
Issues検索は、シンプルでフラットな構造のクエリをサポートしていました。それを、高度な検索構文により、論理的なAND/OR演算子や入れ子になった括弧を使用して検索を構築しました。これで、関心のあるIssueを正確に特定できるようになりました。
この機能の構築には、既存の検索との後方互換性の確保、大量のクエリに対するパフォーマンスの維持、入れ子検索のユーザーフレンドリーな体験の構築という大きな課題がありました。今回は、長年の要望であったこの機能を、どのようにしてアイデアから製品化したのか、その舞台裏をご紹介します。
新しい構文でできることと、その舞台裏
Issues検索では、すべてのフィールドにわたって論理AND/OR演算子を使用したクエリの構築がサポートされ、クエリ語のネストも可能になりました。例えば、is:issue state:open author:rileybroughten (type:Bug OR type:Epic) は、オープンであり、rileybroughtenが作成し、bugまたはepicタイプであるすべてのissueを検索します。

ここまでの経緯
前述したように、Issues検索はクエリ・フィールドと用語のフラット・リストのみをサポートしており、それらは暗黙的に論理ANDで結合されていました。例えば、assignee:@me label:support new-project というクエリは、”私に割り当てられていて、かつsupportというラベルがあり、なおかつ、new-project というテキストが含まれているすべての課題を教えてください” という意味になります。
開発者コミュニティからは10年近く前から、Issues検索の柔軟性を求められて きました。彼らは、クエリlabel:support OR label:question を使用して、ラベルsupport またはラベルquestion のいずれかを持つすべてのissueを検索できることを望んでいました。そこで私たちは、2021年にこのリクエストに対応する機能拡張を行い、カンマで区切られた値のリストを使用したORスタイルの検索を可能にしました。
しかし、ラベルフィールドだけでなく、 すべてのissueフィールドをこの方法で検索できる柔軟性が求められていました。そこで私たちは作業に取り掛かりました。
技術的なアーキテクチャと実装
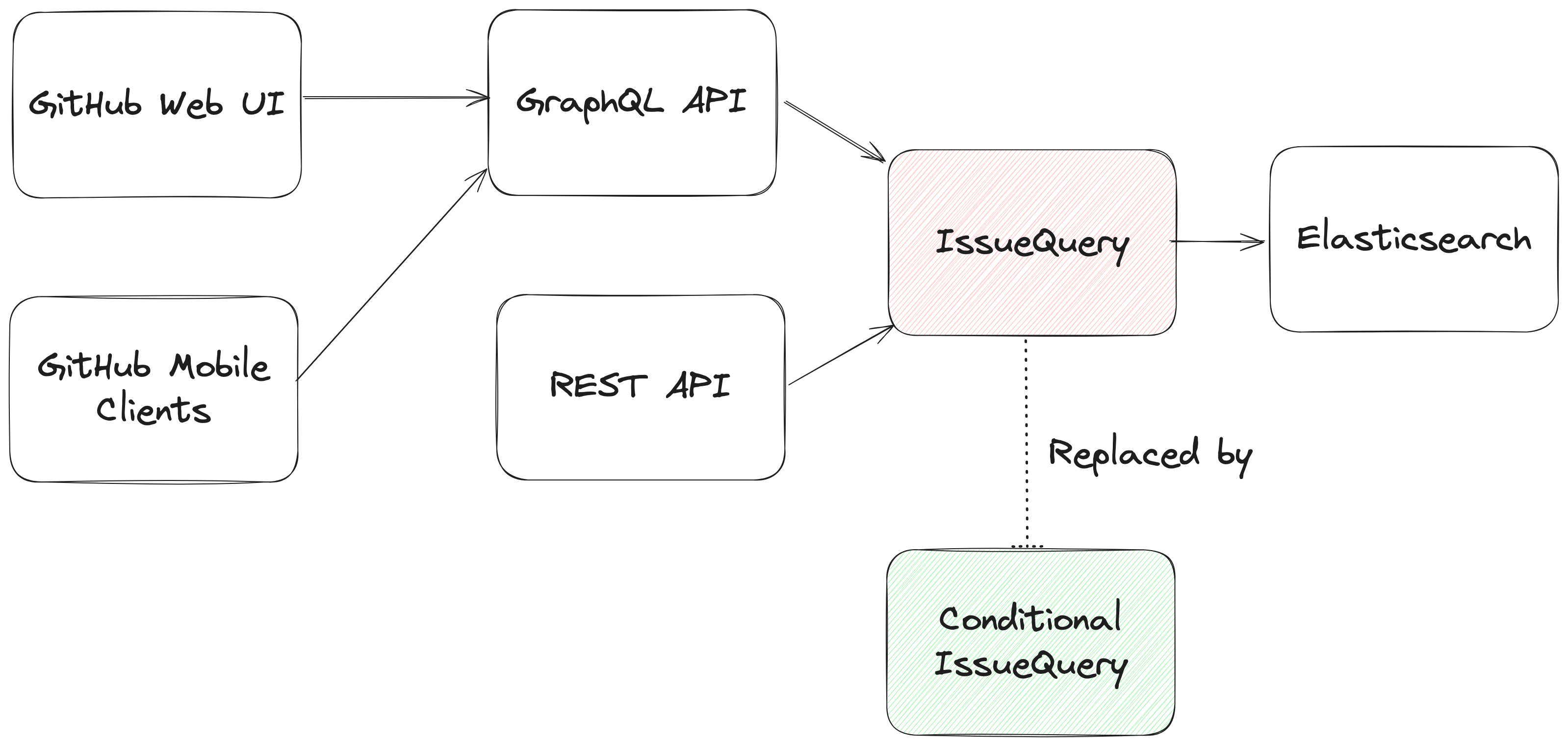
アーキテクチャの観点から、私たちは既存のIssue用検索モジュール(IssueQuery)を、既存のクエリ形式をサポートしながらネストされたクエリを処理できる新しい検索モジュール(ConditionalIssuesQuery)と交換しました。
これには、クエリ文字列を解析して Elasticsearch クエリにマッピングする検索モジュールである IssueQuery の書き換えが必要でした。

新しい検索モジュールを構築するためには、まず既存の検索モジュールと、1つの検索クエリがどのようにシステム内を流れるのかを理解する必要がありました。高レベルで言えば、ユーザーが検索を実行するとき、その実行には3つの段階があります:
- 解析:ユーザーの入力文字列を処理しやすい構造(リストやツリーのような)に分解する。
- クエリ:パースされた構造を Elasticsearch のクエリドキュメントに変換し、Elasticsearch に対してクエリを実行する。
- 正規化する: Elasticsearchから得られた結果(JSON)をRubyオブジェクトにマッピングし、簡単にアクセスできるようにし、データベースから削除されたレコードを削除するために結果を刈り込む。
各ステージにはそれぞれ課題がありましたが、以下で詳しく説明します。ノーマライズステップは再書き込みの間、変更されなかったので、これについては掘り下げません。
解析段階
ユーザー入力文字列(検索フレーズ)は、まず中間構造にパースされます。検索フレーズには以下のようなものがあります:
- クエリ用語:ユーザーがより多くの情報を見つけようとしている関連ワード(例:”models”)
- 検索フィルター: 何らかの条件に基づいて、返される検索文書のセットを制限する(例:”assignee:Deborah-Digges”)
検索フレーズの例
- 私に割り当てられた課題のうち、”codespaces “という単語を含むものをすべて検索してください:
is:issue assignee:@me codespaces
- 私に割り当てられている、”documentation“というラベルを持つすべての課題を検索します:
assignee:@me label:documentation
古い解析方法:フラットリスト
フラットでシンプルなクエリしかサポートされていなかったときは、ユーザーの検索文字列を検索語とフィルタのリストにパースし、それを検索プロセスの次のステージに渡すだけで十分でした。
新しい解析方法:抽象構文木
ネストされたクエリは再帰的である可能性があるため、検索文字列をリストにパースするだけではもはや十分ではありませんでした。私たちはこのコンポーネントを、構文解析ライブラリparsletを使用して、ユーザーの検索文字列を抽象構文木(AST)に構文解析するように変更しました。
検索文字列の構造を表現するための文法(PEG、Parsing Expression Grammar)を定義しました。この文法は既存のクエリ構文と新しいネストされたクエリ構文の両方をサポートし、後方互換性を持たせています。
パースレットパーサ用のPEG文法で記述されたブーリアン式の簡略化された文法を以下に示します:
class Parser < Parslet::Parser
rule(:space) { match[" "].repeat(1) }
rule(:space?) { space.maybe }
rule(:lparen) { str("(") >> space? }
rule(:rparen) { str(")") >> space? }
rule(:and_operator) { str("and") >> space? }
rule(:or_operator) { str("or") >> space? }
rule(:var) { str("var") >> match["0-9"].repeat(1).as(:var) >> space? }
# The primary rule deals with parentheses.
rule(:primary) { lparen >> or_operation >> rparen | var }
# Note that following rules are both right-recursive.
rule(:and_operation) {
(primary.as(:left) >> and_operator >>
and_operation.as(:right)).as(:and) |
primary }
rule(:or_operation) {
(and_operation.as(:left) >> or_operator >>
or_operation.as(:right)).as(:or) |
and_operation }
# We start at the lowest precedence rule.
root(:or_operation)
end例えば、このユーザー検索文字列:is:issue AND (author:deborah-digges OR author:monalisa )
は以下のASTに解析されます:
{
"root": {
"and": {
"left": {
"filter_term": {
"attribute": "is",
"value": [
{
"filter_value": "issue"
}
]
}
},
"right": {
"or": {
"left": {
"filter_term": {
"attribute": "author",
"value": [
{
"filter_value": "deborah-digges"
}
]
}
},
"right": {
"filter_term": {
"attribute": "author",
"value": [
{
"filter_value": "monalisa"
}
]
}
}
}
}
}
}
}クエリ
クエリが中間構造に解析されると、次のステップに進みます:
- この中間構造を Elasticsearch が理解できるクエリドキュメントに変換する。
- Elasticsearch に対してクエリを実行し、結果を取得する。
ステップ2でのクエリの実行は新旧のシステムで変わりませんので、以下ではクエリドキュメントの構築の違いについてだけ説明します。
旧クエリ生成: フィルタクラスを使ったフィルタ用語の線形マッピング
各フィルタ用語(例:label:documentation )には、それをElasticsearchクエリドキュメントのスニペットに変換する方法を知っているクラスがあります。クエリドキュメント生成時に、各フィルタ用語に対応する正しいクラスが呼び出され、クエリドキュメント全体が構築されます。
新しいクエリ生成: Elasticsearch のブールクエリを生成する再帰的 AST トラバーサル
構文解析中に生成された AST を再帰的に走査し、同等の Elasticsearch クエリドキュメントを構築します。ネストされた構造とブール演算子は、AND、OR、NOT 演算子がmust、should、should_not節にマッピングされることで、Elasticsearch のブールクエリにうまくマッピングされます。
クエリ生成の小部分のビルディングブロックを再利用して、ツリーのトラバーサル中にネストされたクエリドキュメントを再帰的に構築します。
構文解析段階の例から続けると、ASTは次のようなクエリ文書に変換されます:
{
"query": {
"bool": {
"must": [
{
"bool": {
"must": [
{
"bool": {
"must": {
"prefix": {
"_index": "issues"
}
}
}
},
{
"bool": {
"should": {
"terms": {
"author_id": [
"<DEBORAH_DIGGES_AUTHOR_ID>",
"<MONALISA_AUTHOR_ID>"
]
}
}
}
}
]
}
}
]
}
// SOME TERMS OMITTED FOR BREVITY
}
}この新しいクエリドキュメントを使って、Elasticsearchに対して検索を実行します。この新しいクエリ文書で、Elasticsearchに対して検索を実行します。この検索では、論理AND/OR演算子や括弧がサポートされ、よりきめ細かな方法でissueを検索できるようになりました。
考察
Issues は GitHub で最も古く、最も多く使われている機能のひとつです。Issues検索のような中心的な機能を変更することは、平均で毎秒2000近いクエリ(QPS)、つまり1日に約1億6000万クエリが行われる機能であり、克服すべき多くの課題がありました。
後方互換性の確保
課題検索は、ブックマークされたり、ユーザー間で共有されたり、ドキュメントにリンクされたりすることが多く、開発者やチームにとって重要な成果物となっています。そのため、ユーザーにとって既存のクエリを壊すことなく、ネストされた検索クエリの新機能を導入したいと考えました。
私たちは、新しい検索システムがユーザーに届く前に、以下の方法で検証を行いました:
- 広範なテスト:既存の検索モジュールのすべての単体テストと統合テストに対して、新しい検索モジュールを実行しました。GraphQL と REST API のコントラクトに変更がないことを確認するため、新しい検索システムの機能フラグが有効な場合と無効な場合の両方で検索エンドポイントのテストを実行しました。
- ダークシッピングによる本番での正しさの検証: Issues検索の1%について、ユーザーの検索をバックグラウンドジョブで既存の検索システムと新しい検索システムの両方に対して実行し、レスポンスの違いを記録しました。これらの差異を分析することで、ユーザーに届く前にバグを修正したり、見逃されてきたエッヂケースでふるまいを修正することができました。
- 当初は「差異」をどのように定義するか迷いましたが、最初の反復では「結果の数」に落ち着きました。一般的には、検索が1秒以内に実行された場合、異なる数の結果が返されれば、ユーザーが新しい検索機能に対する検索結果に驚くかどうかを判断できると思われた。
パフォーマンス低下の防止
より複雑なネストされたクエリは、より単純なクエリよりもバックエンドでより多くのリソースを使用することが予想されるため、既存の単純なクエリのパフォーマンスを低下させないようにしながら、ネストされたクエリの現実的なベースラインを確立する必要がありました。
Issues検索の1%について、既存の検索システムと新しい検索システムの両方で同等のクエリを実行しました。クリティカルパスを注意深くリファクタリングするために、GitHubのオープンソースのRubyライブラリであるscientistを使用し、同等のクエリのパフォーマンスを比較し、後退がないことを確認しました。
ユーザーエクスペリエンスの維持
より複雑な検索が 可能になったからといって、ユーザーが以前よりも悪い体験をすることは避けたいと考えました。
私たちは製品チームやデザインチームと密接に協力し、この機能を追加してもユーザビリティが低下しないよう、次のような対策を講じました:
- クエリの入れ子レベルの数を 5つに制限 。カスタマー・インタビューの結果、これがユーティリティとユーザビリティのスイート・スポットであることがわかりました。
- 役に立つUI/UXの手がかりを提供する:検索クエリのAND/ORキーワードを強調し、単純なフラットクエリで慣れ親しんだのと同じフィルター用語のオートコンプリート機能をUIでユーザーに提供する。
既存ユーザーへのリスクの最小化
1日に何百万人ものユーザーが使用する機能であるため、ユーザーへのリスクを最小限に抑える方法で意図的に展開する必要がありました。
私たちは、次のような方法でシステムに対する信頼を築きました:
- ブラスト半径の制限:徐々に信頼を築くために、私たちは新しいシステムを GraphQL API と UI のリポジトリ用の Issues タブのみに統合して開始しました。これにより、すべてのユーザーのエクスペリエンスを低下させるリスクを冒すことなく、フィードバックを収集し、対応し、取り入れる時間を得ることができました。そのパフォーマンスに満足したら、IssuesダッシュボードとREST APIに展開しました。
- 社内および信頼できるパートナーとのテストGitHubで開発するすべての機能と同様に、私たちはこの機能を開発期間中ずっと社内でテストし、初期のうちは私たちのチームにリリースし、その後徐々にGitHubの全従業員に展開していきました。その後、信頼できるパートナー企業にもリリースし、初期のユーザーフィードバックを集めました。
こうして、新しく改良されたIssues検索を作り、検証し、リリースしたのです!
フィードバック
このエキサイティングな新機能を試してみたいですか?ブーリアン演算子や 括弧を使って気になる課題を検索する方法については、ドキュメントをご覧ください!
この機能に関するフィードバックがありましたら、コミュニティ・ディスカッションにお寄せください。
謝辞
AJ Schuster、Riley Broughten、Stephanie Goldstein、Eric Jorgensen Mike Melanson、Laura Lindeman に感謝します!
This post GitHub Issues search now supports nested queries and boolean operators: Here’s how we (re)built it appeared first on The GitHub Blog.