GitHub data, ready for you to explore with BigQuery
GitHub data is available for public analysis using Google BigQuery, and we’d like to help you take it for a spin. If you’d like to find out more about what…
GitHub data is available for public analysis using Google BigQuery, and we’d like to help you take it for a spin.
If you’d like to find out more about what data is available and how it’s been used so far, watch this conversation between GitHub Data Analyst Alyson La and Google Developer Advocate Felipe Hoffa. You’ll learn the story behind the datasets and what types of analysis they make possible. You’ll also see how we’ve visualized data with Tableau and Looker.
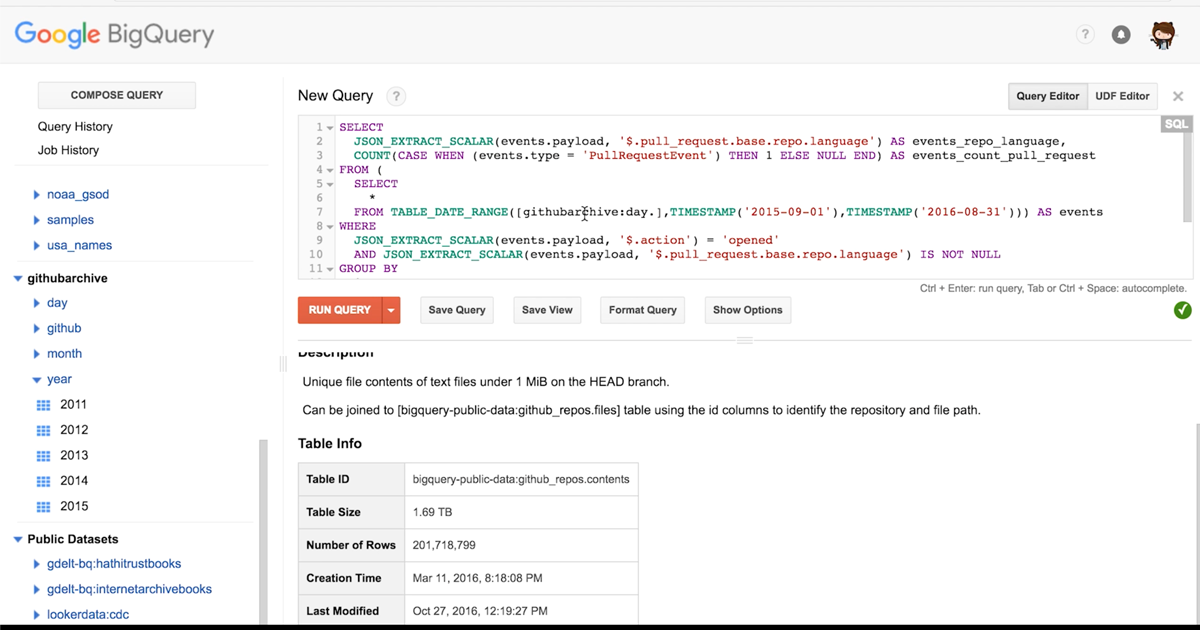
There’s a lot of data out there, but it’s all available through BigQuery in two large data sets. The original, community-led GitHub Archive project launched in 2012 and captures almost 30 million events monthly, including issues, commits, and pushes. Last year, we worked with Google to release The GitHub Public Data Set, separate tables with information on all projects that have open source licenses, including commits, file contents, and file paths.
You can also use the GH torrent project to complement the existing datasets with additional metadata.
We ran a list of queries on the datasets above to create the open source section of our Octoverse report, but anyone can run an analysis. Here are the results of some of the queries run so far.
- “This should never have happened” has appeared in code comments more than a million times (hear this data point for yourself in this Changelog episode)
- Where does open source happen? GitHub top countries shares which countries have the most open source developers per capita
- How reliable is GitHub? Felipe runs a query to find out in GitHub reliability with BigQuery
- There are a lot of feels in open source. Geeksta examines how emotions are expressed in GitHub commit messages
- Are bigger pull requests better? Jessie Frazelle analyzed the top 15 projects on GitHub in terms of pull requests opened vs. pull requests closed
Happy exploring!
Tags:
Written by

Related posts

From pair to peer programmer: Our vision for agentic workflows in GitHub Copilot
AI agents in GitHub Copilot don’t just assist developers but actively solve problems through multi-step reasoning and execution. Here’s what that means.
GitHub Availability Report: May 2025
In May, we experienced three incidents that resulted in degraded performance across GitHub services.

GitHub Universe 2025: Here’s what’s in store at this year’s developer wonderland
Sharpen your skills, test out new tools, and connect with people who build like you.