GitHub Mobile and GraphQL
GitHub’s mobile applications have used GraphQL to power new features. We’ve now been able to move faster and get more done with less hassle and no over-fetching. We were able…

GitHub’s mobile applications have used GraphQL to power new features. We’ve now been able to move faster and get more done with less hassle and no over-fetching.
We were able to turn to the open source community and use Apollo for iOS and Android. By doing so, we moved at warp-speed. We also minimized ongoing engineering effort on what is a core part of our mobile applications.
GraphQL has allowed us to focus less on the tedium around networking, modeling, and API stability. It’s allowed us to focus on the things we’re really passionate about: building great experiences.
The GraphQL mindset
GraphQL has a bit of a learning curve. It requires a change in mindset for people who have worked in REST environments.
GraphQL provides interfaces, types, methods, and the associated documentation as a data structure. This paves the way for tooling to be built on top of it. This is often referred to as the schema. The schema is a representation of the available interfaces, types, and mutations that can modify them. There are no endpoints for different responses in the GraphQL world. Thus the first necessary shift in mindset is from thinking in endpoints, to thinking in types. GraphQL isn’t SQL. But, thinking about it in terms of a SQL schema can be helpful in facilitating the necessary shift in mindset. The schema is a record of the available data types, queries and mutations on the backend. External clients – like the mobile app – hold onto a reference of the schema that must be manually updated.
Moving from the REST mindset to GraphQL
Moving from the REST mindset into the GraphQL means shifting thought away from HTTP methods. You no longer think about GET and POST methods; you now only think about operations, like query and mutation. Queries are analogous to an HTTP get. They are any operation that retrieves data from the server. Mutations, on the other hand, encompass the rest of the possible HTTP operations. A mutation occurs whenever the client wants to modify data on the server. This could be a POST, PUT, DELETE, or PATCH.
Since the client defines the data it wants, and endpoints don’t exist, the response is whatever the client wants it to be – so long as it’s valid within the schema. This allows client engineers to write queries specific to the view they’re working on, rather than using bloated responses or correlating roundtrips across multiple endpoints.
Despite the shift in thought, the GraphQL mindset is actually less complex than the REST mindset. There are the available query types, available mutations, and the inputs they take. There is no more thought being given to endpoints or to response structure.
Code generation
One of the largest strengths of GraphQL on mobile, is code generation of static types for network responses. Being able to generate our network models saves us an incredible amount of time, effort, and upkeep.
In most REST-based systems, we’d have to manually define our network models and consider encoding and decoding strategies. While encoding and decoding has gotten easier over the years with both iOS’s Codable and Kotlin’s built-in serialization, it’s still a consideration that needs to be made. In addition, codable implementations require the whole model to be part of the response. Keys must be manually kept up to date with their server counterparts, and structural changes to the response are generally breaking changes to older clients.
Using Apollo and GraphQL, however, we no longer have to consider this foundational step of app development. Apollo’s tooling allows us to statically type our network responses. This leads our clients to know and trust the data they’re receiving. From there, we’re free to transform and do with them as we wish. As our backend changes, our models keep up to date with the backend changes each time we refresh our schema.
Since GraphQL API’s have field-level deprecation, we can be certain any updates to our backend models don’t break our mobile consumers.
Fragments
A fragment is a small reusable piece of GraphQL. On the GitHub mobile team, we are very heavy users of fragments. We use them to ensure data and API consistency across models. It also reduces the total number of models. A common example would be our actorFields fragment:

In the GitHub API, an Actor represents an object that can take actions – most typically a user. We re-use this fragment across large parts of our application. This allows for a very consistent model API. For example, all of our mobile timeline events have an actor or multiple actors. By using field, each of those GraphQL queries becomes shorter, and the generated models are more consistent.
By re-using fragments, this allows us to quickly prop up new queries and mutations. The more powerful aspect of using fragments is fragments are composable; we are not limited to using one fragment per type. For example, when requesting a User, we could request their actor fields as well as information related to their follows and following:
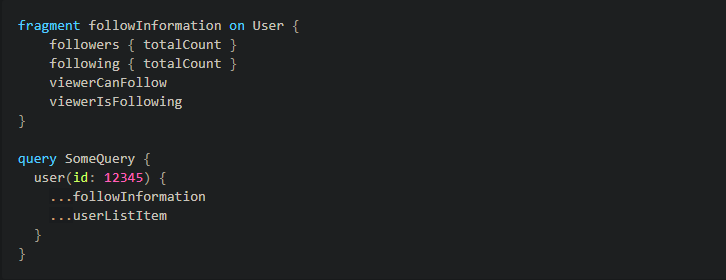
By doing this, we’re able to reduce repetition across our GraphQL queries and generate less models – the response object for SomeQuery contains two models that we’ve already previously generated. More crucially, we can now reuse and compose the fragments we’ve already defined! We can create smaller view models initialzied with type-specific fragments, and compose them into a larger view models just by composing the fragments.
Platform differences
There are noticeable differences between the iOS and Android implementations of the Apollo GraphQL library.
Both iOS and Android (via Kotlin) have introduced their own reactive primitives. Apollo’s Kotlin support is still young, but it’s working well enough for us to use in production. Combined support, however, is still on its way – it’s listed as a long-term goal in the Apollo roadmap.
Additionally, some fragments – notably those performing on interfaces – are only possible to generate on iOS. This is rarely ever a roadblock; it frequently requires more explicit adherence to the types that Apollo-GraphQL recognizes.
Ultimately, there are some platform differences, but they don’t translate into large shifts from one platform to the other. The generated code provided by Apollo is similar enough between the two languages. This means it can be used in much the same way. The Apollo team is also working on aligning and reducing differences across the Apollo Client projects – both web and mobile.
In Closing
GraphQL and Apollo’s tooling allows us to operate at a high degree of efficiency. By allowing us to abstract away many of the concerns traditionally affect mobile applications, we can focus on building features rapidly. Additionally, we get the benefit of every part of every network request becoming useful while no longer having to maintain the network responses ourselves.
Tags:
Written by

Related posts
Don’t stop early: Case-folding source code at memory speed
How a branch-free loop and byte-space arithmetic let GitHub case-fold every byte of code search at >45 GiB/s on a single core.
Tame Dependabot: Group your updates, slow the cadence, keep security fast
Dependabot keeps your dependencies current, but its defaults can flood your repository with pull requests. Here’s how grouping updates, slowing the cadence, and keeping security fixes fast cut the noise on a Microsoft open source project.

The cost of saying yes has changed
The cost of writing code dropped; the cost of owning it didn’t. A framework for deciding which changes are actually cheap in the AI era.