Under the hood: Security architecture of GitHub Agentic Workflows
GitHub Agentic Workflows are built with isolation, constrained outputs, and comprehensive logging. Learn how our threat model and security architecture help teams run agents safely in GitHub Actions.
Whether you’re an open-source maintainer or part of an enterprise team, waking up to documentation fixes, new unit tests, and refactoring suggestions can be a true “aha” moment. But automation also raises an important concern: how do you put guardrails on agents that have access to your repository and the internet? Will you be wondering if your agent relied on documentation from a sketchy website, or pushed a commit containing an API token? What if it decides to add noisy comments to every open issue one day? Automations must be predictable to offer durable value.
But what is the safest way to add agents to existing automations like CI/CD? Agents are non-deterministic: They must consume untrusted inputs, reason over repository state, and make decisions at runtime. Letting agents operate in CI/CD without real-time supervision allows you to scale your software engineering, but it also requires novel guardrails to keep you from creating security problems.
GitHub Agentic Workflows run on top of GitHub Actions. By default, everything in an action runs in the same trust domain. Rogue agents can interfere with MCP servers, access authentication secrets, and make network requests to arbitrary hosts. A buggy or prompt-injected agent with unrestricted access to these resources can act in unexpected and insecure ways.
That’s why security is baked into the architecture of GitHub Agentic Workflows. We treat agent execution as an extension of the CI/CD model—not as a separate runtime. We separate open‑ended authoring from governed execution, then compile a workflow into a GitHub Action with explicit constraints such as permissions, outputs, auditability, and network access.
This post explains how we built Agentic Workflows with security in mind from day one, starting with the threat model and the security architecture that it needs.
Threat model
There are two properties of agentic workflows that change the threat model for automation.
First, agents’ ability to reason over repository state and act autonomously makes them valuable, but it also means they cannot be trusted by default—especially in the presence of untrusted inputs.
Second, GitHub Actions provide a highly permissive execution environment. A shared trust domain is a feature for deterministic automation, enabling broad access, composability, and good performance. But when combined with untrusted agents, having a single trust domain can create a large blast radius if something goes wrong.
Under this model, we assume an agent will try to read and write state that it shouldn’t, communicate over unintended channels, and abuse legitimate channels to perform unwanted actions. By default, GitHub Agentic Workflows run in a strict security mode with this threat model in mind, and their design is guided by four security principles: defense in depth, don’t trust agents with secrets, stage and vet all writes, and log everything.
Defend in depth
GitHub Agentic Workflows provide a layered security architecture consisting of substrate, configuration, and planning layers. Each layer limits the impact of failures above it by enforcing distinct security properties that are consistent with its assumptions.
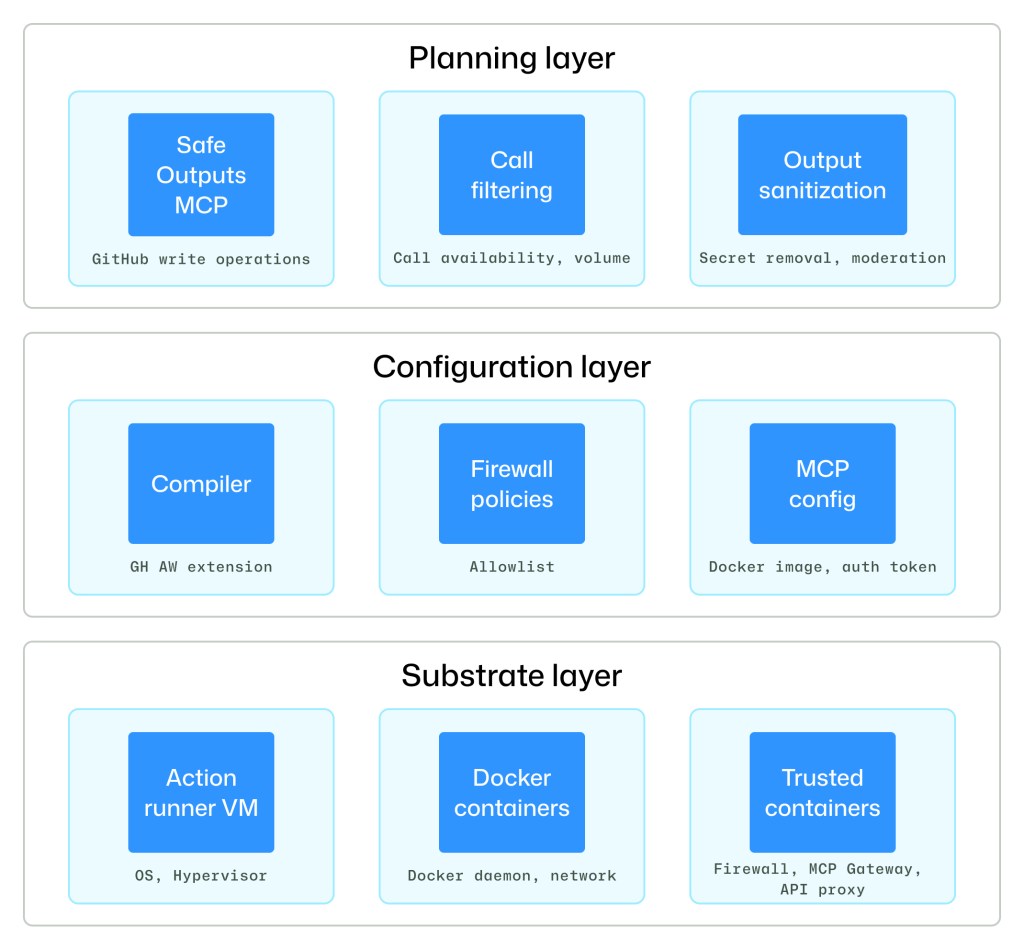
The substrate layer rests on a GitHub Actions runner virtual machine (VM) and several trusted containers that limit the resources an agent can access. Collectively, the substrate level provides isolation among components, mediation of privileged operations and system calls, and kernel-enforced communication boundaries. These protections hold even if an untrusted user-level component is compromised and executes arbitrary code within its container isolation boundary.
Above the substrate layer is a configuration layer that includes declarative artifacts and the toolchains that interpret them to instantiate a secure system structure and connectivity. The configuration layer dictates which components are loaded, how components are connected, what communication channels are permitted, and what privileges are assigned. Externally minted tokens, such as agent API keys and GitHub access tokens, are critical inputs that bound components’ external effects—configuration controls which tokens are loaded into which containers.
The final layer of defense is the planning layer. The configuration layer dictates which components exist and how they communicate, but it does not dictate which components are active over time. The planning layer’s primary responsibility is to create a staged workflow with explicit data exchanges between them. The safe outputs subsystem, which will be described in greater detail below, is the primary instance of secure planning.
Don’t trust agents with secrets
From the beginning, we wanted workflow agents to have zero access to secrets. Agentic workflows execute as GitHub Actions, in which components share a single trust domain on top of the runner VM. In that model, sensitive material like agent authentication tokens and MCP server API keys reside in environment variables and configuration files visible to all processes in the VM.
This is dangerous because agents are susceptible to prompt injection: Attackers can craft malicious inputs like web pages or repository issues that trick agents into leaking sensitive information. For example, a prompt-injected agent with access to shell-command tools can read configuration files, SSH keys, Linux /proc state, and workflow logs to discover credentials and other secrets. It can then upload these secrets to the web or encode them within public-facing GitHub objects like repository issues, pull requests, and comments.
Our first mitigation was to isolate the agent in a dedicated container with tightly controlled egress: firewalled internet access, MCP access through a trusted MCP gateway, and LLM API calls through an API proxy. To limit internet access, agentic workflows create a private network between the agent and firewall. The MCP gateway runs in a separate trusted container, launches MCP servers, and has exclusive access to MCP authentication material.
Although agents like Claude, Codex, and Copilot must communicate with an LLM over an authenticated channel, we avoid exposing those tokens directly to the agent’s container. Instead, we place LLM auth tokens in an isolated API proxy and configure agents to route model traffic through that proxy.
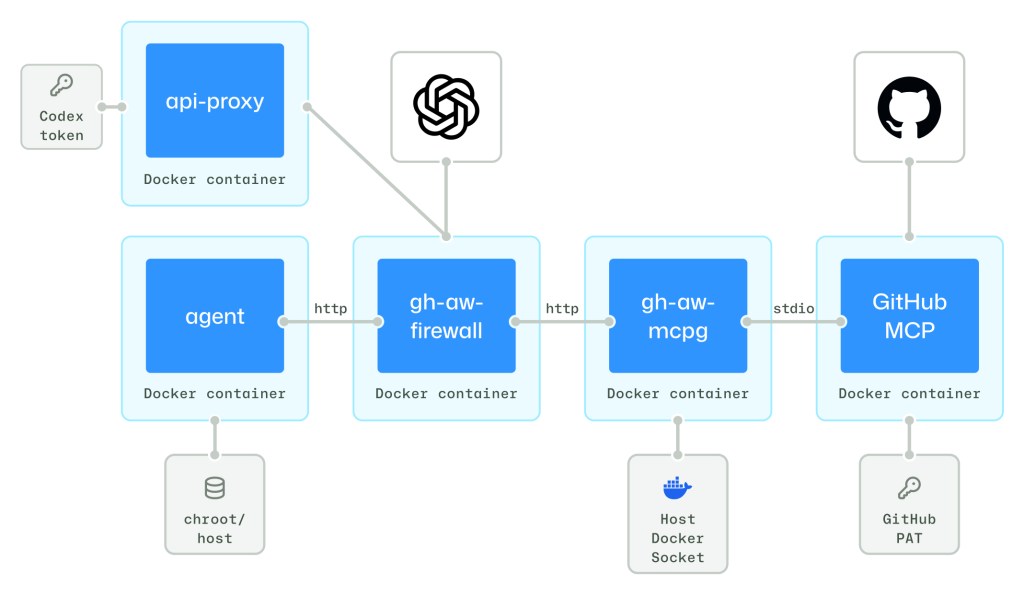
Zero-secret agents require a fundamental trade-off between security and utility. Coding workloads require broad access to compilers, interpreters, scripts, and repository state, but expanding the in-container setup would duplicate existing actions provisioning logic and increase the set of network destinations that must be allowed through the firewall.
Instead, we carefully expose host files and executables using container volume mounts and run the agent in a chroot jail. We start by mounting the entire VM host file system read-only at /host. We then overlay selected paths with empty tmpfs layers and launch the agent in a chroot jail rooted at /host. This approach keeps the host-side setup intact while constraining the agent’s writable and discoverable surface to what it needs for its job.
Stage and vet all writes
Prompt-injected agents can still do harm even if they do not have access to secrets. For example, a rogue agent could spam a repository with pointless issues and pull requests to overwhelm repository maintainers, or add objectionable URLs and other content in repository objects.
To prevent this kind of behavior, the agentic workflows compiler decomposes workflows into explicit stages and defines, for each stage:
- The active components and permissions (read vs. write)
- The data artifacts emitted by that stage
- The admissible downstream consumers of those artifacts
While the agent runs, it can read GitHub state through the GitHub MCP server and can only stage its updates through the safe outputs MCP server. Once the agent exits, write operations that have been buffered by the safe outputs MCP server are processed by a suite of safe outputs analyses.
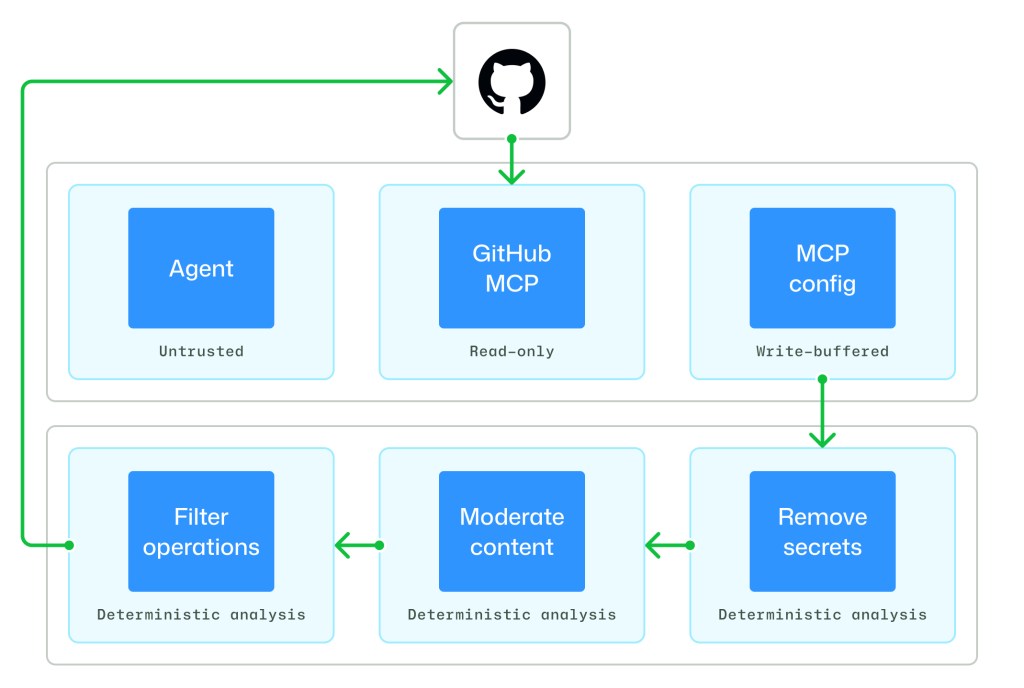
First, safe outputs allow workflow authors to specify which write operations an agent can perform. Authors can choose which subset of GitHub updates are allowed, such as creating issues, comments, or pull requests. Second, safe outputs limits the number of updates that are allowed, such as restricting an agent to creating at most three pull requests in a given run. Third, safe outputs analyzes update content to remove unwanted patterns, such as output sanitization to remove URLs. Only artifacts that pass through the entire safe outputs pipeline can be passed on, ensuring that each stage’s side effects are explicit and vetted.
Log everything
Even with zero secrets and vetted writes, an agent can still transform repository data and invoke tools in unintended ways or try to break out of the constraints that we impose upon it. Agents are determined to accomplish their tasks by any means and have a surprisingly deep toolbox of tricks for doing so. If an agent behaves unexpectedly, post-incident analysis requires visibility into the complete execution path.
Agentic workflows make observability a first-class property of the architecture by logging extensively at each trust boundary. Network and destination-level activity is recorded at the firewall layer, model request/response metadata and authenticated requests are captured by the API proxy; and tool invocations are logged by the MCP gateway and MCP servers. We also add internal instrumentation to the agent container to audit potentially sensitive actions like environment variable accesses. Together, these logs support end-to-end forensic reconstruction, policy validation, and rapid detection of anomalous agent behavior.
Pervasive logging also lays the foundation for future information-flow controls. Every location where communication can be observed is also a location where it can be mediated. Agentic workflows already support the GitHub MCP server’s lockdown mode, and in the coming months, we’ll introduce additional safety controls that enforce policies across MCP servers based on visibility (public vs. private) and the role of a repository object’s author.
What’s next?
We’d love for you to be involved! Share your thoughts in the Community discussion or join us (and tons of other awesome makers) in the #agentic-workflows channel of the GitHub Next Discord. We look forward to seeing what you build with GitHub Agentic Workflows. Happy automating, and keep an eye out for more updates!
Tags:


Related posts
GitHub recognized as a Leader in the Gartner® Magic Quadrant™ for Enterprise AI Coding Agents for the third year in a row
We are committed to empowering every developer by building an open, secure, and AI-powered platform that defines the future of software development.
Take your local GitHub sessions anywhere
Kick off work in VS Code or the CLI, finish it from your phone. Remote control for GitHub Copilot sessions is now generally available on github.com and GitHub Mobile.
Building a general-purpose accessibility agent—and what we learned in the process
Learn about the experimental general-purpose accessibility agent that GitHub is piloting.