CodeQL zero to hero part 1: The fundamentals of static analysis for vulnerability research
Learn more about static analysis and how to use it for security research!
In this blog post series, we will take a closer look at static analysis concepts, present GitHub’s static analysis tool CodeQL, and teach you how to leverage static analysis for security research by writing custom CodeQL queries.

Static analysis (static code analysis or static program analysis) is a process that allows you to analyze an application’s code for potential errors without executing the code itself. The technique can be used to perform various checks, verification, and to highlight issues in the code. At Github, we perform static analysis in code scanning via CodeQL, our semantic analysis engine. This blog series will give you an introduction to static analysis concepts, an overview of CodeQL, how you can leverage static analysis for security research, and teach you how to write custom CodeQL queries. If you’d like to jump right into learning CodeQL, check out my other blog post—CodeQL zero to hero part 2: getting started with CodeQL. If you already know a bit of CodeQL and would like to use it for security research, check out CodeQL zero to hero part 3: Security research with CodeQL.
It is possible to start using CodeQL and find vulnerabilities without digging into static analysis by using the predefined queries in the default configuration (check out our CodeQL documentation). However, learning static analysis fundamentals will enable you to define and query for specific patterns or vulnerabilities. As you dig into vulnerability research with CodeQL, we hope you will find many of these concepts useful for writing your own queries and getting precise alert results.
To facilitate learning static analysis, vulnerability research, and CodeQL, this blog contains voluntary challenges. Before we dive into static analysis, let’s look more closely at the problem it is trying to solve: finding vulnerabilities.
Vulnerability detection—sources and sinks
There are many types of vulnerabilities—some are easier to find with static analysis, some with other means, and some can only be found through manual analysis. One of the types of vulnerabilities that static analysis can find are injection vulnerabilities, which encompass tens of subtypes, and those are the ones that we are going to focus on.
Think about one of the most well-known vulnerabilities—SQL injection. SQL injection is a vulnerability that allows an attacker to change or execute queries in an application’s database. This can result in the attacker accessing sensitive data that they wouldn’t otherwise have access to, or even getting remote code execution on your server! It exists due to using input from a user in a query, which is executed in the database, without proper sanitization.
The main cause of injection vulnerabilities is untrusted, user-controlled input being used in sensitive or dangerous functions of the program. To represent these in static analysis, we use terms such as data flow, sources, and sinks.
User input generally comes from entry points to an application—the origin of data. These include parameters in HTTP methods, such as GET and POST, or command line arguments to a program. These are called “sources.”
Continuing with our SQL injection, an example of a dangerous function that should not be called with unsanitized untrusted data could be MySQLCursor.execute() from the MySQLdb library in Python or Python’s eval() built-in function which evaluates arbitrary expressions. These dangerous functions are called “sinks.” Note that just because a function is potentially dangerous, it does not mean it is immediately an exploitable vulnerability and has to be removed. Many sinks have ways of using them safely.
For a vulnerability to be present, the unsafe, user-controlled input has to be used without proper sanitization or input validation in a dangerous function. In other words, there has to be a code path between the source and the sink, in which case we say that data flows from a source to a sink—there is a “data flow” from the source to the sink.
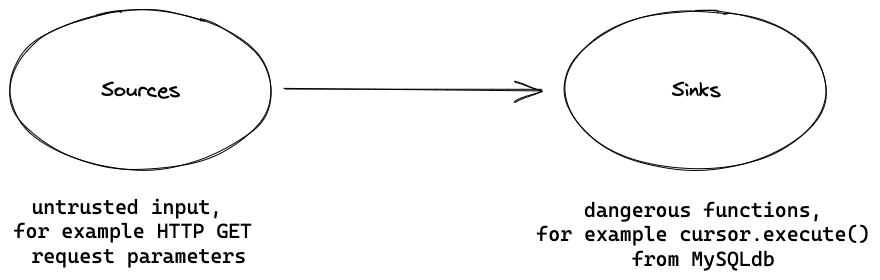
To illustrate – user-controlled input from a parameter in a Django GET request used in the previously named cursor.execute() function from MySQLdb library could lead to SQL injection. Another example: in a user-controlled input form, a parameter from a POST request that is used in eval() could lead to code injection. It could be that you already understand these concepts intuitively, but defining them will allow us to find them easier further on.
Finding sources and sinks
Since we know that sources are where the vulnerability comes through and sinks are where they are executed, it would be prudent to search for vulnerabilities in source code by looking for either one of these and see if the source flows into functions performing sensitive actions (sinks), or the other way around, starting with the sink and going backwards.
We could do so manually by using the *nix utility grep, and start by searching for sources such as GET requests. For example, if we are reviewing a project using the Python framework Django, we might want to look for all places in the codebase, in which Django GET requests are accessed.
There are two problems with this approach. First, if we are looking for a source, for example, Django GET requests, grep will match the selected functions, for example:
username = request.GET.get("username")
but it will also match innocuous function names and comments, for example:
Def request_check(req)
Or:
# This processes a request from the server
We don’t really need these in the analysis, since they will produce a lot of false positives.
Second, we can only search for one type of source and review it one at a time. If we look for GET requests, we will likely get tens of results that do not lead to any real vulnerabilities. What about sources for POST requests? And sources from other libraries of frameworks? There are thousands of sources of untrusted data! Even if we assume the only sources in an application are GET requests, how many requests are there in the source code (likely tens) and how many of these sources end up in a sink, to finally become a vulnerability? There are thousands of ways that the data from a source could propagate through an application and we won’t be able to search through them all manually. We could instead search for sinks that would likely be vulnerable and go backwards to find the source, but the same issue stands—there are too many sinks to go through.
The simple pattern-matching approach with grep doesn’t scale and is not a reliable enough method of finding vulnerabilities. All in all, there are too many results to look through individually.
The earliest static analysis tools for security review were designed to solve these problems.
Early static analysis tools–lexical pattern matching
It is much easier to understand how modern static analysis tools like CodeQL work by looking at some of the first static analysis tools and how they evolved. Let’s consider that many of the steps taken by a static analysis tool are similar to the ones of a compiler. If you think about compilers and interpreters, they already perform a form of static analysis—type checking. Type checking verifies that a type of an object matches what is expected in a given context, for example, if an operation is applied to the right type of object. It is usually enforced by the compiler or interpreter and thanks to that entire categories of bugs can be eliminated. So, we could leverage the technologies that are already in use in compilers, and adapt them to use in static analysis for security review.
The first problem that we found with grepping was that it returned results from comments and function names. Filtering out these results could easily be solved by performing lexical analysis—a well-known compiler technology. Lexical analysis reads the source code and transforms it from a stream of characters into a stream of tokens, ignoring any characters that do not contribute to the semantics of the code. Tokens consist of characters, for example, a comma, literals; for example, strings and integers or the reserved words in the language; for example, with, def in Python.
Take this example code, containing SQL injection.
1. from django.db import connection
2.
3. def show_user(request, username):
4. with connection.cursor() as cursor:
5. cursor.execute("SELECT * FROM users WHERE username = '%s'" % username)
Here is how the first line of the source code was transformed into tokens. It contains information about the token, its row and column position, and what it contains. The output below was generated using Python’s tokenize library from the first line of the above source code, so from django.db import connection.
TokenInfo(type=63 (ENCODING), string='utf-8', start=(0, 0), end=(0, 0), line='')
TokenInfo(type=62 (NL), string='\n', start=(1, 0), end=(1, 1), line='\n')
TokenInfo(type=1 (NAME), string='from', start=(2, 0), end=(2, 4), line='from django.db import connection\n')
TokenInfo(type=1 (NAME), string='django', start=(2, 5), end=(2, 11), line='from django.db import connection\n')
TokenInfo(type=54 (OP), string='.', start=(2, 11), end=(2, 12), line='from django.db import connection\n')
TokenInfo(type=1 (NAME), string='db', start=(2, 12), end=(2, 14), line='from django.db import connection\n')
TokenInfo(type=1 (NAME), string='import', start=(2, 15), end=(2, 21), line='from django.db import connection\n')
TokenInfo(type=1 (NAME), string='connection', start=(2, 22), end=(2, 32), line='from django.db import connection\n')
TokenInfo(type=4 (NEWLINE), string='\n', start=(2, 32), end=(2, 33), line='from django.db import connection\n')
Another important feature that was introduced in static analysis tools at that time was a knowledge base containing information about dangerous sinks, and matched the sink name from the tokens. Upon match, the information about the dangerous sink and why it might be dangerous to use was displayed. Example tools of this type include: ITS4, Flawfinder and RATS.
We have solved the first problem and are no longer finding results inside comments. Now, we can (given that a tool supports this functionality) detect sources and sinks automatically without too many false positives. The second problem still stands though—tools report on dangerous sinks, which might not have been used with untrusted data or in a way causing a vulnerability. There are still too many false positives.
The obvious solution would be to check whether there is a connection between a source and sink. But how can we do that?
Syntactic pattern matching, abstract syntax tree, and control flow graph
The earliest static analysis tools leveraged one technology from compiler theory—lexical analysis. One of the ways to increase precision of detecting vulnerabilities is via leveraging more techniques common in compiler theory. As time progressed, static analysis tools adopted more technologies from compilers—such as parsing and abstract syntax trees (AST). Although there exist a lot of static analysis methods, we are going to explore one of the most popular—data flow analysis with taint analysis.
After the code is scanned for tokens, it can be built into a more abstract representation that will make it easier to query the code. One of the common approaches is to parse the code into a parse tree and build an abstract syntax tree (AST)—here we are more interested in the latter. An abstract syntax tree is a tree representation of source code—thanks to an AST we went from working on a stream of tokens to a representation of source code, in which each node has a type that it represents and that allows us to take into account the semantics, that is the “meaning” of code. To take as an example, one type could be a call to a method, which would be represented as a node in the tree, and its qualifier and arguments will be represented as child nodes. All in all, an abstract syntax tree makes it easier to query the code for what we need in an analysis. Some of the simpler vulnerabilities that we could catch at this stage with high accuracy using an AST could be a disabled CSRF protection or an application running in debug mode.
It is easier to see with a visualization, so let’s take the example of a Python program with a SQL injection vulnerability from above and show its AST. Using the Python’s ast and astpretty module, we can parse the code into an abstract syntax tree. A part of the program’s AST has been presented below. The full AST is available in the appendix.
Module(
body=[
ImportFrom(
lineno=2,
col_offset=0,
end_lineno=2,
end_col_offset=32,
module='django.db',
names=[alias(lineno=2, col_offset=22, end_lineno=2, end_col_offset=32, name='connection', asname=None)],
level=0,
),
FunctionDef(
lineno=5,
col_offset=0,
end_lineno=7,
end_col_offset=78,
name='show_user',
args=arguments(
posonlyargs=[],
args=[
arg(lineno=5, col_offset=14, end_lineno=5, end_col_offset=21, arg='request', annotation=None, type_comment=None),
arg(lineno=5, col_offset=23, end_lineno=5, end_col_offset=31, arg='username', annotation=None, type_comment=None),
],
vararg=None,
kwonlyargs=[],
kw_defaults=[],
kwarg=None,
defaults=[],
)
# output cut for readability
)])
From the output from Python’s ast module and traversing the abstract tree, we can visualize the abstract syntax tree in a simplified graph using the graphviz library. The graph has some information missing for the sake of readability. The code is repeated here again for easier comparison between the code and the graph.
1. from django.db import connection
2.
3. def show_user(request, username):
4. with connection.cursor() as cursor:
5. cursor.execute("SELECT * FROM users WHERE username = '%s'" % username)

As we mentioned before, one type could be a call to a method. Now we can clearly see a node labeled “Call on line 5,” which is a call to a method with its qualifier and arguments represented as child nodes.
What could we do with the representation of source code as an AST? As an example, we could query for all the nodes representing method calls to execute from the django.db library. That would return to us all the method calls to execute—only method calls, not any other types that we might not be interested in. In the next step, we could query for all method calls to execute, that do not take a string literal as an argument. That would exclude the calls from the results that use plain strings—so the ones that do not use any potentially unsafe data and which we already know are not vulnerable. We would then be left with the calls that do not take a string literal—like the call to execute in our example code snippet above, that takes "SELECT * FROM users WHERE username = '%s'" % username as an argument, which in this case is vulnerable to SQL injection. Thanks to using a representation like the abstract syntax tree, we can make more precise queries and thus significantly reduce the number of false positive results.
To make our analysis even more accurate, we can use another representation of source code called control call graph (CFG). A control flow graph describes the flow of control, that is the order in which the AST nodes are evaluated in all possible runs of a program, where each node corresponds to a primitive statement in the program. These primitive statements include assignments and conditions. Edges going out from a node denote a possible successor of that statement in the same run of the program. Thanks to the control flow graph, we can track how the code flows throughout the program and perform further analysis.
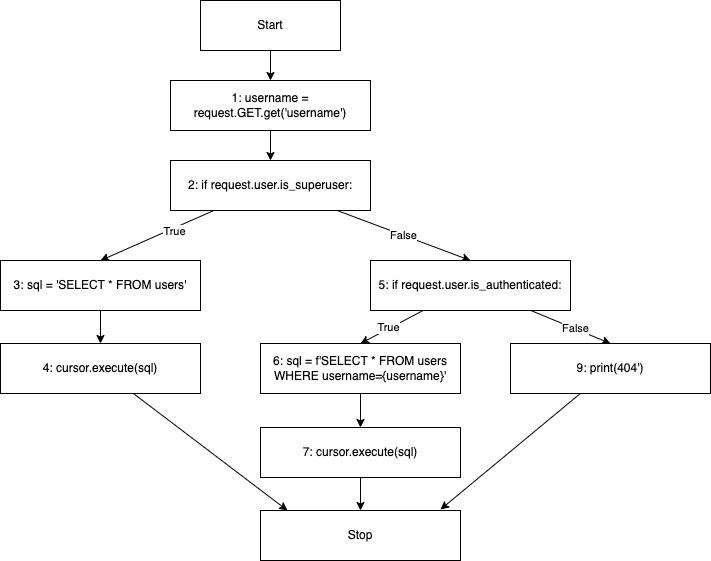
To visualize the control flow graph we will use the following example code with a SQL injection vulnerability. Note that the code is simplified, so it’s easier to visualize and understand the concept. As we can see on lines five to seven, the vulnerability exists only for non-admin authenticated users.
1. username = request.GET.get("username")
2. if request.user.is_superuser:
3. sql = "SELECT * FROM users"
4. cursor.execute(sql)
5. elif request.user.is_authenticated:
6. sql = f"SELECT * FROM users WHERE username={username}"
7. cursor.execute(sql)
8. else:
9. print("404")
A control flow graph created from the above source code will look like below. Note that each block on the diagram has a source code line assigned to it.
We explained in the paragraph “Vulnerability detection—sources and sinks” that for an injection vulnerability to be present, we would need a source with untrusted data to flow into a dangerous function sink—there would have to be a data flow between a source and a sink.
With an AST, we would be able to grab the two method calls on line 3 and 7, but we can’t tell if data flows from source to sink just yet. Can a control flow graph help us with that?
Data flow analysis and taint tracking
It turns out that yes, we can utilize a control flow graph of the source code to check if there is a connection between a given source and a sink—a data flow. We call that technique “data flow analysis.” On first thought, that should allow us to check if a vulnerability exists by checking if there is a data flow between a given source and a sink. That is somewhat the case—data flow analysis leverages the control flow graph and other representations such as the Call Graph (which we will introduce later) and the Static Single Assignment form (SSA) to emulate data propagating throughout the code. The problem with data flow analysis is that it only tracks value-preserving data, that is data that does not change. As an example, if a string is concatenated with another string, then a new string with a different value is created and data flow analysis would not track it. This is the case in our example code and the control flow graph above.
To solve this problem, we use taint tracking—it works similarly to data flow analysis, but with slightly different rules. Taint tracking marks certain inputs—sources—as “tainted” (here, meaning unsafe, user-controlled), which allows a static analysis tool to check if a tainted, unsafe input propagates all the way to a defined spot in our application, such as the argument to a dangerous function. Just like in our example, with taint tracking we can detect that the data flows from the username parameter on line 1, through the if condition if request.user.is_authenticated: on line 5 to the cursor.execute(sql) sink on line 7.
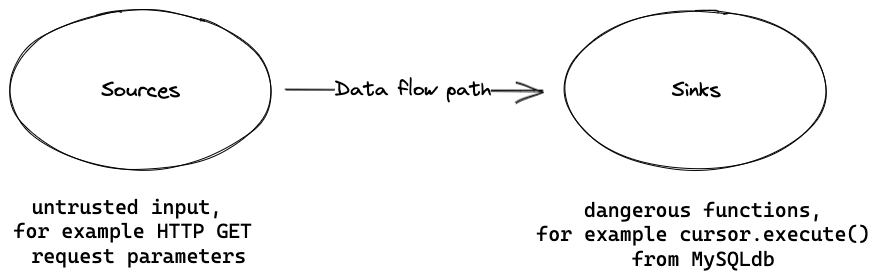
To recap, taint tracking analysis (in comparison to data flow analysis) allows tracking of data even if its value is not preserved, for example, a tainted string is concatenated with another string or if it is assigned to an attribute of an object.
Let’s visualize the data flow path with another example, a very similar one.
1. from django.db import connection
2.
3. def profile(request):
4. with connection.cursor() as cursor:
5. username = request.GET.get("username")
6. sql = f"SELECT * FROM users WHERE username={username}"
7. cursor.execute(sql)
The code snippet contains another SQL injection and the below simplified diagram shows the data flow path of the vulnerability in the above snippet.
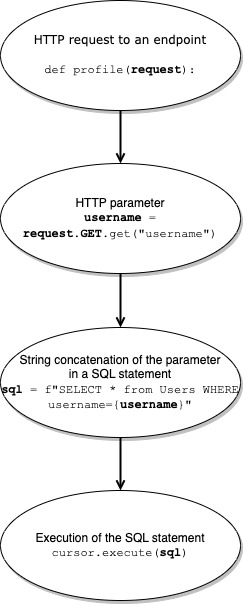
We see the HTTP parameter username being concatenated into a SQL statement called sql. Using data flow analysis, the variable sql would not be highlighted as part of the data flow since the tracked variable (username) value is not preserved through the string interpolation (a new string is created rather than passing username around). Using the more permissive taint tracking analysis, however, sql would be considered tainted and would be a part of the taint flow going to the execute sink. With string interpolation or concatenation specifically, we assume that if the value is not preserved, the taint will be passed to the resulting string.
With taint tracking analysis, we managed to solve the second problem—too many false positive results—and the results right now only report on the issues, in which untrusted data flows all the way into a dangerous function. This really showcases the power of static analysis—we went from having to manually analyze tens of sources and see if they connect to the sinks (or the other way around) to having the flow analyzed automatically and delivered as a few easy to triage results.
What if a given codebase uses sanitization for untrusted data, for example, MySQLdb.escape_string() to prevent SQL injection? Granted, the vulnerabilities will be true positives only if the untrusted data is not validated, escaped or in other way sanitized. Many static analysis tools have built-in support to not report on vulnerabilities that have been sanitized—for example, by using MySQLdb.escape_string(). If one of the nodes in the data flow path from the source to the sink uses sanitization, the tool will stop the flow from propagating and thus not provide a result on a given data flow which uses sanitization. It might happen though that the codebase uses custom, uncommon sanitization methods, that a static analyzer does not support, in which case the tool will still report on the said issue. Being familiar with the codebase should however make it fairly straightforward to verify and dismiss these results. Static analysis tools normally offer a way to define what constitutes a sanitizer or a taint step (an edge between two data flow nodes) to allow users to customize the analysis to their own code and libraries.
Other internal representations
We have explored how the abstract syntax tree and the control flow graph can be used to analyze code. The AST and CFG are some of the most popular representations of source code that static analysis tools operate on, but there are also others. For a security researcher these might not be as relevant, but you will likely encounter them either in the documentation or in the results, and it’s good to know they exist.
A call graph is a representation of potential control flow between functions or methods. Nodes in the graph represent functions, and directed edges represent the potential for one function to invoke another. The call graph represents relationships between functions and allows us to see which function can invoke a different function or if a function can invoke itself.
Another popular form is the Single Static-Assignment (SSA), in which the control flow graph is modified so that every single variable is assigned exactly once. The SSA form considerably improves the precision of various data flow analysis methods.
Oftentimes, static analysis tools use several representations for their analyses, so they can capture advantages of using each of these representations and deliver more precise results.
Conclusion
In this blog, we have gone through the basics of static analysis, the anatomy of static analysis tools, and the data flow analysis and taint tracking analysis methods. The anatomy of most static code analysis tools can be summarized into three components: the parser, the internal representation, and the analysis of the representation. Many static analysis tools’ methods stem from compiler technology and thus have similar steps as a compiler does.
First, the parser parses the source code into an internal representation. In that step, the source code’s syntax is converted into abstract syntax more suited for a particular method of analysis. We could say that there are almost as many internal representations as there are static code analyses—the most popular ones being the abstract syntax tree, control flow graph, call graph and single static-assignment. The next step is the actual analyses—these are divided into analyses: sound or unsound, flow sensitive or flow insensitive, safe or unsafe and according to their complexity, but we will not get into these details in this introductory blog and leave it to the reader. For more information about the analyses, I recommend reading David Binkley’s paper, “Source Code Analysis: A Road Map.”
In the next blog, we will look closer into how some of these techniques are implemented in GitHub’s static analysis tool for security review—CodeQL.
If you found this article interesting, let us know on Twitter! And if you’d like to test your newly acquired knowledge to perform security research, then I have a few challenges for you.
Challenges
Challenge 1—find potential sources and sinks in a web application
Description:
Choose an open source project in a language of your choice, preferably a web application. Find out what are the potential sources and sinks in a language of your choice for a vulnerability such as SQL injection.
1.1 You have already heard that a potential source could be a parameter from an HTTP GET request. What framework does the project of your choice use? If you have chosen a project that is not a web app,what could the sources be in the project?
1.2 What does an HTTP request look like in that framework? Try to find it in the project.
1.3 What are the sinks for SQL injection?
1.4 What would the sink look like in the project? Try to find it.
1.5 Do any of the sources flow into a sink?
Hint: if you can’t find a project, utilize GitHub search functionality, for example, type in the GitHub search bar “language:python stars:>100 type:repositories”. You could also choose one of the intentionally vulnerable projects from OWASP DVWA wherein we have an open source repository.
Challenge 2—find potential sources and sinks in a different vulnerability
Description:
Find out what are the potential sources and sinks in a language of your choice for another vulnerability. For inspiration, look into the Common Weakness Enumeration Database Top 25 or other vulnerabilities in the CWE database.
Hint: if you are having trouble identifying the sources and sinks for a given vulnerability, check out the CodeQL query with that CWE number in CodeQL documentation. Most queries in the documentation contain examples of vulnerable code snippets, which will make it easy to identify sources and sinks.
Challenge 3—analyze one of the latest injection vulnerabilities
Description:
New vulnerabilities are reported every day. Think about the latest injection vulnerability in an opensource project that you have heard about.
3.1 What were the sources and the sinks for that vulnerability?
3.2 Look into the repository of the project. Can you find the source and follow the flow to the sink?
Hint: find the advisory related to the vulnerability. It should contain information about in which version the vulnerability was patched. If the source code is hosted on GitHub, you can easily compare the vulnerable and the patched versions, using the “compare” feature.
Sources
- Brian Chess, Jacob West. “Secure Programming with Static Analysis”
- David Binkley. “Source Code Analysis: A Road Map.” In 2007 Future of Software Engineering (FOSE ’07). IEEE Computer Society, USA, 104–119. https://doi.org/10.1109/FOSE.2007.27
- McGraw, G., “Software security: Building security in,”
- Alfred V. Aho et al. “Compilers: Principles, Techniques, and Tools”
Appendix 1—Abstract Syntax Tree for the example Python program
Module(
body=[
ImportFrom(
lineno=2,
col_offset=0,
end_lineno=2,
end_col_offset=32,
module='django.db',
names=[alias(lineno=2, col_offset=22, end_lineno=2, end_col_offset=32, name='connection', asname=None)],
level=0,
),
FunctionDef(
lineno=5,
col_offset=0,
end_lineno=7,
end_col_offset=78,
name='show_user',
args=arguments(
posonlyargs=[],
args=[
arg(lineno=5, col_offset=14, end_lineno=5, end_col_offset=21, arg='request', annotation=None, type_comment=None),
arg(lineno=5, col_offset=23, end_lineno=5, end_col_offset=31, arg='username', annotation=None, type_comment=None),
],
vararg=None,
kwonlyargs=[],
kw_defaults=[],
kwarg=None,
defaults=[],
),
body=[
With(
lineno=6,
col_offset=4,
end_lineno=7,
end_col_offset=78,
items=[
withitem(
context_expr=Call(
lineno=6,
col_offset=9,
end_lineno=6,
end_col_offset=28,
func=Attribute(
lineno=6,
col_offset=9,
end_lineno=6,
end_col_offset=26,
value=Name(lineno=6, col_offset=9, end_lineno=6, end_col_offset=19, id='connection', ctx=Load()),
attr='cursor',
ctx=Load(),
),
args=[],
keywords=[],
),
optional_vars=Name(lineno=6, col_offset=32, end_lineno=6, end_col_offset=38, id='cursor', ctx=Store()),
),
],
body=[
Expr(
lineno=7,
col_offset=8,
end_lineno=7,
end_col_offset=78,
value=Call(
lineno=7,
col_offset=8,
end_lineno=7,
end_col_offset=78,
func=Attribute(
lineno=7,
col_offset=8,
end_lineno=7,
end_col_offset=22,
value=Name(lineno=7, col_offset=8, end_lineno=7, end_col_offset=14, id='cursor', ctx=Load()),
attr='execute',
ctx=Load(),
),
args=[
BinOp(
lineno=7,
col_offset=23,
end_lineno=7,
end_col_offset=77,
left=Constant(lineno=7, col_offset=23, end_lineno=7, end_col_offset=66, value="SELECT * FROM users WHERE username = '%s'", kind=None),
op=Mod(),
right=Name(lineno=7, col_offset=69, end_lineno=7, end_col_offset=77, id='username', ctx=Load()),
),
],
keywords=[],
),
),
],
type_comment=None,
),
],
decorator_list=[],
returns=None,
type_comment=None,
),
],
type_ignores=[],
)
Tags:
Written by

Related posts

GitHub for Beginners: Answers to some common questions
Find the answers to some of the most common GitHub-related questions.

GitHub for Beginners: Getting started with Git and GitHub in VS Code
Discover how to use VS Code to interact with GitHub and maintain your projects.

Dungeons & Desktops: 10 roguelikes that never die (because their communities won’t let them)
Roguelikes don’t die. They fork, mutate, get argued over, rewritten, abandoned, and revived again. Sometimes all at once.