高品質のコードでソフトウェア開発を加速しましょう。
GitHub Copilotはこちらから。

Author
私たちの最新の調査結果によると、GitHub Copilot を使って書かれたコードの品質は、機能性、可読性、信頼性、保守性、簡潔性が大幅に向上しています。
GitHub Copilotが一般提供開始されてから2年間で、AIはソフトウェア開発を根本的に変えました。その間に、GitHub Copilotは開発者のコーディング速度を最大55%向上させました。また事前の調査では、85%の開発者が自分のコードに自信を持ち、88%がGitHub Copilotを使用することでよりフロー状態になれていると感じていることが示されました。
しかし、疑問が残ります。GitHub Copilot を使って書かれたコードの品質は、客観的に見て良いのでしょうか、それとも悪いのでしょうか?
これに答えるため、GitHub Copilot を使って書かれたコードの機能性、読みやすさ、信頼性、保守性、簡潔さ、承認される可能性がどの程度あるのかを調べるランダム化比較試験を実施しました。
この研究では、少なくとも5年の経験を持つ202人の開発者を募集しました。半数にはGitHub Copilotへのアクセスをランダムに割り当て、残りの半数にはAIツールを使用しないよう指示しました。参加者は全員、ウェブサーバーのAPIエンドポイントを書くコーディング作業を完了するよう求められました。その後、単体テストと開発者による専門家レビューでコードを評価しました。
その結果、GitHub Copilotを使用して作成されたコードの品質は、機能性の向上、可読性の改善、品質の向上、承認率の向上が見られました。
私たちが発見したことを深く掘り下げてみましょう:
GitHub Copilotを使って書かれたコードは、より機能的でした
コードが機能しなければ、高品質とは言えません。そこで、機能性に注目し、コードがどれだけの単体テストをパスしたかを分析して測定しました。その結果、GitHub Copilot を使って作成されたコードは、有意に多くのテストをパスしていることがわかりました (p=0.002)。実際のところ、GitHub Copilotにアクセスした開発者は、この調査で10個の単体テストすべてに合格する可能性が56%高くなりました(p=0.04)。つまり、GitHub Copilotを使うことで、開発者はより機能的なコードを書くことができるのです。
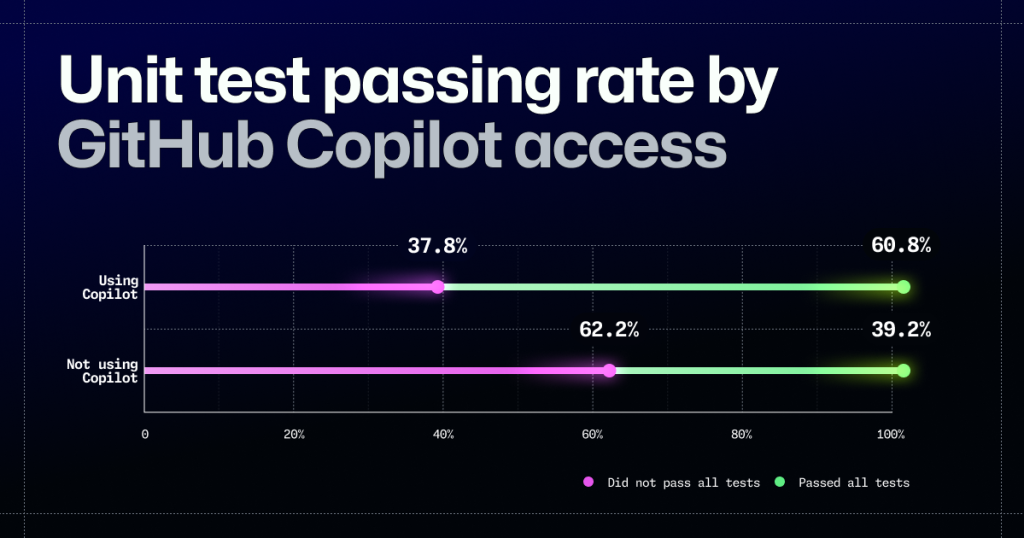
GitHub Copilotを使って書かれたコードは読みやすいと開発者は感じています
研究の最初のフェーズで10個の単体テストをすべてパスしたコードを作成した25人の開発者が、匿名で提出されたコード(GitHub Copilotを使ったものと使っていないもの)のブラインドレビューを行うようランダムに割り当てられました。レビュアーが発見したのは、GitHub Copilotを使用して作成されたコードには、コードの可読性エラーが少ないということでした。
開発者の行ごとのコードレビューを分析したところ、GitHub Copilot を使って書かれたコードでは、コードエラーが大幅に少ないことがわかりました。GitHub Copilot を使っている開発者は、コードエラー 1 件あたり 18.2 行のコードを書いていますが、使っていない場合は 16.0 行しか書いていません。これは、GitHub Copilotを使用した場合、コードエラーのないコード行数が平均で13.6%多いことに相当します(p=0.002)。これらのコードエラーはそれぞれ開発者のアクションを必要とするため、これは時間の節約につながります。例えば、GitHub Copilotを使用しない場合、チームは最大13%多くのコメントや提案に直面する可能性があり、これは時間の経過とともに蓄積されていきます。
| コードエラーの平均数 | 平均コード行数 | コードエラーあたりの平均コード行数 | 差分 | |
|---|---|---|---|---|
| GitHub Copilot を使用 | 4.63 | 84.3 | 18.2 | 13.6% |
| GitHub Copilotを利用していない | 5.35 | 85.7 | 16.0 | -11.9% |

さらに、開発者が発見した違いは、コード1行あたりのエラーだけにとどまりませんでした。GitHub Copilot を使って作成されたコードの方が、読みやすく、信頼性が高く、保守性が高く、 簡潔であると、1~3%評価されました(それぞれ、p=0.003, p=0.01, p=0.041, p=0.002)。これらの差は小さいものの、統計的に有意であり、より良いコードベースに貢献しています。
| 従属変数 | 平均差 | P値 |
|---|---|---|
| 可読性 | 3.62% | 0.003 |
| 信頼性 | 2.94% | 0.01 |
| 維持可能 | 2.47% | 0.041 |
| 簡潔 | 4.16% | 0.002 |

GitHub Copilot を使って作成されたコードは承認されやすい
最後に、GitHub Copilotを使って作成されたコードも、開発者が承認する確率が5%高いことがわかりました(p=0.014)。これは、GitHub Copilot を使っている開発者が、より早くマージできるコードを書いていることを意味します。

結論
では、GitHub Copilotがコードの品質をどのように向上させるかについて、これらの調査結果は何を示しているのでしょうか?GitHub Copilotグループでは、コミット数とコード変更行数が有意に多かったものの、平均コミットサイズはわずかに小さくなりました。これは、GitHub Copilotによって開発者がコードの品質を向上させるために反復作業を行えるようになったことを示唆しています。私たちの仮説では、開発者はコードを機能的にするために費やす時間が少なかったため、品質を向上させることに集中できたと考えられます。これは、開発者が GitHub Copilot を使用することに自信を感じているという前回の調査結果と一致します。また、GitHub Copilotによって自信が深まったことで、コードにエラーが発生することを恐れることなく、反復作業を行うことができるようになったと考えられます。
GitHub Copilotがコードの品質に与える影響を調べた初の管理研究として、GitHub Copilotが高品質のコードを書くのに役立つことが示されました。他の研究では、GitHub Copilot を使用してもコード品質の改善が見られなかった可能性があるという仮説を立てています。その理由は、ツール自体の問題ではなく、開発者が品質に重点的に取り組む機会や動機が不足していたためである可能性があります。このデータは、GitHub Copilot が強力な製品であり、開発者がより迅速にコーディングを行い、仕事の満足度を高めるのに役立つだけでなく、チームが迅速に動き、創造性と革新性を最大限に高めることを可能にするという、私たちのこれまでの研究結果を裏付けるものです。
GitHubカスタマーリサーチチームでは、10億人の開発者を抱えるGitHubを目指し、製品の有効性に関する新たな調査を常に行っています。
調査方法
研究の第一段階では、少なくとも5年のPython経験を持つ243人の開発者を募集し、GitHub Copilotを使用するグループと使用しないグループに無作為に振り分けられました。各グループは、架空のレストランレビューのWebサーバーのコーディング演習を行い、機能性を評価するための10個の単体テストを実施したところ、202人の開発者から有効な提出がありました:GitHub Copilotを使用したものが104人、使用しなかったものが98人です。
第二段階では、開発者は提供されたルーブリックを使用してレビューする投稿をランダムに割り当てられました。開発者は、コードが GitHub Copilot を使用して作成されたかどうかをブラインドで確認しました。各投稿は少なくとも10人の異なる参加者によってレビューされ、1,293件のレビューが行われました。開発者はルーブリックを使用して、コードの誤りを特定することに重点を置いた行ごとのレビューを行いました。また、可読性、信頼性、保守性、簡潔性、および投稿を承認すべきかどうかの総合的な評価も行いました。方法論に関するその他の質問については、press@github.comまでお問い合わせください。
コードエラーをどのように定義するか?
この研究では、容易に理解できないコードをコードエラーと定義しました。これには、コードが意図したとおりに動作することを妨げる機能的なエラーは含まれず、代わりに、不適切なコーディングプラクティスを表すエラーが含まれます。これらのコードエラーは、コードの可読性1およびコードの複雑さ2に関する学術文献から得られたものです。コード・エラーは、コードレビューの際に提供されたルーブリックで使用されました。それらは、一貫性のない命名、不明確な識別子、過剰な行の長さ、過剰な空白、欠落した文書、繰り返されるコード、過剰な分岐やループの深さ、不十分な機能分離、変数の複雑さなどです。
謝辞:本研究の設計と統計分析にご協力いただいたリジー・レッドフォード博士とシダ・ペン博士に感謝します。
ノート
- Raymond P.L. Buse and Westley R. Weimer. 2008. A metric for software readability. In Proceedings of the 2008 international symposium on Software testing and analysis (ISSTA ’08). Association for Computing Machinery, New York, NY, USA, 121–130. https://doi.org/10.1145/1390630.1390647
-
D. Beyer and A. Fararooy, “A Simple and Effective Measure for Complex Low-Level Dependencies,” 2010 IEEE 18th International Conference on Program Comprehension, Braga, Portugal, 2010, pp. 80-83, doi: 10.1109/ICPC.2010.49.
keywords: {Software measurement;Lab-on-a-chip;Size measurement;Length measurement;Application software;Software systems;Frequency;Stability;Guidelines;Program processors;Software Measure;Dependency Analysis;Refactoring;Program Understanding},
The post Does GitHub Copilot improve code quality? Here’s what the data says appeared first on The GitHub Blog.