Highlights from Git 2.41
The open-source Git project just released Git 2.41. Take a look at our highlights on what’s new in Git 2.41.

The open source Git project just released Git 2.41 with features and bug fixes from over 95 contributors, 29 of them new. We last caught up with you on the latest in Git back when 2.40 was released.
To celebrate this most recent release, here’s GitHub’s look at some of the most interesting features and changes introduced since last time.
Improved handling of unreachable objects
At the heart of every Git repository lies a set of objects. For the unfamiliar, you can learn about the intricacies of Git’s object model in this post. In general, objects are the building blocks of your repository. Blobs represent the contents of an individual file, and trees group many blobs (and other trees!) together, representing a directory. Commits tie everything together by pointing at a specific tree, representing the state of your repository at the time when the commit was written.
Git objects can be in one of two states, either “reachable” or “unreachable.” An object is reachable when you can start at some branch or tag in your repository and “walk” along history, eventually ending up at that object. Walking merely means looking at an individual object, and seeing what other objects are immediately related to it. A commit has zero or more other commits which it refers to as parents. Conversely, trees point to many blobs or other trees that make up their contents.
Objects are in the “unreachable” state when there is no branch or tag you could pick as a starting point where a walk like the one above would end up at that object. Every so often, Git decides to remove some of these unreachable objects in order to compress the size of your repository. If you’ve ever seen this message:
Auto packing the repository in background for optimum performance.
See "git help gc" for manual housekeeping.
or run git gc directly, then you have almost certainly removed unreachable objects from your repository.
But Git does not necessarily remove unreachable objects from your repository the first time git gc is run. Since removing objects from a live repository is inherently risky1, Git imposes a delay. An unreachable object won’t be eligible for deletion until it has not been written since a given (via the –prune argument) cutoff point. In other words, if you ran git gc --prune=2.weeks.ago, then:
- All reachable objects will get collected together into a single pack.
- Any unreachable objects which have been written in the last two weeks will be stored separately.
- Any remaining unreachable objects will be discarded.
Until Git 2.37, Git kept track of the last write time of unreachable objects by storing them as loose copies of themselves, and using the object file’s mtime as a proxy for when the object was last written. However, storing unreachable objects as loose until they age out can have a number of negative side-effects. If there are many unreachable objects, they could cause your repository to balloon in size, and/or exhaust the available inodes on your system.
Git 2.37 introduced “cruft packs,” which store unreachable objects together in a packfile, and use an auxiliary *.mtimes file stored alongside the pack to keep track of object ages. By storing unreachable objects together, Git prevents inode exhaustion, and allows unreachable objects to be stored as deltas.
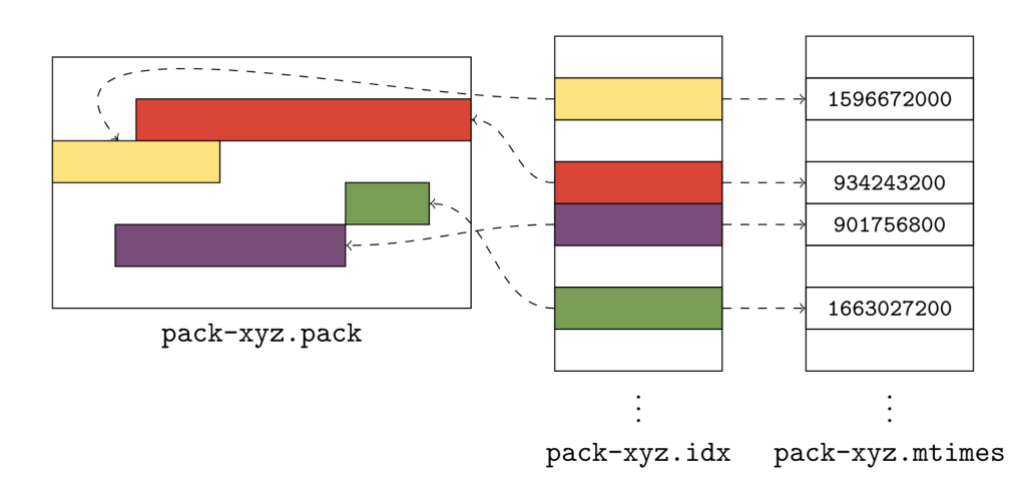
The figure above shows a cruft pack, along with its corresponding *.idx and *.mtimes file. Storing unreachable objects together allows Git to store your unreachable data more efficiently, without worry that it will put strain on your system’s resources.
In Git 2.41, cruft pack generation is now on by default, meaning that a normal git gc will generate a cruft pack in your repository. To learn more about cruft packs, you can check out our previous post, “Scaling Git’s garbage collection.”
[source]
On-disk reverse indexes by default
Starting in Git 2.41, you may notice a new kind of file in your repository’s .git/objects/pack directory: the *.rev file.
This new file stores information similar to what’s in a packfile index. If you’ve seen a file in the pack directory above ending in *.idx, that is where the pack index is stored.
Pack indexes map between the positions of all objects in the corresponding pack among two orders. The first is name order, or the index at which you’d find a given object if you sorted those objects according to their object ID (OID). The other is pack order, or the index of a given object when sorting by its position within the packfile itself.
Git needs to translate between these two orders frequently. For example, say you want Git to print out the contents of a particular object, maybe with git cat-file -p. To do this, Git will look at all *.idx files it knows about, and use a binary search to find the position of the given object in each packfile’s name order. When it finds a match, it uses the *.idx to quickly locate the object within the packfile itself, at which point it can dump its contents.
But what about going the other way? How does Git take a position within a packfile and ask, “What object is this”? For this, it uses the reverse index, which maps objects from their pack order into the name order. True to its name, this data structure is the inverse of the packfile index mentioned above.
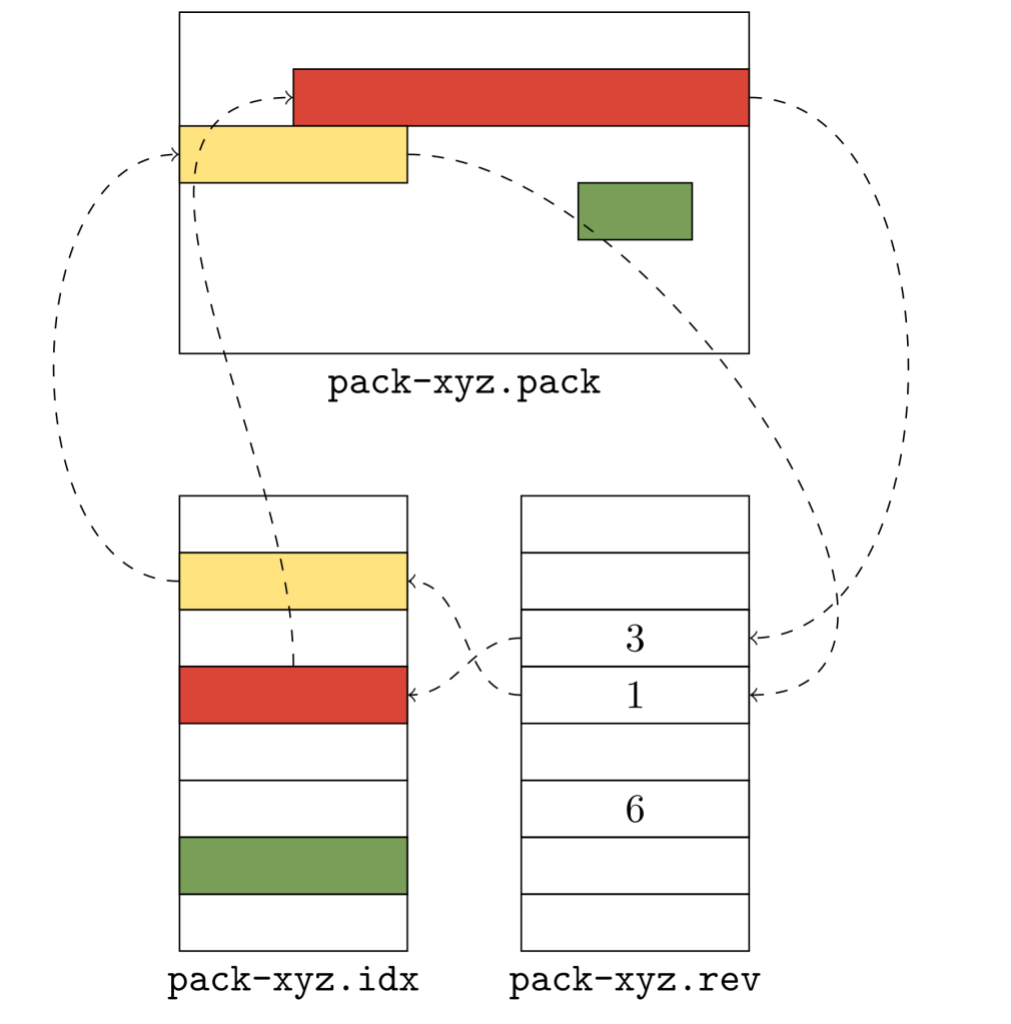
The figure above shows a representation of the reverse index. To discover the lexical (index) position of, say, the yellow object, Git reads the corresponding entry in the reverse index, whose value is the lexical position. In this example, the yellow object is assumed to be the fourth object in the pack, so Git reads the fourth entry in the .rev file, whose value is 1. Reading the corresponding value in the *.idx file gives us back the yellow object.
In previous versions of Git, this reverse index was built on-the-fly by storing a list of pairs (one for each object, each pair contains that object’s position in name and packfile order). This approach has a couple of drawbacks, most notably that it takes time and memory in order to materialize and store this structure.
In Git 2.31, the on-disk reverse index was introduced. It stores the same contents as above, but generates it once and stores the result on disk alongside its corresponding packfile as a *.rev file. Pre-computing and storing reverse indexes can dramatically speed-up performance in large repositories, particularly for operations like pushing, or determining the on-disk size of an object.
In Git 2.41, Git will now generate these reverse indexes by default. This means that the next time you run git gc on your repository after upgrading, you should notice things get a little faster. When testing the new default behavior, the CPU-intensive portion of a git push operation saw a 1.49x speed-up when pushing the last 30 commits in torvalds/linux. Trivial operations, like computing the size of a single object with git cat-file --batch='%(objectsize:disk)' saw an even greater speed-up of nearly 77x.
To learn more about on-disk reverse indexes, you can check out another previous post, “Scaling monorepo maintenance,” which has a section on reverse indexes.
[source]
- You may be familiar with Git’s credential helper mechanism, which is used to provide the required credentials when accessing repositories stored behind a credential. Credential helpers implement support for translating between Git’s credential helper protocol and a specific credential store, like Keychain.app, or libsecret. This allows users to store credentials using their preferred mechanism, by allowing Git to communicate transparently with different credential helper implementations over a common protocol.Traditionally, Git supports password-based authentication. For services that wish to authenticate with OAuth, credential helpers typically employ workarounds like passing the bearer token through basic authorization instead of authenticating directly using bearer authorization.
Credential helpers haven’t had a mechanism to understand additional information necessary to generate a credential, like OAuth scopes, which are typically passed over the
WWW-Authenticateheader.In Git 2.41, the credential helper protocol is extended to support passing
WWW-Authenticateheaders between credential helpers and the services that they are trying to authenticate with. This can be used to allow services to support more fine-grained access to Git repositories by letting users scope their requests.[source]
- If you’ve looked at a repository’s branches page on GitHub, you may have noticed the indicators showing how many commits ahead and behind a branch is relative to the repository’s default branch. If you haven’t noticed, no problem: here’s a quick primer. A branch is “ahead” of another when it has commits that the other side doesn’t. The amount ahead it is depends on the number of unique such commits. Likewise, a branch is “behind” another when it is missing commits that are unique to the other side.
Previous versions of Git allowed this comparison by running two reachability queries:git rev-list --count main..my-feature(to count the number of commits unique to my-feature) andgit rev-list --count my-feature..main(the opposite). This works fine, but involves two separate queries, which can be awkward. If comparing many branches against a common base (like on the/branchespage above), Git may end up walking over the same commits many times.
In Git 2.41, you can now ask for this information directly via a newfor-each-refformatting atom,%(ahead-behind:<base>). Git will compute its output using only a single walk, making it far more efficient than in previous versions.
For example, suppose I wanted to list my unmerged topic branches along with how far ahead and behind they are relative to upstream’s mainline. Before, I would have had to write something like:$ git for-each-ref --format='%(refname:short)' --no-merged=origin/HEAD \ refs/heads/tb | while read ref do ahead="$(git rev-list --count origin/HEAD..$ref)" behind="$(git rev-list --count $ref..origin/HEAD)" printf "%s %d %d\n" "$ref" "$ahead" "$behind" done | column -t tb/cruft-extra-tips 2 96 tb/for-each-ref--exclude 16 96 tb/roaring-bitmaps 47 3which takes more than 500 milliseconds to produce its results. Above, I first ask
git for-each-refto list all of my unmerged branches. Then, I loop over the results, computing their ahead and behind values manually, and finally format the output.In Git 2.41, the same can be accomplished using a much simpler invocation:
$ git for-each-ref --no-merged=origin/HEAD \ --format='%(refname:short) %(ahead-behind:origin/HEAD)' \ refs/heads/tb/ | column -t tb/cruft-extra-tips 2 96 tb/for-each-ref--exclude 16 96 tb/roaring-bitmaps 47 3 [...]That produces the same output (with far less scripting!), and performs a single walk instead of many. By contrast to earlier versions, the above takes only 28 milliseconds to produce output, a more than 17-fold improvement.
[source]
- When fetching from a remote with
git fetch, Git’s output will contain information about which references were updated from the remote, like:+ 4aaf690730..8cebd90810 my-feature -> origin/my-feature (forced update)While convenient for a human to read, it can be much more difficult for a machine to parse. Git will shorten the reference names included in the update, doesn’t print the full before and after values of the reference being updated, and columnates its output, all of which make it more difficult to script around.
In Git 2.41,
git fetchcan now take a new--porcelainoption, which changes its output to a form that is much easier to script around. In general, the--porcelainoutput looks like:<flag> <old-object-id> <new-object-id> <local-reference>When invoked with
--porcelain,git fetchdoes away with the conveniences of its default human readable output, and instead emits data that is much easier to parse. There are four fields, each separated by a single space character. This should make it much easier to script around the output ofgit fetch. - Speaking of
git fetch, Git 2.41 has another new feature that can improve its performance:fetch.hideRefs. Before we get into it, it’s helpful to recall our previous coverage ofgit rev-list’s--exclude-hiddenoption. If you’re new around here, don’t worry: this option was originally introduced to improve the performance of Git’s connectivity check, the process that checks that an incoming push is fully connected, and doesn’t reference any objects that the remote doesn’t already have, or are included in the push itself.
Git 2.39 sped-up the connectivity check by ignoring parts of the repository that weren’t advertised to the pusher: its hidden references. Since these references weren’t advertised to the pusher, it’s unlikely that any of these objects will terminate the connectivity check, so keeping track of them is usually just extra bookkeeping.
Git 2.41 introduces a similar option forgit fetchon the client side. By settingfetch.hideRefsappropriately, you can exclude parts of the references in your local repository from the connectivity check that your client performs to make sure the server didn’t send you an incomplete set of objects.When checking the connectedness of a fetch, the search terminates at the branches and tags from any remote, not just the one you’re fetching from. If you have a large number of remotes, this can take a significant amount of time, especially on resource-constrained systems.
In Git 2.41, you can narrow the endpoints of the connectivity check to focus just on the remote you’re fetching from. (Note that
transfer.hideRefsvalues that start with ! are interpreted as un-hiding those references, and are applied in reverse order.) If you’re fetching from a remote called$remote, you can do this like so:$ git -c fetch.hideRefs=refs -c fetch.hideRefs=!refs/remotes/$remote \ fetch $remoteThe above first hides every reference from the connectivity check (
fetch.hideRefs=refs) and then un-hides just the ones pertaining to that specific remote (fetch.hideRefs=!refs/remotes/$remote). On a resource constrained machine with repositories that have many remote tracking references, this takes the time to complete a no-op fetch from 20 minutes to roughly 30 seconds.[source]
- If you’ve ever been on the hunt for corruption in your repository, you are undoubtedly aware of
git fsck. This tool is used to check that the objects in your repository are intact and connected. In other words, that your repository doesn’t have any corrupt or missing objects.git fsckcan also check for more subtle forms of repository corruption, like malicious looking.gitattributesor.gitmodulesfiles, along with malformed objects (like trees that are out of order, or commits with a missing author). The full suite of checks it performs can be found under thefsck. configuration.
In Git 2.41,git fscklearned how to check for corruption in reachability bitmaps and on-disk reverse indexes. These checks detect and warn about incorrect trailing checksums, which indicate that the preceding data has been mangled. When examining on-disk reverse indexes,git fsckwill also check that the*.revfile holds the correct values.
To learn more about the new kinds offsckchecks implemented, see the git fsck documentation.
[source, source]
The whole shebang
That’s just a sample of changes from the latest release. For more, check out the release notes for 2.41, or any previous version in the Git repository.
Notes
-
The risk is based on a number of factors, most notably that a concurrent writer will write an object that is either based on or refers to an unreachable object. This can happen when receiving push whose content depends on an object that
git gcis about to remove. If a new object is written which references the deleted one, the repository can become corrupt. If you’re curious to learn more, this section is a good place to start. ↩
Tags:
Written by

Related posts
6 security settings every GitHub maintainer should enable this week
These six free settings will not make your project unhackable. Nothing will. What they will do is close the easy doors. Turn these on, and your project will be meaningfully harder to attack than it was before.
How GitHub maintains compliance for open source dependencies
Explore how the Open Source Program Office uses GitHub’s new license compliance product to manage open source dependencies at scale.

Highlights from Git 2.55
The open source Git project just released Git 2.55. Here is GitHub’s look at some of the most interesting features and changes introduced since last time.