Pwning Pixel 6 with a leftover patch
In this post, I’ll look at a security-related change in version r40p0 of the Arm Mali driver that was AWOL in the January update of the Pixel bulletin, where other patches from r40p0 was applied, and how these two lines of changes can be exploited to gain arbitrary kernel code execution and root from a malicious app. This highlights how treacherous it can be when backporting security changes.

The Christmas leftover patch
In the year 2023 A.D., after a long struggle, N-day vulnerabilities, such as CVE-2022-33917, CVE-2022-36449, and CVE-2022-38181 had been fixed in the Pixel 6. Vendor drivers like the Arm Mali had laid their patches at Android’s feet. Peace reigns, disturbed only by occasional toddlers bankrupting their parents with food ordering apps. All patches from upstream are applied.1
All? No, one patch still stubbornly holds out.
@@ -2262,10 +2258,13 @@ int kbase_mem_commit(struct kbase_context *kctx, u64 gpu_addr, u64 new_pages)
if (atomic_read(®->cpu_alloc->kernel_mappings) > 0)
goto out_unlock;
if (reg->flags & KBASE_REG_DONT_NEED)
goto out_unlock;
+ if (reg->flags & KBASE_REG_NO_USER_FREE)
+ goto out_unlock;
In this post, I’m going to take a very close look at what these two lines, or rather, the lack of them, are capable of.
GHSL-2023-005
GHSL-2023-005 can be used to gain arbitrary kernel code execution and root privileges from a malicious app on the Pixel 6. What makes this bug interesting from a patching point of view is that it was already fixed publicly in the Arm Mali GPU driver on October 7, 2022 in the r40p0 release. While other security patches from the r40 version of the driver had been backported to the Pixel 6 in the January security update, the particular change mentioned in the previous section was missing.
I noticed this change shortly after r40p0 was released and had always assumed that it was a defense in depth measure against potential issues similar to CVE-2022-38181. As it was part of the changes made in the r40 version of the driver, I assumed it’d be applied to Android when other security patches from the r40 driver were applied. To my surprise, when I checked the January patch for Google’s Pixel phones, I realized that while many security patches from r40p0 had been applied, this particular change was missing. As it wasn’t clear to me whether this patch was going to be treated as a security issue and be applied at all, I reported it to the Android security team on January 10, 2023, together with a proof-of-concept exploit that roots the Pixel 6 phone to demonstrate the severity of the issue. I also sent a copy of the report to Arm in case it was an issue of cherry picking patches. Arm replied on January 31, 2023 saying that there might have been a problem with backporting patches to version r36p0. The Android security team rated the issue as a high-severity vulnerability on January 13, 2023. However, on February 14, 2023, the Android security team decided that the issue was a duplicate of an internally reported issue. The issue was eventually fixed silently in the March feature drop update (which was delayed until March 20, 2023 for Pixel 6), where the source code progressed to the Android 13 qpr2 branch. Looking at this branch, the fix uses the kbase_va_region_is_no_user_free function, which was introduced in upstream drivers from versions r41 onwards.
@@ -2270,8 +2237,11 @@
if (atomic_read(®->cpu_alloc->kernel_mappings) > 0)
goto out_unlock;
- /* can't grow regions which are ephemeral */
- if (reg->flags & KBASE_REG_DONT_NEED)
+
+ if (kbase_is_region_shrinkable(reg))
+ goto out_unlock;
+
+ if (kbase_va_region_is_no_user_free(kctx, reg))
goto out_unlock;
So, it seems that this was indeed a backporting issue as Arm suggested, and the problem has only been fixed in the Pixel phones because the Android13 qpr2 branch uses a newer version of the driver. It is perhaps a piece of luck that the feature drop update is happening only two months after I reported the issue; otherwise, it may have taken longer to fix it.
The Arm Mali GPU
The Arm Mali GPU can be integrated in various devices (for example, see “Implementations” in the Mali (GPU) Wikipedia entry) ranging from Android phones to smart TV boxes. It has been an attractive target on Android phones and has been targeted by in-the-wild exploits multiple times.
This current issue is related to CVE-2022-38181, a vulnerability that I reported last year that is another vulnerability in the handling of a type of GPU memory, the JIT memory, in the Arm Mali driver. Readers may find the section “The life cycle of JIT memory” in that post useful, although for completeness, I’ll also briefly explain JIT memory and the root cause of CVE-2022-38181 in this post.
JIT memory in Arm Mali
When using the Mali GPU driver, a user app first needs to create and initialize a kbase_context kernel object. This involves the user app opening the driver file and using the resulting file descriptor to make a series of ioctl calls. A kbase_context object is responsible for managing resources for each driver file that is opened and is unique for each file handle.
In particular, the kbase_context manages different types of memory that are shared between the GPU devices and user space applications. The JIT memory is one such type of memory whose lifetime is managed by the kernel driver. A user application can use the KBASE_IOCTL_JOB_SUBMIT ioctl call to instruct the GPU driver to create or free such memories. By submitting the BASE_JD_REQ_SOFT_JIT_ALLOC job, a user can allocate JIT memory, while the BASE_JD_REQ_SOFT_JIT_FREE job instructs the kernel to free the memory.
When users submit the BASE_JD_REQ_SOFT_JIT_FREE job to the GPU, the JIT memory region does not get freed immediately. Instead, the memory region is first shrunk to a minimal size via the function kbase_jit_free:
void kbase_jit_free(struct kbase_context *kctx, struct kbase_va_region *reg)
{
...
//First reduce the size of the backing region and unmap the freed pages
old_pages = kbase_reg_current_backed_size(reg);
if (reg->initial_commit < old_pages) {
u64 new_size = MAX(reg->initial_commit,
div_u64(old_pages * (100 - kctx->trim_level), 100));
u64 delta = old_pages - new_size;
//Free delta pages in the region and reduces its size to old_pages - delta
if (delta) {
mutex_lock(&kctx->reg_lock);
kbase_mem_shrink(kctx, reg, old_pages - delta);
mutex_unlock(&kctx->reg_lock);
}
}
...
In the above, the kbase_va_region reg is a struct representing the JIT memory region, and kbase_mem_shrink is a function that shrinks the region while freeing some of its backing pages. As explained in my previous post, the kbase_jit_free function also moves the JIT region to the evict_list of the kbase_context.
void kbase_jit_free(struct kbase_context *kctx, struct kbase_va_region *reg)
{
...
mutex_lock(&kctx->jit_evict_lock);
/* This allocation can't already be on a list. */
WARN_ON(!list_empty(®->gpu_alloc->evict_node));
//Add reg to evict_list
list_add(®->gpu_alloc->evict_node, &kctx->evict_list);
atomic_add(reg->gpu_alloc->nents, &kctx->evict_nents);
//Move reg to jit_pool_head
list_move(®->jit_node, &kctx->jit_pool_head);
...
}
Memory regions in the evict_list will eventually be freed when memory pressure arises and the Linux kernel’s shrinker is triggered to reclaim unused memory. kbase_jit_free also performs other clean up actions that remove references to the JIT memory region so that it cannot no longer be reached from user space.
While the BASE_JD_SOFT_JIT_FREE GPU job can be used to put JIT memory in the evict_list so that it can be freed when the shrinker is triggered, the Arm Mali GPU driver also provides other ways to place a memory region in the evict_list. The KBASE_IOCTL_MEM_FLAGS_CHANGE ioctl can be used to call the kbase_mem_flags_change function with the BASE_MEM_DONT_NEED flag to place a memory region in the evict_list:
int kbase_mem_flags_change(struct kbase_context *kctx, u64 gpu_addr, unsigned int flags, unsigned int mask)
{
...
prev_needed = (KBASE_REG_DONT_NEED & reg->flags) == KBASE_REG_DONT_NEED;
new_needed = (BASE_MEM_DONT_NEED & flags) == BASE_MEM_DONT_NEED;
if (prev_needed != new_needed) {
...
if (new_needed) {
...
ret = kbase_mem_evictable_make(reg->gpu_alloc); //<------ Add to `evict_list`
if (ret)
goto out_unlock;
} else {
kbase_mem_evictable_unmake(reg->gpu_alloc); //<------- Remove from `evict_list`
}
}
Prior to version r40p0 of the driver, this ioctl could be used to add a JIT region directly to the evict_list, bypassing the clean up actions done by kbase_jit_free. This then caused a use-after-free vulnerability, CVE-2022-38181, which was fixed in r40p0 by preventing such flag changes from being applied to JIT region:
@@ -951,6 +951,15 @@
if (kbase_is_region_invalid_or_free(reg))
goto out_unlock;
+ /* There is no use case to support MEM_FLAGS_CHANGE ioctl for allocations
+ * that have NO_USER_FREE flag set, to mark them as evictable/reclaimable.
+ * This would usually include JIT allocations, Tiler heap related allocations
+ * & GPU queue ringbuffer and none of them needs to be explicitly marked
+ * as evictable by Userspace.
+ */
+ if (reg->flags & KBASE_REG_NO_USER_FREE)
+ goto out_unlock;
+
/* Is the region being transitioning between not needed and needed? */
prev_needed = (KBASE_REG_DONT_NEED & reg->flags) == KBASE_REG_DONT_NEED;
new_needed = (BASE_MEM_DONT_NEED & flags) == BASE_MEM_DONT_NEED;
In the above, code is added to prevent kbase_va_region with the KBASE_REG_NO_USER_FREE flag from being added to the evict_list via the kbase_mem_flags_change function. The KBASE_REG_NO_USER_FREE flag is added to the JIT region when it is created and is only removed while the region is being released. So, adding this condition very much prevents a JIT memory region from being added to the evict_list outside of kbase_jit_free.
For memory regions, however, memory management is not just about the lifetime of the kbase_va_region itself, but the backing pages of the kbase_va_region may also be released by using the KBASE_IOCTL_MEM_COMMIT ioctl. This ioctl allows the user to change the number of backing pages in a region and may also be used with JIT region to release its backing pages. So, naturally, the same condition should also be applied to the kbase_mem_commit function to avoid JIT regions being manipulated outside of the BASE_JD_SOFT_JIT_FREE job. This was indeed done by Arm to harden the handling of JIT memory:
@@ -2262,10 +2258,13 @@ int kbase_mem_commit(struct kbase_context *kctx, u64 gpu_addr, u64 new_pages)
if (atomic_read(®->cpu_alloc->kernel_mappings) > 0)
goto out_unlock;
if (reg->flags & KBASE_REG_DONT_NEED)
goto out_unlock;
+ if (reg->flags & KBASE_REG_NO_USER_FREE)
+ goto out_unlock;
This is the patch that we’re going to look at.
From defense-in-depth to offense-in-depth
While the changes made in the kbase_mem_commit function have removed the opportunity to manipulate the backing pages of a JIT region via the KBASE_IOCTL_MEM_COMMIT ioctl, the actual effect of the patch is more subtle, because even without the patch, the kbase_mem_commit function already prevents memory regions with the KBASE_REG_ACTIVE_JIT_ALLOC and KBASE_REG_DONT_NEED from being modified:
int kbase_mem_commit(struct kbase_context *kctx, u64 gpu_addr, u64 new_pages)
{
...
if (reg->flags & KBASE_REG_ACTIVE_JIT_ALLOC)
goto out_unlock;
...
/* can't grow regions which are ephemeral */
if (reg->flags & KBASE_REG_DONT_NEED)
goto out_unlock;
The KBASE_REG_ACTIVE_JIT_ALLOC flag indicates that a JIT region is actively being used, and it is added when the JIT region is allocated:
struct kbase_va_region *kbase_jit_allocate(struct kbase_context *kctx,
const struct base_jit_alloc_info *info,
bool ignore_pressure_limit)
{
...
if (info->usage_id != 0)
/* First scan for an allocation with the same usage ID */
reg = find_reasonable_region(info, &kctx->jit_pool_head, false);
if (!reg)
/* No allocation with the same usage ID, or usage IDs not in
* use. Search for an allocation we can reuse.
*/
reg = find_reasonable_region(info, &kctx->jit_pool_head, true);
...
} else {
...
reg = kbase_mem_alloc(kctx, info->va_pages, info->commit_pages, info->extension,
&flags, &gpu_addr, mmu_sync_info);
...
}
...
reg->flags |= KBASE_REG_ACTIVE_JIT_ALLOC;
...
return reg;
}
It is removed when kbase_jit_free is called on the region:
void kbase_jit_free(struct kbase_context *kctx, struct kbase_va_region *reg)
{
...
kbase_gpu_vm_lock(kctx);
reg->flags |= KBASE_REG_DONT_NEED;
reg->flags &= ~KBASE_REG_ACTIVE_JIT_ALLOC;
...
kbase_gpu_vm_unlock(kctx);
...
}
However, at this point, the KBASE_REG_DONT_NEED is added to the JIT region. It seems that during the lifetime of a JIT region, either the KBASE_REG_ACTIVE_JIT_ALLOC or the KBASE_REG_DONT_NEED flag is added to the region and so the use of JIT region in kbase_mem_commit is already covered entirely?
Well, not entirely—one small window still holds out against these flags. And lifetime management is not easy for JIT regions in the fortified camps of Midgard, Bifrost, and Valhal.
As explained in the section “The life cycle of JIT memory” of my previous post, after a JIT region is freed by submitting the BASE_JD_REQ_SOFT_JIT_FREE GPU job, it’s added to the jit_pool_head list. JIT regions that are in the jit_pool_head list are not yet destroyed and can be reused as JIT regions if another BASE_JD_REQ_SOFT_JIT_ALLOC job is submitted. When kbase_jit_allocate is called to allocate JIT region, it’ll first look in the jit_pool_head for an unused region:
struct kbase_va_region *kbase_jit_allocate(struct kbase_context *kctx,
const struct base_jit_alloc_info *info,
bool ignore_pressure_limit)
{
...
if (info->usage_id != 0)
/* First scan for an allocation with the same usage ID */
reg = find_reasonable_region(info, &kctx->jit_pool_head, false);
...
if (reg) {
...
ret = kbase_jit_grow(kctx, info, reg, prealloc_sas,
mmu_sync_info);
...
}
...
}
If a region is found in the jit_pool_head, kbase_jit_grow is called on the region to change its backing store to a suitable size. At this point, the region reg still has the KBASE_REG_DONT_NEED flag attached and is still on the evict_list. However, kbase_jit_grow will first remove reg from the evict_list and remove the KBASE_REG_DONT_NEED flag by calling kbase_mem_evictable_unmake:
static int kbase_jit_grow(struct kbase_context *kctx,
const struct base_jit_alloc_info *info,
struct kbase_va_region *reg,
struct kbase_sub_alloc **prealloc_sas,
enum kbase_caller_mmu_sync_info mmu_sync_info)
{
...
/* Make the physical backing no longer reclaimable */
if (!kbase_mem_evictable_unmake(reg->gpu_alloc)) //<---- removes KBASE_REG_DONT_NEED
goto update_failed;
...
After this point, the region has neither the KBASE_REG_DONT_NEED nor the KBASE_REG_ACTIVE_JIT_ALLOC flag. It is still protected by the kctx->reg_lock, which prevents the kbase_mem_commit function from changing it. If the region needs to grow, it’ll try to take pages from a memory pool managed by the kbase_context kctx, and if the memory pool does not have the capacity, then it’ll try to grow the memory pool, during which the kctx->reg_lock is dropped:
static int kbase_jit_grow(struct kbase_context *kctx,
const struct base_jit_alloc_info *info,
struct kbase_va_region *reg,
struct kbase_sub_alloc **prealloc_sas,
enum kbase_caller_mmu_sync_info mmu_sync_info)
{
...
while (kbase_mem_pool_size(pool) < pages_required) {
int pool_delta = pages_required - kbase_mem_pool_size(pool);
int ret;
kbase_mem_pool_unlock(pool);
spin_unlock(&kctx->mem_partials_lock);
kbase_gpu_vm_unlock(kctx);
ret = kbase_mem_pool_grow(pool, pool_delta); //<------- race window
kbase_gpu_vm_lock(kctx);
...
}
}
Between the kbase_gpu_vm_unlock and kbase_gpu_vm_lock (marked as race window in the above), it is possible for kbase_mem_commit to modify the backing pages of reg. As kbase_mem_pool_grow involves rather large memory allocations from the kernel page allocator, this race window can be hit fairly easily.
The next question is, what can I do with this race?
To answer this, we need to take a look at how backing pages are stored in a kbase_va_region and what is involved in changing the size of the backing stores. The structure responsible for managing backing stores in a kbase_va_region is the kbase_mem_phy_alloc, stored as the gpu_alloc and cpu_alloc fields. In our settings, these two are the same. Within the kbase_mem_phy_alloc, the fields nents and pages are responsible for keeping track of the backing pages:
struct kbase_mem_phy_alloc {
...
size_t nents;
struct tagged_addr *pages;
...
}
The field nents is the number of backing pages for the region, while pages is an array containing addresses of the actual backing pages. When the size of the backing store changes, entries are either added to or removed from pages. When an entry is removed from pages, a NULL address is written to the entry. The size nents is also changed to reflect the new size of the backing store.
In general, growing the backing store involves the following:
- Allocate memory pages and then add them to the
pagesarray of thegpu_alloc, and then changegpu_alloc->nentsto reflect the new size. - Insert the addresses of the new pages into the GPU page table to create GPU mappings so the pages can be accessed via the GPU. Shrinking the backing store is similar, but pages and mappings are removed instead of added.
We can now go back to take a look at the kbase_jit_grow function. Prior to growing the memory pool, it stores the number of pages that reg needs to grow by as delta, and the original size of reg as old_size.
static int kbase_jit_grow(struct kbase_context *kctx,
const struct base_jit_alloc_info *info,
struct kbase_va_region *reg,
struct kbase_sub_alloc **prealloc_sas)
{
...
/* Grow the backing */
old_size = reg->gpu_alloc->nents;
/* Allocate some more pages */
delta = info->commit_pages - reg->gpu_alloc->nents;
...
//grow memory pool
...
Recall that, while growing the memory pool, it is possible for another thread to modify the backing store of reg, which will change reg->gpu_alloc->nents and invalidates both old_size and delta. After growing the memory pool, both old_size and delta are used for allocating backing pages and creating GPU mappings:
static int kbase_jit_grow(struct kbase_context *kctx,
const struct base_jit_alloc_info *info,
struct kbase_va_region *reg,
struct kbase_sub_alloc **prealloc_sas)
{
...
//grow memory pool
...
//delta use for allocating pages
gpu_pages = kbase_alloc_phy_pages_helper_locked(reg->gpu_alloc, pool,
delta, &prealloc_sas[0]);
...
//old_size used for growing gpu mapping
ret = kbase_mem_grow_gpu_mapping(kctx, reg, info->commit_pages,
old_size);
The function kbase_alloc_phy_pages_helper_locked allocates delta number of pages and appends them to the reg->gpu_alloc->pages array. In order words, delta pages are added to the entries between reg->gpu_alloc->pages + nents and reg->gpu_alloc->pages + nents + delta:
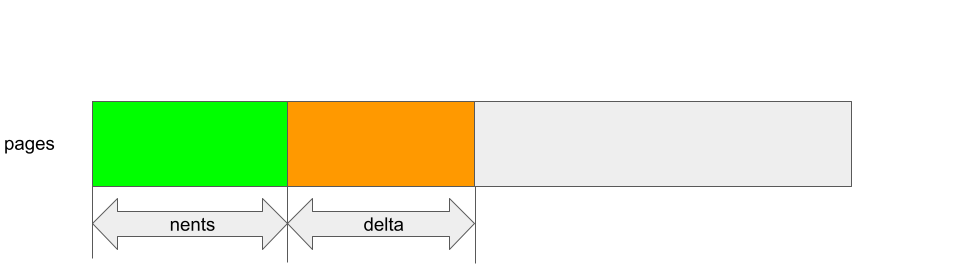
The function kbase_mem_grow_gpu_mapping, on the other hand, maps the pages between reg->gpu_alloc->pages + old_size and reg->gpu_alloc->pages + info->commit_pages to the gpu addresses between region_start_address + old_size * 0x1000 and region_start_address + info->commit_pages * 0x1000, where region_start_address is the GPU address at the start of the region:
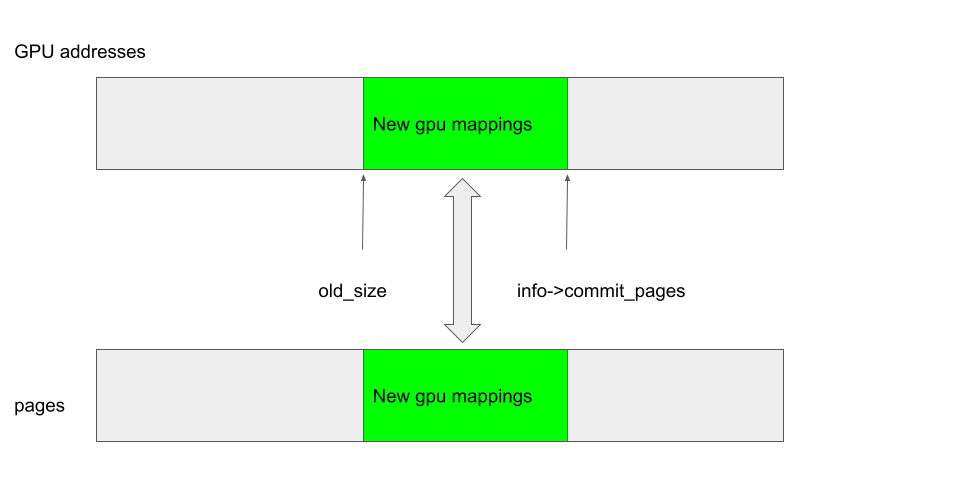
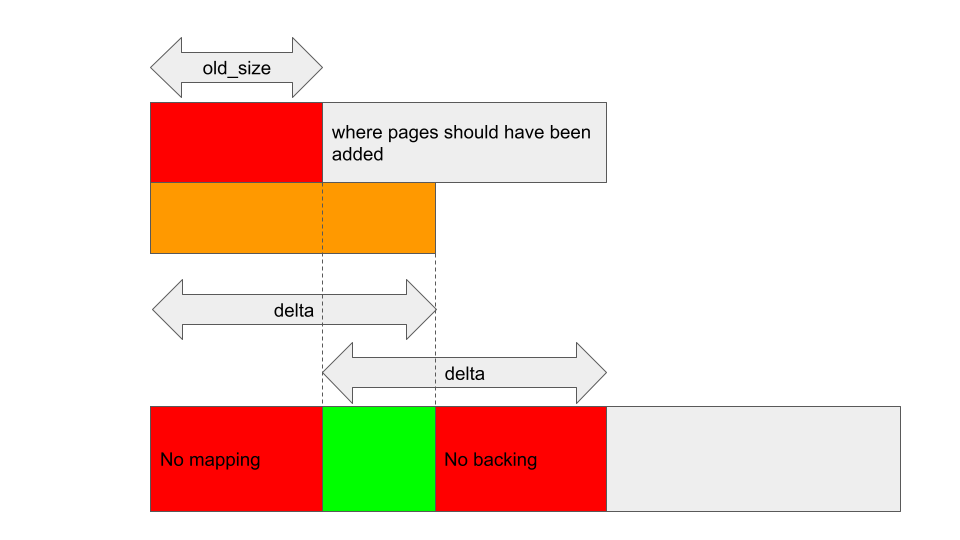
Now, what if reg->gpu_alloc->nents changed after old_size and delta are stored? For example, if I shrink the backing store of reg so that the new nents is smaller than old_size, then kbase_alloc_phy_pages_helper_locked will add delta pages to reg->gpu_alloc->pages, starting from reg->gpu_alloc->pages + nents:
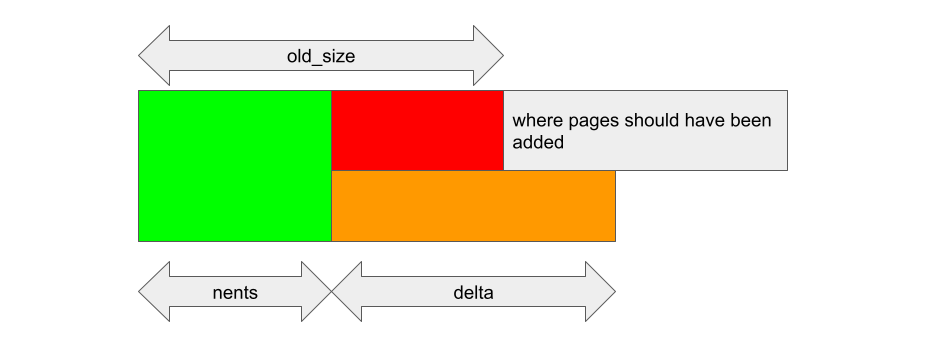
After that, kbase_mem_grow_gpu_mapping will insert GPU mappings between region_start_address + old_size * 0x1000 and region_start_address + info->commit_pages * 0x1000, and back them with pages between reg->gpu_alloc->pages + old_size and reg->gpu_alloc->pages + info->commit_pages, independent of what nents is:
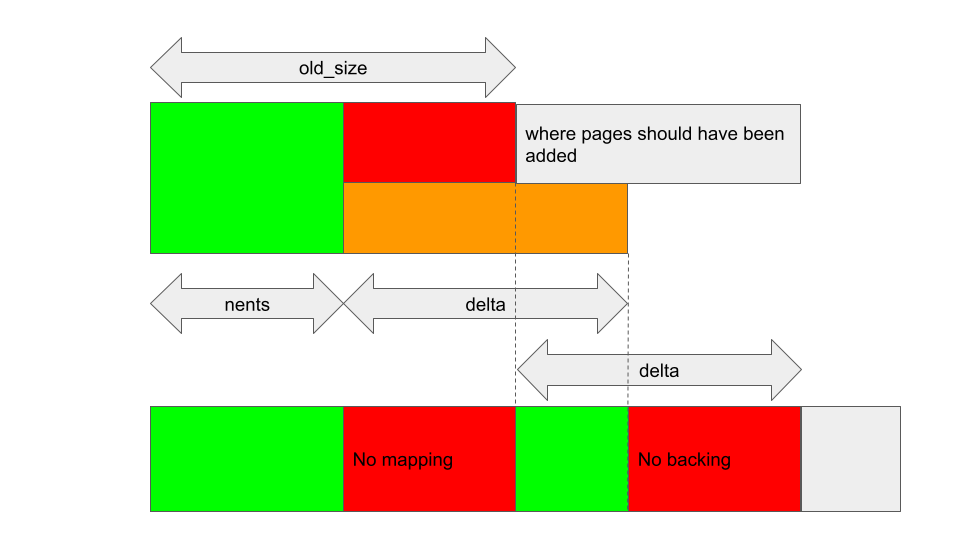
This creates gaps in reg->gpu_alloc->pages where the backing pages are not mapped to the GPU (indicated by No mapping in the figure) and gaps where addresses are mapped to the GPU but there are no backing pages (indicated as No backing in the above). Either way, it’s not obvious how to exploit such a situation. In the “No mapping” case, the addresses are invalid and accessing those addresses from the GPU simply results in a fault. In the latter case, the addresses are valid but the backing memory has zero as their physical address. Accessing these addresses from the GPU is most likely going to result in a crash.
A curious optimization
While auditing the Arm Mali driver code, I’ve noticed an interesting optimization in the kbase_mmu_teardown_pages function. This function is called to remove GPU mappings before releasing their backing pages. It is used every time a memory region is released or when its backing store shrinks.
This function essentially walks through a GPU address range and marks their page table entries as invalid, so the address can no longer be accessed from the GPU. What is curious about it is that, if it encounters a high level page table entry that is already marked as invalid, then it’ll skip a number of GPU addresses that belong to this entry:
int kbase_mmu_teardown_pages(struct kbase_device *kbdev,
struct kbase_mmu_table *mmut, u64 vpfn, size_t nr, int as_nr)
{
...
for (level = MIDGARD_MMU_TOPLEVEL;
level <= MIDGARD_MMU_BOTTOMLEVEL; level++) {
...
if (mmu_mode->ate_is_valid(page[index], level))
break; /* keep the mapping */
else if (!mmu_mode->pte_is_valid(page[index], level)) {
/* nothing here, advance */
switch (level) {
...
case MIDGARD_MMU_LEVEL(2):
count = 512; //<------ 1.
break;
...
}
if (count > nr)
count = nr;
goto next;
}
...
next:
kunmap(phys_to_page(pgd));
vpfn += count;
nr -= count;
For example, if the level 2 page table entry is invalid, then mmu_mode->pte_is_valid in the above will return false, and path 1. is taken, which sets count to 512, which is the number of pages contained in a level 2 page table entry. After that, the code jumps to next, which simply advances the address by 512 pages and skips cleaning up the lower-level page table entries for those addresses. If the GPU address where this happens aligns with the size of the entry (512 pages in this case), then there is indeed no need to clean up the level 3 page table entries, as they can only be reached if the level 2 entry is valid.
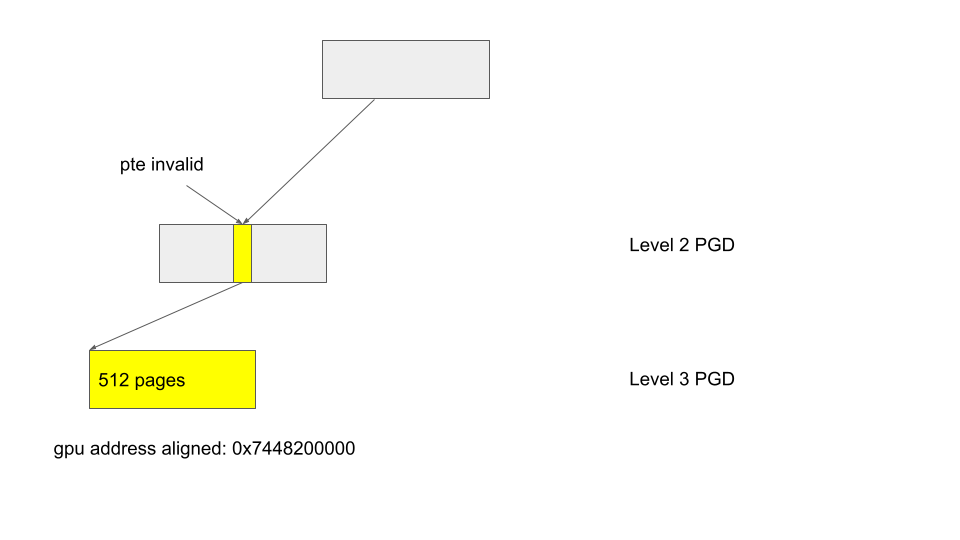
If, however, the address where pte_is_valid is false does not align with the size of the entry, then the clean up of some page table entries may be skipped incorrectly.
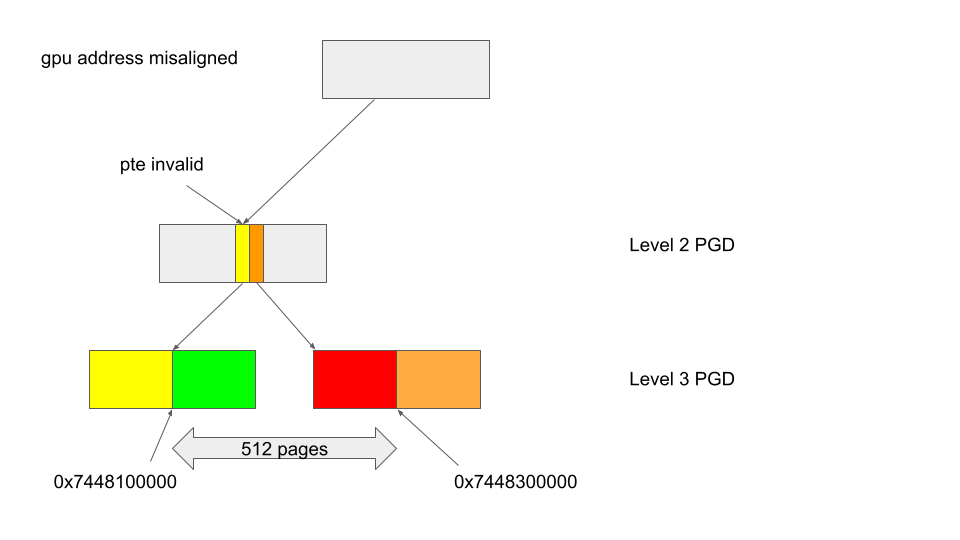
In the above figure, the yellow entry in the level 2 PGD is invalid, while the orange entry right after it is valid. When kbase_mmu_teardown_pages is called with the address 0x7448100000, which has a 256 page offset from the start of the yellow entry, pte_is_valid will return false because the yellow entry is invalid. This then causes the clean up of the addresses between 0x7448100000 and 0x7448300000 (which is 0x7448100000 + 512 pages), to be skipped. For the addresses between 0x7448100000 and 0x7448200000, which is indicated in the green block, this is correct as the addresses are under the yellow entry and cannot be reached. The addresses between 0x7448200000 and 0x7448300000, indicated by the red block, however, are under the orange entry and can still be reached, so skipping their clean up is incorrect as they can still be reached from the orange entry, which is valid.
As it turns out, in all use cases of kbase_mmu_teardown_pages, a valid start address vpfn is passed, which ensures that whenever pte_is_valid is evaluated to false, the corresponding GPUaddress is always aligned and the clean up is correct.
Exploiting the bug
This, however, changes with the bug that we have here.
Recall that, by changing the size of the JIT region while kbase_jit_grow is running, it is possible to create memory regions that have a “gap” in their gpu mapping where some GPU addresses that belong to the region are not mapped. In particular, if I shrink the region completely while kbase_jit_grow is running, I can create a region where the start of the region is unmapped:
When this region is freed, its start address is passed to kbase_mmu_teardown_pages to remove its GPU mappings. If I, then take care so that:
- The start of this region is not aligned with the boundary of the level 2 page table entry that contains it;
- The previous addresses within this level 2 page table entry are also unmapped;
- The “gap” of unmapped addresses in this region is large enough that the rest of the addresses in this level 2 page table entry are also unmapped.
Then, the level 2 page table entry (the yellow entry) containing the start address of the region will become invalid, and when kbase_mmu_teardown_pages is called and pte_is_valid is evaluated at the start of the region, it’ll return false for the yellow entry:
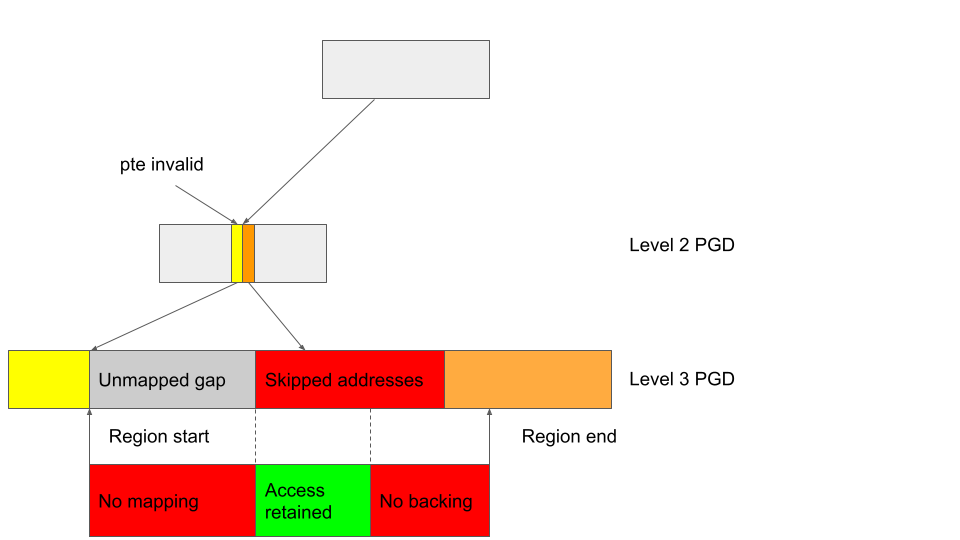
The cleanup in kbase_mmu_teardown_pages then skips the GPU addresses in the orange entry, meaning that the GPU mapping for the addresses in the green block will remain even after the region and its backing pages are freed. This allows the GPU to retain access to memory pages that are already freed.
In the case of a JIT memory region, the only way to free the region is to first place it in the evict_list by submitting the BASE_JD_SOFT_JIT_FREE GPU job, and then create memory pressure, for example, by mapping a large amount of memory via mmap, to cause the linux shrinker to run and free the JIT region that is in the evict_list. After the corrupted JIT region is freed, some of its GPU addresses will retain access to its backing pages, which are now freed and can be reused for other purposes. I can then use the GPU to gain access to these pages when they are reused. So, the two remaining problems now are:
- The amount of memory pressure that is required to trigger the Linux shrinker is uncertain, and after allocating a certain amount of memory, there is no guarantee that the shrinker will be triggered. I’d like to find a way to test whether the JIT memory is free after each allocation so that I can reuse its backing pages more reliably.
- Reuse the backing pages of the JIT memory in a way that will allow me to gain root.
For the first problem, the situation is very similar to CVE-2022-38181, where the use-after-free bug was triggered through memory eviction, so I can apply the solution from there. The Arm Mali driver provides an ioctl, KBASE_IOCTL_MEM_QUERY that allows users to check whether a memory region containing a GPU address is valid or not. If the JIT region is evicted, then querying its start address with KBASE_IOCTL_MEM_QUERY will return an error. So, by using the KBASE_IOCTL_MEM_QUERY ioctl every time after I mmap some memory, I can check whether the JIT region has been evicted or not, and only try to reclaim its backing pages after it has been evicted.
For the second problem, we need to look at how the backing pages of a memory region are freed. The function kbase_free_phy_pages_helper is responsible for freeing the backing pages of a memory region:
int kbase_free_phy_pages_helper(
struct kbase_mem_phy_alloc *alloc,
size_t nr_pages_to_free)
{
...
bool reclaimed = (alloc->evicted != 0);
...
while (nr_pages_to_free) {
if (is_huge_head(*start_free)) {
...
} else {
...
kbase_mem_pool_free_pages(
&kctx->mem_pools.small[alloc->group_id],
local_end_free - start_free,
start_free,
syncback,
reclaimed);
freed += local_end_free - start_free;
start_free += local_end_free - start_free;
}
}
...
}
The function calls kbase_mem_pool_free_pages to free the backing pages, and depending on the reclaimed argument, it either returns the page into memory pools managed by the Arm Mali driver, or directly back to the kernel’s page allocator. In our case, reclaimed is set to true because alloc->evicted is non zero due to the region being evicted. This means the backing pages will go directly back to the kernel’s page allocator
void kbase_mem_pool_free_pages(struct kbase_mem_pool *pool, size_t nr_pages,
struct tagged_addr *pages, bool dirty, bool reclaimed)
{
...
if (!reclaimed) { //<------ branch not taken as reclaim is true
/* Add to this pool */
...
}
/* Free any remaining pages to kernel */
for (; i < nr_pages; i++) {
...
p = as_page(pages[i]);
kbase_mem_pool_free_page(pool, p); //<---- returns page to kernel
pages[i] = as_tagged(0);
}
...
}
This means that the freed backing page can now be reused as any kernel page, which gives me plenty of options to exploit this bug. One possibility is to use my previous technique to replace the backing page with page table global directories (PGD) of our GPU kbase_context.
To recap, let’s take a look at how the backing pages of a kbase_va_region are allocated. When allocating pages for the backing store of a kbase_va_region, the kbase_mem_pool_alloc_pages function is used:
int kbase_mem_pool_alloc_pages(struct kbase_mem_pool *pool, size_t nr_4k_pages,
struct tagged_addr *pages, bool partial_allowed)
{
...
/* Get pages from this pool */
while (nr_from_pool--) {
p = kbase_mem_pool_remove_locked(pool); //<------- 1.
...
}
...
if (i != nr_4k_pages && pool->next_pool) {
/* Allocate via next pool */
err = kbase_mem_pool_alloc_pages(pool->next_pool, //<----- 2.
nr_4k_pages - i, pages + i, partial_allowed);
...
} else {
/* Get any remaining pages from kernel */
while (i != nr_4k_pages) {
p = kbase_mem_alloc_page(pool); //<------- 3.
...
}
...
}
...
}
The input argument kbase_mem_pool is a memory pool managed by the kbase_context object associated with the driver file that is used to allocate the GPU memory. As the comments suggest, the allocation is actually done in tiers. First, the pages will be allocated from the current kbase_mem_pool using kbase_mem_pool_remove_locked (1 in the above). If there is not enough capacity in the current kbase_mem_pool to meet the request, then pool->next_pool is used to allocate the pages (2 in the above). If even pool->next_pool does not have the capacity, then kbase_mem_alloc_page is used to allocate pages directly from the kernel via the buddy allocator (the page allocator in the kernel).
When freeing a page, provided that the memory region is not evicted, the same happens in reverse order: kbase_mem_pool_free_pages first tries to return the pages to the kbase_mem_pool of the current kbase_context, if the memory pool is full, it’ll try to return the remaining pages to pool->next_pool. If the next pool is also full, then the remaining pages are returned to the kernel by freeing them via the buddy allocator.
As noted in my post “Corrupting memory without memory corruption,” pool->next_pool is a memory pool managed by the Mali driver and shared by all the kbase_context. It is also used for allocating page table global directories (PGD) used by GPU contexts. In particular, this means that by carefully arranging the memory pools, it is possible to cause a freed backing page in a kbase_va_region to be reused as a PGD of a GPU context. (The details of how to achieve this can be found here.)
After triggering the vulnerability, I can retain access to freed backing pages of a JIT region and I’d like to reclaim this page as a PGD of a GPU context. In order to do so, I first need to reuse it as a backing page of another GPU memory region. However, as the freed backing page of the JIT region has now been returned to the kernel, I can only reuse it as a backing page of another region if both the memory pool of the kbase_context and the shared memory pool of the Mali driver (pool->next_pool) are emptied. This can be achieved simply by creating and allocating a sufficient amount of memory regions from the GPU. By doing so, some of the memory regions will take their backing pages from the kernel allocator when the memory pools run out of capacity. So, by creating enough memory regions, the freed backing page of our JIT region may now be reused as a backing page of one of these newly created regions.
To identify which of these new memory regions had reclaimed our backing page, recall that the freed JIT region page is still reachable from the GPU via a GPU address associated with the freed JIT region. I can instruct the GPU to write some recognizable “magic values” to this address, and then search for these “magic values” in the newly created memory regions to identify the one that has reclaimed the backing page.
After identifying the region, I can manipulate the memory pool of its GPU context so that it becomes full, and then when I free this region, its backing page will be returned to pool->next_pool, the shared memory pool managed by the Mali driver. This allows the page to be reused as a PGD of a GPU context. By writing to the GPU address in the freed JIT region, I can then write to this page and modify the PGD. As the bottom level PGD stores the physical addresses of the backing pages to GPU virtual memory addresses, writing to PGD enables me to map arbitrary physical pages to the GPU memory, which I can then access by issuing GPU commands. This gives me access to arbitrary physical memory. As physical addresses for kernel code and static data are not randomized and depend only on the kernel image, I can use this primitive to overwrite arbitrary kernel code and gain arbitrary kernel code execution.
To summarize, the exploit involves the following steps:
- Allocate a JIT memory region, and then free it so that it gets placed on the
jit_pool_headlist. - Allocate another JIT memory region and request a large backing store, this will reuse the freed region in the
jit_pool_headfrom the previous step. Provided the requested size is large enough, the Mali driver will try to grow the memory pools to fulfill the request. - From a different thread, use the
KBASE_IOCTL_MEM_COMMITioctlto shrink the backing store of the JIT memory region allocated in step 2. to zero. If this happens while the Mali driver is growing the memory pool, the JIT memory region will become corrupted with the GPU addresses at the start of the region becoming unmapped. As a growing memory pool involves many slow and large allocations, this race can be won easily. - Free the JIT region and to place it on the
evict_list. - Increase memory pressure by mapping memory to user space via normal
mmapsystem calls. - Use the
KBASE_IOCTL_MEM_QUERYioctlto check if the JIT memory is freed. Carry on applying memory pressure until the JIT region is freed. - Allocate new GPU memory regions to reclaim the backing pages of the freed JIT memory region.
- Identify the GPU memory region that has reclaimed the backing pages.
- Free the GPU memory region identified in step 8. and then reuse its backing pages as PGD of a GPU context (using the technique described in my previous blog post).
- Rewrite the page table entries so that some GPU addresses point to kernel code. This allows me to rewrite kernel code from the GPU to gain arbitrary kernel code execution, which can then be used to rewrite the credentials of our process to gain root, and to disable SELinux.
The exploit for Pixel 6 can be found here with some setup notes.
Conclusion
In this post I looked at a small change made in version r40p0 of the Arm Mali driver that was somehow missed out when other security patches were applied to the Pixel 6.
Software vendors often separate security related patches from other updates so that their customers can apply a minimal set of security patches while avoiding backward incompatible changes. This creates an interesting situation where the general public, and in particular, attackers and security researchers, only see the entire set of changes, rather than the security-related changes that are going to be backported and used by many users.
For an attacker, whether or not a change is labeled as security-related makes very little difference to what they do. However, for a security researcher who is trying to help, this may stop them from reporting a mislabeled security issue and cause a delay in the patch being applied. In this particular case, although I noticed the change, I never thought to investigate it too closely or to report it as I assumed it would be applied. This resulted in considerable delay between the bug being identified and patched and, in the end, leaving Android users vulnerable to an N-day vulnerability for several months. Making the backporting process more transparent and identifying security patches in public releases could perhaps have prevented such a delay and reduced the amount of time where this bug was exploitable as an N-day.
Notes
- Observant readers who learn their European history from a certain comic series may recognise the similarities between this and the beginning of the very first book in the Asterix series, “Asterix the Gaul.” ↩
Tags:
Written by

Related posts
How GitHub gave every repository a durable owner
GitHub had over 14,000 repositories. Fewer than half had clear ownership. Here’s how we gave every active repository a validated owner in under 45 days, archived the rest, and made ownership the foundation for everything that followed.
How GitHub used secret scanning to reach inbox zero
GitHub had 20,000+ secret scanning alerts across 15,000 repositories. Here’s how we separated signal from noise, built remediation workflows, and reached inbox zero in nine months.
6 security settings every GitHub maintainer should enable this week
These six free settings will not make your project unhackable. Nothing will. What they will do is close the easy doors. Turn these on, and your project will be meaningfully harder to attack than it was before.