Announcing an open data set on the open source community
We just released an open data set for the open source community, researchers, and curious data wonks to study. The data includes responses from 5,500 open source participants randomly sampled…
We just released an open data set for the open source community, researchers, and curious data wonks to study.
The data includes responses from 5,500 open source participants randomly sampled from over 3,800 projects on GitHub.com and over 500 sourced from communities that work on other platforms. Altogether, the data represents some of the most comprehensive and high-quality data on the open source community to date.
The Open Source Survey covers a broad set of topics, including:
- What people value in the software they use and in open source projects
- How and where people find and provide help
- Privacy preferences and practices
- Employer policies around using and contributing to open source
- Negative experiences and their consequences
- Personal backgrounds of community members
We hope you’ll use the data to inform decisions about community, tooling, and prioritization of work; understand the needs and experiences of different parts of the community; and do new and interesting research on a remarkable system of peer production that powers so much of modern life.
In the meantime, we’ve started using the findings to help us understand what makes a healthy community and how we can improve GitHub for maintainers, contributors, and end users.
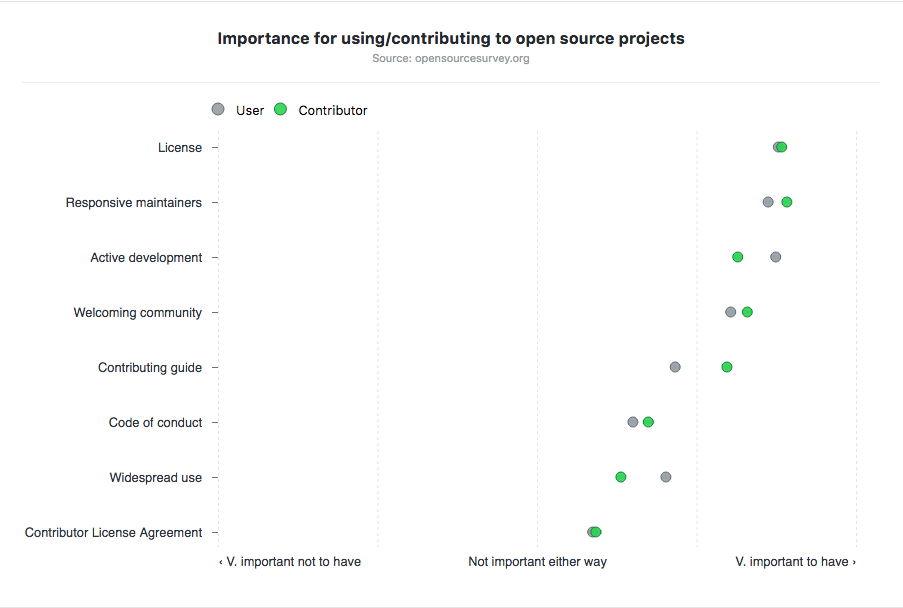
Huge thanks to all of our collaborators in academia, industry, and the open source community who contributed topic ideas and questions, helped with translations, and took the survey. You can find the data, and an analysis of the key findings, at opensourcesurvey.org. Let us know how you use the data or write to us with questions or comments.
Tags:
Written by

Related posts
GitHub joins coalition advocating for fixes to California AI Transparency Act to protect open source
We’re calling for targeted amendments to resolve conflicts with open source licensing and align with international transparency frameworks while preserving regulatory intent.

GitHub availability report: May 2026
In May, we experienced nine incidents that resulted in degraded performance across GitHub services.

GitHub Universe is back: All together now, in the agentic era
GitHub Universe is back: returning to the historic Fort Mason Center in San Francisco on October 28–29, 2026.