The Story of Scalar
New to Git v2.38, Scalar is a built-in repository manager for large repos. Here, we’ll tell the story of how Scalar went from a rough VFS for Git successor to a fully-integrated Git tool, with all of the engineering lessons learned in the process.

When you install Git v2.38, you’ll find a new executable tool available called scalar. At its core, Scalar enables the latest and greatest Git features for working with large repositories. By simply switching from git clone to scalar clone, you will have all of Git’s most impactful performance features, such as partial clone, sparse-checkout, background maintenance, and advanced config options neatly configured for your repository. Have you already cloned your repository? Run scalar register in it to get the same features.

Although Scalar is only now making its formal Git debut, this release represents the culmination of a multi-year journey. Today, we will share the story of how Scalar got to this point. We’ll start from what inspired its creation, how it evolved from a prototype carved out of the VFS for Git codebase, and finally how it landed in upstream Git. Each step of the way was guided by a set of development principles that helped us with each challenge and opportunity.
Special thanks to @chrisd8088, @dscho, @jeffhostetler, @jrbriggs, @kyle-rader, @mjcheetham, @ldennington, @prplr, @wilbaker, and all of the other contributors who helped make this happen!
Our development principles
Before we get into specifics about how Scalar was built and eventually rewritten and contributed upstream, we need to first establish some context. We entered the project with certain values that we used to guide our decisions. Here are a few that are particularly important to this story.
Rapid prototyping
Code speaks volumes. We could design an architecture all we want on paper, but when solving problems at scale, we need to have actual code running before we can make a final decision.
Before committing to a decision, we would quickly build a prototype and measure its performance. During this prototyping phase, we would take shortcuts to get to that point of measurement. Then, we’d throw everything we could at the prototype to make sure it was correct and fast.
Based on the prototype, we would commit to doing the careful engineering of building the feature again but with a test strategy, thoughtful architecture, and a plan for delivering it to users.
Incremental changes over complete rewrites
Looking at where we started to where we ended, it might seem like we are proponents of rewriting things from scratch. We intend to demonstrate exactly the opposite: Scalar moved with small incremental changes that solved an immediate need. While making those changes, we also optimized for reducing our technical debt and creating a better architecture, and that resulted in code moving from .NET to C and then from our fork to upstream Git, but each individual movement was relatively small compared to the entire system.
The biggest reason we focused on incremental changes was because of our next value.
Tests are an asset
Making any kind of software change adds risk to a project. That risk is mitigated when we have a large set of battle-hardened tests. With a robust test suite available, we were able to make significant changes to our architecture with confidence.
Work in the open
Other than the earliest prototypes, all changes were reviewed and merged completely in public, either in the microsoft/scalar repository or the microsoft/git repository. Scalar was an open source project from day one, and was never intended to be a project only for internal use. By contrast, VFS for Git was built as a tool for Microsoft’s internal use first, and open sourcing it was a bonus after it reached enough adoption. Not only did we value that transparency during Scalar’s development, but now we have a history of public code changes to talk about here.
Now that we’ve established these values, let’s begin the story of Scalar.
A catalyst forces a pivot
The Virtual FileSystem for Git project (VFS for Git for short—previously “GVFS”) was built specifically to transition the Microsoft Windows OS monorepo to Git. VFS for Git utilizes a virtual filesystem to lazily load files only when a filesystem read occurs. This greatly reduced the amount of work Git needed to do, but required installing the microsoft/git fork as well as the .NET VFS for Git software and use Azure Repos to host the repository.
Initially, the Microsoft Office monorepo was going to onboard to Git using VFS for Git, but they needed cross-platform support, specifically for macOS development. After getting pretty far in a macOS port, Apple deprecated the kernel features that provided the filesystem virtualization that was required for that flow.
We were in luck, however, because we had come to understand something a key quality of the Office monorepo: Office has a rigorous dependency system that clearly identifies which files are necessary for a local build. This means that a developer could specify the files they need to Git’s sparse-checkout feature instead of dynamically populating the worktree using a virtual filesystem. This also significantly simplifies the software needed to manage their monorepo!
However, there was a problem. The sparse-checkout feature had previously been abandoned as a direction for VFS for Git due to its performance. Git would use a list of patterns to match which paths should be in the worktree and which should be ignored. This pattern matching had an ordering strategy that required iterating through the entire pattern list for every possible path, requiring quadratic time! For one of the larger sparse-checkout definition examples we had, Git would take 40 minutes to evaluate the sparse-checkout patterns.
Sparse-checkout definitions are extremely generic. They include matching on file prefix, but also file suffix, or path substring, and any combination. For our target monorepo, we only needed directory matches. With that limited type of pattern in mind, we added a new mode to Git’s sparse-checkout feature: “cone mode” sparse-checkout. A quick prototype of cone mode sparse-checkout demonstrated that Git could reach similar performance as VFS for Git, especially when paired with the filesystem monitor hook. Our critical performance measurement was the git status command, and we were seeing performance within three or four seconds, which was close to the typical case in VFS for Git.
This was promising enough to move forward with a full prototype. We decided to make this a separate project from VFS for Git, so it needed its own name: Scalar.
Throw the first one away
Once we had a handle on Git command performance using Git’s sparse-checkout feature, we needed to adapt all of the code that allowed fast clones and fetches to work within that environment. For most Git hosting services, Git’s partial clone feature is the best way to solve for fast clones and fetches. However, Azure Repos has an earlier version that was built for VFS for Git called the GVFS protocol. We needed a way to speak the GVFS protocol to bootstrap clones and to dynamically fetch missing objects during Git commands.
This was our first point of asking, “Should we rewrite, or refactor?” The VFS for Git codebase already had all of the client-side code for speaking the GVFS protocol. Not only that, it also had a large set of end-to-end tests that constructed a complete clone from Azure Repos and then ran thousands of Git commands in that environment to make sure they operated exactly the same as a normal Git clone. Since those tests were a significant asset, we set out to construct the first version of this new project starting with the VFS for Git code.
In this initial prototype, we just wanted to get things working for the end-to-end tests to pass. This process included disabling the virtual filesystem code, but leaving all of the hooks that enabled the GVFS Protocol. We also needed to set up sparse-checkout at clone time before initializing the HEAD reference. This prototype was so rough it still didn’t have the Scalar name: it still operated as if it was the gvfs command-line interface.
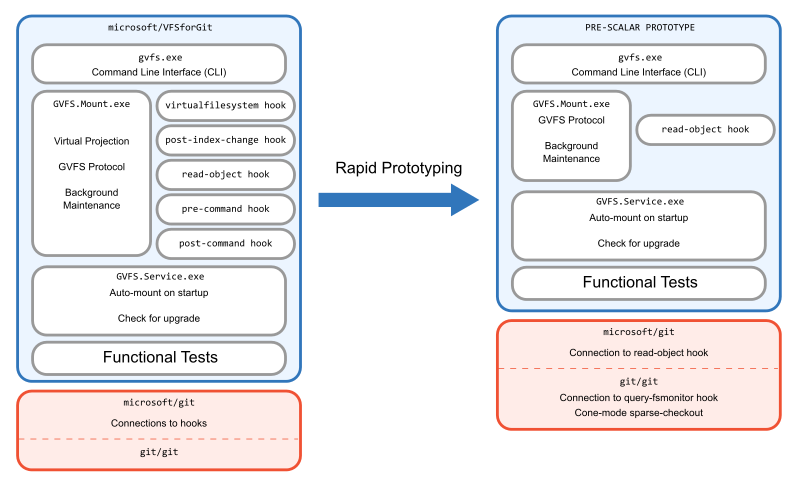
The end result wasn’t pretty. We couldn’t hope to ship it since it would break compatibility with previous VFS for Git versions. The tests were cobbled together to make things work, but we had disabled sparse-checkout in the tests since the previous tests assumed that every path could be populated dynamically with the virtual filesystem. However, we got to a point where we could reliably create this new repository setup and measure its success. Since the clones were doing the exact same thing as in VFS for Git, the performance matched exactly. Now, we needed to rebuild it, and do it the right way.
Get to Minimum Viable Product (MVP)
From the success of our initial prototype, we moved on to creating an MVP that we could demo to internal users. Here is where we created the Scalar name, the microsoft/scalar repository, and started doing thorough reviews of all changes.
As a team, we decided it would be best to create a new repository rather than to build the project within the VFS for Git codebase. We did not want to be locked into the architecture of VFS for Git as we moved forward, and we also wanted to take advantage of the commit history for the code in the repository. The first task in creating the new project was renaming all references to the old project.
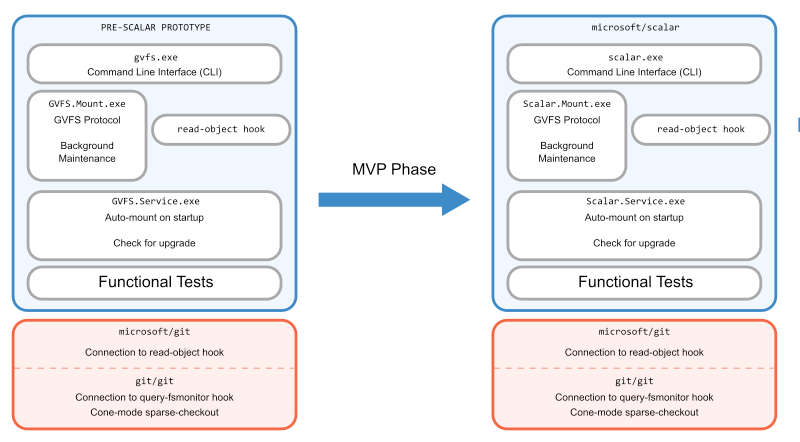
Updating tests
The next step we had to do was to make sure that we were sufficiently testing the sparse-checkout environment. Recall that we used the full worktree to get tests passing in the prototype, but now we needed to actually be sure that our sparse-checkout environment would work properly.
For this, we found a minimal set of patterns that would include all of the concrete paths used by the test suite.
Then, we made sure that there were interesting changes happening outside of those patterns that would exercise Git features like git merge or git cherry-pick in interesting ways outside of the sparse-checkout definition.
Finally, we added specific tests that involved changing the sparse-checkout definition to make sure that Git would properly fill in the missing files. In this way, we were able to keep all of the existing tests while also adding new tests that were specific to our environment.
Evaluating the MVP
After completing the product changes and test updates, it was time to evaluate the solution. We ran performance numbers to ensure they matched what we saw in our prototype phase. We created local clones to use in daily work to try and catch any lingering bugs.
But it all came down to evaluating the solution with internal users. We demoed Scalar directly with the Office engineering system team and asked pointed questions about whether this would work for them.
In particular, we were worried about the performance of git checkout. In VFS for Git, git checkout is extremely fast because it doesn’t actually do much work. It clears the filesystem of concrete files and replaces them with virtualized files. The cost of populating the filesystem comes later when those files are read by an IDE or a build process. With Scalar, the filesystem is populated within the git checkout process, so that work is now upfront and clear to the user.
By working directly with the engineering system team, we learned that this git checkout performance was not an issue. Since git checkout changes source files, it invalidates the local build. Build times can take hours in this monorepo after taking new changes, so users typically do not use git checkout until the end of the day when they are ready to trigger a long build overnight. For this reason, git checkout was not a critical path for their developers. In fact, there was great interest in being able to know that they could disconnect from the network and still poke around the code without risk of finding a virtual file.
We were good to go with our plan for Scalar. However, the monorepo team needed to build something of their own. They needed a connection between their build system and sparse-checkout. While they built that, we had time to polish Scalar and make it easier to install and use.
Update architecture under stable conditions
With the benefit of a stable test suite and a few months of runway, we were able to take our MVP and rethink the architecture. In particular, we shed some architectural decisions that were critical to how VFS for Git works, but were no longer needed in Scalar.
VFS for Git requires a process running that can handle requests from the filesystem to populate virtualized content on-demand. The existence of this process creates the concept of a “mounted” repository, and even included the commands gvfs mount and gvfs unmount to toggle this state.
Because this process needed to exist, a lot of other things were placed in that process that could be relocated elsewhere in Scalar. We set out to remove the need for this process.
Since we had already removed the virtual filesystem code, there were two remaining pieces that were in the mount process: performing background maintenance and downloading objects via the GVFS protocol.
For background maintenance, we took the fastest approach and moved the scheduled tasks out of the mount process and into the Scalar.Service global singleton process. We had versions of this service for Windows and macOS to handle things like startup operations. Moving the maintenance tasks to this service was quick and easy.
For the object downloads, it was a bigger job. The existing architecture included a read-object hook custom to microsoft/git that was installed by the scalar clone command, and that hook communicated to the mount process which actually communicated with the server and placed the objects in the repository.
For this, we created a tool within microsoft/git to do these missing object queries via the GVFS protocol directly within the Git codebase. This tool lives underneath the code that fills in objects for Git’s partial clone feature. By connecting this tool to partial clone, we could work to improve partial clone while also helping Scalar users at the same time. One major benefit to working within the partial clone framework is that some missing object requests can be batched together into a single request, while the old read-object hook could only ask for one missing object at a time.
Finally, there was nothing important remaining in the mount process, so we deleted it. In addition, we were able to delete the old Git hook.
At this point, we had simplified the architecture to have fewer moving parts and were ready to ship internally.

Upon success, look for low-hanging fruit
Shortly after announcing Scalar to the world, we realized that Scalar could have a larger benefit to the Git ecosystem than just very large monorepos using Azure Repos.
We extended scalar clone to use Git’s partial clone if the remote did not speak the GVFS protocol. In this way, scalar clone became something a user could run against any Git remote.
This was an inflection point in our lifecycle: we had accomplished what we set out to do, but wanted to put these tools in front of more people and find a wider audience. We started to shift our focus from making updates in the .NET project and instead contributing features to the upstream Git project.
Rethink architecture as conditions change
Up until this point, we were using the existing hook approach that speaks to a third-party filesystem monitor. This meant that we needed to install that third-party tool next to Scalar, but also scalar clone would install the hook in addition to all of its other operations. We realized that we could solve our installation complexities, reduce the complexity of scalar clone, and get faster performance if the filesystem monitor was built into Git. With that context, we began building Git’s builtin filesystem monitor. We took early versions into microsoft/git while it was reviewed carefully by the Git community.
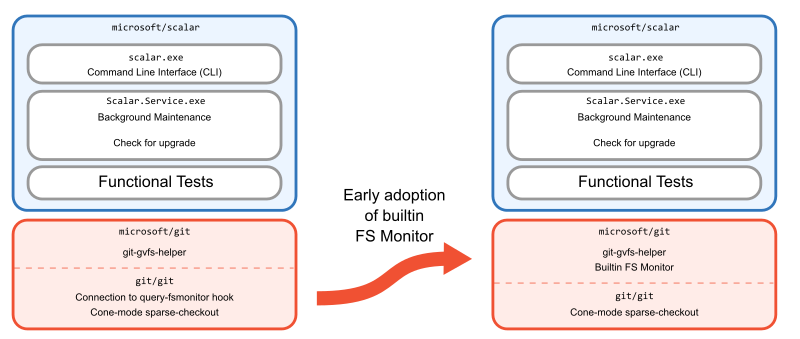
An important Scalar feature was background maintenance, which was accomplished by a service running in the background and launching Git commands at certain intervals to keep data fresh and well-organized. This service existed from the VFS for Git days, so it was easy to keep using it on Windows and macOS. However, when the Office team told us that they needed Linux clients to support some of their web developers, we focused on porting Scalar to Linux. This service was one platform-specific part that would be difficult to implement in .NET.
We decided that instead of creating a new service in Scalar, it would be better to implement background maintenance in Git. Once Git had its own cross-platform way of doing maintenance, Scalar could stop using its custom logic and instead rely on git maintenance run.
We then removed the service from Scalar.
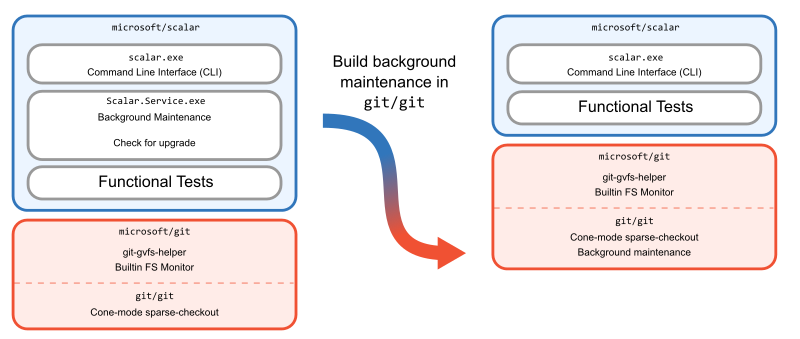
After making this change, we took another look at our architecture and realized something. Suddenly, Scalar was only a command-line interface on top of Git. Why have it be in C#, separate from the Git source code?
The overhead of dealing with Scalar as a .NET tool was colliding with our maintenance costs of creating releases and shipping it to users. If Office developers require the microsoft/git fork of Git and another tool then things get tricky when we want to release a new version.
We had replaced so many features in the Scalar codebase with Git functionality that starting from a clean slate could allow us to build a more manageable architecture than that of the existing code. Also, by inserting the Scalar CLI into the Git codebase, we could take advantage of internal functions such as using Git config APIs instead of running git config processes to set recommended config values.
With these goals in mind, we ported the Scalar CLI to C in microsoft/git using less than 3,000 lines of code!
This endeavor to recreate the Scalar CLI in the microsoft/git codebase can best be appreciated by seeing that we deleted over 10 times the amount of code from microsoft/scalar than we added to microsoft/git when we removed all product code. We kept the microsoft/scalar repository around as a collection of tests, allowing us to be confident in the new code.
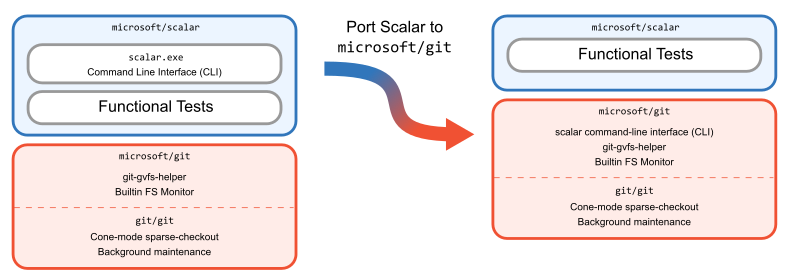
This was our biggest step in the journey because it involved the largest rewrite of Scalar code. However, the requirements of the Scalar CLI at this point were well-defined and greatly simplified from earlier. We were able to immediately celebrate by no longer shipping the .NET Scalar application to our internal customers and instead rely on just shipping the microsoft/git fork.
There was one downside to this change, though. Before, you could install the .NET Scalar solution on top of any Git version and still get all the benefits of scalar clone. Now, users needed to replace their Git client with microsoft/git in order to get the latest Scalar version. We wanted to make Scalar useful to everyone, not just those that were willing to install our fork.
The journey into core Git
Porting Scalar to C not only enabled hosting the tool in microsoft/git, it opened up the possibility of making Scalar part of the upstream Git project. Although it wouldn’t be the first feature originating in microsoft/git that was contributed upstream, there was no clear precedent for something like Scalar: a standalone executable whose name didn’t start with git in the Git project. That might sound like nothing more than an implementation detail, but it represented a philosophical departure from the existing tools in Git. This divergence would drive us to define what Scalar meant for Git.
contrib/-uting to Git
From the outset, we knew there was a contingent of Git users that would benefit from Scalar beyond microsoft/git‘s typical user base. Features like the filesystem monitor, background maintenance, cone mode sparse-checkout, etc. had all become popular among developers in large repositories. Scalar exposed those and a multitude of other features more readily to users. Still, it wasn’t clear that Scalar as a standalone executable was the best—or Git-friendliest—way to present those features.
To gradually introduce the tool to the Git community, Scalar’s journey upstream began in Git’s contrib/ directory. From the contrib/ README:
Although these pieces are available as part of the official git
source tree, they are in somewhat different status. The
intention is to keep interesting tools around git here, maybe
even experimental ones, to give users an easier access to them,
and to give tools wider exposure, so that they can be improved
faster.
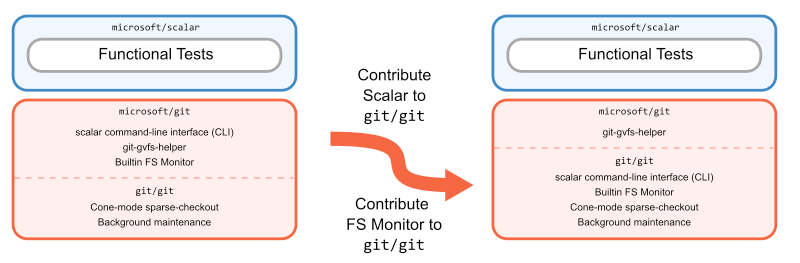
Despite the loose requirements of contrib/, the submitted version of Scalar still required some changes from what was in microsoft/git. First was removing the GVFS protocol-supported clones. As we mentioned earlier, blobless clones were introduced into Scalar as a fallback for clones using the GVFS protocol, so the upstream version defaulted to using blobless partial clones instead. Additionally, to preserve the separation between contrib/ and the main Git repository, the GitHub Actions workflow was also stripped of references to Scalar, including execution of the microsoft/scalar test suite.
However, being in contrib/ did have some drawbacks. In order to build and install Scalar, a user needed to not only build Git from source, but know to navigate into contrib/scalar/ and build that as well. The separate build and test process also left it prone to changes in the rest of Git unintentionally breaking it. Even with these challenges, this arrangement was exactly what Scalar needed while its features were built out and long-term plan was developed. As we drew closer to finishing those features, we needed to finally answer the question: what should we do with Scalar?
Home sweet home
As soon as the possibility of upstreaming Scalar materialized, there were lots of ideas about what its final form would look like. One popular idea—which can be found in the original RFC—was to dissolve Scalar into a collection of new git commands and options to existing commands. Another was to have scalar reside in the Git tree in a dedicated subdirectory, like gitk. Another was to reimagine it as a Git built-in command: something like git scalar. Along with these implementation decisions came overarching questions of maintenance and relevance to Git.
As the tool was nearing feature completion upstream and the downsides of contrib/ isolation were weighing on the project, we took a step back and revisited the questions of Scalar’s identity. The result was a proposal to update Scalar’s documentation and outline a three-part approach to making the tool generally available in Git:
- Add any remaining large repo performance features to Scalar.
- Extract the parts of Scalar that are generally applicable to all Git users into built-in commands and/or options.
- Move Scalar into the root tree of Git, built and installed as a standalone executable alongside
git.
The crux of this approach was a new framing of Scalar within the Git project. Scalar began, like VFS for Git before it, as a tool with its own features and opinions: how to configure a repository, what workflows to use, etc. As it evolved, those features and opinions were folded into Git or adjusted to align better with the upstream project, leaving Scalar with only the parts that fit the very specific role of configuring large repositories. In essence, Git had a user experience niche left by its myriad of large repo-focused performance features. Scalar filled that niche.
The roadmap to Scalar’s completion emerged from this philosophy. First, a few more particularly impactful features would be added to it (namely, the built-in FSMonitor). Then, because Scalar’s purpose is to configure features for large repositories that aren’t set up by default in Git, the parts that serve all Git users (such as repository diagnostics in scalar diagnose) would be extracted into new or existing Git commands. Finally, Scalar would be moved out of contrib/ and into the main build of the repository, intended to continue existing as a dedicated tool for managing large Git repositories.
The best laid plans often go awry but, fortunately, this one didn’t. Over the course of three upstream patch series, Scalar was streamlined inside of contrib/, then moved into its new home as part of core Git. And just in time for the v2.38.0 release!
The past, present, and future of Scalar
We’ve shared the story of Scalar not only to publicize a new and exciting feature in Git (seriously, go try it!), but also to illustrate one of the many paths an open source project can take to reach its users. Planning and re-planning, designing and redesigning, and no shortage of engineering lessons were all necessary steps to make Scalar the powerful tool it is today.
It is now a fully-integrated part of Git, but Scalar’s journey is far from over. Scalability and performance in Git is a hot topic—our own engineering blog is a testament to that—and consistent improvement in that area will undoubtedly be part of Scalar’s future. Today, though, Scalar’s eventful history is what has shaped it into the best way to unlock Git’s full potential on your largest repositories.
Tags:


Related posts

$100 million for open source: A milestone built by the community
Celebrating $100 million contributed by the community to the people who build and sustain open source every day.
6 security settings every GitHub maintainer should enable this week
These six free settings will not make your project unhackable. Nothing will. What they will do is close the easy doors. Turn these on, and your project will be meaningfully harder to attack than it was before.
How GitHub maintains compliance for open source dependencies
Explore how the Open Source Program Office uses GitHub’s new license compliance product to manage open source dependencies at scale.