Get started by running the risk assessment for your organization today, or learn more about secret scanning.
|
5 minutes
Secret scanning plays a critical role in protecting developers and organizations. It helps catch exposed credentials early and prevents small mistakes from turning into real incidents.
At GitHub’s scale, even small inefficiencies create real friction. Too many false positives make alerts harder to trust.
When alerts feel noisy, developers spend more time triaging and less time fixing real issues. Over time, this slows down remediation and reduces confidence in the system.
To address this challenge, GitHub collaborated with Microsoft Security & AI’s Agents Offense team to bring more contextual reasoning into GitHub’s secret scanning verification. The collaboration applied the verification approach from Agentic Secret Finder, a broader detection and verification system developed to understand potential secrets in context, not just whether they match a secret-like pattern. This helped GitHub explore ways to reduce low-value alerts while preserving the coverage you expect from secret scanning.
Secret scanning at GitHub today
GitHub secret scanning combines pattern-based detection with AI-based detection to identify potential secrets. Pattern-based detection catches known secret formats, such as partner patterns for tokens and API keys. AI-powered generic secret detection expands coverage to unstructured secrets like passwords that don’t match a known provider pattern.
GitHub already has industry-leading precision for provider-pattern secret detection at massive scale, processing billions of pushes and protecting tens of millions of developers across millions of repositories.
As GitHub expanded into AI-powered secret detection, the next challenge was bringing the precision of AI-detected secrets closer to the same high standard as provider-pattern detections. This collaboration focused on combining GitHub’s large-scale detection pipeline with LLM-based contextual verification to improve alert quality and developer trust.
Our approach: Make secret scanning alerts trustworthy
Secret scanning is most useful when you can quickly tell which alerts need action.
GitHub already has safeguards to reduce noise, but some secret-like values need more context to determine whether they represent a real exposure. To make those alerts easier to trust, we added more reasoning to the verification step.
By looking at how a detected value appears in code, the system can better separate real exposures from values that only look sensitive. This helps you spend less time investigating low-value alerts and more time fixing the issues that matter.
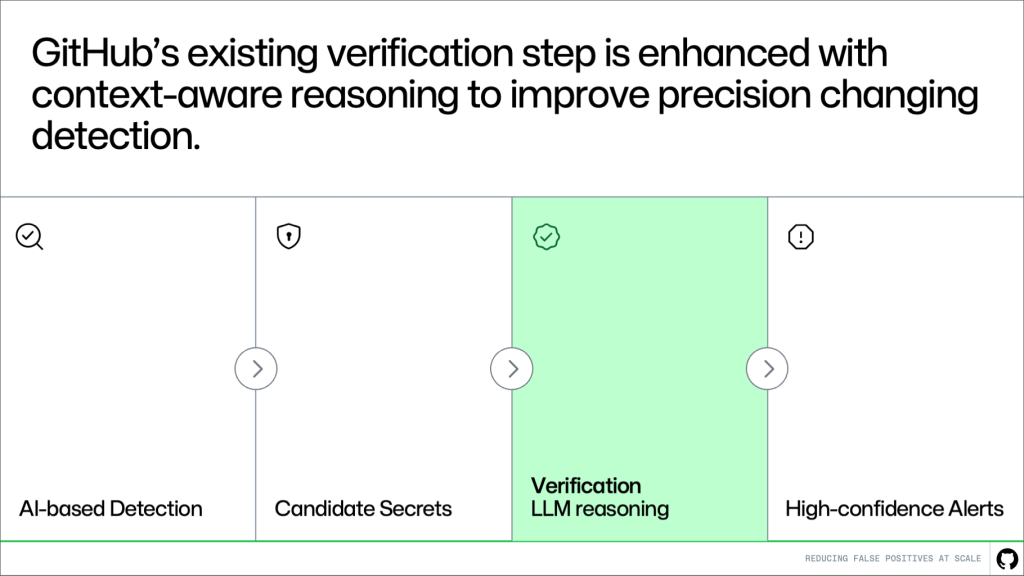
Where this fits in the pipeline
This approach builds directly on the existing system. Detection continues to generate candidates, and the verification step evaluates them. More context-awareness makes this system better at distinguishing real secrets from noise.
The result is higher precision without changing upstream detection logic or reducing coverage.
How it works
A key challenge in verification is deciding what context to provide.
A small snippet of code is often not enough to determine whether something is a real secret. At the same time, passing entire files or repositories introduces too much noise and increases cost and latency.
Instead of giving more context, we’re giving better context.
Rather than send large amounts of code, we extract a small set of high-signal information that helps explain how the value is used. For example, we look for cases where a value is assigned to a variable and later passed into an API request, authentication header, database client, or cloud SDK call. Pattern matching can tell us that a value looks like a secret, but it can’t tell us whether the value is actually being used as one. The surrounding usage context helps the model distinguish real exposures from false alarms, such as random UUIDs or opaque strings, without reviewing the full file or repository.

Focused context, not more data
It’s natural to assume that improving accuracy requires analyzing more of the codebase. But the opposite is true.
Most false positives can be resolved with focused, file-level context. What matters is not how much code the model sees, but whether it has the right signals.
In many cases, you can determine whether a value is a real secret by looking at how it is used within a single file. Values that resemble placeholders, test data, or unused configuration can often be filtered out without deeper analysis.
This keeps the system both effective and practical: high accuracy, low latency, and the ability to scale across large codebases.
Results: reducing false positives in practice
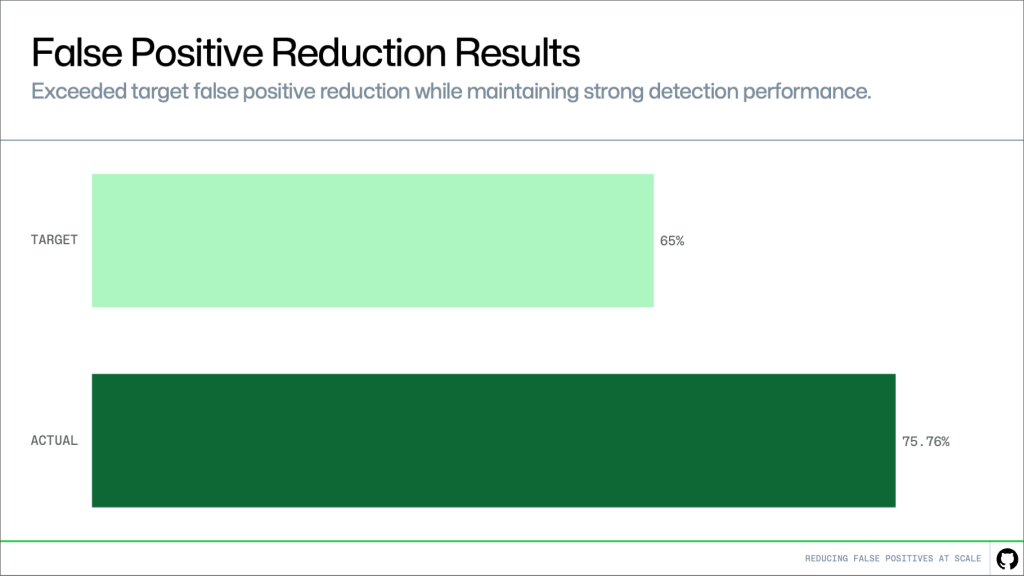
We evaluated this approach on hundreds of customer-confirmed false positive alerts.
Our target was a 65% reduction. The result was 75.76%, exceeding that goal while maintaining strong detection performance.
In practice, this means significantly less noise and a higher proportion of alerts that require action.
This improvement shows up directly in the developer experience. With fewer irrelevant alerts, it becomes easier to trust what you see. Less time is spent triaging noise, and real issues can be prioritized and fixed faster.
What’s next
We’re continuing to evaluate this approach on larger datasets and live traffic, while improving how context is extracted and used for verification.
Reducing false positives has been a consistent need at scale. This work focuses on improving signal quality where it matters most, making alerts easier to trust and act on.
The goal is simple: fewer distractions, clearer signals, and faster action on real risks.
Tags:
Written by

Related posts

How to build interactive experiences with canvases
Canvases turn AI into interactive workspaces where you can visualize information, explore workflows, and take action across complex tasks.
Better tools made Copilot code review worse. Here’s how we actually improved it.
How migrating Copilot code review to shared Unix-style code exploration tools reduced review cost by reshaping agent workflows around pull request evidence.
How GitHub gave every repository a durable owner
GitHub had over 14,000 repositories. Fewer than half had clear ownership. Here’s how we gave every active repository a validated owner in under 45 days, archived the rest, and made ownership the foundation for everything that followed.