Git’s database internals V: scalability
This fifth and final part of our blog series exploring Git’s internals shows several strategies for scaling your Git repositories that match related database sharding techniques.
This week, we are exploring Git’s internals with the following concept in mind:
Git is the distributed database at the core of your engineering system.
When the database at the core of an application approaches scale limits of a single database node, a common strategy is to shard the database. By splitting the database into multiple components, we can scale beyond the limits of a single node.
For Git, large repositories can have a similar feeling. While there exist some extremely large monorepos operating with success, they require careful attention and advanced features. For some, that effort is better spent sharding the repository. Just like sharding an application database, there are many ways to split a Git repository, with various trade-offs.
When sharding an application database, there are a number of factors to consider.
Some application databases include automatic horizontal sharding based on a shard key, which is usually a string literal that can be sorted lexicographically so related values appear in the same shard due to a common prefix in the shard key. There is no immediate way to shard Git’s object store in this way. The object IDs are hashes of the object contents and have essentially random prefixes.
Instead, we think of sharding strategies that split the repository by other structures, including logical components, paths in the worktree, and time periods in the commit history.
Component sharding: multi-repo
One way to shard an application database is to split out entire tables that can be operated independently and managed by independent services. The Git equivalent is to split a repository in to multiple smaller repositories with no concrete links between them. This creates a multi-repo sharding strategy.
The common approach to this strategy is to extract functionality out of a monolith into a microservice, but that microservice exists in its own Git repository that is not linked at all to the monolith’s repository. This effort might remove code from the monolith across multiple path prefixes due to the monolith’s architecture.
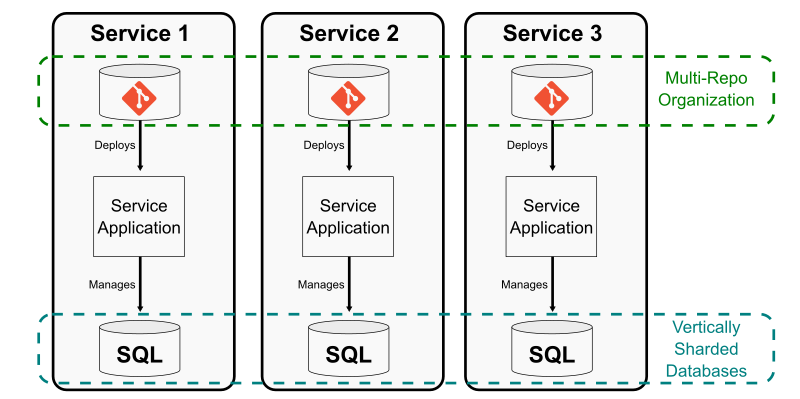
Using this strategy works best if each microservice is paired with a team that manages that repository, including full responsibility for developing, testing, deploying, and monitoring that service. This is very similar to the application database sharding strategy, where there is typically one application component connected to that database shard. There is no need for other components to be aware of that database since it is hidden by the component interface.
Multi-repo environments work best when there is a similar “human abstraction” where the team is autonomous as long as their service satisfies certain contracts that other teams depend on.
The tricky part of the multi-repo setup is that it requires human overhead to track where these component repositories live and how they link together. The only way to link the connections of the larger service ecosystem is through documentation and siloed experiential knowledge. System-wide efforts, such as security audits, become difficult to track to completion.
Another main downside to the multi-repo organization is that shared dependencies become difficult to manage. Common dependencies must be imported using package managers instead of using source control updates. This can make it difficult to track the consumers of those dependencies, leading to a lack of test coverage when updating those core components.
The next sharding strategy solves some of these multi-repo issues by collecting all of the smaller repositories into one larger super-repository.
Horizontal sharding: submodules
Git submodules allow a repository to include a link to another repository within its worktree. The super repository contains one or more submodules at specific paths in the worktree. The information for each submodule is stored in the .gitmodules file, but the tree entry for that submodule’s path points to a commit in the submodule repository.
Submodules create a way to stitch several smaller repositories into a single larger repository. Each has its own distinct commit history, ref store, and object store. Each has its own set of remotes to synchronize. When cloning the super repository, Git does not recursively clone the submodule by default, allowing the user to opt-in to the submodules they want to have locally.
One main benefit of using a super repository is that it becomes the central hub for finding any of the smaller repositories that form a multi-repo setup. This is similar to a horizontally sharded application database that uses a shard coordinator database to actively balance the shards and run queries on the correct shard.
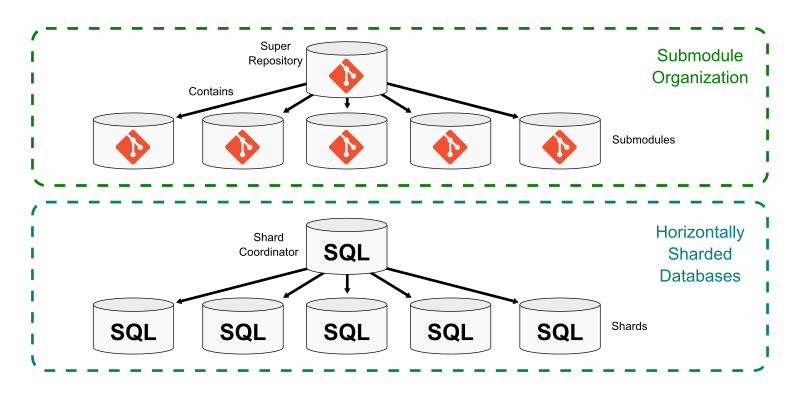
Further, certain global properties can be guaranteed via continuous integration builds such as cross-submodule source dependencies. In this setup, the super project creates requirements that it cannot advance a submodule unless all builds and tests in the super project pass. This creates some safety that a core component does not break any consumer in the super project.
This global structure has a cost. The submodule repositories become less independent. Since they have their own Git hosting location, users can update them by pushing changes. This can even be done with local builds that make sure that component is self-consistent. However, any update to the submodule repository is incomplete until the super project updates its path pointer to that commit. At the same time, should the submodule repository move forward before that change has been validated within the super repository?
This contention between the independence of the submodule repository and the inter-dependence of submodules in the super repository is a major hurdle. It is up to the architects of this arrangement to create policies and procedures to ensure that all of the components interact well with the entire system.
One common issue developers have in a submodule environment is when there is a source dependency across multiple submodules. If a breaking change is introduced in one submodule repository, the consumer repositories need to be updated to take advantage of those changes. However, this means that all of the submodules need to coordinate when they are updated into the super repository.
There are a lot of tools out there in the wild to help manage submodules, all built on top of the git submodule command. One famous example is Google’s repo tool that coordinates changes across multiple submodules.
If you are interested in submodules and super repository workflows, then you would likely benefit from coming to Git Merge 2022 (or, watching the videos afterward), especially Emily Shaffer’s talk, “An Improved Workflow for Submodules.”
Using a single worktree: Monorepos
The previous two examples focused on reducing the size of Git repositories by breaking them up based on the worktree. By having fewer files in each repository, fewer developers are interacting with each and the repositories grow more slowly. Each approach had its benefits and trade-offs, and one big issue with each was build-time source dependencies between components.
Another common way to avoid source dependencies across multiple repositories is to only have one repository: a monorepo. Here, I’m defining a monorepo as a repository containing all source code required to build and ship a large system. This does not mean that every single file written by an employee of the company must be tracked in “the monorepo.” Instead, monorepos are defined by their strategy for how they choose to include components in the same repository:
If it ships together, it merges together.
One pattern that is increasing in popularity is the service-oriented architecture (SOA) monorepo. In this environment, all of the code for the application is contained in the same repository, but each component deploys as an independent service. In this pattern, each component can be tested against the current version of all of the other services before it is deployed.
The monorepo pattern solves many of the coordination issues discussed in the previous sharding strategies. The biggest downside is that the repository itself grows very quickly. As discussed in the previous parts of this series, Git has many advanced features that improve performance even for large repositories. Monorepos more frequently need to enable those advanced Git features, even for client repositories.
One of the main costs of a monorepo is actually the build system. If every change to the monorepo requires passing builds across the entire system, then the build system needs to take advantage of incremental builds so updates to a single component do not require building the entire monorepo. Most groups using large monorepos have a team dedicated to the developer experience, including improving the build system. Frequently, these build improvements can also lead to being able to use advanced Git features such as sparse-checkout and partial clone, which can greatly reduce the amount of data necessary for client repositories to interact with the monorepo.
Even with a carefully designed architecture and the best Git features available, monorepos can still grow incredibly fast. It may be valuable to take a monorepo and find creative ways to split it and reset the size to something smaller.
Time-based sharding
One solution to a fast-growing monorepo is to consider it as if it was a time-series database: the changes over time are important, so what if it shards based on time instead of based on the worktree?
When performing a time-based shard, first determine a point in time where the existing monorepo can be paused and all movement on the trunk branch can be blocked. Pausing work on a monorepo is very unusual, so should be done with extreme care and preparation.
After pausing the changes to the monorepo’s trunk, create a new repository with the same root tree as the current trunk of the old monorepo, but with a brand new root commit. Be sure to reference the old monorepo and its tip commit somewhere in the message of that new root commit. This commit can be pushed to a new repository.
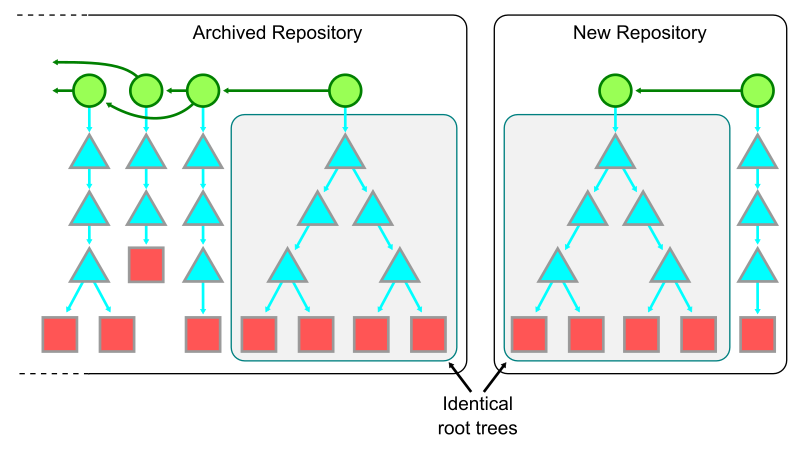
For a quick refresher on how we represent Git objects, see the key below.
Any ongoing work in the old monorepo must be replayed on top of the new repository. One way to do this is to rebase each topic branch onto the final commit of the trunk branch, then generate patches with git format-patch and then apply those patches in the new repository with git am.
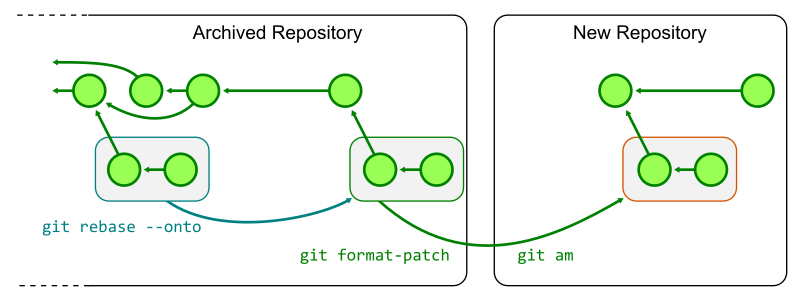
After the new monorepo shard is created, the old monorepo can be archived as a read-only repository as all new work continues in the new monorepo. There are likely many updates required to ensure that everyone knows the new monorepo location as well as repository secrets to update. If your repository uses infrastructure as code patterns, then almost all of the information for building, testing, and deploying the monorepo will automatically be ready in the new monorepo.
Even with all of these precautions, performing a time-based shard like this is disruptive and requires a timeframe where no new work is merging into the trunk. If you are considering doing this in your engineering system, then I highly recommend doing a few test runs to make sure you minimize the time between locking the old shard and deploying out of the new shard.
The biggest benefit of this approach is that it can be done at any time regardless of the shape of your worktree. The other sharding methods require some amount of architecture changes in order to split into multiple repos or submodules. This approach cuts out the potentially large commit history and all of the old versions of files without changing the repository structure at the tip.
A time-based shard might be particularly beneficial if your commit history includes some anti-patterns for Git repositories, such as large binary files. If you have done the hard work to clean up the worktree at the tip of your repository, you may still want to clear those old files. This sharding approach is similar to rewriting history, except that the new monorepo can have an even smaller size.
However, that commit history from the old monorepo is still important! We just discussed commit history and file history queries in this blog series. It is extremely important to be able to find the reasons why the code is in its current form. In the new monorepo shard, it will look like the entire codebase was created in a single commit!
To satisfy these history queries, Git can combine the two histories in a way that allows a seamless history query, though at some performance cost. The good news is that these history queries across the shard boundary may be common at first, but become less common as time goes on.
The first step to combining the two shards together is to have a local clone of each. In the new shard, add the object store of the old repository as a Git alternate. Add the full path to the .git/objects directory of the old repository into the .git/objects/info/alternates file in the new repository. While this file exists, it allows Git processes in the new repository to see the objects in the old one.
The second step is to use git replace to create a reference that tells Git to swap the contents of the new root commit with the tip of the old repository. Since those commits share the same root tree, the only change will be the message and commit parents at that point. This allows walking “through” the link into the previous commit history.
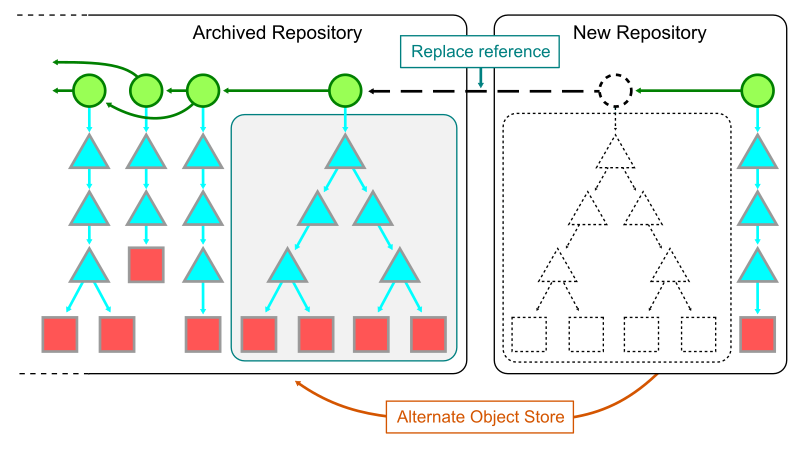
It is important to note that operating with replace objects enabled comes at some performance cost. In addition to having the large commit history that existed before the split, some features like the commit-graph file discussed in part II are not compatible with replace objects. For this reason, operating in this combined mode should only be done when it is critical to do history queries across the shard boundary.
One way to guarantee that the combined history is quickly available, but does not affect normal Git operations is to “hide” the replace references using the GIT_REPLACE_REF_BASE environment variable. This writes the replace reference in a non-standard location, so the replacement is only effective when that environment variable is set to your custom value.
Using replace references to view a combined form of the history can also help transition ongoing work from the old repository to the new one. While in the combined mode, users can use git rebase to move their topics from the old history to the new history. They no longer need to use the git format-patch and git am transformation.
Here is a concrete example for how I created a time-based shard of the Git repository starting at the v2.37.0 tag:
$ git init
$ echo /home/stolee/_git/git/src/.git/objects >.git/objects/info/alternates
$ git commit-tree -m "new root commit" \
-m "Sharded from e4a4b31577c7419497ac30cebe30d755b97752c5" \
-m "Signed-off-by: Derrick Stolee <derrickstolee@github.com>" \
a4a2aa60ab45e767b52a26fc80a0a576aef2a010
b49d35c8288501462ca1a008b3bb2efb9b4c4a9d
$ GIT_REPLACE_REF_BASE=refs/shard git replace \
b49d35c8288501462ca1a008b3bb2efb9b4c4a9d \
e4a4b31577c7419497ac30cebe30d755b97752c5
$ git log --oneline
b49d35c828 (HEAD -> master) new root commit
$ GIT_REPLACE_REF_BASE=refs/shard git log --oneline -n 5
b49d35c828 (HEAD -> master, replaced) Git 2.37
49c837424a Merge branch 'jc/revert-show-parent-info'
5dba4d6540 Merge tag 'l10n-2.37.0-rnd1' of https://github.com/git-l10n/git-po
fc0f8bcd64 revert: config documentation fixes
71e3a31e40 l10n: sv.po: Update Swedish translation (5367t0f0u)
You can follow the instructions in the sharded repository to experience cloning the two repositories and using the combined history as needed.
Time-based shards can be successful in reducing several dimensions of scale that cause friction in a large monorepo. However, the hurdle of transitioning work to a new repository location may be too disruptive for your group. There is one final sharding strategy I’ll discuss today, and it keeps the logistical structure of the monorepo in a single location while still improving how client repositories interact with the remote repository.
Data offloading
When a database grows, it may be beneficial to recognize that some data elements are infrequently accessed and to move that data to less expensive, but also lower performance storage mechanisms. It is possible to do this with Git repositories as well!
It is possible to think about partial clone as a way to offload data to secondary storage. A blobless clone (created by git clone --filter=blob:none) downloads the full commit history and all reachable trees from the origin server, but only downloads blob contents when necessary. In this way, the initial clone can be much faster and the amount of local storage greatly reduced. This comes at a cost that when Git needs a blob to satisfy a git checkout or git blame query, Git needs to communicate across the network to get that information. Frequently, that network hop requires going great distances across the internet and not just a local area network.
This idea of offloading data to secondary storage can work even better if there is a full clone of the remote repository available to add as an alternate. Perhaps the repository lives on a network fileshare that is accessible on the local network. Perhaps your IT department sets up new machines with a hard-disk drive containing a static copy of the repository from certain points in time. In either case, a blobless partial clone can add that static repository as an alternate, providing a faster lookup location for the blobs that do not exist in the local object store.
One major benefit of this kind of setup is that most custom query indexes, such as the commit-graph and changed-path Bloom filters, work automatically in this environment. This can be a great way to bootstrap local clones while minimizing the effect of missing blobs in a partial clone.
However, the current organization only helps at clone time. All fetches and future operations still grow the local repository size at the same rate, without ever reducing the size of the repository.
It is possible to take this idea of data offloading and use it to move data out of your local repository and into secondary storage, freeing up your expensive-but-fast storage for cheap-but-slower storage.
The key idea is again to use Git alternates, and create an alternate that points to some area of secondary storage. The second step is to discover objects in the repository history that are infrequently used, then copy them to that alternate and delete them from the local copy.
To decide what is an “infrequently used” object, we can use the commit history. The commits themselves are cheap and used for many commit history queries, so always keep those in the local storage. Similarly, keep each root tree. Also, objects reachable from recent root trees should be kept locally. (Feel free to be flexible to what you think “recent” means.)
After we know that we care about these objects, there are many ways we can decide what else should be kept. We could have a hard cutoff where we only keep root trees and no other objects older than that cutoff. We could also taper off the object list by first moving the blobs older than the cutoff, then slowly removing trees at certain depths, keeping fewer and fewer trees as the history gets older and older. There are a lot of possibilities to explore in this space.
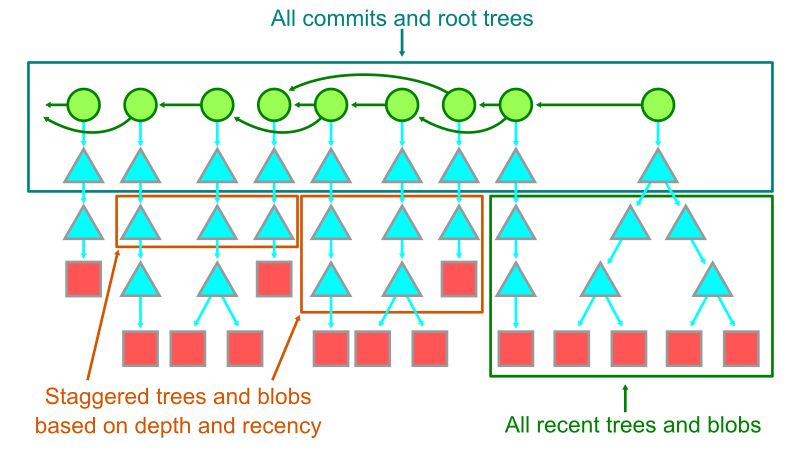
I don’t know of any existing tool that does this kind of secondary storage offloading based on recency, but I think it could be really useful for some of these large monorepos. If this is something you think would work for your team, then try building it yourself tailored to your specific needs. Just promise that you’ll tell me if you do, because I want to see it!
Let’s keep the conversation going!
Thank you for reading this blog series! I had a lot of fun writing it and thinking about these advanced Git features and some potential extensions.
This may be the end of my prepared writing, but I will keep thinking of Git like a database for a very long time. If you have additional ideas to share, then please ping me on Twitter so we can keep the conversation going. I’ll also be speaking at Git Merge 2022 covering all five parts of this blog series, so I look forward to seeing you there!
Tags:
Written by

Related posts
Don’t stop early: Case-folding source code at memory speed
How a branch-free loop and byte-space arithmetic let GitHub case-fold every byte of code search at >45 GiB/s on a single core.

$100 million for open source: A milestone built by the community
Celebrating $100 million contributed by the community to the people who build and sustain open source every day.
6 security settings every GitHub maintainer should enable this week
These six free settings will not make your project unhackable. Nothing will. What they will do is close the easy doors. Turn these on, and your project will be meaningfully harder to attack than it was before.