
パーシャルクローンは Git にとって比較的新しいものですが、古い機能でツリーレスクローンと非常に似たようなことをするものにシャロークローンがあります。シャロークローンは、 git clone の --depth=<N> パラメータを使ってコミット履歴を切り捨てます。一般的に --depth=1 は、直近のコミットのみを対象とすることを意味します。シャロークローンは --single-branch --branch=<branch> オプションと組み合わせるのがベストです。こうすることで、確実にすぐに使う予定のコミットのデータのみをダウンロードすることができます。
シャロークローンのオブジェクトモデルを下に示します:
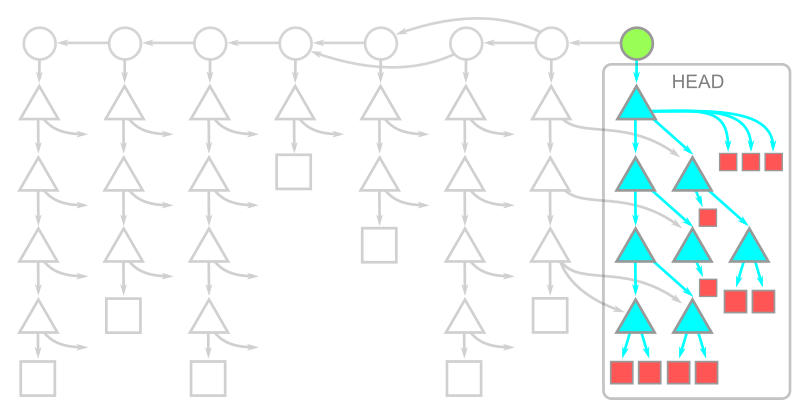
ここでは、 HEAD のコミットは存在しますが、その親や他の履歴への接続は切れています。親が削除されたコミットは シャローコミット と呼ばれ、 シャローバウンダリー を形成します。コミットオブジェクト自体は変更されていませんが、クライアントリポジトリでは、Git クライアントがこれらの親との接続を無視するように指示するメタデータを持っています。クライアント上に存在するすべてのコミットのツリーとブロブに関しては、すべてダウンロードされます。
コミット履歴は切り捨てられているので、 git merge-base や git log のようなコマンドを実行すると、フルクローンを作成したときとは異なる結果が表示されます!一般的に、これらのコマンドは期待どおりに動作しません。これらのコマンドは、パーシャルクローンでは期待どおりに動作することを思い出してください。ブロブレスクローンの場合でも、 git blame -- <path> のようなコマンドはフルクローンでの場合よりは多少遅いかもしれませんが正しく動作します。シャロークローンでは、そのような可能性すらありません!
もうひとつの大きな違いは、シャロークローンでの git fetch の挙動です。新しいコミットをフェッチする際、サーバーはそれらのコミットのツリーやブロブの中でシャローコミットに「存在しない」ものをすべてを提供しなければなりません。この計算は通常のフェッチよりもコストがかかります。これはメンテナンスが行き届いたサーバであれば到達可能性ビットマップを利用できるからです。他の人がリモートリポジトリにどのように貢献しているかにもよりますが、シャロークローンでの git fetch 操作では、ほぼすべてのコミット履歴をダウンロードしてしまうことがあります。
ここまでに、シャロークローンの価値を打ち消してしまうようなうまくいかないケースをいくつか説明してきました。これらの理由から、その後すぐにリポジトリを削除するようなビルドのケースを除いて、シャロークローンはお勧めしません。シャロークローンからのフェッチは、メリットよりもデメリットの方が大きくなることがあります。
先ほど「シャローバウンダリー」について言及したのを覚えているでしょうか?クライアントは git fetch コマンドの際にそのバウンダリー(境界)をサーバーに送り、そのバウンダリー以外の到達可能なコミットをすべて保持していないことをサーバーに伝えます。そしてクライアントは最新のコミットとそこから到達可能なすべてのコミットを取得し、 そのバウンダリーのシャローコミットに到達するまで 要求します。別のユーザーがそのバウンダリー外でトピックブランチを開始し、シャロークライアントがそのトピックを取得した場合 (もしくはより悪いことにトピックがデフォルトブランチにマージされた場合)、サーバーは履歴をすべてたどり、ほぼフルクローンに相当するものをクライアントに返す必要があります!さらに、サーバーは到達可能性ビットマップのようなパフォーマンス機能の利点を利用せずにデータを計算する必要があります。
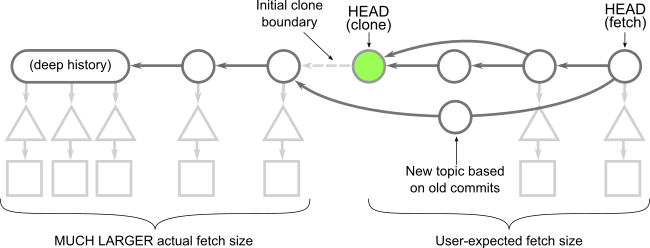
クローンの各選択肢の比較
それぞれのクローンの選択肢を振り返ってみましょう。純粋なオブジェクトレベルで見るのではなく、オブジェクトをカテゴリーに分けて見てみましょう。下の図は、リポジトリタイプごとにダウンロードされるデータをグループ化したものです。クローンでダウンロードされるデータに加えて、ある程度時間が経過した後に git fetch と git checkout を実行して新しいコミットに移動した場合を考えてみましょう。それぞれの選択肢について、どのくらいのデータがダウンロードされるかを見てみます。
フルクローンは、到達可能なすべてのオブジェクトをダウンロードします。一般的に、このデータの大部分はブロブです。
パーシャルクローンでは、一部のデータはすぐには提供されず、クライアントが必要とする時に提供されます。ブロブレスクローンは、チェックアウト時に必要なデータのみダウンロードし、それ以外のブロブはスキップします。ツリーレスクローンは、各チェックアウトに必要なツリーのフルコピーはダウンロードし、それ以外の履歴内のすべてのツリーをスキップします。
実際の計測値は?
GitHub の仲間のエンジニアの @solmazabbaspour が、さまざまなオープンソースリポジトリ上でこれらの異なるクローンの選択肢を比較するための実験を設計し、実行しました。彼女は別のブログで実験の詳細とデータを公開する予定ですが、ここではその概要を共有します。ここでは、あなた自身の使用法に適したシナリオを選択するのに役立つであろう、私たちが特定したいくつかの共通のテーマを紹介します。
クローンにはデフォルトのフルクローン以外にも様々なタイプがあります。本当に分散型のワークフローが必要で、すべてのデータをローカルリポジトリに保存したい場合は、フルクローンを使い続けるべきです。単一のリポジトリで作業している開発者で、リポジトリのサイズが適切である場合は、フルクローンを行うのが最善のアプローチです。
大きなブロブがたくさんあってリポジトリが非常に大きい場合は、ブロブレスのパーシャルクローンに切り替えることができます。そうすることで、より素早く作業を始めることができます。トレードオフは、 git checkout や git blame のようなコマンドにおいて、必要に応じて新しいブロブデータがダウンロードされるというものです。
一般的に、シャローフェッチの計算はフルフェッチに比べて計算量が多くなります。フルクローンリポジトリでもシャロークローンリポジトリでも、常にシャローフェッチではなくフルフェッチを使用するようにしましょう。
CI ビルドのようなワークフローで、単一のクローンを作成してすぐにリポジトリを削除する場合は、シャロークローンが良い選択肢です。シャロークローンは最新のコミットの作業ディレクトリのコピーを取得する最速の方法ですが、これらのリポジトリでのフェッチにはコストがかかるため、開発者にはシャロークローンはお勧めできません。ビルドの際にコミット履歴が必要な場合は、フルクローンよりもツリーレスなパーシャルクローンの方がうまくいくかもしれません。
一般的に、 人によって適切な使い方は異なります 。ここまでで、様々な異なる選択肢とその背後にあるオブジェクトモデルがわかったので、これらのクローンを適切に使い分けることができるようになりました。これらのフルクローン以外の選択肢にはいくつかの落とし穴があることを意識して使いましょう。
- シャロークローンはコミット履歴をスキップします。そのため
git logやgit merge-baseのようなコマンドが使えなくなります。シャロークローンからは絶対にフェッチしないようにしましょう。 - ツリーレスクローンにはコミット履歴が含まれていますが、欠落しているツリーをダウンロードするのは非常にコストがかかります。そのため、
git log(パス指定なし)やgit merge-baseは実行可能ですが、git log -- <path>やgit blameのようなコマンドは非常に遅く、これらのクローンでの利用はお勧めしません。 - ブロブレスクローンにはすべての到達可能なコミットとツリーが含まれており、Git はファイルの内容にアクセスする必要があるときにブロブをダウンロードします。つまり、
git log -- <path>のようなコマンドは使えますが、git blameのようなコマンドは最初の実行時には少し遅くなります。しかし、古くて大きなブロブをたくさん持っている非常に大きなリポジトリを使い始める際には、これはとても良い方法です。 - フルクローンは期待通りに動作します。唯一の欠点は、すべてのデータをダウンロードするのに時間がかかることと、すべてのファイルのためのディスク容量が余分に必要になることです。
最後に、最新のパフォーマンス改善の恩恵を得るために、必ず最新の Git バージョンにアップグレードしましょう!