Code scanning finds more vulnerabilities using machine learning
Today we launched new code scanning analysis features powered by machine learning. The experimental analysis finds more of the most common types of vulnerabilities.
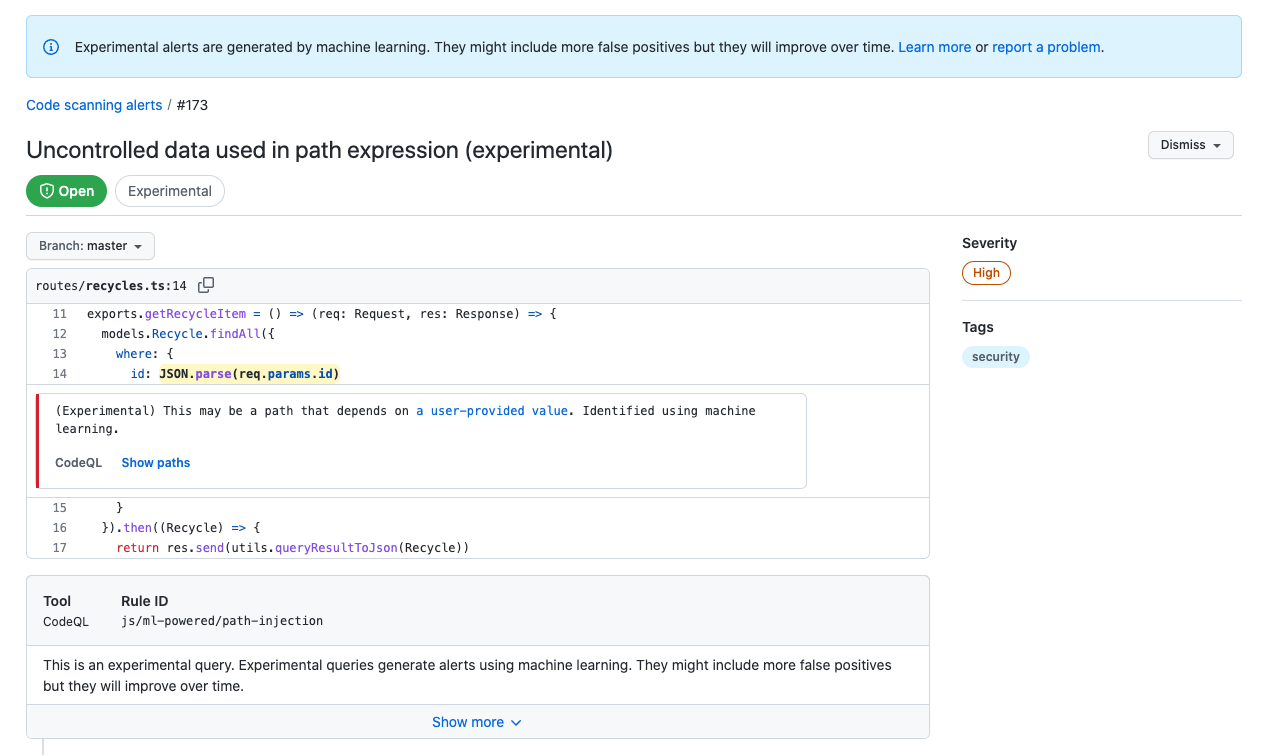
Code scanning is now able to find more potential security vulnerabilities by harnessing a new deep learning model. This experimental feature is available in public beta for JavaScript and TypeScript repositories on GitHub.com. With the new analysis capabilities, code scanning can surface even more alerts for four common vulnerability patterns: cross-site scripting (XSS), path injection, NoSQL injection, and SQL injection. Together, these four vulnerability types account for many of the recent vulnerabilities (CVEs) in the JavaScript/TypeScript ecosystem, and improving code scanning’s ability to detect such vulnerabilities early in the development process is key in helping developers write more secure code.
Why use machine learning to generate better results?
GitHub code scanning is powered by the CodeQL analysis engine. To identify potential security vulnerabilities, you can enable CodeQL to run queries against your codebase. These open source queries are written by members of the community and GitHub security experts, and each query is carefully crafted to recognize as many variants of a particular vulnerability type as possible and provide broad Common Weakness Enumeration (CWE) coverage. Queries are continuously updated to recognize emerging libraries and frameworks. Identifying such libraries is important: it allows us to accurately identify flows of untrusted user data, which are often the root cause of security vulnerabilities.
With the rapid evolution of the open source ecosystem, there is an ever-growing long tail of libraries that are less commonly used. We use examples surfaced by the manually-crafted CodeQL queries to train deep learning models to recognize such open source libraries, as well as in-house developed closed-source libraries. Using these models, CodeQL can identify more flows of untrusted user data, and therefore more potential security vulnerabilities.
Want to learn about the machine learning framework powering these alerts? Check out this post, which describes how we trained our deep learning models.
How do I enable the new experimental analysis?
The new experimental JavaScript and TypeScript analysis is rolled out to all users of code scanning’s security-extended and security-and-quality analysis suites. If you’re already using one of these suites, your code will be analyzed using the new machine learning technology.
If you’re already using code scanning, but not using either of these suites yet, you can enable the new experimental analysis by modifying your code scanning Actions workflow configuration file as follows:
[...]
- uses: github/codeql-action/init@v1
with:
queries: +security-extended
[...]
If you’re new to code scanning, please follow these instructions to configure the analysis for your JavaScript/TypeScript code. During the setup process, you can configure the security-extended or security-and-quality analysis suites described above.
Where do new alerts appear?
If the new experimental analysis finds additional results, you will see the new alerts displayed alongside the other code scanning alerts in the “Security” tab of your repository. They will also appear on pull requests. The new alerts are clearly marked with the “Experimental” label.
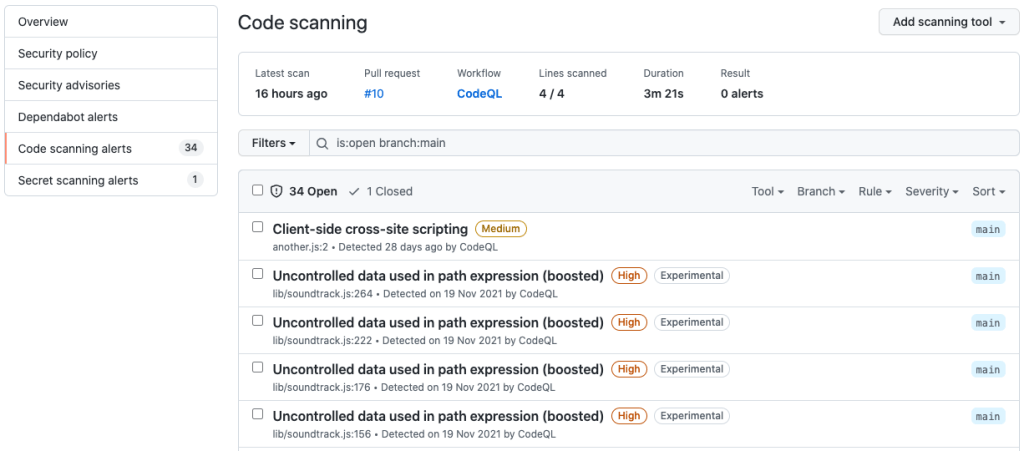
It’s important to note that while we continue to improve and test our machine learning models, this new experimental analysis can have a higher false-positive rate relative to results from our standard CodeQL analysis. As with most machine learning models, the results will improve over time. We encourage everyone to try out this new experimental feature; with your feedback we can continue to innovate and secure the world’s code!
Tags:


Related posts
Take your local GitHub sessions anywhere
Kick off work in VS Code or the CLI, finish it from your phone. Remote control for GitHub Copilot sessions is now generally available on github.com and GitHub Mobile.

GitHub availability report: April 2026
In April, we experienced 10 incidents that resulted in degraded performance across GitHub services.
GitHub Copilot individual plans: Introducing flex allotments in Pro and Pro+, and a new Max plan
Starting June 1, our lineup of individual plans will update based on your feedback.