Looking to bring the power of GitHub Copilot Enterprise to your organization? Learn more about GitHub Copilot Enterprise or get started now.
Home / AI & ML / Generative AI
What is retrieval-augmented generation, and what does it do for generative AI?
Here’s how retrieval-augmented generation, or RAG, uses a variety of data sources to keep AI models fresh with up-to-date information and organizational knowledge.

|
9 minutes
One of the hottest topics in AI right now is RAG, or retrieval-augmented generation, which is a retrieval method used by some AI tools to improve the quality and relevance of their outputs.
Organizations want AI tools that use RAG because it makes those tools aware of proprietary data without the effort and expense of custom model training. RAG also keeps models up to date. When generating an answer without RAG, models can only draw upon data that existed when they were trained. With RAG, on the other hand, models can leverage a private database of newer information for more informed responses.
We talked to GitHub Next’s Senior Director of Research, Idan Gazit, and Software Engineer, Colin Merkel, to learn more about RAG and how it’s used in generative AI tools.
Why everyone’s talking about RAG
One of the reasons you should always verify outputs from a generative AI tool is because its training data has a knowledge cut-off date. While models are able to produce outputs that are tailored to a request, they can only reference information that existed at the time of their training. But with RAG, an AI tool can use data sources beyond its model’s training data to generate an output.
The difference between RAG and fine-tuning
Most organizations currently don’t train their own AI models. Instead, they customize pre-trained models to their specific needs, often using RAG or fine-tuning. Here’s a quick breakdown of how these two strategies differ.
Fine-tuning requires adjusting a model’s weights, which results in a highly customized model that excels at a specific task. It’s a good option for organizations that rely on codebases written in a specialized language, especially if the language isn’t well-represented in the model’s original training data.
RAG, on the other hand, doesn’t require weight adjustment. Instead, it retrieves and gathers information from a variety of data sources to augment a prompt, which results in an AI model generating a more contextually relevant response for the end user.
Some organizations start with RAG and then fine-tune their models to accomplish a more specific task. Other organizations find that RAG is a sufficient method for AI customization alone.
How AI models use context
In order for an AI tool to generate helpful responses, it needs the right context. This is the same dilemma we face as humans when making a decision or solving a problem. It’s hard to do when you don’t have the right information to act on.
So, let’s talk more about context in the context (😉) of generative AI:
- Today’s generative AI applications are powered by large language models (LLMs) that are structured as transformers, and all transformer LLMs have a context window— the amount of data that they can accept in a single prompt. Though context windows are limited in size, they can and will continue to grow larger as more powerful models are released.
-
Input data will vary depending on the AI tool’s capabilities. For instance, when it comes to GitHub Copilot in the IDE, input data comprises all of the code in the file that you’re currently working on. This is made possible because of our Fill-in-the-Middle (FIM) paradigm, which makes GitHub Copilot aware of both the code before your cursor (the prefix) and after your cursor (the suffix).
GitHub Copilot also processes code from your other open tabs (a process we call neighboring tabs) to potentially find and add relevant information to the prompt. When there are a lot of open tabs, GitHub Copilot will scan the most recently reviewed ones.
-
Because of the context window’s limited size, the challenge of ML engineers is to figure out what input data to add to the prompt and in what order to generate the most relevant suggestion from the AI model. This task is known as prompt engineering.
How RAG enhances an AI model’s contextual understanding
With RAG, an LLM can go beyond training data and retrieve information from a variety of data sources, including customized ones.
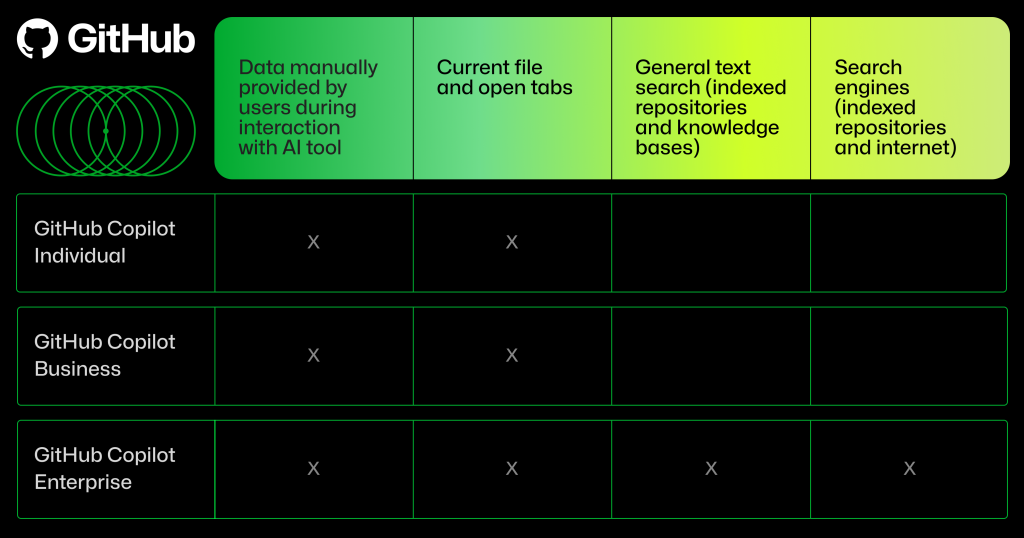
When it comes to GitHub Copilot Chat within GitHub.com and in the IDE, input data can include your conversation with the chat assistant, whether it’s code or natural language, through a process called in-context learning. It can also include data from indexed repositories (public or private), a collection of Markdown documentation across repositories (that we refer to as knowledge bases), and results from integrated search engines. From these other sources, RAG will retrieve additional data to augment the initial prompt. As a result, it can generate a more relevant response.
The type of input data used by GitHub Copilot will depend on which GitHub Copilot plan you’re using.
RAG and semantic search
Unlike keyword search or Boolean search operators, an ML-powered semantic search system uses its training data to understand the relationship between your keywords. So, rather than view, for example, “cats” and “kittens” as independent terms as you would in a keyword search, a semantic search system can understand, from its training, that those words are often associated with cute videos of the animal. Because of this, a search for just “cats and kittens” might rank a cute animal video as a top search result.
How does semantic search improve the quality of RAG retrievals? When using a customized database or search engine as a RAG data source, semantic search can improve the context added to the prompt and overall relevance of the AI-generated output.
The semantic search process is at the heart of retrieval. “It surfaces great examples that often elicit great results,” Gazit says.
Developers can use Copilot Chat on GitHub.com to ask questions and receive answers about a codebase in natural language, or surface relevant documentation and existing solutions.
RAG data sources: Where RAG uses semantic search
You’ve probably read dozens of articles (including some of our own) that talk about RAG, vector databases, and embeddings. And even if you haven’t, here’s something you should know: RAG doesn’t require embeddings or vector databases.
A RAG system can use semantic search to retrieve relevant documents, whether from an embedding-based retrieval system, traditional database, or search engine. The snippets from those documents are then formatted into the model’s prompt. We’ll provide a quick recap of vector databases and then, using GitHub Copilot Enterprise as an example, cover how RAG retrieves data from a variety of sources.
Vector databases
Vector databases are optimized for storing embeddings of your repository code and documentation. They allow us to use novel search parameters to find matches between similar vectors.
To retrieve data from a vector database, code and documentation are converted into embeddings, a type of high-dimensional vector, to make them searchable by a RAG system.
Here’s how RAG retrieves data from vector databases: while you code in your IDE, algorithms create embeddings for your code snippets, which are stored in a vector database. Then, an AI coding tool can search that database by embedding similarity to find snippets from across your codebase that are related to the code you’re currently writing and generate a coding suggestion. Those snippets are often highly relevant context, enabling an AI coding assistant to generate a more contextually relevant coding suggestion. GitHub Copilot Chat uses embedding similarity in the IDE and on GitHub.com, so it finds code and documentation snippets related to your query.
Embedding similarity is incredibly powerful because it identifies code that has subtle relationships to the code you’re editing.
“Embedding similarity might surface code that uses the same APIs, or code that performs a similar task to yours but that lives in another part of the codebase,” Gazit explains. “When those examples are added to a prompt, the model’s primed to produce responses that mimic the idioms and techniques that are native to your codebase—even though the model was not trained on your code.”
General text search and search engines
With a general text search, any documents that you want to be accessible to the AI model are indexed ahead of time and stored for later retrieval. For instance, RAG in GitHub Copilot Enterprise can retrieve data from files in an indexed repository and Markdown files across repositories.
RAG can also retrieve information from external and internal search engines. When integrated with an external search engine, RAG can search and retrieve information from the entire internet. When integrated with an internal search engine, it can also access information from within your organization, like an internal website or platform. Integrating both kinds of search engines supercharges RAG’s ability to provide relevant responses.
For instance, GitHub Copilot Enterprise integrates both Bing, an external search engine, and an internal search engine built by GitHub into Copilot Chat on GitHub.com. Bing integration allows GitHub Copilot Chat to conduct a web search and retrieve up-to-date information, like about the latest Java release. But without a search engine searching internally, ”Copilot Chat on GitHub.com cannot answer questions about your private codebase unless you provide a specific code reference yourself,” explains Merkel, who helped to build GitHub’s internal search engine from scratch.
Here’s how this works in practice. When a developer asks a question about a repository to GitHub Copilot Chat in GitHub.com, RAG in Copilot Enterprise uses the internal search engine to find relevant code or text from indexed files to answer that question. To do this, the internal search engine conducts a semantic search by analyzing the content of documents from the indexed repository, and then ranking those documents based on relevance. GitHub Copilot Chat then uses RAG, which also conducts a semantic search, to find and retrieve the most relevant snippets from the top-ranked documents. Those snippets are added to the prompt so GitHub Copilot Chat can generate a relevant response for the developer.
Key takeaways about RAG
RAG offers an effective way to customize AI models, helping to ensure outputs are up to date with organizational knowledge and best practices, and the latest information on the internet.
GitHub Copilot uses a variety of methods to improve the quality of input data and contextualize an initial prompt, and that ability is enhanced with RAG. What’s more, the RAG retrieval method in GitHub Copilot Enterprise goes beyond vector databases and includes data sources like general text search and search engine integrations, which provides even more cost-efficient retrievals.
Context is everything when it comes to getting the most out of an AI tool. To improve the relevance and quality of a generative AI output, you need to improve the relevance and quality of the input.
As Gazit says, “Quality in, quality out.”
Tags:
Written by

Related posts
Copilot vs. raw API access: What are you actually paying for?
Copilot now bills usage at listed API rates. Compare direct model access with the coding workflow, policy, and harness work around it.

How to build interactive experiences with canvases
Canvases turn AI into interactive workspaces where you can visualize information, explore workflows, and take action across complex tasks.
Better tools made Copilot code review worse. Here’s how we actually improved it.
How migrating Copilot code review to shared Unix-style code exploration tools reduced review cost by reshaping agent workflows around pull request evidence.