Git’s database internals II: commit history queries
This post explores Git commit history as a database where ‘git log’ is the query language. Learn about Git’s custom query index – the commit-graph file – and how to make sure it’s enabled in your repositories.

This week, we are exploring Git’s internals with the following concept in mind:
Git is the distributed database at the core of your engineering system.
Git’s role as a version control system has multiple purposes. One is to help your team make collaborative changes to a common repository. Another purpose is to allow individuals to search and investigate the history of the repository. These history investigations form an interesting query type when thinking of Git as a database.
Not only are history queries an interesting query type, but Git commit history presents interesting data shapes that inform how Git’s algorithms satisfy those queries.
Let’s dig into some common history queries now.
Git history queries
History queries can take several forms. For this post, we are focused only on history queries based entirely on the commits themselves. In part III we will explore file history queries.
Recent commits
Users most frequently interact with commit history using git log to see the latest changes in the current branch. git log shows the commit history which relies on starting at some known commits and then visiting their parent commits and continuing to “walk” parent relationships until all interesting commits are shown to the user. This command can be modified to compare the commits in different branches or display commits in a graphical visualization.
$ git log --oneline --graph 091680472db
* 091680472db Merge branch 'tb/midx-race-in-pack-objects'
|\
| * 4090511e408 builtin/pack-objects.c: ensure pack validity from MIDX bitmap objects
| * 5045759de85 builtin/pack-objects.c: ensure included `--stdin-packs` exist
| * 58a6abb7bae builtin/pack-objects.c: avoid redundant NULL check
| * 44f9fd64967 pack-bitmap.c: check preferred pack validity when opening MIDX bitmap
* | d8c8dccbaaf Merge branch 'ds/object-file-unpack-loose-header-fix'
|\ \
| * | 8a50571a0ea object-file: convert 'switch' back to 'if'
* | | a9e7c3a6efe Merge branch 'pb/use-freebsd-12.3-in-cirrus-ci'
|\ \ \
| * | | c58bebd4c67 ci: update Cirrus-CI image to FreeBSD 12.3
| | |/
| |/|
* | | b3b2ddced29 Merge branch 'ds/bundle-uri'
|\ \ \
| * | | 89c6e450fe4 bundle.h: make "fd" version of read_bundle_header() public
| * | | 834e3520ab6 remote: allow relative_url() to return an absolute url
Containment queries
We sometimes also need to get extra information about our commit history, such as asking “which tags contain this commit?” The git tag --contains command is one way to answer that question.
$ git tag --contains 4ae3003ba5
v2.36.0
v2.36.0-rc0
v2.36.0-rc1
v2.36.0-rc2
v2.36.1
v2.37.0
v2.37.0-rc0
v2.37.0-rc1
v2.37.0-rc2
The similar git branch --contains command will report all branches that can reach a given commit. These queries can be extremely valuable. For example, they can help identify which versions of a product have a given bugfix.
Merge base queries
When creating a merge commit, Git uses a three-way merge algorithm to automatically resolve the differences between the two independent commits being merged. As the name implies, a third commit is required: a merge base.
A merge base between two commits is a commit that is in the history of both commits. Technically, any commit in their common history is sufficient, but the three-way merge algorithm works better if the difference between the merge base and each side of the merge is as small as possible.
Git tries to select a single merge base that is not reachable from any other potential merge base. While this choice is usually unique, certain commit histories can permit multiple “best” merge bases, in which case Git prints all of them.
The git merge-base command takes two commits and outputs the object ID of the merge base commit that satisfies all of the properties described earlier.
$ git merge-base 3d8e3dc4fc d02cc45c7a
3d8e3dc4fc22fe41f8ee1184f085c600f35ec76f
One thing that can help to visualize merge commits is to explore the boundary between two commit histories. When considering the commit range B..A, a commit C is on the boundary if it is reachable from both A and B and there is at least one commit that is reachable from A and not reachable from B and has C as its parent. In this way, the boundary commits are the commits in the common history that are parents of something in the symmetric difference. There are a number of commits on the boundary of these two example commits, but one of them can reach all of the others providing the unique choice in merge base.
$ git log --graph --oneline --boundary 3d8e3dc4fc..d02cc45c7a
* d02cc45c7a2c Merge branch 'mt/pkt-line-comment-tweak'
|\
| * ce5f07983d18 pkt-line.h: move comment closer to the associated code
* | acdb1e1053c5 Merge branch 'mt/checkout-count-fix'
|\ \
| * | 611c7785e8e2 checkout: fix two bugs on the final count of updated entries
| * | 11d14dee4379 checkout: show bug about failed entries being included in final report
| * | ed602c3f448c checkout: document bug where delayed checkout counts entries twice
* | | f0f9a033ed3c Merge branch 'cl/rerere-train-with-no-sign'
|\ \ \
| * | | cc391fc88663 contrib/rerere-train: avoid useless gpg sign in training
| o | | bbea4dcf42b2 Git 2.37.1
| / /
o / / 3d8e3dc4fc22 Merge branch 'ds/rebase-update-ref' <--- Merge Base
/ /
o / e4a4b31577c7 Git 2.37
/
o 359da658ae32 Git 2.35.4
These simple examples are only a start to the kind of information Git uses from a repository’s commit history. We will discuss some of the important ways the structure of commits can be used to accelerate these queries.
The commit graph
Git stores snapshots of the repository as commits and each commit stores the following information:
- The object ID for the tree representing the root of the worktree at this point in time.
- The object IDs for any number of parent commits representing the previous points in time leading to this commit. We use different names for commits based on their parent count:
- Zero parents: these commits are the starting point for the history and are called root commits.
- One parent: these are typical commits that modify the repository with respect to the single parent. These commits are frequently referred to as patches, since their differences can be communicated in patch format using
git format-patch. - Two parents: these commits are called merges because they combine two independent commits into a common history.
- Three or more parents: these commits are called _octopus merges_since they combine an arbitrary number of independent commits.
- Name and email information for the author and committer, which can be different.
- Time information for the author time and committer time, which can be different.
- A commit message, which represents additional metadata. This information is mostly intended for human consumption, so you should write it carefully. Some carefully-formatted trailer lines in the message can be useful for automation. One such trailer is the
Co-authored-by:trailer which allows having multiple authors of a single commit.
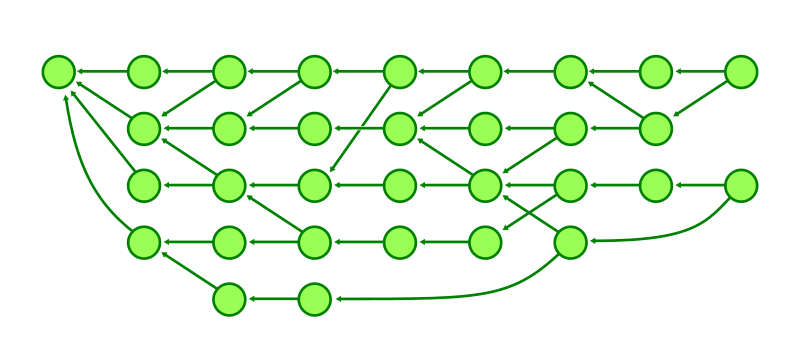
The commit graph is the directed graph whose vertices are the commits in the repository and where a commit has a directed edge to each of its parents. With this representation in mind, we can visualize the commit history as dots and arrows.
Graph databases need not apply
There are a number of graph databases that store general-purpose graph relationships. While it would be possible to store commits, trees, and blobs in such a database, those databases are instead designed for queries of limited-depth. They expect to walk only a few relationships, and maybe there are many relationships from a single node.
When considering general-purpose graph databases, think about social networks. Think about the concept of six degrees of separation and how almost every node is reachable within a short distance. In these graphs, the number of relationships at a given node can vary wildly. Further, the relationships are mainly unordered.
Git is not like that. It is rare to refer to a commit directly by its object ID. Instead Git commands focus on the current set of references. The references are much smaller in number than the total number of commits, and we might need to walk thousands of commit-parent edges before satisfying even the simplest queries.
Git also cares about the order of the parent relationships. When a merge commit is created, the parents are ordered. The first parent has a special role here. The convention is that the first parent is the previous value of the branch being updated by the merge operation. If you use pull requests to update a branch, then you can use git log --first-parent to show the list of merge commits created by that pull request.
$ git log --oneline --first-parent
2d79a03 Merge pull request #797 from ldennington/ssl-cert-updates
e209b3d Merge pull request #790 from cornejom/gitlab-support-docs
b83bf02 Merge pull request #788 from ldennington/arm-fix
cf5a693 (tag: v2.0.785) Merge pull request #778 from GyroJoe/main
dd4fe47 Merge pull request #764 from timsu92/patch-1
428b40a Merge pull request #759 from GitCredentialManager/readme-update
0d6f1c8 (tag: v2.0.779) Merge pull request #754 from mjcheetham/bb-newui
a9d78c1 Merge pull request #756 from mjcheetham/win-manifest
Git’s query pattern is so different from general-purpose graph databases that we need to use specialized storage and algorithms suited to its use case.
Git’s commit-graph file
All of Git’s functionality can be done by loading each commit’s contents out of the object store, parsing its header to discover its parents, and then repeating that process for each commit we need to examine. This is fast enough for small repositories, but as the repository increases in size the overhead of parsing these plain-text files to get the graph relationships becomes too expensive. Even the fact that we need a binary search to locate the object within the packfile begins to add up.
Git’s solution is the commit-graph file. You can create one in your own repository using git commit-graph write --reachable, but likely you already get one through git gc --auto or through background maintenance.
The file acts as a query index by storing a structured version of the commit graph data, such as the parent relationships as well as the commit date and root tree information. This information is sufficient to satisfy the most expensive parts of most history queries. This avoids the expensive lookup and parsing of the commit messages from the object store except when a commit needs to be output to the user.
We can think about the commit-graph as a pair of database tables. The first table stores each commit with its object ID, root tree, date, and first two parents as the columns. A special value, -1, is used to indicate that there is no parent in that position, which is important for root commits and patches.
The vast majority of commits have at most two parents, so these two columns are sufficient. However, Git allows an arbitrary number of parents, forming octopus merges. If a commit has three or more parents, then the second parent column has a special bit indicating that it stores a row position in a second table of overflow edges. The remaining parents form a list starting at that row of the overflow edges table, each position stores the integer position of a parent. The list terminates with a parent listed along with a special bit.
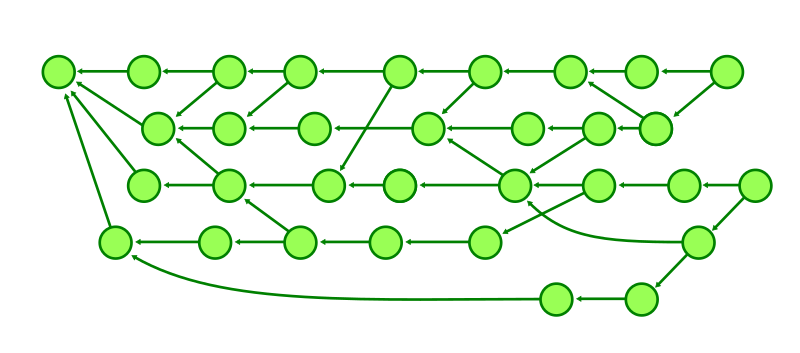
In the figure below, the commit at row 0 has a single parent that exists at row 2. The commit at row 4 is a merge whose second parent is at row 5. The commit at row 8 is an octopus merge with first parent at row 3 and the remaining parents come from the parents table: 2, 5, and 1.
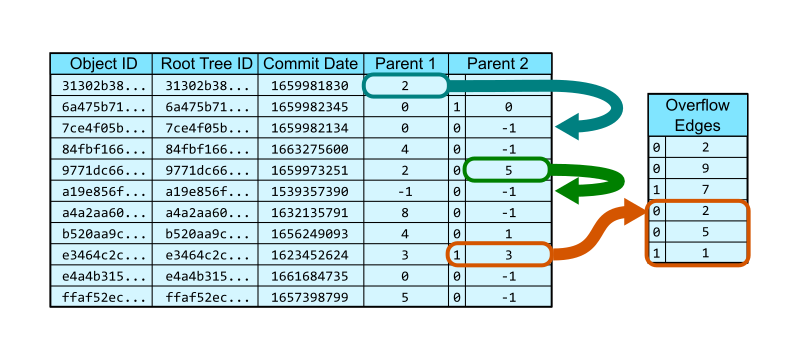
One important thing about the commit-graph file is that it is closed under reachability. That means that if a commit is in the file, then so is its parent. This means that a commit’s parents can be stored as row numbers instead of as full object IDs. This provides a constant-time lookup when traversing between a commit and its parent. It also compresses the commit-graph file since it only needs four bytes per parent.
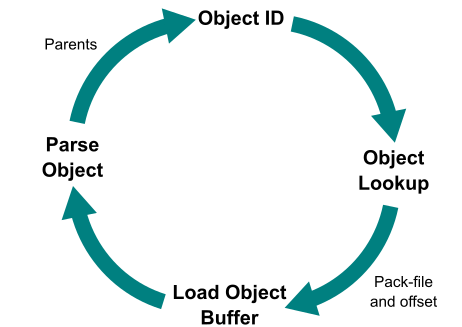
The structure of the commit-graph file speeds up commit history walks significantly, without any changes to the commit walk algorithms themselves. This is mainly due to the time it takes to visit a commit. Without the commit-graph file, we follow this pattern:
- Start with an Object ID.
- Do a lookup in the object store to see where that object is stored.
- Load the object content from the loose object or pack, decompressing the data from disk.
- Parse that object file looking for the parent object IDs.
This loop is visualized below.
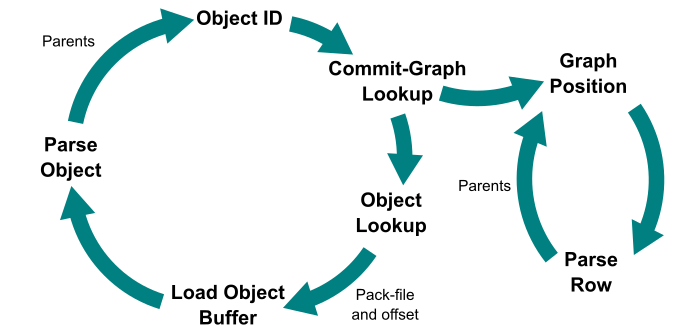
When a commit-graph file exists, we have a way to eject out of this loop and into a much tighter loop. We add an extra step before doing a generic object lookup in the object store: use a binary search to find that object ID in the commit-graph file. This operation is logarithmic in the number of commits, not in the total number of objects in the repository. If the commit-graph does not have that commit, then continue in the old loop. Check the commit-graph each time so we can eventually find a commit and its position in the commit-graph file.
Once we have a commit in the commit-graph file, we can navigate immediately to the row that stores that commit’s information, then load the parent commits by their position. This means that we can lookup the parents in constant time without doing any binary search! This loop is visualized below.
This reduced data footprint makes it clear that we can speed up certain queries on the basis of parsing speed alone. The git rev-list command is great for showing this because it prints the object IDs of the commits and not the commit messages. Thus, we can test how long it takes to walk the full commit graph with and without the commit-graph file.
The Linux kernel repository is an excellent candidate for testing these queries, since it is publicly available and has over a million commits. You can replicate these tests by writing a commit-graph file and toggling the core.commitGraph config setting.
| Command | Without commit-graph |
With commit-graph |
git rev-list v5.19 |
6.94s | 0.98s |
git rev-list v5.0..v5.19 |
2.51s | 0.30s |
git merge-base v5.0 v5.19 |
2.59s | 0.24s |
Avoiding the expensive commit parsing results in a nice constant factor speedup (about 6x in these examples), but we need something more to get even better performance out of certain queries.
Reachability indexes
One of the most important questions we ask about commits is “can commit A reach commit B?” If we can answer that question quickly, then commands such as git tag --contains and git branch --contains become very fast.
Providing a positive answer can be very difficult, and most times we actually want to traverse the full path from A to B, so there is not too much value in that answer. However, we can learn a lot from the opposite answer when we can be sure that A cannot reach B.
The commit-graph file provides a location for adding new information to our commits that do not exist in the commit object format by default. The new information that we store is called a generation number. There are multiple ways to compute a generation number, but the most important property we need to guarantee is the following:
If the generation number of a commit A is less than the generation number of a commit B, then A cannot reach B.
In this way, generation numbers form a negative reachability index in that they can help us determine that some commits definitely cannot reach some other set of commits.
The simplest generation number is called topological level and it is defined this way:
- If a commit has no parents, then its topological level is 1.
- Otherwise, the topological level of a commit is one more than the maximum of the topological level of its parents.
Our earlier commit graph figure was already organized by topological level, but here it is shown with those levels marked by dashed lines.
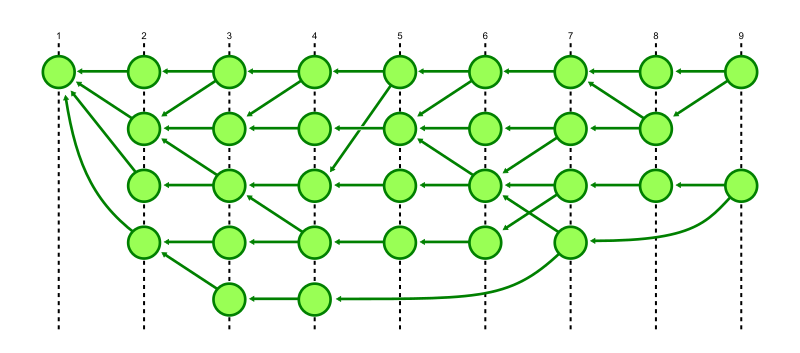
The topological level satisfies the property of a generation number because every commit has topological level strictly larger than its parents, which implies that everything that commit can reach has strictly smaller topological level. Conversely, if something has larger topological level, then it is not reachable from that commit.
You may have noticed that I did not mention what is implied when two commits have the same generation number. While we could surmise that equal topological level implies that neither commit can reach the other, it is helpful to leave equality as an unknown state. This is because commits that are in the repository but have not yet been added to the commit-graph file do not have a precomputed generation number. Internally, Git treats these commits as having generation number infinity which is larger than all of the precomputed generation numbers in the commit-graph. However, Git can do nothing when two commits with generation number infinity are compared. Instead of special-casing these commits, Git does not assume anything about equal generation number.
Stopping walks short with generation numbers
Let’s explore how we can use generation numbers to speed up commit history queries. The first category to explore are reachability queries, such as:
git tag --contains <b>returns the list of tags that can reach the commit<b>.git merge-base --is-ancestor <b> <a>returns an exit code of 0 if and only if<b>is an ancestor of<a>(<b>is reachable from<a>)
Both of these queries seek to find paths to a given point <b>. The natural algorithm is to start walking and report success if we ever discover the commit <b>. However, this might lead to walking every single commit before determining that we cannot in fact reach <b>. Before generation numbers, the best approach was to use a breadth-first search using commit date as a heuristic for walking the most recent commits first. This minimized the number of commits to walk in the case that we did eventually find <b>, but does not help at all if we cannot find <b>.
With generation numbers, we can gain two new enhancements to this search.
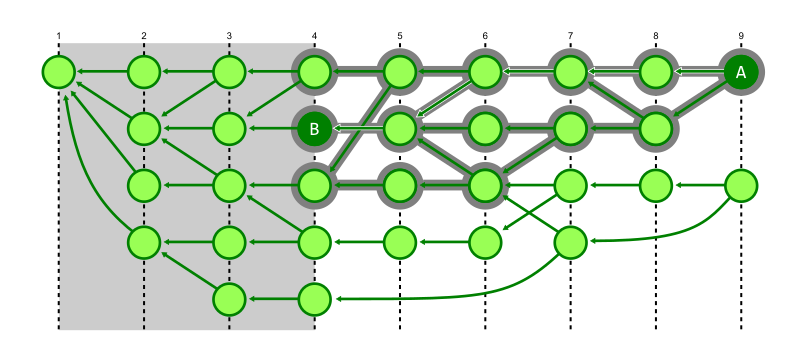
The first enhancement is that we can stop exploring a commit if its generation number is below the generation number of our target commit. Those commits of smaller generation could never contribute to a path to the target, so avoid walking them. This is particularly helpful if the target commit is very recent, since that cuts out a huge amount of commits from the search space.
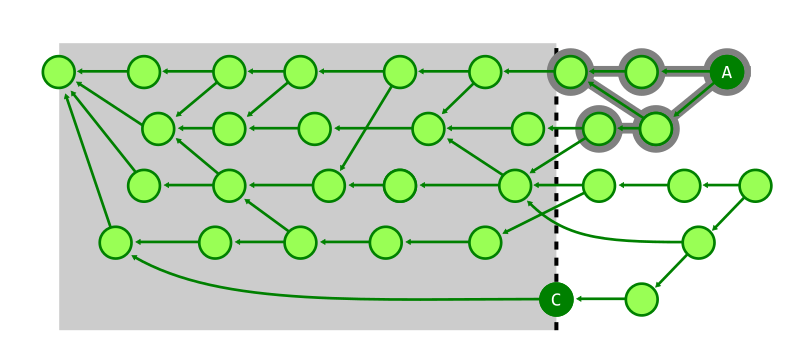
In the figure below, we discover that commit A can reach commit B, but we explored every reachable commit with higher generation. We know that we do not need to explore below generation number 4.
The second enhancement is that we can switch from breadth-first search to a depth-first search. This heuristic exploits some structure about typical repositories. The first parent of a commit is typically special, representing the previous value of the branch before the merge. The later parents are typically small topic branches merging a few new commits into the trunk of the repository. By walking the first parent history, we can navigate quickly to the generation number cutoff where the target commit is likely to be. As we backtrack from that cutoff, we are likely to find the merge commit that introduced the target commit sooner than if we had walked all recent commits first.
In the figure below, we demonstrate the same reachability query from commit A to commit B, where Git avoids walking below generation 4, but the depth-first search also prevents visiting a number of commits that were marked as visited in the previous figure.
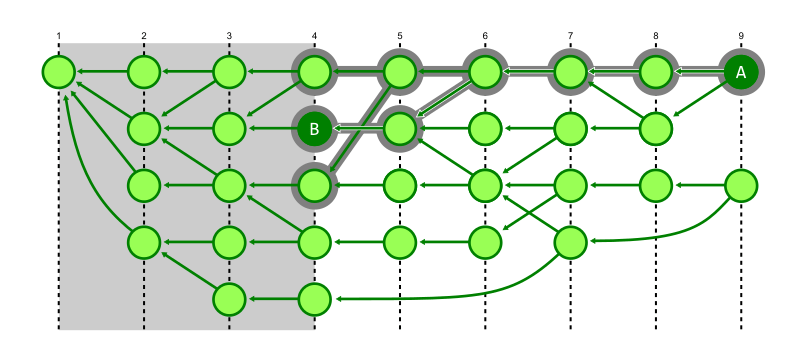
Note that this depth-first search approach is less efficient if we do not have the first generation number cutoff optimization, because the walk would spend most of its time exploring very old commits.
These two walks together can introduce dramatic improvements to our reachability queries.
| Command | Without commit-graph |
With commit-graph |
git tag --contains v5.19~100 |
7.34s | 0.04s |
git merge-base --is-ancestor v5.0 v5.19 |
2.64s | 0.02s |
Note that since git tag --contains is checking reachability starting at every tag, it needs to walk the entire commit history even from old tags in order to be sure they cannot reach the target commit. With generation numbers, the cutoff saves Git from even starting a walk from those old tags. The git merge-base --is-ancestor command is faster even without generation numbers because it can terminate early once the target commit is found.
However, with the commit-graph file and generation numbers, both commands benefit from the depth-first search as the target commit is on the first-parent history from the starting points.
If you’re interested to read the code for this depth-first search in the Git codebase, then read the can_all_from_reach_with_flags() method which is a very general form of the walk. Take a look at how it is used by other callers such as repo_is_descendant_of() and notice how the presence of generation numbers determines which algorithm to use.
Topological sorting
Generation numbers can help other queries where it is less obvious that a reachability index would help. Specifically, git log --graph displays all reachable commits, but uses a special ordering to help the graphical visualization.
git log --graph uses a sorting algorithm called topological sort to present the commits in a pleasing order. This ordering has one hard requirement and one soft requirement.
The hard requirement is that every commit appears before its parents. This is not guaranteed by default in git log, since the default sort uses commit dates as a heuristic during the walk. Commit dates could be skewed and a commit could appear after one of its parents because of date skew.
The soft requirement is that commits are grouped together in an interesting way. When git log --graph shows a merge commit, it shows the commits “introduced” by the merge before showing the first parent. This means that the second parent is shown first followed by all of the commits it can reach that the first parent cannot reach. Typically, this will look like the commits from the topic branch that were merged in that pull request. We can see how this works with the following example from the git/git repository.
$ git log --oneline --graph -n 10 091680472db
* 091680472d Merge branch 'tb/midx-race-in-pack-objects'
|\
| * 4090511e40 builtin/pack-objects.c: ensure pack validity from MIDX bitmap objects
| * 5045759de8 builtin/pack-objects.c: ensure included `--stdin-packs` exist
| * 58a6abb7ba builtin/pack-objects.c: avoid redundant NULL check
| * 44f9fd6496 pack-bitmap.c: check preferred pack validity when opening MIDX bitmap
* | d8c8dccbaa Merge branch 'ds/object-file-unpack-loose-header-fix'
|\ \
| * | 8a50571a0e object-file: convert 'switch' back to 'if'
* | | a9e7c3a6ef Merge branch 'pb/use-freebsd-12.3-in-cirrus-ci'
|\ \ \
| * | | c58bebd4c6 ci: update Cirrus-CI image to FreeBSD 12.3
| | |/
| |/|
* | | b3b2ddced2 Merge branch 'ds/bundle-uri'
|\ \ \
$ git log --oneline --graph --date-order -n 10 091680472db
* 091680472d Merge branch 'tb/midx-race-in-pack-objects'
|\
* \ d8c8dccbaa Merge branch 'ds/object-file-unpack-loose-header-fix'
|\ \
* \ \ a9e7c3a6ef Merge branch 'pb/use-freebsd-12.3-in-cirrus-ci'
|\ \ \
* \ \ \ b3b2ddced2 Merge branch 'ds/bundle-uri'
|\ \ \ \
* \ \ \ \ 83937e9592 Merge branch 'ns/batch-fsync'
|\ \ \ \ \
* \ \ \ \ \ 377d347eb3 Merge branch 'en/sparse-cone-becomes-default'
|\ \ \ \ \ \
* | | | | | | 2668e3608e Sixth batch
* | | | | | | 4c9b052377 Merge branch 'jc/http-clear-finished-pointer'
|\ \ \ \ \ \ \
* \ \ \ \ \ \ \ db5b7c3e46 Merge branch 'js/ci-gcc-12-fixes'
|\ \ \ \ \ \ \ \
* | | | | | | | | 1bcf4f6271 Fifth batch
Notice that the first example with only --graph brought the commits introduced by the merge to the top of the order. Adding --date-order changes this ordering goal to instead present commits by their commit date, hiding those introduced commits below a long list of merge commits.
The basic algorithm for topological sorting is Kahn’s algorithm which follows two big steps:
- Walk all reachable commits, counting the number of times a commit appears as a parent of another commit. Call these numbers the in-degree of the commit, referencing the number of incoming edges.
- Walk the reachable commits, but only visit a commit if its in-degree value is zero. When visiting a commit, decrement the in-degree value of each parent.
This algorithm works because at least one of our starting points will have in-degree zero, and then decrementing the in-degree value is similar to deleting the commit from the graph, always having at least one commit with in-degree zero.
But there’s a huge problem with this algorithm! It requires walking all reachable commits before writing even one commit for the user to see. It would be much better if our algorithm would be fast to show the first page of information, so the computation could continue while the user has something to look at.
Typically, Git will show the results in a pager such as less, but we can emulate that experience using a commit count limit with the -n 100 argument. Trying this in the Linux kernel takes over seven seconds!
With generation numbers, we can perform an in-line form of Kahn’s algorithm to quickly show the first page of results. The trick is to perform both steps of the algorithm at the same time.
To perform two walks at the same time, Git creates structures that store the state of each walk. The structures are initialized with the starting commits. The in-degree walk uses a priority queue ordered by generation number and that walk starts by computing in-degrees until the maximum generation in that priority queue is below the minimum generation number of the starting positions. The output walk uses a stack, which gives us the nice grouping of commits, but commits are not added unless their in-degree value is zero.
To guarantee that the output walk can add a commit to the stack, it first checks with the status of the in-degree walk to see that the maximum generation in its queue is below the generation number of that commit. In this way, Git alternates between the two walks. It computes just enough of the in-degrees to know that certain commits have an in-degree of zero, then pauses that walk to output some commits to the user.
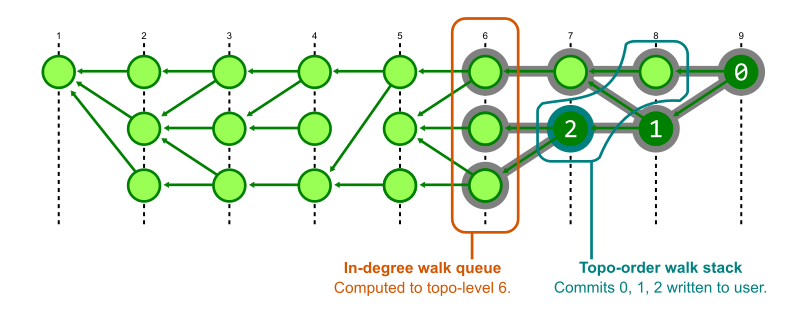
This has a significant performance improvement for our topological sorting commands.
| Command | Without commit-graph |
With commit-graph |
git rev-list --topo-order -n 100 v5.19 |
6.88s |
0.02s |
git log --graph -n 100 v5.19 |
7.73s |
0.03s |
git rev-list --topo-order -n 100 v5.18..v5.19 |
0.39s |
0.02s |
git log --graph -n 100 v5.18..v5.19 |
0.43s |
0.03s |
The top two commands use an unbounded commit range, which is why the old algorithm takes so long: it needs to visit every reachable commit in the in-degree walk before writing anything to output. The new algorithm with generation numbers can explore only the recent commits.
The second two commands use a commit range (v5.18..v5.19) which focuses the search on the commits that are reachable from one commit, but not reachable from another. This actually adds a third stage to the algorithm, where first Git determines which commits are in this range. That algorithm can use a priority queue based on commit date to discover that range without walking the entire commit history, so the old algorithm speeds up for these cases. The in-degree walk still needs to walk that entire range, so it is still slower than the new algorithm as long as that range is big enough.
This idea of a commit range operating on a smaller subgraph than the full commit history actually requires that our interleaved topological sort needs a third walk to determine which commits should be excluded from the output. If you want to learn more about this three-stage algorithm, then read the commit that introduced the walk to Git’s codebase for the full details.
Generation number v2: corrected commit dates
The earlier definition of a generation number was intentionally generic. This is because there are actually multiple possible generation numbers even in the Git codebase!
The definition of topological level essentially uses the smallest possible integer that could be used to satisfy the property of a generation number. The simplicity is nice for understanding, but it has a drawback. It is possible to make the algorithms using generation number worse if you create your commit history in certain ways.
Most of the time, merge commits introduce a short list of recent commits into the commit history. However, some times those merges introduce a commit that’s based on a very old commit. This can happen when fixing a bug in a really old area of code and the developer wants to apply the fix as early as possible so it can merge into old maintenance branches. However, this means that the topological level is much smaller for that commit than for other commits created at similar times.
In this sense, the commit date is a much better heuristic for limiting the commit walk. The only problem is that we can’t trust it as an accurate generation number! Here is where a solution was found: a new generation number based on commit dates. This was implemented as part of a Google Summer of Code project in 2020.
The corrected commit date is defined as follows:
- If a commit has no parents, then its corrected commit date is the same as its commit date.
- Otherwise, determine the maximum corrected commit date of the commit’s parents. If that maximum is larger than the commit date, then add one to that maximum. Otherwise, use the commit date.
Using corrected commit date leads to a wider variety of values in the generation number of each commit in the commit graph. The figure below is the same graph as in the earlier examples, but the commits have been shifted as they could be using corrected commit dates on the horizontal axis.
This definition flips the generation number around. If possible, use the commit date. If not, use the smallest possible value that satisfies the generation number properties with respect to the corrected commit dates of the commit’s parents.
In performance testing, corrected commit dates solve these performance issues due to recent commits based on old commits. In addition, some Git commands generally have slight improvements over topological levels.
For example, the search from A to C in the figure below shows how many commits must be visited to determine that A cannot reach C when using topological level.

However, switching to using corrected commit dates, the search space becomes much smaller.
Recent versions of Git have transitioned to corrected commit dates, but you can test against topological levels by adjusting the commitGraph.generationVersion config option.
Out of the weeds again
We’ve gone very deep into the commit-graph file and reachability algorithms. The on-disk file format is customized to Git’s needs when answering these commit history queries. Thus, it is a type of query index much like one could define in an application database. The rabbit hole goes deeper, though, with yet another level of query index specialized to other queries.
Make sure that you have a commit-graph file accelerating your Git repositories! You can ensure this happens in one of several ways:
- Manually run
git commit-graph write --reachable. - Enable the
fetch.writeCommitGraphconfig option. - Run
git maintenance startand let Git write it in the background.
In the next part of this blog series, we will explore how Git file history queries use the structure of tree objects and the commit graph to limit how many objects need to be parsed. We’ll also talk about a special file history index that is stored in the commit-graph and greatly accelerates file history queries in large repositories.
I’ll also be speaking at Git Merge 2022 covering all five parts of this blog series, so I look forward to seeing you there!
Tags:
Written by

Related posts

$100 million for open source: A milestone built by the community
Celebrating $100 million contributed by the community to the people who build and sustain open source every day.
6 security settings every GitHub maintainer should enable this week
These six free settings will not make your project unhackable. Nothing will. What they will do is close the easy doors. Turn these on, and your project will be meaningfully harder to attack than it was before.
How GitHub maintains compliance for open source dependencies
Explore how the Open Source Program Office uses GitHub’s new license compliance product to manage open source dependencies at scale.