Highlights from Git 2.38
Another new release of Git is here! Take a look at some of our highlights on what’s new in Git 2.38.

The open source Git project just released Git 2.38, with features and bug fixes from over 92 contributors, 24 of them new. We last caught up with you on the latest in Git back when 2.37 was released.
To celebrate this most recent release, here’s GitHub’s look at some of the most interesting features and changes introduced since last time.
A repository management tool for large repositories
We talk a lot about performance in Git, especially in the context of large repositories. Returning readers of these blog posts will no doubt be familiar with the dozens of performance optimizations that have landed in Git over the years.
But with so many features to keep track of, it can be easy to miss out some every now and then (along with their corresponding performance gains).
Git’s new built-in repository management tool, Scalar, attempts to solve that problem by curating and configuring a uniform set of features with the biggest impact on large repositories. To start using it, you can either clone a new repository with scalar clone:
$ scalar clone /path/to/repo
Or, you can use the --full-clone option if you don’t want to start out with a sparse checkout. To apply Scalar’s recommended configuration to a clone you already have, you can instead run:
$ cd /path/to/repo
$ scalar register
At the time of writing, Scalar’s default configured features include:
- Built-in filesystem monitor
- Multi-pack index
- Commit graphs
- Scheduled background maintenance
- Partial cloning
- Cone mode sparse-checkout
Scalar’s configuration is updated as new (even experimental!) features are introduced to Git. To make sure you’re always using the latest and greatest, be sure to run scalar reconfigure /path/to/repo after a new release to update your repository’s config (or scalar reconfigure -a to update all of your Scalar-registered repositories at once).
Git 2.38 is the first time Scalar has been included in the release, but it has actually existed for much longer. Check back soon for a blog post on how Scalar came to be—from its early days as a standalone .NET application to its journey into core Git!
[source]
Rebase dependent branches with –update-refs
When working on a large feature, it’s often helpful to break up the work across multiple branches that build on each other.
But these branches can become cumbersome to manage when you need to rewrite history in an earlier branch. Since each branch depends on the previous ones, rewriting commits in one branch will leave the subsequent branches disconnected from history after rewriting.
In case that didn’t quite make sense, let’s walk through an example.
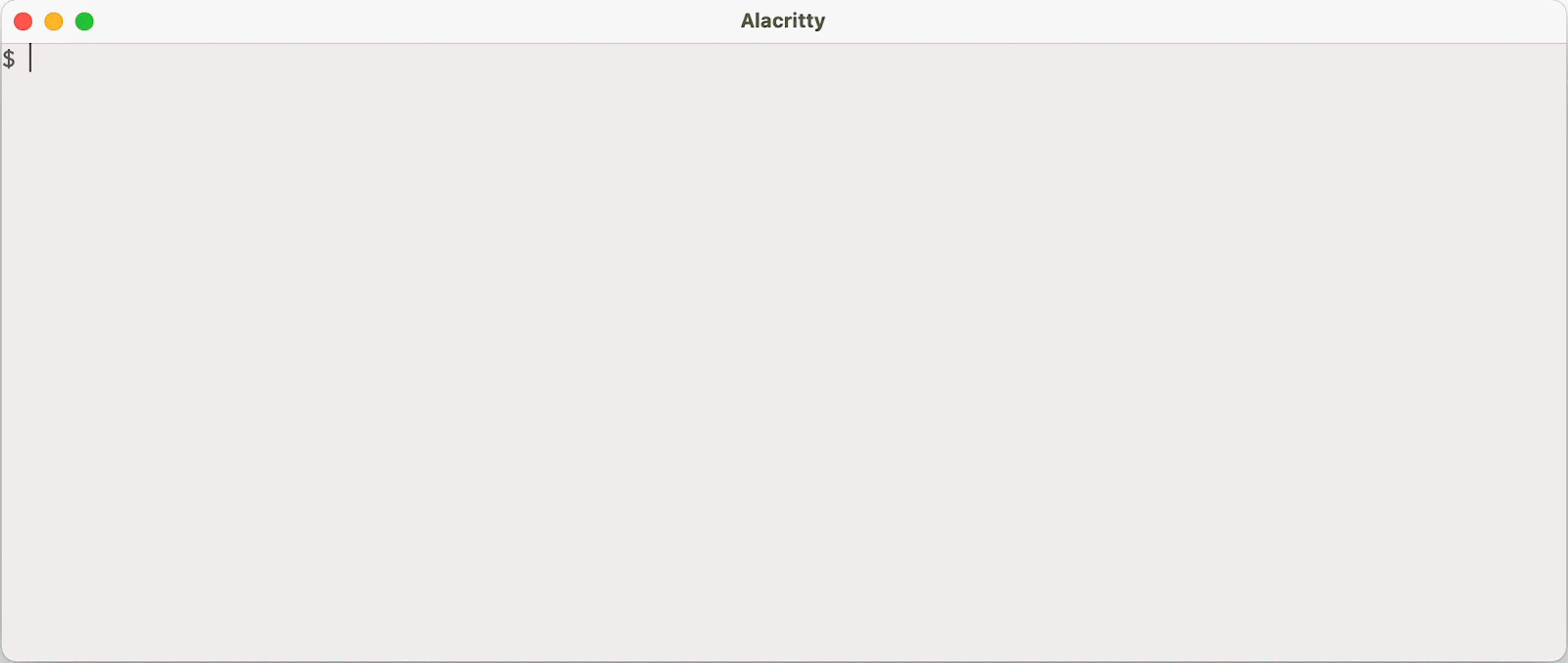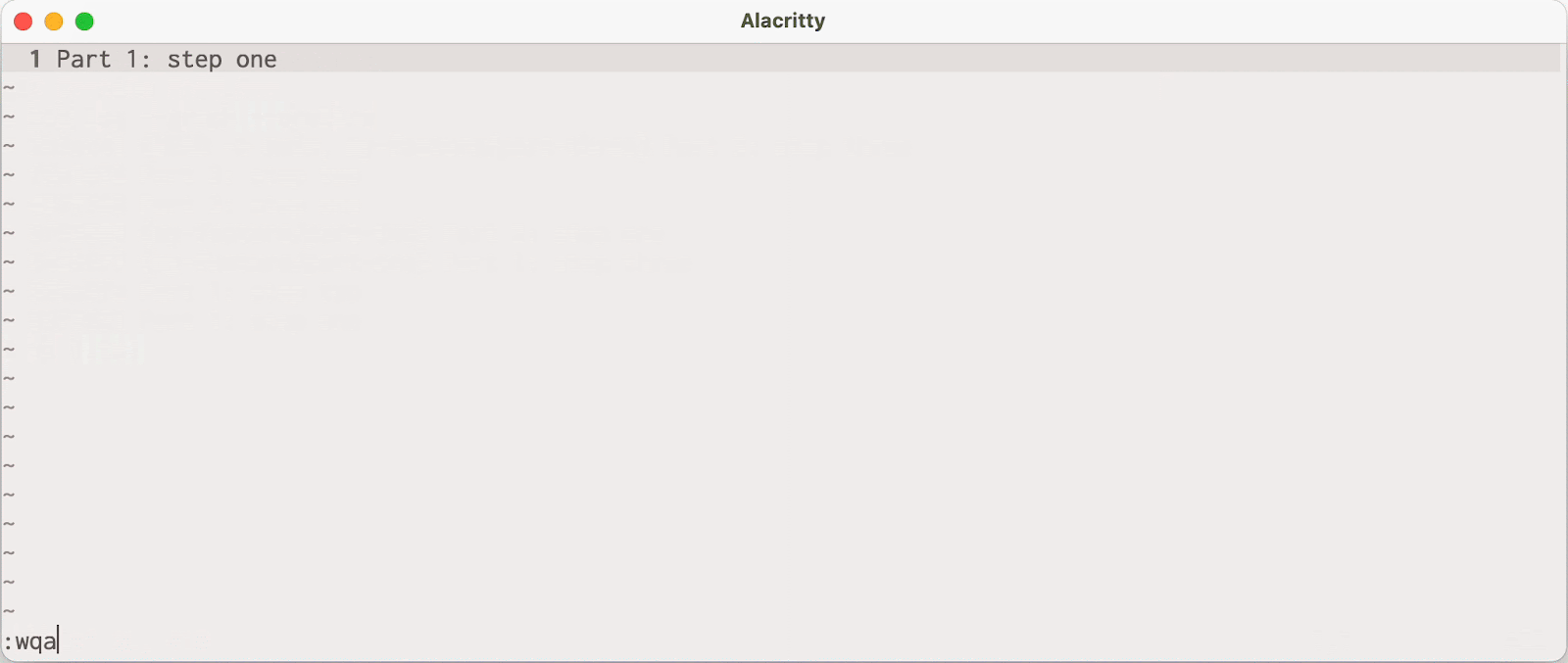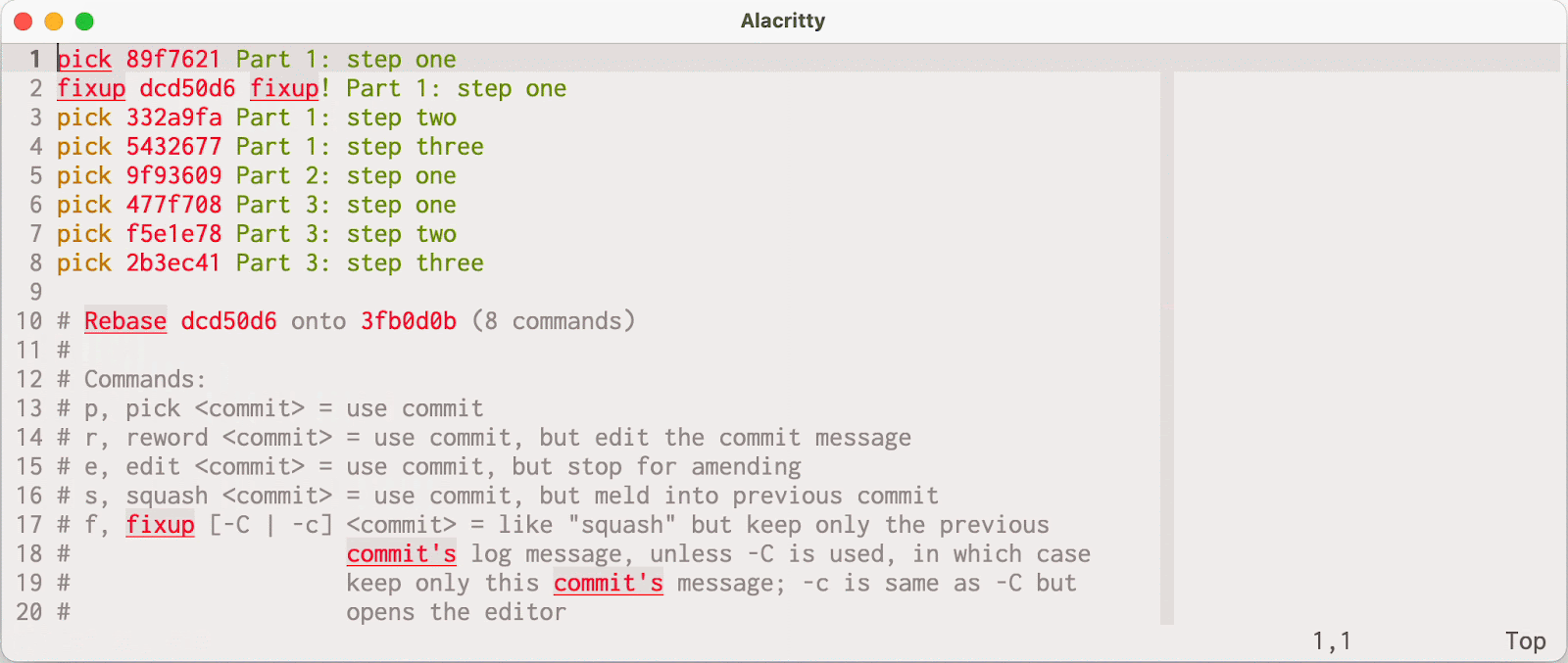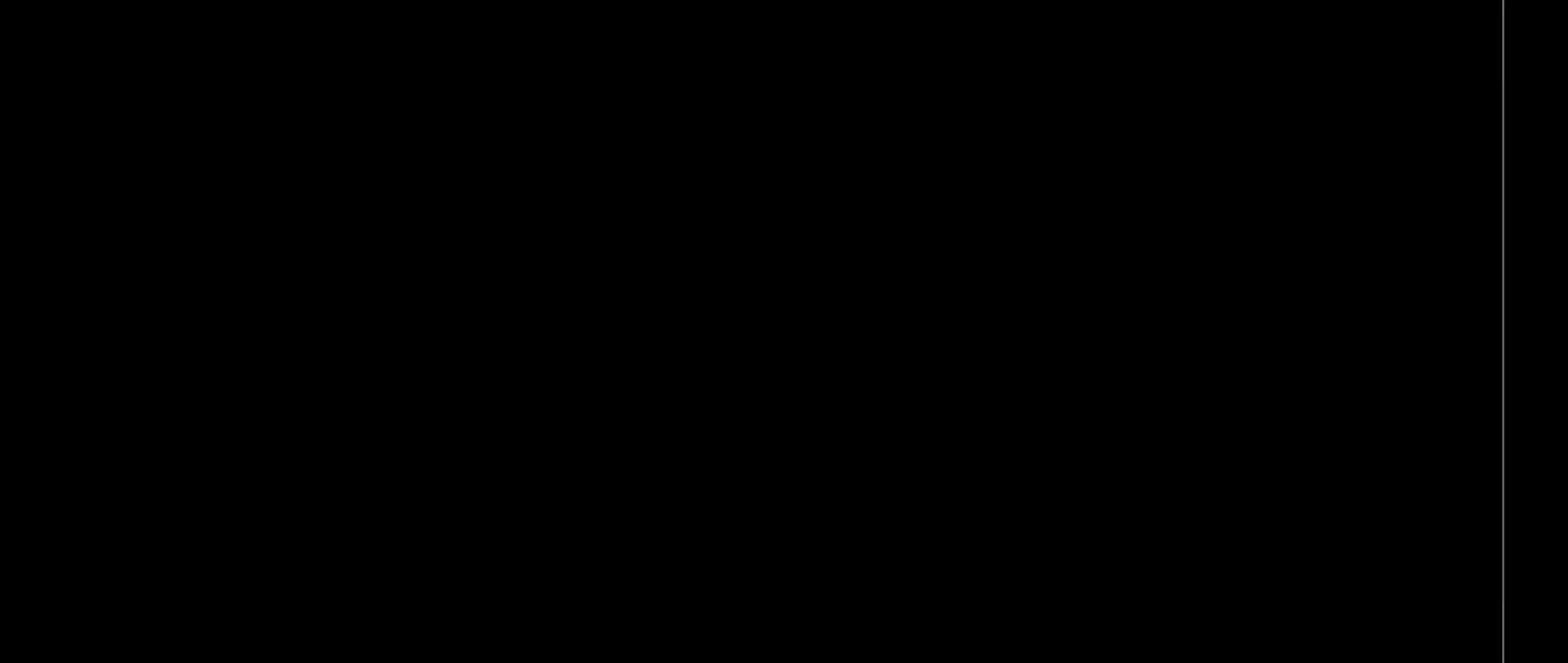
Suppose that you are working on a feature (my-feature), but want to break it down into a few distinct parts (maybe for ease of review, or to ensure you’re deploying it safely, etc.). Before you share your work with your colleagues, you build the entire feature up front to make sure that the end-result is feasible, like so.
$ git log --oneline origin/main..HEAD
741a3174683 (HEAD -> my-feature/part-three) Part 3: all done!
1ff073007eb Part 3: step two
880c07e326f Part 3: step one
40529bd11dc (my-feature/part-two) Part 2: step two
0a92cc3acd8 Part 2: step one
eed018043ba (my-feature/part-one) Part 1: step three
646c870d69e Part 1: step two
9147f6d2eb4 Part 1: step one
In the example below, the my-feature/part-three branch resembles what you imagine the final state will look like. But the intermediate check-points (my-feature/part-one, and so on) represent the chunks you intend to submit for code review.
After you submit everything, what happens if you want to make a change to one of the patches in part one?
You might create a fixup! commit on top, but squashing that patch into the one you wanted to change from part one will cause parts two and three to become disconnected:
Notice that after we squashed our fix into “Part 1: step one,” the subsequent branches vanished from history. That’s because they didn’t get updated to depend on the updated tip of my-feature/part-one after rebasing.
You could go through and manually checkout each branch, resetting each to the right commit. But this can get cumbersome quickly if you have a lot of branches, are making frequent changes, or both.
Git 2.38 ships with a new option to git rebase called --update-refs that knows how to perform these updates for you. Let’s try that same example again with the new version of Git.

Because we used --update-refs, git rebase knew to update our dependent branches, so our history remains intact without having to manually update each individual branch.
If you want to use this option every time you rebase, you can run git config --global rebase.updateRefs true to have Git act as if the --update-refs option is always given.
[source]
Tidbits
This release coincides with the Git project’s participation in the annual Google Summer of Code program. This year, the Git project mentored two students, Shaoxuan Yuan, and Abhradeep Chakraborty, working on sparse index integration and various improvements to reachability bitmaps, respectively.
- Shaoxuan’s first contribution was integrating the
git rmcommand with the sparse index. The sparse index is a relatively new Git feature that enables Git to shrink the size of its index data structure to only track the contents of your sparse checkout, instead of the entire repository. Long-time readers will remember that Git commands have been converted to be compatible with the sparse-index one-by-one. Commands that aren’t compatible with the sparse index need to temporarily expand the index to cover the entire repository, leading to slow-downs when working in a large repository.Shaoxuan’s work made the
git rmcommand compatible with the sparse index, causing it to only expand the index when necessary, bringing Git closer to having all commands be compatible with the sparse index by default.[source]
-
Shaoxuan also worked on improving
git mv‘s behavior when moving a path from within the sparse checkout definition (sometimes called a “cone”) to outside of the sparse checkout. There were a number of corner cases that required careful reasoning, and curious readers can learn more about exactly how this was implemented in the patches linked below.[source]
-
Abhradeep worked on adding a new “lookup table” extension to Git’s reachability bitmap index. For those unfamiliar, this index (stored in a
.bitmapfile) associates a set of commits to a set of bitmaps, where each bit position corresponds to an object. A1bit indicates that a commit can reach the object specified by that bit position, and a0indicates that it cannot.But
.bitmapfiles do not list their selected commits in a single location. Instead, they prefix each bitmap with the object ID of the commit it corresponds to. That means that in order to know what set of commits are covered by a.bitmap, Git must read the entire contents of the file to discover the set of bitmapped commits.Abhradeep addressed this shortcoming by adding an optional “lookup table” at the end of the .bitmap format, which provides a concise list of selected commits, as well as the offset of their corresponding bitmaps within the file. This provided some speed-ups across a handful of benchmarks, making bitmaps faster to load and use, especially for large repositories.
[source]
-
Abhradeep also worked on sprucing up the technical documentation for the .bitmap format. So if you have ever been curious about or want to hack on Git’s bitmap internals, now is the time!
[source]
For more about these projects, you can check out each contributor’s final blog posts here and here. Thank you, Shaoxuan, and Abhradeep!
Now that we’ve covered a handful of changes contributed by Google Summer of Code students, let’s take a look at some changes in this release of Git from other Git contributors.
- You may not be familiar with Git’s
merge-treecommand, which historically was used to compute trivial three-way merges using Git’s recursive merge strategy. In Git 2.38, this command now knows how to integrate with the new ort merge strategy, allowing it to compute non-trivial merges without touching the index or working copy.The existing mode is still available behind a (deprecated)
--trivial-mergeoption. When the new--write-treemode is used,merge-treetakes two branches to merge, and computes the result using the ort strategy, all without touching the working copy or index. It outputs the resulting tree’s object ID, along with some information about any conflicts it encountered.As an aside, we at GitHub recently started using
merge-ortto compute merges on GitHub.com more than an order of magnitude faster than before. We had previously used the implementation in libgit2 in order to compute merges without requiring a worktree, since GitHub stores repositories as bare, meaning we do not have a worktree to rely on. These changes will make their way to GitHub Enterprise beginning with verion 3.7.[source]
-
Bare Git repositories can be stored in and distributed with other Git repositories. This is often convenient, for example, as an easy mechanism to distribute Git repositories for use as test fixtures.
When using repositories from less-than-trustworthy sources, this can also present a security risk. Git repositories often execute user-defined programs specified via the
$GIT_DIR/configfile. For example,core.pagerdefines which pager program Git uses, andcore.editordefines which editor Git opens when you want to write a commit message (among other things).There are other examples, but an often-discussed one is the core.fsmonitor configuration, which can be used to specify a path to a filesystem monitoring hook. Because Git often needs to query the state of the filesystem, this hook (when configured) is invoked many times, including from
git status, which people commonly script around in their shell prompt.This means that it’s possible to convince a victim to run arbitrary code by convincing them to clone a repository with a malicious bare repository embedded inside of it. If they change their working directory into the malicious repository within (since you cannot embed a bare repository at the top-level directory of a repository) and run some Git command, then they are likely to execute the script specified by core.fsmonitor (or any other configuration that specifies a command to execute).
For this reason, the new
safe.bareRepositoryconfiguration was introduced. When set to “explicit,” Git will only work with bare repositories specified by the top-level--git-dirargument. Otherwise, when set to “all” (which is the default), Git will continue to work with all bare repositories, embedded or not.It is worth noting that setting
safe.bareRepositoryto “explicit” is only required if you worry that you may be cloning malicious repositories and executing Git commands in them.[source]
-
git greplearned a new-moption (short for--max-count), which behaves like GNUgrep‘s options of the same name. This new option limits the number of matches shown per file. This can be especially useful when combined with other options, like-Cor-p(which show code context, or the name of the function which contains each match).You could, for example, combine all three of these options to show a summary of how some function is called by many different files in your project. Git has a handful of objects that contain the substring
oid_object_info. If you want to look at how callers across different files are structured without seeing more than one example from the same file, you can now run:$ git grep -C3 -p -m1 oid_object_info[source]
-
If you’ve ever scripted around the directory contents of your Git repository, there’s no doubt that you’ve encountered the
git ls-filescommand. Unlikels-tree(which lists the contents of a tree object),ls-fileslists the contents of the index, the working directory, or both.There are already lots of options which can further specify what does or doesn’t get printed in
ls-files‘s output. But its output was not easily customizable without additional scripting.In Git 2.38, that is no longer the case, with
ls-files‘s new--formatoption. You can now customize how each entry is printed, with fields to print an object’s name and mode, as well as more esoteric options, like its stage in the index, or end-of-line (EOL) behavior.[source]
-
git cat-filealso learned a new option to respect the mailmap when printing the contents of objects with identifiers in them. This feature was contributed by another Google Summer of Code student, this time working on behalf of GitLab!For the uninitiated, the mailmap is a feature which allows mapping name and email pairs to their canonical values, which can be useful if you change your name or email and want to retain authorship over historical commits without rewriting history.
git show, and many other tools already understand how to remap identities under the mailmap (for example,git show‘s%aNand%aEformat placeholders print the mailmapped author name and email, respectively, as opposed to%anand%ae, which don’t respect the mailmap). Butgit cat-file, which is a low-level command which prints the contents of objects, did not know how to perform this conversion.That meant that if you wanted to print a stream of objects, but transform any author, committer, or tagger identities according to the mailmap, you would have to pipe their contents through git show or similar. This is no longer the case, since git cat-file now understands the
--[no]-use-mailmapoption, meaning this transformation can be done before printing out object contents.[source]
-
Finally, Git’s developer documentation got an improvement in this most recent release, by adding a codified version of the Git community’s guidelines for code review. This document is a helpful resource for new and existing contributors to learn about the cultural norms around reviewing patches on the Git mailing list.
If you’ve ever had the itch to contribute to the Git project, I highly encourage you to read the new reviewing guidelines (as well as the coding guidelines, and the “My First Contribution” document) and get started!
[source]
The rest of the iceberg
That’s just a sample of changes from the latest release. For more, check out the release notes for 2.38, or any previous version in the Git repository.
Tags:
Written by

Related posts
Welcome to Maintainer Month: Celebrating the people behind the code
What maintainers are telling us, what we’ve shipped, and how to celebrate the people behind open source.

Register now for OpenClaw: After Hours @ GitHub
OpenClaw builders will gather at GitHub HQ during Microsoft Build 2026 for demos and conversations. Join in person, or watch the livestream on Twitch.

Highlights from Git 2.54
The open source Git project just released Git 2.54. Here is GitHub’s look at some of the most interesting features and changes introduced since last time.