A developer’s guide to prompt engineering and LLMs
Prompt engineering is the art of communicating with a generative AI model. In this article, we’ll cover how we approach prompt engineering at GitHub, and how you can use it to build your own LLM-based application.

In a blog post authored back in 2011, Marc Andreessen warned that, “Software is eating the world.” Over a decade later, we are witnessing the emergence of a new type of technology that’s consuming the world with even greater voracity: generative artificial intelligence (AI). This innovative AI includes a unique class of large language models (LLM), derived from a decade of groundbreaking research, that are capable of out-performing humans at certain tasks. And you don’t have to have a PhD in machine learning to build with LLMs—developers are already building software with LLMs with basic HTTP requests and natural language prompts.
In this article, we’ll tell the story of GitHub’s work with LLMs to help other developers learn how to best make use of this technology. This post consists of two main sections: the first will describe at a high level how LLMs function and how to build LLM-based applications. The second will dig into an important example of an LLM-based application: GitHub Copilot code completions.
Others have done an impressive job of cataloging our work from the outside. Now, we’re excited to share some of the thought processes that have led to the ongoing success of GitHub Copilot.
Let’s jump in.
Everything you need to know about prompt engineering in 1600 tokens or less
You know when you’re tapping out a text message on your phone, and in the middle of the screen just above the keypad, there’s a button you can click to accept a suggested next word? That’s pretty much what an LLM is doing—but at scale.
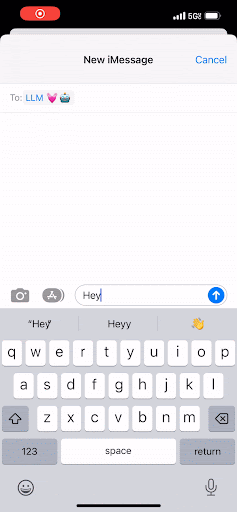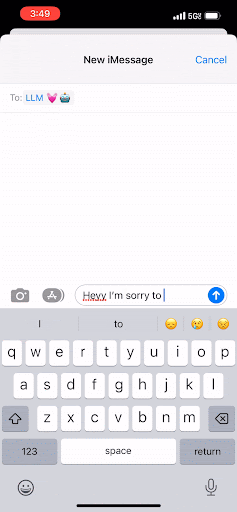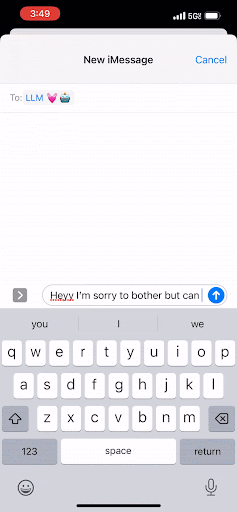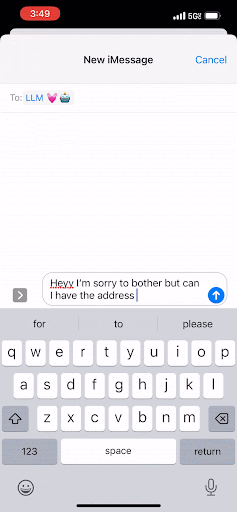
Instead of text on your phone, an LLM works to predict the next best group of letters, which are called “tokens.” And in the same way that you can keep tapping that middle button to complete your text message, the LLM completes a document by predicting the next word. It will continue to do that over and over, and it will only stop once it has reached a maximum threshold of tokens or once it has encountered a special token that signals “Stop! This is the end of the document.”
There’s an important difference, though. The language model in your phone is pretty simple—it’s basically saying, “Based only upon the last two words entered, what is the most likely next word?” In contrast, an LLM produces an output that’s more akin to being “based upon the full content of every document ever known to exist in the public domain, what is the most likely next token in your document?” By training such a large, well-architected model on an enormous dataset, an LLM can almost appear to have common sense such as understanding that a glass ball sitting on a table might roll off and shatter.

But be warned: LLMs will also sometimes confidently produce information that isn’t real or true, which are typically called “hallucinations” or “fabulations.” LLMs can also appear to learn how to do things they weren’t initially trained to do. Historically, natural language models have been created for one-off tasks, like classifying the sentiment of a tweet, extracting the business entities from an email, or identifying similar documents, but now you can ask AI tools like ChatGPT to perform a task that it was never trained to do.
Building applications using LLMs
A document completion engine is a far cry from the amazing proliferation of LLM applications that are springing up every day, running the gamut from conversational search, writing assistants, automated IT support, and code completion tools, like GitHub Copilot. But how is it possible that all of these tools can come from what is effectively a document completion tool? The secret is any application that uses an LLM is actually mapping between two domains: the user domain and the document domain.
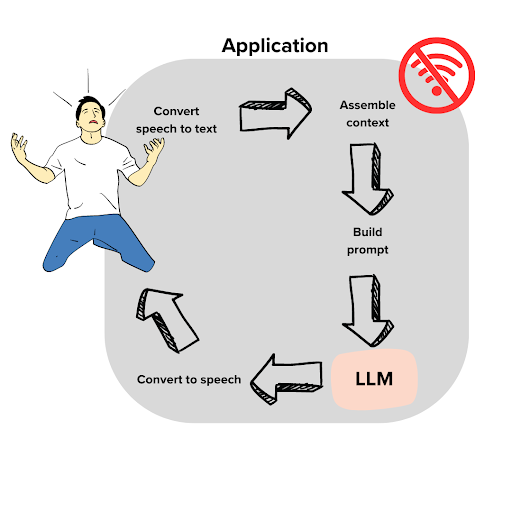
On the left is the user. His name is Dave, and he has a problem. It’s the day of his big World Cup watch party, and the Wi-Fi is out. If they don’t get it fixed soon, he’ll be the butt of his friends’ jokes for years. Dave calls his internet provider and gets an automated assistant. Ugh! But imagine that we are implementing the automated assistant as an LLM application. Can we help him?
The key here is to figure out how to convert from user domain into document domain. For one thing, we will need to transcribe the user’s speech into text. As soon as the automated support agent says “Please state the nature of your cable-related emergency,” Dave blurts out:
Oh it’s awful! It’s the World Cup finals. My TV was connected to my Wi-Fi, but I bumped the counter and the Wi-Fi box fell off and broke! Now, we can’t watch the game.
At this point, we have text, but it’s not of much use. Maybe you would imagine that this was part of a story and continue it, “I guess, I’ll call up my brother and see if we can watch the game with him.” An LLM with no context will similarly create the continuation of Dave’s story. So, let’s give the LLM some context and establish what type of document this is:
### ISP IT Support Transcript:
The following is a recorded conversation between an ISP customer, Dave Anderson, and Julia Jones, IT support expert. This transcript serves as an example of the excellent support provided by Comcrash to its customers.
*Dave: Oh it's awful! This is the big game day. My TV was connected to my Wi-Fi, but I bumped the counter and the Wi-Fi box fell off and broke! Now we can't watch the game.
*Julia:
Now, if you found this pseudo document on the ground, how would you complete it? Based on the extra context, you would see that Julia is an IT support expert, and apparently a really good one. You would expect the next words to be sage advice to help Dave with his problem. It doesn’t matter that Julia doesn’t exist, and this wasn’t a recorded conversation—what matters is that these extra words offer more context for what a completion might look like. An LLM does the same exact thing. After reading this partial document, it will do its best to complete Julia’s dialogue in a helpful manner.
But there’s more we can do to make the best document for the LLM. The LLM doesn’t know a whole lot about cable TV troubleshooting. (Well, it has read every manual and IT document ever published online, but stay with me here). Let’s assume that its knowledge is lacking in this particular domain. One thing we can do is search for extra content that might help Dave and place it into the document. Let’s assume that we have a complaints search engine that allows us to find documentation that has been helpful in similar situations in the past. Now, all we have to do is weave this information into our pseudo document in a natural place.
Continuing from above:
*Julia:(rifles around in her briefcase and pulls out the perfect documentation for Dave's request)
Common internet connectivity problems ...
<...here we insert 1 page of text that comes from search results against our customer support history database...>
(After reading the document, Julia makes the following recommendation)
*Julia:
Now, given this full body of text, the LLM is conditioned to make use of the implanted documentation, and in the context of “a helpful IT expert,” the model will generate a response. This reply takes into account the documentation as well as Dave’s specific request.
The last step is to move from the document domain into the user’s problem domain. For this example, that means just converting text to voice. And since this is effectively a chat application, we would go back and forth several times between the user and the document domain, making the transcript longer each time.
This, at the core of the example, is prompt engineering. In the example, we crafted a prompt with enough context for the AI to produce the best possible output, which in this case was providing Dave with helpful information to get his Wi-Fi up and running again. In the next section, we’ll take a look at how we at GitHub have refined our prompt engineering techniques for GitHub Copilot.
The art and science of prompt engineering
Converting between the user domain and document domain is the realm of prompt engineering—and since we’ve been working on GitHub Copilot for over two years, we’ve started to identify some patterns in the process.
These patterns have helped us formalize a pipeline, and we think it is an applicable template to help others better approach prompt engineering for their own applications. Now, we’ll demonstrate how this pipeline works by examining it in the context of GitHub Copilot, our AI pair programmer.
The prompt engineering pipeline for GitHub Copilot
From the very beginning, GitHub Copilot’s LLMs have been built on AI models from OpenAI that have continued to get better and better. But what hasn’t changed is the answer to the central question of prompt engineering: what kind of document is the model trying to complete?
The OpenAI models we use have been trained to complete code files on GitHub. Ignoring some filtering and stratification steps that don’t really change the prompt engineering game, this distribution is pretty much that of individual file contents according to the most recent commit to main at data collection time.
The document completion problem the LLM solves is about code, and GitHub Copilot’s task is all about completing code. But the two are very different.
Here are some examples:
- Most files committed to main are finished. For one, they usually compile. Most of the time the user is typing, the code does not compile because of incompletions that will be fixed before a commit is pushed.
- The user might even write their code in hierarchical order, method signatures first, then bodies rather than line by line or in a mixed style.
- Writing code means jumping around. In particular, people’s edits often require them to jump up in the document and make a change there, for example, adding a parameter to a function. Strictly speaking, if Codex suggests using a function that has not been imported yet, no matter how much sense it might make, that’s a mistake. But as a GitHub Copilot suggestion, it would be useful.
The issue is that merely predicting the most likely continuation based on the text in front of the cursor to make a GitHub Copilot suggestion would be a wasted opportunity. That’s because it ignores an incredible wealth of context. We can use that context to guide the suggestion, like metadata, the code below the cursor, the content of imports, the rest of the repository, or issues, and create a strong prompt for the AI assistant.
Software development is a deeply interconnected, multimodal challenge, and the more of that complexity we can tame and present to the model, the better your completions are going to be.
Step 1: Gathering context
GitHub Copilot lives in the context of an IDE such as Visual Studio Code (VS Code), and it can use whatever it can get the IDE to tell it—only if the IDE is quick about it though. In an interactive environment like GitHub Copilot, every millisecond matters. GitHub Copilot promises to take care of the common coding tasks, and if it wants to do that, it needs to display its solution to the developer before they have started to write more code in their IDE. Our rough heuristics say that for every additional 10 milliseconds we take to come up with a suggestion, the chance it’ll arrive in time decreases by one percent.
So, what can we say quickly? Well, here’s an example. Consider this suggestion to a simple piece of Python:

Wrong! Turns out the user actually wanted to write Ruby, like this:

The two languages have similar enough syntax so that only a couple of lines can be ambiguous, especially when it’s toward the beginning of the file where much of what we encounter are boilerplate comments. But modern IDEs such as VS Code typically know what language the user is writing in. That makes language mix ups especially annoying to the user because they break the implicit expectation that “the computer should know” (after all, most IDEs highlight language syntax).
So, let’s put the language metadata into our pile of context we might want to include. In fact, let’s add the whole filename too. If it’s available, it usually implies the language through its extension, and additionally sets the tone for what to expect in that file—small, easy pieces of information that won’t turn the tide but are helpful to include.
On the other end of the spectrum, there’s the rest of the repository. Say you’ve got a file that defines an abstract class DataReader. And you have another that defines a subclass CsvReader. And you’re now writing a new file defining another subclass SqlReader. Chances are that to write the new file, you’ll want to check out both existing files as well because they communicate useful background into what you need to implement and how to do it. Typically, developers keep such files open in different tabs and switch to remind themselves of definitions, examples, similar patterns, or tests.
If the content of those two files is useful to you, chances are it would be useful to the AI as well. So, let’s add it as context! After all, the IDE knows what other files from the repository are open as tabs in the same window. The repository might have hundreds or even thousands of files, but only some will be open, and that is a strong hint that they might be useful to what they’re doing right now. Of course, “some” can mean a lot of things, so we don’t consider any more than the 20 most recent tabs.
Step 2: Snippeting
Irrelevant information in an LLM’s context decreases its accuracy. Additionally, source code tends to be long, so even a single file is not guaranteed to fit completely into an LLM’s context window (a problem that occurs roughly a fifth of the time). So, unless the user is very frugal about their tab usage, we simply cannot include all the tabs.
It’s important to be selective about what code to include from other files, so we cut files into (hopefully) natural, overlapping snippets that are no longer than 60 lines. Of course, we don’t want to actually include all overlapping snippets—that’s why we score them and take only the best. In this case, the “score” is meant to reflect relevance. To determine a snippet’s score, we use the Jaccard similarity, a stat that can be used to gauge the similarity or diversity of sample sets. (It’s also super fast to compute, which is great for reducing latency.)
Step 3: Dressing them up
Now we have some context we’d like to pass on to the model. But how? Codex and other models don’t offer an API where you can add other files, or where you can specify the document’s language and filename for that matter. They complete one single document. As mentioned above, you’ll need to inject your context into that document in a natural way.
The path and name might be easiest. Many files start with a preamble that gives some metadata, like author, project name, or filename. So, we’ll pretend this is happening here as well, and add a line at the very top that reads something like # filepath: foo/bar.py or // filepath: foo.bar.js, depending on comment syntax in the file’s language.
Sometimes the path isn’t known, like with new files that haven’t yet been saved. Even then, we could try to at least specify the language, provided the IDE is aware of it. For many languages, we have the opportunity to include shebang lines like #!/usr/bin/python or #!/usr/bin/node. That’s a neat trick that works pretty well at warding against mistaken language identity. But it’s also a bit dangerous since files with shebang lines are a biased subpopulation of all code. So, let’s do it for short files where the danger of mistaken language identity is high, and avoid it for larger or named files.
If comments work as a delivery system for tiny nuggets of information, like path or language, we can also make them work as delivery systems for the chunky deep dives that are 60 lines of related code.
Comments are versatile, and commented-out code exists all over GitHub. Let’s look at some of the most common examples:
- Old code that doesn’t apply anymore
- Deleted features
- Earlier versions of current code
- Example code specifically left there for documentation purposes
- Code lifted from other parts of the codebase
Let’s take our inspiration from the last group of examples. Familiarity with groups (1) – (3) makes things a bit easier on the model, but our snippets aim to emulate groups (4) and (5):
# compare this snippet from utils/concatenate.py:
# def crazy_concat(a, b):
# return str(a) + str(b)[::-1]
Note that including the file name and path of the snippet source can be useful. And combined with the current file’s path, this might guide completions referencing imports.
Step 4: Prioritization
So far, we have grabbed many pieces of context from many sources: the text directly above the cursor, text below the cursor, text in other files, and metadata like language and file path.
In the vast majority of cases (around 95%), we have to make the tough choice of what we can or cannot include.
We make that choice by thinking of the items we might include as “wishes.” Each time we uncover a piece of context, like a commented out snippet from an open tab, we make a wish. Wishes come with some priority attached, for example, the shebang lines have rather low priorities. Snippets with a low similarity score are barely higher. In contrast, the lines directly above the cursor have maximum priority. Wishes also come with a desired position in the document. The shebang line needs to be the very first item, while the text directly above the cursor comes last—it should directly precede the LLM’s completion.
The fastest way of selecting which wishes to fill and which ones to discard is by sorting that wishlist by priority. Then, we can keep deleting the lowest priority wishes until what remains fits in the context window. We then sort again by the intended order in the document and paste everything together.
Step 5: The AI does its thing
Now that we’ve assembled an informative prompt, it’s time for the AI to come up with a useful completion. We have always faced a very delicate tradeoff here—GitHub Copilot needs to use a highly capable model because quality makes all the difference between a useful suggestion and a distraction. But at the same time, it needs to be a model capable of speed, because latency makes all the difference between a useful suggestion and not being able to provide a suggestion at all.
So, which AI should we choose to “do its thing” on the completion task: the fastest or the most accurate one? It’s hard to know in advance, so OpenAI developed a fleet of models in collaboration with GitHub. We put two different models in front of developers but found that people got the most mileage (in terms of accepted and retained completions) out of the much faster model. Since then, further optimizations have increased model speed significantly, so that the current version of GitHub Copilot is backed by an even more capable model.
Step 6: Now, over to you!
The generative AI produces a string, and if it’s not stopped, it keeps on producing and will keep going until it predicts the end of the file. That would waste time and compute resources, so you need to set up “stop” criteria.
The most common stop criterion is actually looking for the first line break. In many situations, it seems likely that a software developer wants the current line to be finished, but not more. But some of the most magical contributions by GitHub Copilot are when it suggests multiple lines of code all at once.
Multi-line completions feel natural when they’re about a single semantic unit, such as the body of a function, an if-branch, or a class. GitHub Copilot looks for cases where such a block is being started, either because the developer has just written the start, such as the header, if guard, or class declaration, or is currently writing the start. If the block body appears to be empty, it will attempt to make a suggestion for it, and only stop when the block appears to be done.
This is the point when the suggestion gets surfaced to the coder. And the rest, as they say, is history 10x development.
If you’re interested in learning more about prompt engineering in general and how you can refine your own techniques, check out our guide on getting started with GitHub Copilot.

Tags:


Related posts
The harness is all you need (mostly)
A practical GitHub Copilot workflow for prototyping, planning, implementing, and reviewing software without chasing every new AI tool.

GitHub Copilot app for Beginners: Getting started
New to the GitHub Copilot app? Learn how to start projects, work with AI agents, explore canvases, and streamline your development workflow.
Copilot vs. raw API access: What are you actually paying for?
Copilot now bills usage at listed API rates. Compare direct model access with the coding workflow, policy, and harness work around it.