Gaining kernel code execution on an MTE-enabled Pixel 8
In this post, I’ll look at CVE-2023-6241, a vulnerability in the Arm Mali GPU that allows a malicious app to gain arbitrary kernel code execution and root on an Android phone. I’ll show how this vulnerability can be exploited even when Memory Tagging Extension (MTE), a powerful mitigation, is enabled on the device.

In this post, I’ll look at CVE-2023-6241, a vulnerability in the Arm Mali GPU that I reported to Arm on November 15, 2023 and was fixed in the Arm Mali driver version r47p0, which was released publicly on December 14, 2023. It was fixed in Android in the March security update. When exploited, this vulnerability allows a malicious Android app to gain arbitrary kernel code execution and root on the device. The vulnerability affects devices with newer Arm Mali GPUs that use the Command Stream Frontend (CSF) feature, such as Google’s Pixel 7 and Pixel 8 phones. What is interesting about this vulnerability is that it is a logic bug in the memory management unit of the Arm Mali GPU and it is capable of bypassing Memory Tagging Extension (MTE), a new and powerful mitigation against memory corruption that was first supported in Pixel 8. In this post, I’ll show how to use this bug to gain arbitrary kernel code execution in the Pixel 8 from an untrusted user application. I have confirmed that the exploit works successfully even with kernel MTE enabled by following these instructions.
Arm64 MTE
MTE is a very well documented feature on newer Arm processors that uses hardware implementations to check for memory corruption. As there are already many good articles about MTE, I’ll only briefly go through the idea of MTE and explain its significance in comparison to other mitigations for memory corruption. Readers who are interested in more details can, for example, consult this article and the whitepaper released by Arm.
While the Arm64 architecture uses 64 bit pointers to access memory, there is usually no need to use such a large address space. In practice, most applications use a much smaller address space (usually 52 bits or less). This leaves the highest bits in a pointer unused. The main idea of memory tagging is to use these higher bits in an address to store a “tag” that can then be used to check against the other tag stored in the memory block associated with the address. The helps to mitigate common types of memory corruptions as follows:
In the case of a linear overflow, a pointer is used to dereference an adjacent memory block that has a different tag compared to the one stored in the pointer. By checking these tags at dereference time, the corrupted dereference can be detected. For use-after-free type memory corruptions, as long as the tag in a memory block is cleared every time it is freed and a new tag reassigned when it is allocated, dereferencing an already freed and reclaimed object will also lead to a discrepancy between pointer tag and the tag in memory, which allows use-after-free to be detected.
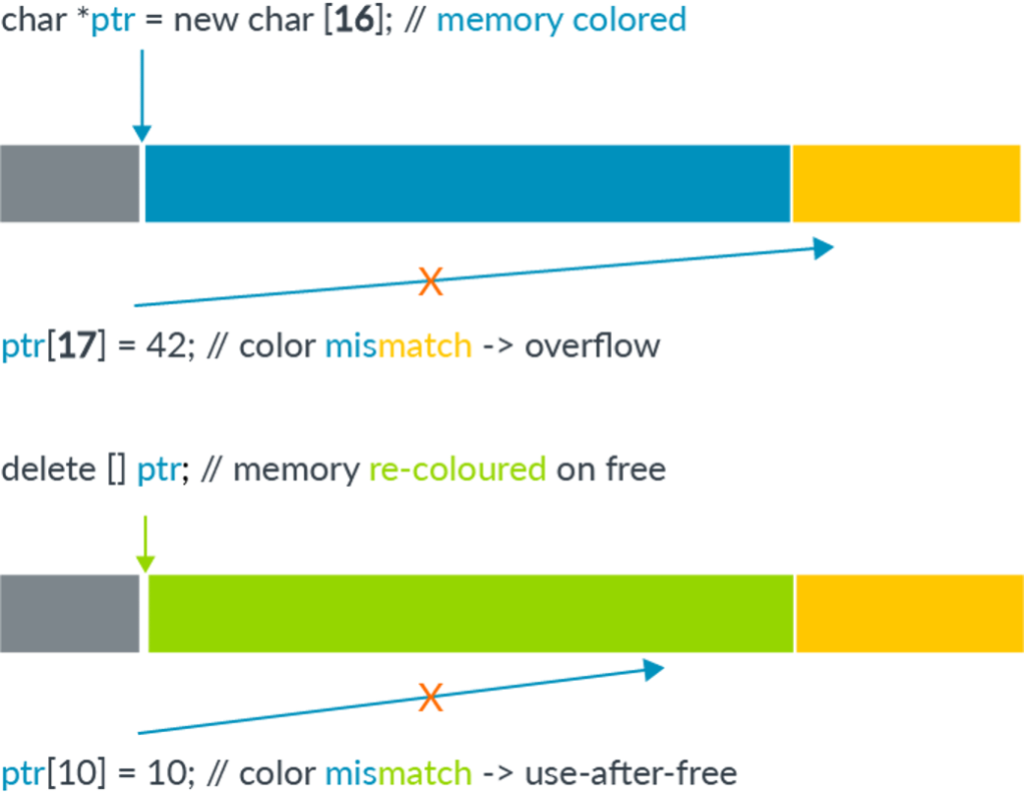
(The above image is from Memory Tagging Extension: Enhancing memory safety through architecture published by Arm.)
The main reason that memory tagging is different from previous mitigations, such as Kernel Control Flow Integrity (kCFI) is that, unlike other mitigations, which disrupts later stages of an exploit, MTE is a very early stage mitigation that tries to catch memory corruption when it first happens. As such, it is able to stop an exploit in a very early stage before the attacker has gained any capabilities and it is therefore very difficult to bypass. It introduces checks that effectively turns an unsafe memory language into one that is memory safe, albeit probabilistically.
In theory, memory tagging can be implemented in software alone, by making the memory allocator assign and remove tags everytime memory is allocated or free, and by adding tag checking logic when dereferencing pointers. Doing so, however, incurs a performance cost that makes it unsuitable for production use. As a result, hardware implementation is needed to reduce the performance cost and to make memory tagging viable for production use. The hardware support was introduced in the v8.5a version of the ARM architecture, in which extra hardware instructions (called MTE) were introduced to perform tagging and checking. For Android devices, most chipsets that support MTE use Arm v9 processors (instead of Arm v8.5a), and currently there are only a handful of devices that support MTE.
One of the limitations of MTE is that the number of available unused bits is small compared to all possible memory blocks that can ever be allocated. As such, tag collision is inevitable and many memory blocks will have the same tag. This means that a corrupted memory access may still succeed by chance. In practice, even when using only 4 bits for the tag, the success rate is reduced to 1/16, which is still a fairly strong protection against memory corruption. Another limitation is that, by leaking pointer and memory block values using side channel attack such as Spectre, an attacker may be able to ensure that a corrupted memory access is done with the correct tag and thus bypasses MTE. This type of leak, however, is mostly only available to a local attacker. The series of articles, MTE As Implemented by Mark Brand, includes an in-depth study of the limitations and impact of MTE on various attack scenarios.
Apart from having hardware that uses processors that implements Arm v8.5a or above, software support is also required to enable MTE. Currently, only Google’s Pixel 8 allows users to enable MTE in the developer options and MTE is disabled by default. Extra steps are also required to enable MTE in the kernel.
The Arm Mali GPU
The Arm Mali GPU can be integrated in various devices, (for example, see “Implementations” in Mali (GPU) Wikipedia entry). It has been an attractive target on Android phones and has been targeted by in-the-wild exploits multiple times. The current vulnerability is closely related to another issue that I reported and is a vulnerability in the handling of a type of GPU memory called JIT memory. I’ll now briefly explain JIT memory and explain the vulnerability CVE-2023-6241.
JIT memory in Arm Mali
When using the Mali GPU driver, a user app first needs to create and initialize a kbase_context kernel object. This involves the user app opening the driver file and using the resulting file descriptor to make a series of ioctl calls. A kbase_context object is responsible for managing resources for each driver file that is opened and is unique for each file handle.
In particular, the kbase_context manages different types of memory that are shared between the GPU device and user space applications. User applications can either map their own memory to the memory space of the GPU so the GPU can access this memory, or they can allocate memory from the GPU. Memory allocated by the GPU is managed by the kbase_context and can be mapped to the GPU memory space and also mapped to user space. A user application can also use the GPU to access mapped memory by submitting commands to the GPU. In general, memory needs to be either allocated and managed by the GPU (native memory) or imported to the GPU from user space, and then mapped to the GPU address space before it can be accessed by the GPU. A memory region in the Mali GPU is represented by the kbase_va_region. Similar to virtual memory in the CPU, a memory region in the GPU may not have its entire range backed by physical memory. The nr_pages field in a kbase_va_region specifies the virtual size of the memory region, whereas gpu_alloc->nents is the actual number of physical pages that are backing the region. I’ll refer to these pages as the backing pages of the region from now on. While the virtual size of a memory region is fixed, its physical size can change. From now on, when I use terminologies such as resize, grow and shrink regarding a memory region, what I mean is that the physical size of the region is resizing, growing or shrinking.
The JIT memory is a type of native memory whose lifetime is managed by the kernel driver. User applications request the GPU to allocate and free JIT memory by sending relevant commands to the GPU. While most commands, such as those using GPU to perform arithmetic and memory accesses are executed on the GPU itself, there are some commands, such as the ones used for managing JIT memory, that are implemented in the kernel and executed on the CPU. These are called software commands (in contrast to hardware commands that are executed on the GPU (hardware)). On GPUs that use the Command Stream Frontend (CSF), software commands and hardware commands are placed on different types of command queues. To submit a software command, a kbase_kcpu_command_queue is needed and it can be created by using the KBASE_IOCTL_KCPU_QUEUE_CREATE ioctl. A software command can then be queued using the KBASE_IOCTL_KCPU_QUEUE_ENQUEUE command. To allocate or free JIT memory, commands of type BASE_KCPU_COMMAND_TYPE_JIT_ALLOC and BASE_KCPU_COMMAND_TYPE_JIT_FREE can be used.
The BASE_KCPU_COMMAND_TYPE_JIT_ALLOC command uses kbase_jit_allocate to allocate JIT memory. Similarly, the command BASE_KCPU_COMMAND_TYPE_JIT_FREE can be used to free JIT memory. As explained in the section “The life cycle of JIT memory” in one of my previous posts, when JIT memory is freed, it goes into a memory pool managed by the kbase_context and when kbase_jit_allocate is called, it first looks into this memory pool to see if there is any suitable freed JIT memory that can be reused:
struct kbase_va_region *kbase_jit_allocate(struct kbase_context *kctx,
const struct base_jit_alloc_info *info,
bool ignore_pressure_limit)
{
...
kbase_gpu_vm_lock(kctx);
mutex_lock(&kctx->jit_evict_lock);
/*
* Scan the pool for an existing allocation which meets our
* requirements and remove it.
*/
if (info->usage_id != 0)
/* First scan for an allocation with the same usage ID */
reg = find_reasonable_region(info, &kctx->jit_pool_head, false);
...
}
If an existing region is found and its virtual size matches the request, but its physical size is too small, then kbase_jit_allocate will attempt to allocate more physical pages to back the region by calling kbase_jit_grow:
struct kbase_va_region *kbase_jit_allocate(struct kbase_context *kctx,
const struct base_jit_alloc_info *info,
bool ignore_pressure_limit)
{
...
/* kbase_jit_grow() can release & reacquire 'kctx->reg_lock',
* so any state protected by that lock might need to be
* re-evaluated if more code is added here in future.
*/
ret = kbase_jit_grow(kctx, info, reg, prealloc_sas,
mmu_sync_info);
...
}
If, on the other hand, no suitable region is found, kbase_jit_allocate will allocate JIT memory from scratch:
struct kbase_va_region *kbase_jit_allocate(struct kbase_context *kctx,
const struct base_jit_alloc_info *info,
bool ignore_pressure_limit)
{
...
} else {
/* No suitable JIT allocation was found so create a new one */
u64 flags = BASE_MEM_PROT_CPU_RD | BASE_MEM_PROT_GPU_RD |
BASE_MEM_PROT_GPU_WR | BASE_MEM_GROW_ON_GPF |
BASE_MEM_COHERENT_LOCAL |
BASEP_MEM_NO_USER_FREE;
u64 gpu_addr;
...
mutex_unlock(&kctx->jit_evict_lock);
kbase_gpu_vm_unlock(kctx);
reg = kbase_mem_alloc(kctx, info->va_pages, info->commit_pages, info->extension,
&flags, &gpu_addr, mmu_sync_info);
...
}
As we can see from the comment above the call to kbase_jit_grow, kbase_jit_grow can temporarily drop the kctx->reg_lock:
static int kbase_jit_grow(struct kbase_context *kctx,
const struct base_jit_alloc_info *info,
struct kbase_va_region *reg,
struct kbase_sub_alloc **prealloc_sas,
enum kbase_caller_mmu_sync_info mmu_sync_info)
{
...
if (!kbase_mem_evictable_unmake(reg->gpu_alloc))
goto update_failed;
...
old_size = reg->gpu_alloc->nents; //commit_pages - reg->gpu_alloc->nents; //<---------2.
pages_required = delta;
...
while (kbase_mem_pool_size(pool) mem_partials_lock);
kbase_gpu_vm_unlock(kctx); //<---------- lock dropped.
ret = kbase_mem_pool_grow(pool, pool_delta);
kbase_gpu_vm_lock(kctx);
...
}
In the above, we see that kbase_gpu_vm_unlock is called to temporarily drop the kctx->reg_lock, while kctx->mem_partials_lock is also dropped during a call to kbase_mem_pool_grow. In the Mali GPU, the kctx->reg_lock is used for protecting concurrent accesses to memory regions. So, for example, when kctx->reg_lock is held, the physical size of the memory region cannot be changed by another thread. In GHSL-2023-005 that I reported previously, I was able to trigger a race so that the JIT region was shrunk by using the KBASE_IOCTL_MEM_COMMIT ioctl from another thread while kbase_mem_pool_grow was running. This change in the size of the JIT region caused reg->gpu_alloc->nents to change after kbase_mem_pool_grow, meaning that the actual value of reg->gpu_alloc->nents was then different from the value that was cached in old_size and delta (1. and 2. in the above). As these values were later used to allocate and map the JIT region, using these stale values caused inconsistency in the GPU memory mapping, causing GHSL-2023-005.
static int kbase_jit_grow(struct kbase_context *kctx,
const struct base_jit_alloc_info *info,
struct kbase_va_region *reg,
struct kbase_sub_alloc **prealloc_sas,
enum kbase_caller_mmu_sync_info mmu_sync_info)
{
...
//grow memory pool
...
//delta use for allocating pages
gpu_pages = kbase_alloc_phy_pages_helper_locked(reg->gpu_alloc, pool,
delta, &prealloc_sas[0]);
...
//old_size used for growing gpu mapping
ret = kbase_mem_grow_gpu_mapping(kctx, reg, info->commit_pages,
old_size);
...
}
After GHSL-2023-005 was patched, it was no longer possible to change the size of JIT memory using the KBASE_IOCTL_MEM_COMMIT ioctl.
The vulnerability
Similar to virtual memory, when an address in a memory region that is not backed by a physical page is accessed by the GPU, a memory access fault happens. In this case, depending on the type of the memory region, it may be possible to allocate and map a physical page on the fly to back the fault address. A GPU memory access fault is handled by the kbase_mmu_page_fault_worker:
void kbase_mmu_page_fault_worker(struct work_struct *data)
{
...
kbase_gpu_vm_lock(kctx);
...
if ((region->flags & GROWABLE_FLAGS_REQUIRED)
!= GROWABLE_FLAGS_REQUIRED) {
kbase_gpu_vm_unlock(kctx);
kbase_mmu_report_fault_and_kill(kctx, faulting_as,
"Memory is not growable", fault);
goto fault_done;
}
if ((region->flags & KBASE_REG_DONT_NEED)) {
kbase_gpu_vm_unlock(kctx);
kbase_mmu_report_fault_and_kill(kctx, faulting_as,
"Don't need memory can't be grown", fault);
goto fault_done;
}
...
spin_lock(&kctx->mem_partials_lock);
grown = page_fault_try_alloc(kctx, region, new_pages, &pages_to_grow,
&grow_2mb_pool, prealloc_sas);
spin_unlock(&kctx->mem_partials_lock);
...
}
Within the fault handler, a number of checks are performed to ensure that the memory region is allowed to grow in size. The two checks that are relevant to JIT memory are the checks for the GROWABLE_FLAGS_REQUIRED and the KBASE_REG_DONT_NEED flags. The GROWABLE_FLAGS_REQUIRED is defined as follows:
#define GROWABLE_FLAGS_REQUIRED (KBASE_REG_PF_GROW | KBASE_REG_GPU_WR)
These flags are added to a JIT region when it is created by kbase_jit_allocate and are never changed:
struct kbase_va_region *kbase_jit_allocate(struct kbase_context *kctx,
const struct base_jit_alloc_info *info,
bool ignore_pressure_limit)
{
...
} else {
/* No suitable JIT allocation was found so create a new one */
u64 flags = BASE_MEM_PROT_CPU_RD | BASE_MEM_PROT_GPU_RD |
BASE_MEM_PROT_GPU_WR | BASE_MEM_GROW_ON_GPF | //jit_evict_lock);
kbase_gpu_vm_unlock(kctx);
reg = kbase_mem_alloc(kctx, info->va_pages, info->commit_pages, info->extension,
&flags, &gpu_addr, mmu_sync_info);
...
}
While the KBASE_REG_DONT_NEED flag is added to a JIT region when it is freed, it is removed in kbase_jit_grow well before the kctx->reg_lock and kctx->mem_partials_lock are dropped and kbase_mem_pool_grow is called:
static int kbase_jit_grow(struct kbase_context *kctx,
const struct base_jit_alloc_info *info,
struct kbase_va_region *reg,
struct kbase_sub_alloc **prealloc_sas,
enum kbase_caller_mmu_sync_info mmu_sync_info)
{
...
if (!kbase_mem_evictable_unmake(reg->gpu_alloc)) //<----- Remove KBASE_REG_DONT_NEED
goto update_failed;
...
while (kbase_mem_pool_size(pool) mem_partials_lock);
kbase_gpu_vm_unlock(kctx);
ret = kbase_mem_pool_grow(pool, pool_delta); //<----- race window: fault handler grows region
kbase_gpu_vm_lock(kctx);
...
}
In particular, during the race window marked in the above snippet, the JIT memory reg is allowed to grow when a page fault happens.
So, by accessing unmapped memory in the region to create a fault on another thread while kbase_mem_pool_grow is running, I can cause the JIT region to be grown by the GPU fault handler while kbase_mem_pool_grow runs. This then changes reg->gpu_alloc->nents and invalidates old_size and delta in 1. and 2. below:
static int kbase_jit_grow(struct kbase_context *kctx,
const struct base_jit_alloc_info *info,
struct kbase_va_region *reg,
struct kbase_sub_alloc **prealloc_sas,
enum kbase_caller_mmu_sync_info mmu_sync_info)
{
...
if (!kbase_mem_evictable_unmake(reg->gpu_alloc))
goto update_failed;
...
old_size = reg->gpu_alloc->nents; //commit_pages - reg->gpu_alloc->nents; //<---------2.
pages_required = delta;
...
while (kbase_mem_pool_size(pool) mem_partials_lock);
kbase_gpu_vm_unlock(kctx);
ret = kbase_mem_pool_grow(pool, pool_delta); //gpu_alloc->nents changed by fault handler
kbase_gpu_vm_lock(kctx);
...
//delta use for allocating pages
gpu_pages = kbase_alloc_phy_pages_helper_locked(reg->gpu_alloc, pool, //commit_pages, //<----- 4.
old_size);
...
}
As a result, when delta and old_size are used in 3. and 4. to allocate backing pages and to map the pages to the GPU memory space, their values are invalid.
This is very similar to what happened with GHSL-2023-005. As kbase_mem_pool_grow involves large memory allocations, this race can be won very easily. There is, however, one very big difference here: With GHSL-2023-005, I was able to shrink the JIT region while in this case, I was only able to grow the JIT region. To understand why this matters, let’s have a brief recap of how my exploit for GHSL-2023-005 worked.
As mentioned before, the physical size, or the number of backing pages of a kbase_va_region is stored in the field reg->gpu_alloc->nents. A kbase_va_region has two kbase_mem_phy_alloc objects: the cpu_alloc and gpu_alloc that are responsible for managing its backing pages. For Android devices, these two fields are configured to be the same. Within kbase_mem_phy_alloc, the field pages is an array that contains the physical addresses of the backing pages, while nents specifies the length of the pages array:
struct kbase_mem_phy_alloc {
...
size_t nents;
struct tagged_addr *pages;
...
}
When kbase_alloc_phy_pages_helper_locked is called, it allocates memory pages and appends the physical addresses represented by these pages to the array pages, so the new pages are added to the index nents onwards. The new size is then stored to nents. For example, when it is called in kbase_jit_grow, delta is the number of pages to add:
static int kbase_jit_grow(struct kbase_context *kctx,
const struct base_jit_alloc_info *info,
struct kbase_va_region *reg,
struct kbase_sub_alloc **prealloc_sas,
enum kbase_caller_mmu_sync_info mmu_sync_info)
{
...
//delta use for allocating pages
gpu_pages = kbase_alloc_phy_pages_helper_locked(reg->gpu_alloc, pool,
delta, &prealloc_sas[0]);
...
}
In this case, delta pages are inserted at the index nents in the array pages of gpu_alloc:
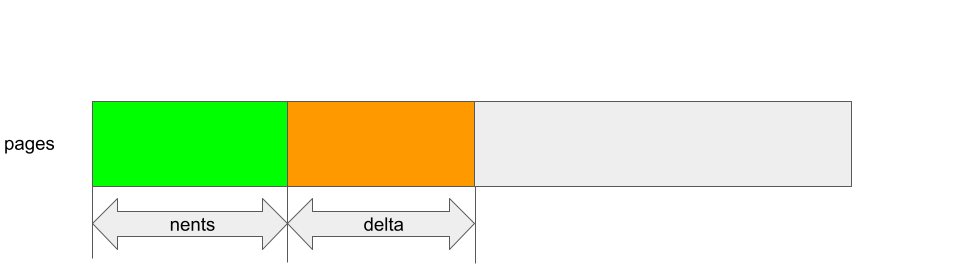
After the backing pages are allocated and inserted into the pages array, the new pages are mapped to the GPU address space by calling kbase_mem_grow_gpu_mapping. The virtual address of a kbase_va_region in the GPU memory space is managed by the kbase_va_region itself and is stored in the fields start_pfn and nr_pages:
struct kbase_va_region {
...
u64 start_pfn;
...
size_t nr_pages;
...
}
The start of the virtual address of a kbase_va_region is stored in start_pfn (as a page frame, so the actual address is start_pfn >> PAGE_SIZE) while nr_pages stores the size of the region. These fields remain unchanged after they are set. Within a kbase_va_region, the initial reg->gpu_alloc->nents pages in the virtual address space are backed by the physical memory stored in the pages array of gpu_alloc->pages, while the rest of the addresses are not backed. In particular, the virtual addresses that are backed are always contiguous (so, no gaps between backed regions) and always start from the start of the region. For example, the following is possible:
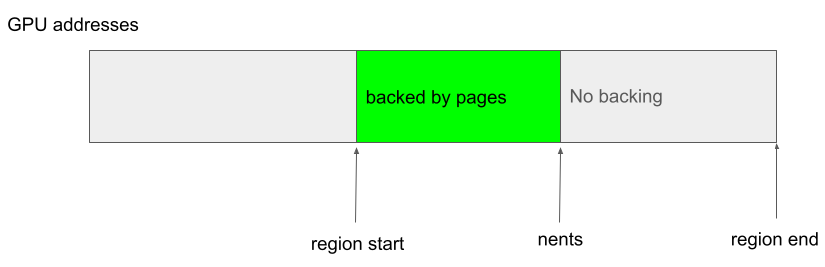
While the following case is not allowed because the backing does not start from the beginning of the region:
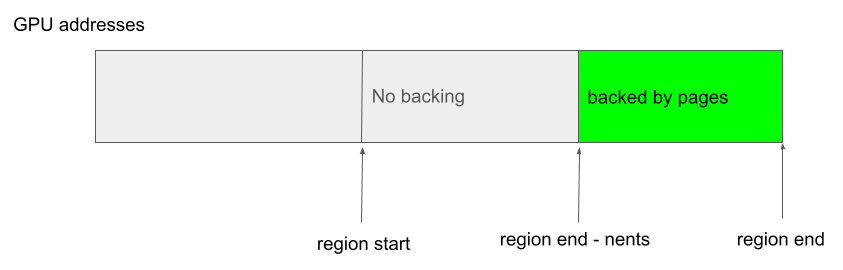
and this following case is also not allowed because of the gaps in the addresses that are backed:
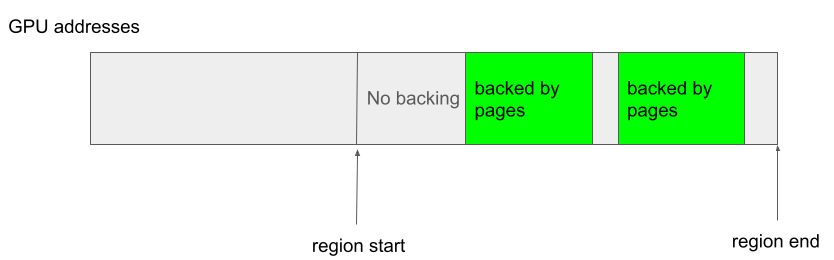
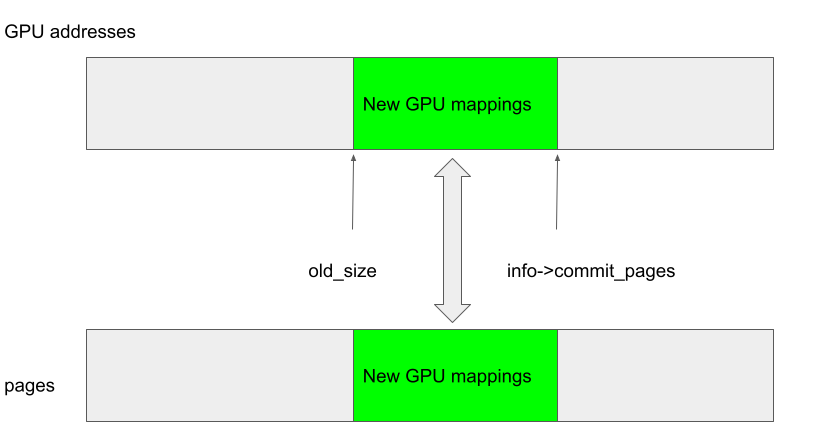
In the case when kbase_mem_grow_gpu_mapping is called in kbase_jit_grow, the GPU addresses between (start_pfn + old_size) * 0x1000 to (start_pfn + info->commit_pages) * 0x1000 are mapped to the newly added pages in gpu_alloc->pages, which are the pages between indices pages + old_size and pages + info->commit_pages (because delta = info->commit_pages - old_size):
static int kbase_jit_grow(struct kbase_context *kctx,
const struct base_jit_alloc_info *info,
struct kbase_va_region *reg,
struct kbase_sub_alloc **prealloc_sas,
enum kbase_caller_mmu_sync_info mmu_sync_info)
{
...
old_size = reg->gpu_alloc->nents;
delta = info->commit_pages - reg->gpu_alloc->nents;
...
//old_size used for growing gpu mapping
ret = kbase_mem_grow_gpu_mapping(kctx, reg, info->commit_pages,
old_size);
...
}
In particular, old_size here is used to specify both the GPU address where the new mapping should start, and also the offset from the pages array where backing pages should be used.
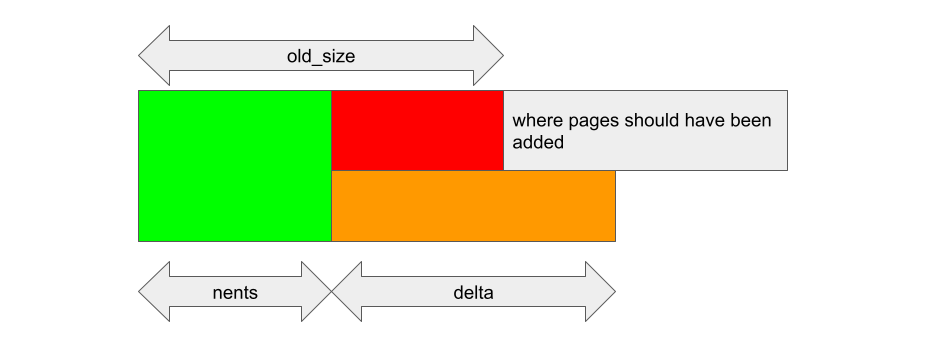
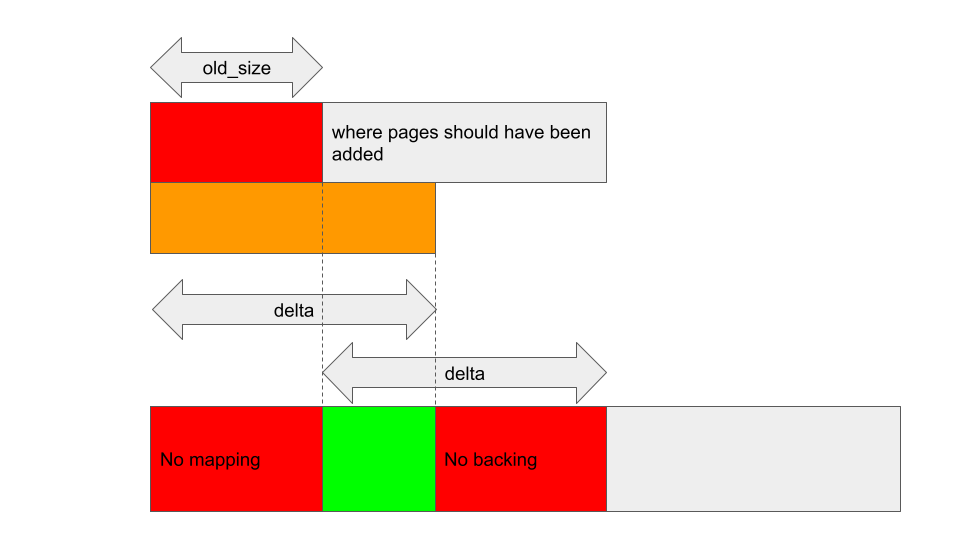
If reg->gpu_alloc->nents changes after old_size and delta are cached, then these offsets may become invalid. For example, if the kbase_va_region was shrunk and nents decreased after old_size and delta were stored, then kbase_alloc_phy_pages_helper_locked will insert delta pages to reg->gpu_alloc->pages + nents:
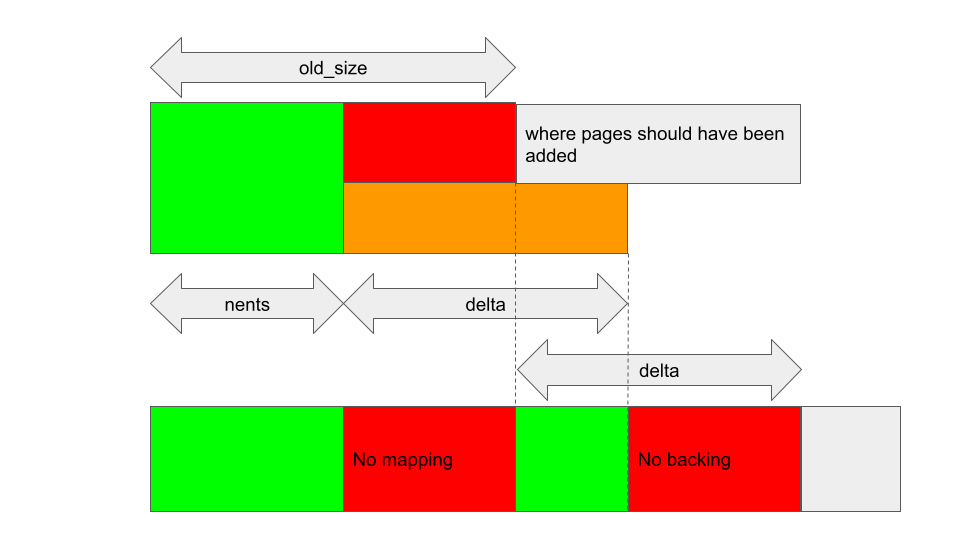
Similarly, kbase_mem_grow_gpu_mapping will map the GPU addresses starting from (start_pfn + old_size) * 0x1000, using the pages that are between reg->gpu_alloc->pages + old_size and reg->gpu_alloc->pages + nents + delta (dotted lines in the figure below). This means that the pages between pages->nents and pages->old_size don’t end up getting mapped to any GPU addresses, while some addresses end up having no backing pages:
Exploiting GHSL-2023-005
GHSL-2023-005 enabled me to shrink the JIT region but CVE-2023-6241 does not give me that capability. To understand how to exploit this issue, we need to know a bit more about how GPU mappings are removed. The function kbase_mmu_teardown_pgd_pages is responsible for removing address mappings from the GPU. This function essentially walks through a GPU address range and removes the addresses from the GPU page table by marking them as invalid. If it encounters a high level page table entry (PTE), which covers a large range of addresses, and finds that the entry is invalid, then it’ll skip removing the entire range of addresses covered by the entry. For example, a level 2 page table entry covers a range of 512 pages, so if a level 2 page table entry is found to be invalid (1. in the below), then kbase_mmu_teardown_pgd_pages will assume the next 512 pages are covered by this level 2 and hence are all invalid already. As such, it’ll skip removing these pages (2. in the below).
static int kbase_mmu_teardown_pgd_pages(struct kbase_device *kbdev, struct kbase_mmu_table *mmut,
u64 vpfn, size_t nr, u64 *dirty_pgds,
struct list_head *free_pgds_list,
enum kbase_mmu_op_type flush_op)
{
...
for (level = MIDGARD_MMU_TOPLEVEL;
level ate_is_valid(page[index], level))
break; /* keep the mapping */
else if (!mmu_mode->pte_is_valid(page[index], level)) { //<------ 1.
/* nothing here, advance */
switch (level) {
...
case MIDGARD_MMU_LEVEL(2):
count = 512; // nr)
count = nr;
goto next;
}
...
next:
kunmap(phys_to_page(pgd));
vpfn += count;
nr -= count;
The function kbase_mmu_teardown_pgd_pages is called either when a kbase_va_region is shrunk or when it is deleted. As explained in the previous section, the virtual addresses in a kbase_va_region that are mapped and backed by physical pages must be contiguous from the start of the kbase_va_region. As a result, if any address in the region is mapped, then the start address must be mapped and hence the high level page table entry covering the start address must be valid (if no address in the region is mapped, then kbase_mmu_teardown_pgd_pages would not even be called):
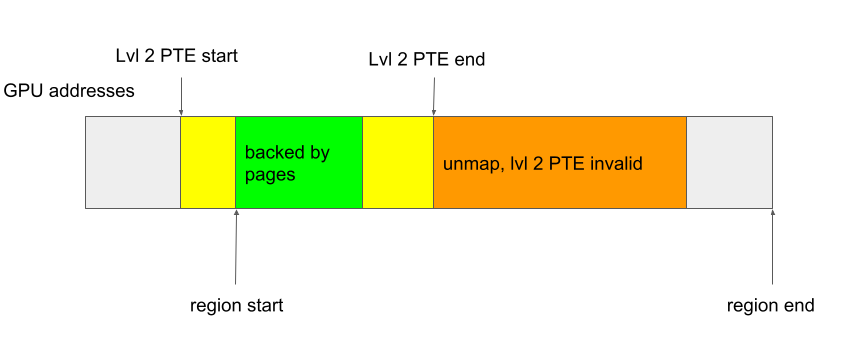
In the above, the level 2 PTE that covers the start address of the region is mapped and so it is valid, therefore in this case, if kbase_mmu_teardown_pgd_pages ever encounters an unmapped high level PTE, the rest of the addresses in the kbase_va_region must have already been unmapped and can be skipped safely.
In the case where a region is shrunk, the address where the unmapping starts lies within the kbase_va_region, and the entire range between this start address and the end of the region will be unmapped. If the level 2 page table entry covering this address is invalid, then the start address must be in a region that is not mapped, and hence the rest of the address range to unmap must also not have been mapped. In this case, skipping of addresses is again safe:
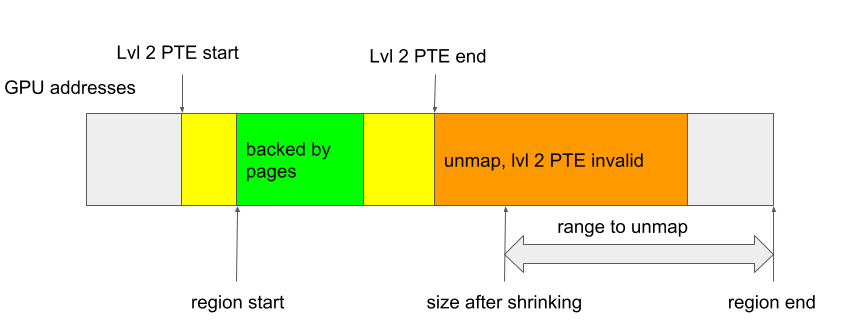
So, as long as regions are only mapped from their start addresses and have no gaps in the mappings, kbase_mmu_teardown_pgd_pages will behave correctly.
In the case of GHSL-2023-005, it is possible to create a region that does not meet these conditions. For example, by shrinking the entire region to size zero during the race window, it is possible to create a region where the start of the region is unmapped:
When the region is deleted, and kbase_mmu_teardown_pgd_pages tries to remove the first address, because the level 2 PTE is invalid, it’ll skip the next 512 pages, some of which may actually have been mapped:
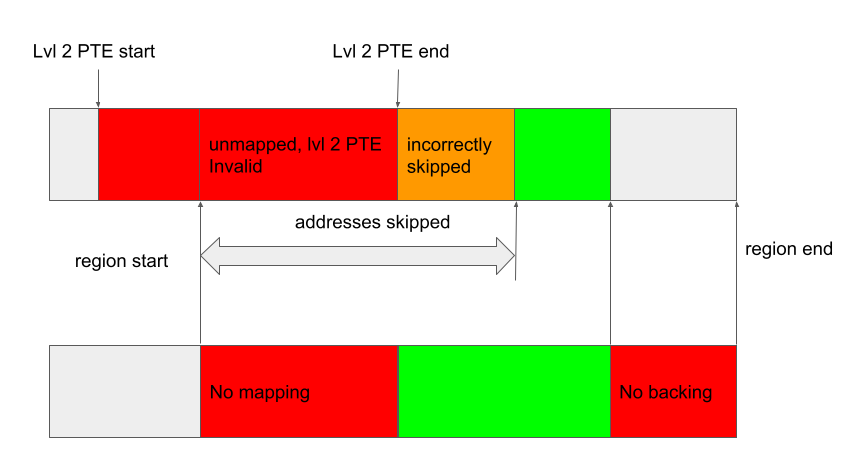
In this case, addresses in the “incorrectly skipped” region will remain mapped to some entries in the pages array in the gpu_alloc, which are already freed. And these “incorrectly skipped” GPU addresses can be used to access already freed memory pages.
Exploiting CVE-2023-6241
The situation, however, is very different when a region is grown during the race window. In this case, nents is larger than old_size when kbase_alloc_phy_pages_helper_locked and kbase_mem_grow_gpu_mapping are called, and delta pages are being inserted at index nents of the pages array:
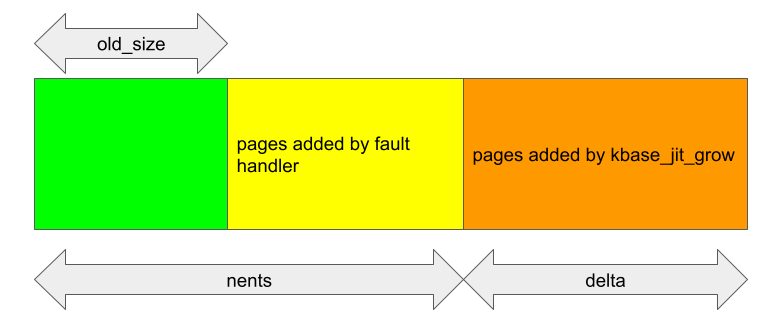
The pages array contains the correct number of pages to backup both the jit grow and the fault access, and is in fact exactly how it should be when kbase_jit_grow is called after the page fault handler.
When kbase_mem_grow_gpu_mapping is called, delta pages are mapped to the GPU from (start_pfn + old_size) * 0x1000. As the total number of backing pages has now increased by fh + delta, where fh is the number of pages added by the fault handler, this leaves the last fh pages in the pages array unmapped.
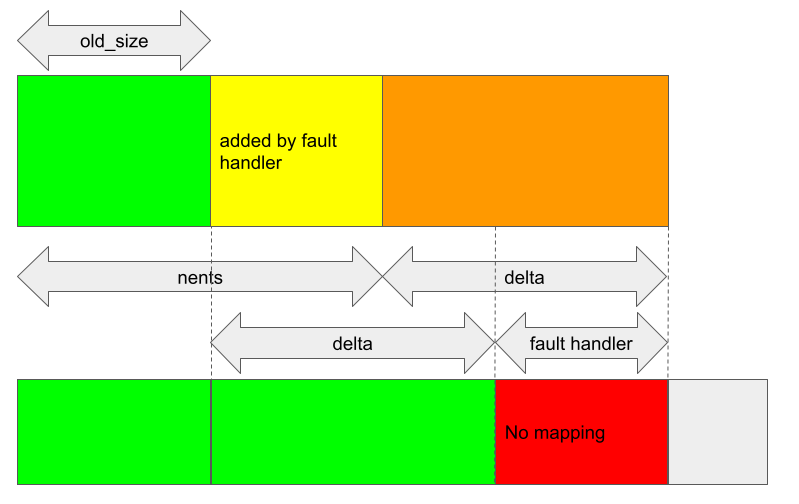
This, however, does not seem to create any problem either. The memory region still only has its start addresses mapped and there is no gap in the mapping. The pages that are not mapped are simply not accessible from the GPU and will get freed when the memory region is deleted, so it isn’t even a memory leak issue.
However, not all is lost. As we have seen, when a GPU page fault happens, if the cause of the fault is that the address is not mapped, then the fault handler will try to add backing pages to the region and map these new pages to the extent of the region. If the fault address is, say fault_addr, then the minimum number of pages to add is new_pages = fault_addr/0x1000 - reg->gpu_alloc->nents. Depending on the kbase_va_region, some padding may also be added. In any case, these new pages will be mapped to the GPU, starting from the address (start_pfn + reg->gpu_alloc->nents) * 0x1000, so as to preserve the fact that only the addresses at the start of a region are mapped.
This means that, if I trigger another GPU fault in the JIT region that was affected by the bug, then some new mappings will be added after the region that is not mapped.
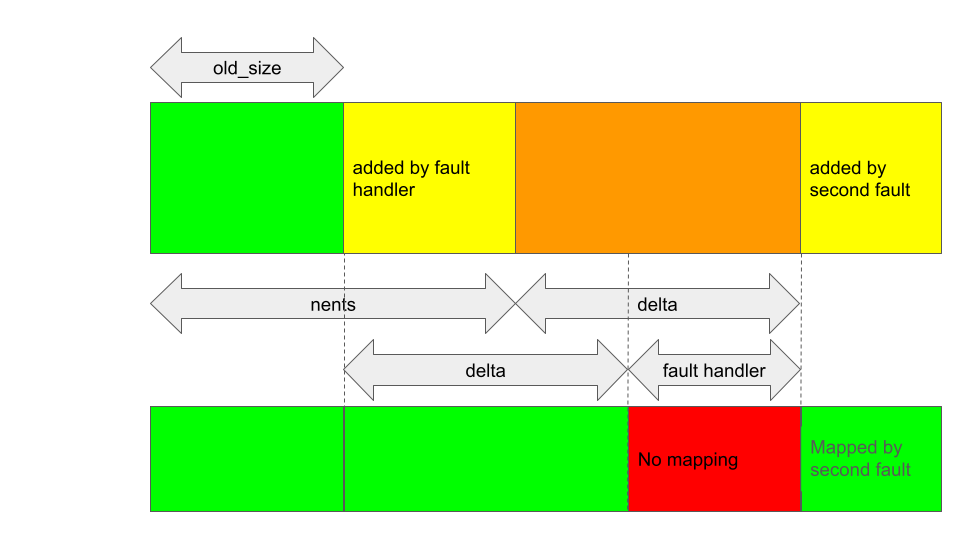
This creates a gap in the GPU mappings, and I’m starting to get something that looks exploitable.
Note that as delta has to be non zero to trigger the bug, and as delta + old_size pages at the start of the region are mapped, it is still not possible to have the start of the region unmapped like in the case of GHSL-2023-005. So, my only option here is to shrink the region and have the resulting size lie somewhere inside the unmapped gap.
The only way to shrink a JIT region is to use the BASE_KCPU_COMMAND_TYPE_JIT_FREE GPU command to “free” the JIT region. As explained before, this does not actually free the kbase_va_region itself, but rather puts it in a memory pool so that it may be reused on subsequent JIT allocation. Prior to this, kbase_jit_free will also shrink the JIT region according to the initial_commit size of the region, as well as the trim_level that is configured in the kbase_context:
void kbase_jit_free(struct kbase_context *kctx, struct kbase_va_region *reg)
{
...
old_pages = kbase_reg_current_backed_size(reg);
if (reg->initial_commit initial_commit,
div_u64(old_pages * (100 - kctx->trim_level), 100));
u64 delta = old_pages - new_size;
if (delta) {
mutex_lock(&kctx->reg_lock);
kbase_mem_shrink(kctx, reg, old_pages - delta);
mutex_unlock(&kctx->reg_lock);
}
}
...
}
Either way, I can control the size of this shrinking. With this in mind, I can arrange the region in the following way:
- Create a JIT region and trigger the bug. Arrange the GPU fault so that the fault handler adds
fault_sizepages, enough pages to cover at least one level 2 PTE.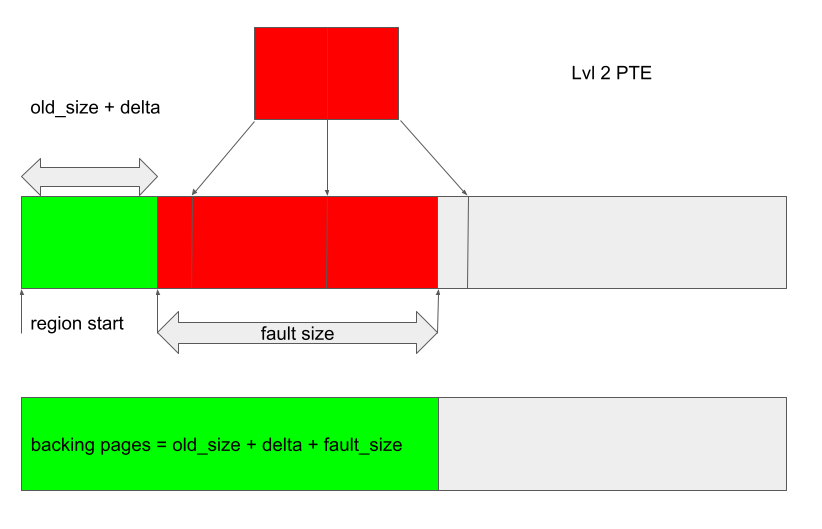
After the bug is triggered, only the initial
old_size + deltapages are mapped to the GPU address space, while thekbase_va_regionhasold_size + delta + fault_sizebacking pages in total. -
Trigger a second fault at an offset greater than the number of backing pages, so that pages are appended to the region and mapped after the unmapped regions created in the previous step.
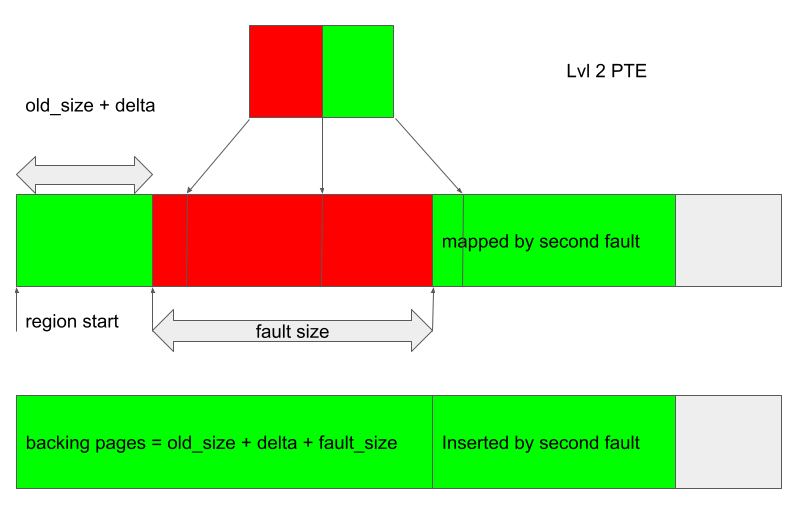
-
Free the JIT region using
BASE_KCPU_COMMAND_TYPE_JIT_FREE, which will callkbase_jit_freeto shrink the region and remove pages from it. Control the size of this trimming either so that the region size after shrinking (final_size) of the backing store lies somewhere within the unmapped region covered by the first level 2 PTE.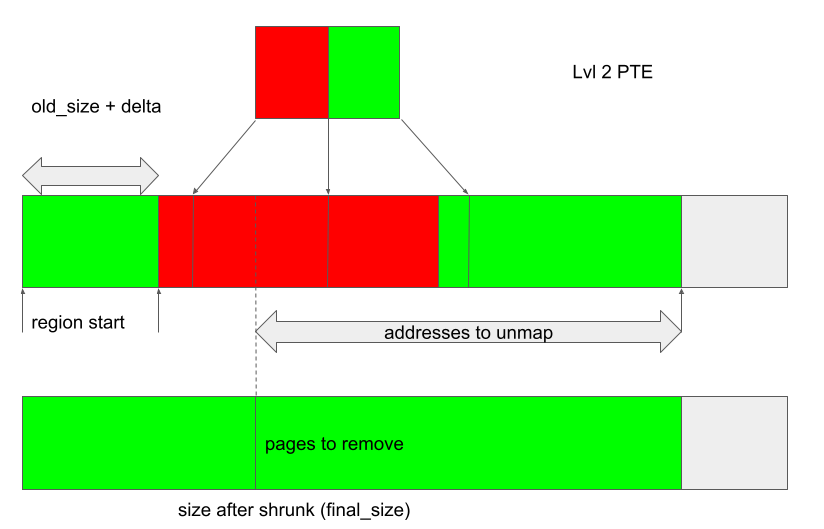
When the region is shrunk, kbase_mmu_teardown_pgd_pages is called to unmap the GPU address mappings, starting from region_start + final_size all the way up to the end of the region. As the entire address range covered by the first level 2 PTE is unmapped, when kbase_mmu_teardown_pgd_pages tries to unmap region_start + final_size, the condition !mmu_mode->pte_is_valid is met at a level 2 PTE and so the unmapping will skip the next 512 pages, starting from region_start + final_size. However, since addresses belonging to the next level 2 PTE are still mapped, these addresses will be skipped incorrectly (the orange region in the next figure), leaving them mapped to pages that are going to be freed:
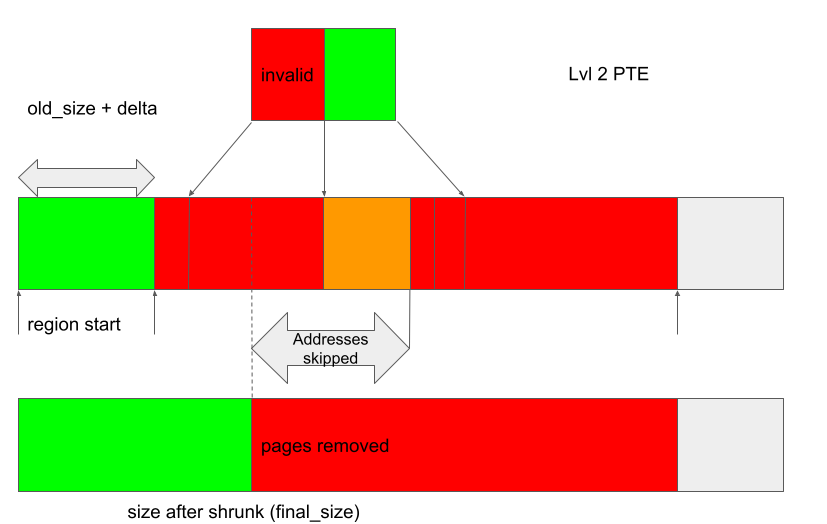
Once the shrinking is completed, the backing pages are freed and the addresses in the orange region will retain access to already freed pages.
This means that the freed backing page can now be reused as any kernel page, which gives me plenty of options to exploit this bug. One possibility is to use my previous technique to replace the backing page as page table global directories (PGD) of our GPU kbase_context.
To recap, let’s take a look at how the backing pages of a kbase_va_region are allocated. When allocating pages for the backing store of a kbase_va_region, the kbase_mem_pool_alloc_pages function is used:
int kbase_mem_pool_alloc_pages(struct kbase_mem_pool *pool, size_t nr_4k_pages,
struct tagged_addr *pages, bool partial_allowed)
{
...
/* Get pages from this pool */
while (nr_from_pool--) {
p = kbase_mem_pool_remove_locked(pool); //next_pool) {
/* Allocate via next pool */
err = kbase_mem_pool_alloc_pages(pool->next_pool, //<----- 2.
nr_4k_pages - i, pages + i, partial_allowed);
...
} else {
/* Get any remaining pages from kernel */
while (i != nr_4k_pages) {
p = kbase_mem_alloc_page(pool); //<------- 3.
...
}
...
}
...
}
The input argument kbase_mem_pool is a memory pool managed by the kbase_context object associated with the driver file that is used to allocate the GPU memory. As the comments suggest, the allocation is actually done in tiers. First the pages will be allocated from the current kbase_mem_pool using kbase_mem_pool_remove_locked (1 in the above). If there is not enough capacity in the current kbase_mem_pool to meet the request, then pool->next_pool, is used to allocate the pages (2 in the above). If even pool->next_pool does not have the capacity, then kbase_mem_alloc_page is used to allocate pages directly from the kernel via the buddy allocator (the page allocator in the kernel).
When freeing a page, provided that the memory region is not evicted, the same happens in the opposite direction: kbase_mem_pool_free_pages first tries to return the pages to the kbase_mem_pool of the current kbase_context, if the memory pool is full, it’ll try to return the remaining pages to pool->next_pool. If the next pool is also full, then the remaining pages are returned to the kernel by freeing them via the buddy allocator.
As noted in my post Corrupting memory without memory corruption, pool->next_pool is a memory pool managed by the Mali driver and shared by all the kbase_context. It is also used for allocating page table global directories (PGD) used by GPU contexts. In particular, this means that by carefully arranging the memory pools, it is possible to cause a freed backing page in a kbase_va_region to be reused as a PGD of a GPU context. (The details of how to achieve this can be found here.)
Once the freed page is reused as a PGD of a GPU context, the GPU addresses that retain access to the freed page can be used to rewrite the PGD from the GPU. This then allows any kernel memory, including kernel code, to be mapped to the GPU. This then allows me to rewrite kernel code and hence execute arbitrary kernel code. It also allows me to read and write arbitrary kernel data, so I can easily rewrite credentials of my process to gain root, as well as to disable SELinux.
The exploit for Pixel 8 can be found here with some setup notes.
How does this bypass MTE?
So far, I’ve not mentioned any specific measures to bypass MTE. In fact, MTE does not affect the exploit flow of this bug at all. While MTE protects against dereferences of pointers against inconsistent memory blocks, the exploit does not rely on any of such dereferencing at all. When the bug is triggered, it creates inconsistencies between the pages array and the GPU mappings of the JIT region. At this point, there is no memory corruption and neither the GPU mappings nor the pages array, when considered separately, contain invalid entries. When the bug is used to cause kbase_mmu_teardown_pgd_pagesto skip removing GPU mappings, its effect is to cause physical addresses of freed memory pages to be retained in the GPU page table. So, when the GPU accesses the freed pages, it is in fact accessing their physical addresses directly, which does not involve any pointer dereferencing either. On top of that, I’m also not sure whether MTE has any effect on GPU memory accesses anyway. So, by using the GPU to access physical addresses directly, I’m able to completely bypass the protection that MTE offers. Ultimately, there is no memory safe code in the code that manages memory accesses. At some point, physical addresses will have to be used directly to access memory.
Conclusion
In this post, I’ve shown how CVE-2023-6241 can be used to gain arbitrary kernel code execution on a Pixel 8 with kernel MTE enabled. While MTE is arguably one of the most significant advances in the mitigations against memory corruptions and will render many memory corruption vulnerabilities unexploitable, it is not a silver bullet and it is still possible to gain arbitrary kernel code execution with a single bug. The bug in this post bypasses MTE by using a coprocessor (GPU) to access physical memory directly (Case 4 in MTE As Implemented, Part 3: The Kernel). With more and more hardware and software mitigations implemented on the CPU side, I expect coprocessors and their kernel drivers to continue to be a powerful attack surface.
Tags:
Written by

Related posts
The case for a cooldown: Why Dependabot now waits before issuing version updates
A new default three-day cooldown delays version update pull requests so maintainers and security researchers can address findings in a release before it gets into your code.

Next chapter: Restructuring GitHub’s bug bounty program
GitHub is making some significant changes to its bug bounty program, shifting its focus to give researchers a better experience working with the GitHub team.
How GitHub gave every repository a durable owner
GitHub had over 14,000 repositories. Fewer than half had clear ownership. Here’s how we gave every active repository a validated owner in under 45 days, archived the rest, and made ownership the foundation for everything that followed.