The little bug that couldn’t: Securing OpenSSL
Software security doesn’t end at the boundaries of your own code. The moment a library dependency is introduced, you’re adopting other people’s code and any bugs that come with it.…

Software security doesn’t end at the boundaries of your own code. The moment a library dependency is introduced, you’re adopting other people’s code and any bugs that come with it. Code review and good software engineering practices face this problem on a daily basis. Securing a single project is already a difficult task, but trying to also secure the libraries that a project depends on is beyond the resources of most development teams and grows exponentially in size and complexity as your dependencies in turn have their own dependencies. GitHub’s State of the Octoverse reports that up to 94% of projects rely on open source components, with nearly 700 dependencies per repository.
This is why working to improve the security of widely used libraries has a force multiplication effect that can positively impact every single project that depends on the library. Focusing on library code is a great way to optimize for limited security research resources.
This post focuses on OpenSSL, a library that’s a core dependency for the cryptographic needs of a lot of software, particularly when it comes to SSL/TLS support. In the course of my work as a GitHub security researcher, I found two security bugs in the OpenSSL library. The first is detailed in advisory GHSL-2020-056, and the second is my main topic here.
Choose your own adventure!
You can read this post from two different perspectives. The first perspective is that of a developer, for whom I’ll demonstrate how to use CodeQL to find variants of bugs, patch them, and make sure they aren’t introduced again. The second perspective is that of a security researcher, for whom I’ll explain the details and impact of the vulnerabilities. Skip to the section you’re interested in!
Using CodeQL to find and patch bug variants
Context matters
Every bug report has its own unique history and my OpenSSL bug was no exception. So why doesn’t this bug have an advisory or CVE associated with it? I was in the process of writing a report when it was independently found and fixed by the OpenSSL team. Such bug collisions aren’t uncommon when researching popular projects that are under a lot of scrutiny. It’s a great sign that the OpenSSL team is actively uncovering and fixing issues like this.
Commit a9612d6c in the OpenSSL library introduced a subtle bug that altered the order in which the big number context (BN_CTX) object is initialized. To make sense of the bug and its impact, we first need to learn what a BN_CTX is and how it operates.
What is a BN_CTX?
A BN_CTX is a memory allocator for a special kind of object called BIGNUM. The API for it is very simple: To create a new batch of BIGNUM objects, BN_CTX_start should be called before using BN_CTX_get to obtain objects. Once the objects are not needed anymore, BN_CTX_end should be called to reclaim the allocated memory.
Going into a little more detail, BN_CTX_start creates a new slab of contiguous memory that is broken into smaller chunks. These chunks are then returned to the user when they use BN_CTX_get to allocate memory. Unlike an allocator (like malloc), each allocation is not supposed to be freed individually. The mechanism used to reclaim memory is to call BN_CTX_end to free the whole slab of memory. Once memory is reclaimed, any object returned by BN_CTX_get should no longer be used as it is now in an unknown state.
As with most allocators, if you fail to use their API correctly, memory management issues can happen (such as leaks, use after frees, and crashes), and this case is no exception. One of the things that can go wrong is a mismatch between the calls to BN_CTX_start and BN_CTX_end. This scenario leads to memory corruption if, for instance, you call BN_CTX_end while still holding and using references to memory allocated in a now gone context.
Here’s an example:. Say function “A” needs to work with BIGNUMs. To do so, it creates a new slab of objects by calling BN_CTX_start and uses BN_CTX_get to get references to those objects. Now function “A” needs to call function “B” to perform another operation. In general, the BN_CTX is passed along to other functions because otherwise a new one should be created. So function “A” calls function “B” and passes a reference to BN_CTX. Now function “B” needs to create BIGNUMs, and it should call BN_CTX_start, but for some reason (maybe an error condition) it bails out and calls (incorrectly) BN_CTX_end. This last call to the API will not free the intended objects corresponding to the function “B” but will free the objects used by function “A.” Remember that function “B” never actually called BN_CTX_start, therefore there’s no memory slab allocated for it. This is bad because function “A” will most likely continue to use the objects it allocated–but in this case those objects will be in a free state, and possibly allocated by another function or even by a completely different thread of execution.
These kinds of issues can be exploited in a variety of ways, most of them application specific. But the general idea would be to influence the memory layout of the targeted application via API interactions that end up allocating process-critical memory objects into the previously freed memory space to which there are now erroneous references available to the attacker. While those process critical memory objects are in use, an attacker would then use those faulty memory references to rewrite, or otherwise manipulate, the memory while it is actively being used by the application. A simple example would involve an object that contains a function pointer. If the attacker is able to use their erroneous access to the reclaimed memory to overwrite a function pointer in an object before it is called, they would be able to redirect execution in the application.
In the code snippet below (introduced by a9612d6c) you can see a concrete example of this theoretical scenario. The error condition that triggers the bug is when the elliptic curve group (EC_GROUP) contains no Montgomery data (mont_data). In this case, the code jumps over the call to BN_CTX_start and goes straight into a call to BN_CTX_end.
static int ec_field_inverse_mod_ord(const EC_GROUP *group, BIGNUM *r, const BIGNUM *x, BN_CTX *ctx)
{
BIGNUM *e = NULL;
int ret = 0;
#ifndef FIPS_MODE
BN_CTX *new_ctx = NULL;
if (ctx == NULL)
ctx = new_ctx = BN_CTX_secure_new();
#endif
if (ctx == NULL)
return 0;
if (group->mont_data == NULL)
goto err;
BN_CTX_start(ctx);
if ((e = BN_CTX_get(ctx)) == NULL)
goto err;
// ...
err:
BN_CTX_end(ctx);
#ifndef FIPS_MODE
BN_CTX_free(new_ctx);
#endif
return ret;
}
Finding all the bug variants
One of the fundamental concepts that this bug illustrates is that reasoning about the control flow of programs is a very hard thing to do, especially when certain side effects are not evident, such as the behavior I discussed before.
With this in mind, I set about finding variants of the bug using CodeQL. CodeQL is particularly useful in this case because it allows you to reason about the control flow of the application. In theory, this should make it possible to find the bug in question and others like it.
When writing CodeQL queries, I recommend putting the pattern you’d like to find into words. In my case, what I want to find would be, “A path in the control flow graph that contains a call to BN_CTX_end but not to BN_CTX_start”.
Working with path problems can be confusing because it requires you to express things in ways that may not be that intuitive. In my case, I need to build a path from the start of a function that reaches a BN_CTX_end without passing through any call to BN_CTX_start.
I started expressing this idea with CodeQL predicates.
predicate isInteresting(ControlFlowNode a, ControlFlowNode b) {
not a instanceof BN_CTX_start and
b = a.getASuccessor()
}
This predicate contains all the tuples (a, b) that satisfy the expression in the body. In other words, the node “a” is not a call to BN_CTX_start and the node “b” is an immediate successor to the control flow node “a”. You can think of the tuple (a, b) as a link in a chain. But, this only expresses a part of my requirements. In order to get the whole path, I need to apply this predicate from the start of the function until a call to BN_CTX_end occurs. One way to do this in CodeQL is to transitively apply the predicate using a transitive closure.
Intuitively, a transitive closure builds a path ((a, b), (b, c), … ) by repeatedly applying the predicate until the predicate no longer holds or there are no more nodes. The requirement for a predicate to be used as a transitive closure is that it has to take two arguments that are of compatible types. Luckily, my predicate is perfectly suited for exactly that kind of use.
import cpp
class BN_CTX_start extends FunctionCall {
BN_CTX_start() { getTarget().getName() = "BN_CTX_start" }
}
class BN_CTX_end extends FunctionCall {
BN_CTX_end() { getTarget().getName() = "BN_CTX_end" }
}
predicate isInteresting(ControlFlowNode a, ControlFlowNode b) {
b = a.getASuccessor() and
not a instanceof BN_CTX_start
}
from BN_CTX_end end, ControlFlowNode entryPoint
where
entryPoint = end.getEnclosingFunction().getEntryPoint() and
isInteresting+(entryPoint, end)
select entryPoint, endCheck the results of this query on LGTM.com
The way you turn a predicate into a transitive closure is by using the + operator at the end of the predicate. This will instruct CodeQL to apply the predicate in the correct way and gives you all the results that satisfy it.
As mentioned before, isInteresting+(a, b) will build a path from node “a” to node “b”. In our case we would like “a” to be the start of the function and “b” a call to BN_CTX_end.
Running that query on OpenSSL returns 36 results, and among those results you can find our case study bug, so I must be on the right track. However, there’s a problem. The way I get the results is not very useful: I only get two control flow nodes and no information about how they’re actually connected to each other.
To make things clearer, I need a way to tell CodeQL to generate what’s called a path explanation. A path explanation is a special kind of query that follows a certain structure. In essence, it needs a predicate called edges that builds the path and the metadata to tell CodeQL that it is a path-problem so the CodeQL VSCode plugin UI knows how to display the results properly. Luckily, my existing isInteresting predicate matches all the criteria to serve as the required edges predicate, and I can simply rename it to edges and let CodeQL know that I want my query results interpreted as a path problem via the @kind path-problem metadata tag.
The new version of the query looks like this:
/**
* @kind path-problem
*/
import cpp
class BN_CTX_start extends FunctionCall {
BN_CTX_start() { getTarget().getName() = "BN_CTX_start" }
}
class BN_CTX_end extends FunctionCall {
BN_CTX_end() { getTarget().getName() = "BN_CTX_end" }
}
query predicate edges(ControlFlowNode a, ControlFlowNode b) {
b = a.getASuccessor() and
not a instanceof BN_CTX_start
}
from BN_CTX_end end, ControlFlowNode entryPoint
where
entryPoint = end.getEnclosingFunction().getEntryPoint() and
edges+(entryPoint, end)
select end, entryPoint, end, "Finalised context may not have been started."Check the results of this query on LGTM.com
Running the new query returns the same 36 results, which is a good indication that I haven’t done anything terribly wrong in terms of transforming the query to a path-problem query, but now the results are presented in a much more readable way in the UI:
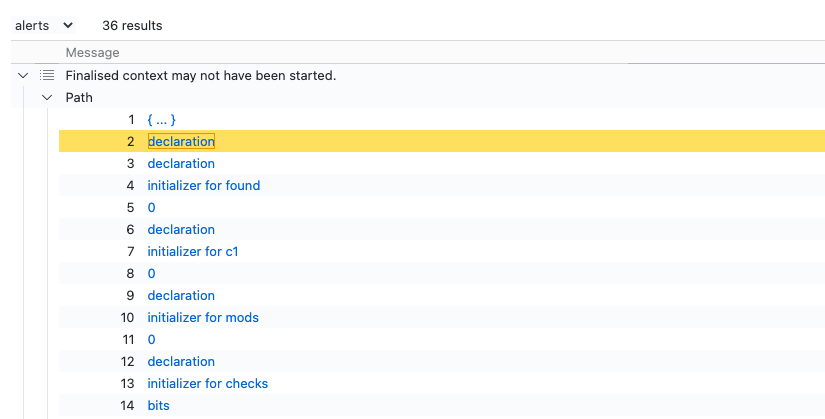
Great! Now I can follow the path from the entry point to the call to BN_CTX_end much more easily. But there is still something I can do to make this even more readable. As can be seen in the results, each node path corresponds to a ControlFlowNode. This kind of granularity doesn’t add any meaningful data to the results so it would be better if I could do this at the basic block level instead.
Luckily again, the changes I need to make to my query are very minor. I just need to change the edges predicate to take BasicBlock types as its arguments and adjust it slightly:
query predicate edges(BasicBlock a, BasicBlock b) {
b = a.getASuccessor() and
not a.getANode() instanceof BN_CTX_start
}
from BN_CTX_end end, ControlFlowNode entryPoint
where
entryPoint = end.getEnclosingFunction().getEntryPoint() and
edges+(entryPoint.getBasicBlock(), end.getBasicBlock())
select end, entryPoint.getBasicBlock(), end.getBasicBlock(),
"Finalised context may not have been started."Check the results of this query on LGTM.com
With these changes, the query results are much more readable to the human eye and allow me to follow the exact paths that result in mismatched start/end cases:
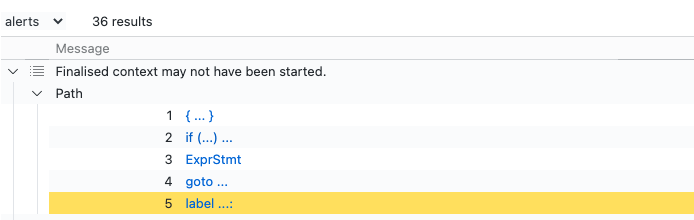
Fixing all the bugs
Even though my query returned 36 results, only four of them are actually true positives. I could have improved the query to be more precise, but since the number of results was pretty manageable by manual review, I decided not to invest more time improving it further. I find that using CodeQL in this kind of hybrid exploratory way makes it a great auditing companion.
The additional issues are similar to the one explained previously but are not considered security issues due to the context in which they appear, and they have been fixed by this PR.
In too deep: Determining the impact of the vulnerability
So we have a bug, but what is its impact? Is it exploitable? To answer these questions we need to understand what the affected function does.
The bug is located in the function ec_field_inverse_mod_ord which calculates the multiplicative inverse of a BIGNUM and returns it. In order to do so in an efficient way, it uses Montgomery modular multiplication, which is a special way to perform operations that suits the task better.
So far, we know what the function does, but can we reach this code in such a way that an attacker can provide the needed elements for exploitation? The answer is certainly “yes” because the computation of the multiplicative inverse is a rather common operation. One such operation is the verification of a certificate signature by using the X509_verify API.
Going back to the bug conditions, to trigger the vulnerable code path, we need to perform the multiplicative inverse operation in an EC_GROUP that does not have mont_data. Looking at all the assignments to this field, you can see that it is only assigned by the function ec_precompute_mont_data which gets called when the order of the EC_GROUP is odd:
if (BN_is_odd(group->order)) {
return ec_precompute_mont_data(group);
}
So if you can find an elliptic curve with an even group order, you can trigger this vulnerability, but is such a thing even possible? Let’s try to build a proof of concept and see how far we get.
Proof of concept
Since the vulnerability has been patched, first you need to compile the library at a specific commit as shown below:
git clone https://github.com/openssl/openssl.git
cd openssl
git checkout -b vulnerable a9612d6c034f47c4788c67d85651d0cd58c3faf7And then compile and install it into a debugging environment (to avoid replacing the systems version of OpenSSL):
export INSTALL_DIR="$HOME/Installations/openssl-debug"
./config --debug --openssldir=$INSTALL_DIR --prefix=$INSTALL_DIR no-shared no-threads no-tests enable-asan enable-ubsan
make
make install
Now that you have a debug version of OpenSSL, you can build a small test case that will generate a certificate using the correct curve, and you can use X509_verify to trigger the vulnerability. The code for the proof of concept can be found here.
As stated before, you need an even curve. To find out if there is such a thing, I went over all the available curves and verified if the group order was even:
std::optional<EC_builtin_curve> EC_get_even_curve()
{
// Get the builtin curves.
size_t count = EC_get_builtin_curves(nullptr, 0);
std::vector<EC_builtin_curve> curves(count);
EC_get_builtin_curves(curves.data(), count);
// Find a curve that has an even order.
for (auto curve : curves)
{
auto eckey = EC_KEY_new_by_curve_name(curve.nid);
auto group = EC_KEY_get0_group(eckey);
auto ctx = BN_CTX_new();
auto order = BN_new();
EC_GROUP_get_order(group, order, ctx);
if (!BN_is_odd(order))
return curve;
}
return {};
}
The rest of the code in the proof of concept creates an X509 certificate using the curve we just found. Once the curve is found, a key is generated and assigned as the public key of the certificate. Then the certificate is signed using another key in a different curve. I could have used the first curve, but it triggered the bug so I just created an extra one and called it a day.
With your certificate signed, you need to see if you can trigger the bug by trying to verify its signature using X509_verify.
Compiling the proof of concept is simple; just execute the commands below:
export PKG_CONFIG_PATH=$HOME/Installations/openssl-debug/lib/pkgconfig
clang++ test.cc -o test -fsanitize=address $(pkg-config --libs --cflags openssl) -g -std=c++17Then run the proof of concept executable in a debugger:
$ lldb test
(lldb) target create "test"
Current executable set to '/Users/goose/Work/Research/projects/openssl/bugs/bug2/test' (x86_64).
(lldb) r
Process 66228 launched: '/Users/goose/Work/Research/projects/openssl/bugs/bug2/test' (x86_64)
Process 66228 stopped
* thread #1, queue = 'com.apple.main-thread', stop reason = EXC_BAD_ACCESS (code=2, address=0x60c40000fffc)
frame #0: 0x0000000100167ad1 test`BN_STACK_pop(st=0x0000607000009f10) at bn_ctx.c:300:12
297
298 static unsigned int BN_STACK_pop(BN_STACK *st)
299 {
-> 300 return st->indexes[--(st->depth)];
301 }
302
303 /***********/
Target 0: (test) stopped.
(lldb) bt
* thread #1, queue = 'com.apple.main-thread', stop reason = EXC_BAD_ACCESS (code=2, address=0x60c40000fffc)
* frame #0: 0x0000000100167ad1 test`BN_STACK_pop(st=0x0000607000009f10) at bn_ctx.c:300:12
frame #1: 0x0000000100167468 test`BN_CTX_end(ctx=0x0000607000009ef0) at bn_ctx.c:216:27
frame #2: 0x0000000100439b99 test`ossl_ecdsa_verify_sig(dgst="\x060��!����:�#\x13�\�E\x94, dgst_len=32, sig=0x0000602000016ed0, eckey=0x0000608000003220) at ecdsa_ossl.c:421:5
frame #3: 0x000000010043a945 test`ECDSA_do_verify(dgst="\x060��!����:�#\x13�\�E\x94, dgst_len=32, sig=0x0000602000016ed0, eckey=0x0000608000003220) at ecdsa_vrf.c:24:16
frame #4: 0x0000000100438b3a test`ossl_ecdsa_verify(type=672, dgst="\x060��!����:�#\x13�\�E\x94, dgst_len=32, sigbuf="0\"\x02\x0f", sig_len=36, eckey=0x0000608000003220) at ecdsa_ossl.c:310:11
frame #5: 0x000000010043ac79 test`ECDSA_verify(type=672, dgst="\x060��!����:�#\x13�\�E\x94, dgst_len=32, sigbuf="0\"\x02\x0f", sig_len=36, eckey=0x0000608000003220) at ecdsa_vrf.c:39:16
frame #6: 0x000000010043084f test`pkey_ec_verify(ctx=0x00006080000034a0, sig="0\"\x02\x0f", siglen=36, tbs="\x060��!����:�#\x13�\�E\x94, tbslen=32) at ec_pmeth.c:146:11
frame #7: 0x00000001005f2f35 test`EVP_PKEY_verify(ctx=0x00006080000034a0, sig="0\"\x02\x0f", siglen=36, tbs="\x060��!����:�#\x13�\�E\x94, tbslen=32) at pmeth_fn.c:82:12
frame #8: 0x00000001005d8713 test`EVP_DigestVerifyFinal(ctx=0x0000607000009e10, sig="0\"\x02\x0f", siglen=36) at m_sigver.c:207:12
frame #9: 0x00000001005d8caa test`EVP_DigestVerify(ctx=0x0000607000009e10, sigret="0\"\x02\x0f", siglen=36, tbs="0R\x02\x01", tbslen=84) at m_sigver.c:217:12
frame #10: 0x000000010007ed40 test`ASN1_item_verify(it=0x0000000100cc89e0, a=0x0000613000002588, signature=0x0000613000002598, asn=0x0000613000002500, pkey=0x0000611000002c00) at a_verify.c:166:11
frame #11: 0x0000000100a00bbf test`X509_verify(a=0x0000613000002500, r=0x0000611000002c00) at x_all.c:170:13
frame #12: 0x00000001000053b0 test`main(argc=1, argv=0x00007ffeefbff898) at test.cc:80:5
frame #13: 0x00007fff20338621 libdyld.dylib`start + 1
frame #14: 0x00007fff20338621 libdyld.dylib`start + 1
(lldb)
The proof of concept demonstrates a simple crash on an unmapped memory address but with enough program state manipulation that I think code execution could be achieved.
I triggered the bug by using X509_verify, which would emulate a client verifying the certificate of a server, but since the inverse multiplicative operation is used in several places, I’m quite sure there are better ways to trigger this bug and maybe turn it into a “server” remote. But this is left as an exercise for the reader.
Further reading
My first dive into cryptography related software led to some interesting results that my team detailed in multiple advisories and blog posts. Most all of my findings in this effort were focused on OpenSSL API misuse, i.e. mistakes that were introduced by users of the OpenSSL library rather than OpenSSL itself:
- GHSL-2020-097: Missing hostname validation in twitter-stream – CVE-2020-24392
- GHSL-2020-096: Missing hostname validation in tweetstream – CVE-2020-24393
- GHSL-2020-095: Monster in the middle attack in em-imap – CVE-2020-13163
- GHSL-2020-026: Person in the middle attacks with lua-openssl
- GHSL-2020-003, GHSL-2020-004, GHSL-2020-005: Person in the middle attack on openfortivpn clients
Thanks
I would like to thank Pavel Avgustinov for his help on the CodeQL query and Matt Caswell from OpenSSL for his help on getting the code merged into OpenSSL.
Tags:
Written by

Related posts
The case for a cooldown: Why Dependabot now waits before issuing version updates
A new default three-day cooldown delays version update pull requests so maintainers and security researchers can address findings in a release before it gets into your code.

Next chapter: Restructuring GitHub’s bug bounty program
GitHub is making some significant changes to its bug bounty program, shifting its focus to give researchers a better experience working with the GitHub team.
How GitHub gave every repository a durable owner
GitHub had over 14,000 repositories. Fewer than half had clear ownership. Here’s how we gave every active repository a validated owner in under 45 days, archived the rest, and made ownership the foundation for everything that followed.