Introducing stack graphs
Precise code navigation is powered by stack graphs, a new open source framework that lets you define the name binding rules for a programming language.

Today, we announced the general availability of precise code navigation for all public and private Python repositories on GitHub.com. Precise code navigation is powered by stack graphs, a new open source framework we’ve created that lets you define the name binding rules for a programming language using a declarative, domain-specific language (DSL). With stack graphs, we can generate code navigation data for a repository without requiring any configuration from the repository owner, and without tapping into a build process or other CI job. In this post, I’ll dig into how stack graphs work, and how they achieve these results.
(This post is a condensed version of a talk that I gave at Strange Loop in October 2021. Please check out the video of that talk if you’d like to learn even more!)
What is code navigation?
Code navigation is a family of features that let you explore the relationships in your code and its dependencies at a deep level. The most basic code navigation features are “jump to definition” and “find all references.” Both build on the fact that names are pervasive in the code that we write. Programming languages let us define things — functions, classes, modules, methods, variables, and more. Those things have names so that we can refer back to them in other parts of our code.
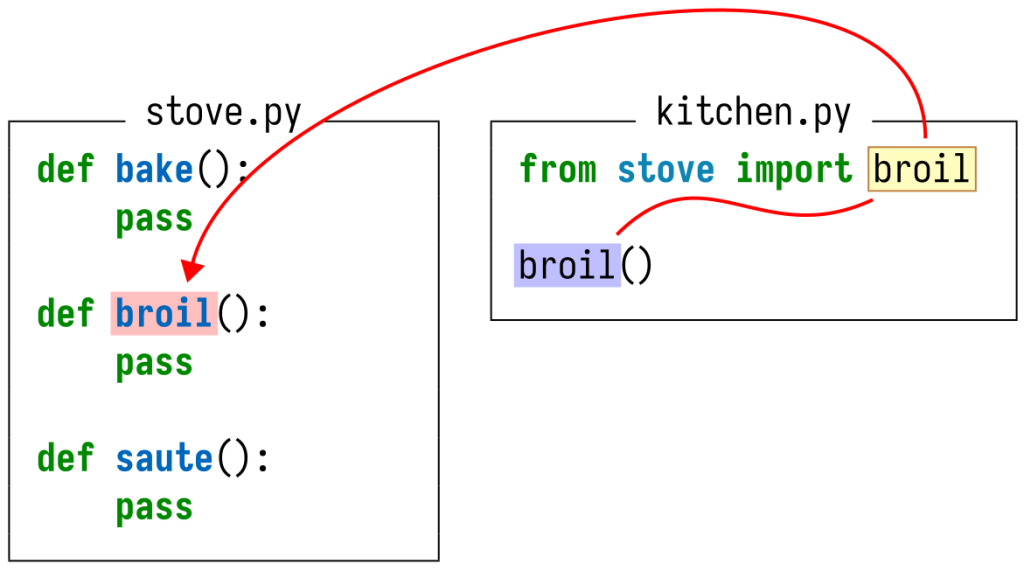
A picture (even a simple one) is worth a thousand words:

In this Python module, the reference to broil at the end of the file refers to the function definition earlier in the file. (Throughout this post, I’ll highlight definitions in red and references in blue.)
Our goal, then, is to collect information about the lists of definitions and references, and to be able to determine which definitions each reference maps to, for all of the code hosted on GitHub.
Why is this hard?
In the above example, the definition and reference were close to each other, and it was easy to visually see the relationship between them. But it won’t always be that easy!

For instance, what if there are multiple definitions with the same name? In Python, names can shadow each other, which means that the broil reference should refer to the latter of the two definitions.
But these rules are language-specific! In Rust, top-level definitions are not allowed to shadow each other, but local variables are. So, this transliteration of my example from Python to Rust is an error according to the Rust language spec. If we were writing a Rust compiler, we would want to surface this error for the programmer to fix. But what about for an exploration feature like code navigation? We might want to show some result even for erroneous code. We’re only human, after all!

Up to now, I’ve only shown you examples consisting of a single file. But when was the last time you worked on a software project consisting of a single file? It’s much more likely that your code will be split across multiple files, multiple packages, and multiple repositories. Programming languages give us the ability to refer to definitions that might be quite far away. But as you might expect, the rules for how you refer to things in other files are different for different languages.
In the above example, I’ve split everything up into three files living in two separate packages or repositories. (I’m using emoji to represent the package names.) In Python, import statements let us refer to names defined in other modules, and the name of a module is determined by the name of the file containing its code. Together, this lets us see that the broil reference in chef.py in the “chef” package refers to the broil definition in stove.py in the “frying pan” package.

Code changes and evolves over time. What happens when one of your dependencies changes the implementation of a function that you’re calling? Here, the maintainers of the “frying pan” package have added some logging to the broil function. As a result, the broil reference in chef.py now refers to a different definition. Insidiously, it was an intermediate file that changed — not the file containing the reference, nor the file containing the original definition! If we’re not careful, we’ll have to reanalyze every file in the repository, and in all its dependencies, whenever any file changes! This makes the amount of work we must do quadratic in the number of changed files, rather than linear, which is especially problematic at GitHub’s scale.
Our last difficulty is one of scale. As mentioned above, we want to provide this feature for all of the code hosted on GitHub. Moreover, we don’t want to require any manual configuration on the part of each repository owner. You shouldn’t have to figure out how to produce code navigation data for your language and project, or have to configure a CI build to generate that data. Code navigation should Just Work.
At GitHub’s scale, this poses two problems. The first is the sheer amount of code that comes in every minute of every day. In each commit that we receive, it’s very likely that only a small number of files have been modified. We must be able to rely on incremental processing and storage, reusing the results that we’ve already calculated and saved for the files that haven’t changed.
The second challenge is the number of programming languages that we need to (eventually) support. GitHub hosts code written in every programming language imaginable. Git itself doesn’t care what language you use for your project — to Git, everything is just bytes. But for a feature like code navigation, where the name binding rules are different for each language, we must know how to parse and interpret the content of those files. To support this at scale, it must be as easy as possible for GitHub engineers and external language communities to describe the name binding rules for a language.
To summarize:
- Different languages have different name binding rules.
- Some of those rules can be quite complex.
- The result might depend on intermediate files.
- We don’t want to require manual per-repository configuration.
- We need incremental processing to handle our scale.
Stack graphs
After examining the problem space, we created stack graphs to tackle these challenges, based on the scope graphs framework from Eelco Visser’s research group at TU Delft. Below I’ll discuss what stack graphs are and how they work.
Because we must rely on incremental results, it’s important that at index time (that is, when we receive pushes containing new commits), we look at each file completely in isolation. Our goal is to extract “facts” about each file that describe the definitions and references in the file, and all possible things that each reference could resolve to.
For instance, consider this example:
Our final result must be able to encode the fact that the broil reference and definition live in different files. But to be incremental, our analysis must look at each file separately. I’m going to step into each file to show you what information GitHub can extract in isolation.

Looking first at stove.py, we can see that it contains a definition of broil. From the name of the file, we know that this definition lives in a module called stove, giving a fully qualified name of stove.broil. We can create a graph structure representing this fact (along with information about the other symbols in the file). Each definition (including the module itself) gets a red, double-bordered definition node. The other nodes, and the pattern of how we’ve connected these nodes with edges, define the scoping and shadowing rules for these symbols. For other programming languages, which don’t implement the same shadowing behavior as Python, we’d use a different pattern of edges to connect everything.

We can do the same thing for kitchen.py. The broil reference is represented by a blue, single-bordered reference node. The import statement also appears in the graph, as a gadget of nodes involving the broil and stove symbols.
Because we are looking at this file in isolation, we don’t yet know what the broil reference resolves to. The import statement means that it might resolve to stove.broil, defined in some other file — but that depends on whether there is a file defining that symbol. This example does in fact contain such a file (we just looked at it!), but we must ignore that while extracting incremental facts about kitchen.py.
At query time, however, we’re able to bring together the data from all files in the commit that you’re looking at. We can load the graphs for each of the files, producing a single “merged” graph for the entire commit:

Within this merged graph, every valid name binding is represented by a path from a reference node to a definition node.
However, not every path in the graph represents a valid name binding! For instance, looking only at the graph structure, there are perfectly fine paths from the broil reference node to the saute and bake definition nodes. To rule out those paths, we also maintain a symbol stack while searching for paths. Each blue node pushes a symbol onto the stack, and each red node pops a symbol from the stack. Importantly, we are not allowed to move into a “pop” node if its symbol does not match the top of the stack.
We’ve shown the contents of the symbol stack at a handful of places in the path that’s highlighted above. Most importantly, when we reach the portion of the graph containing the saute, broil, and bake definition nodes, the symbol stack contains ⟨broil⟩, ensuring that the only valid path that we discover is the one that ends at the broil definition.
We can also use different graph structures to handle my other examples. For example:
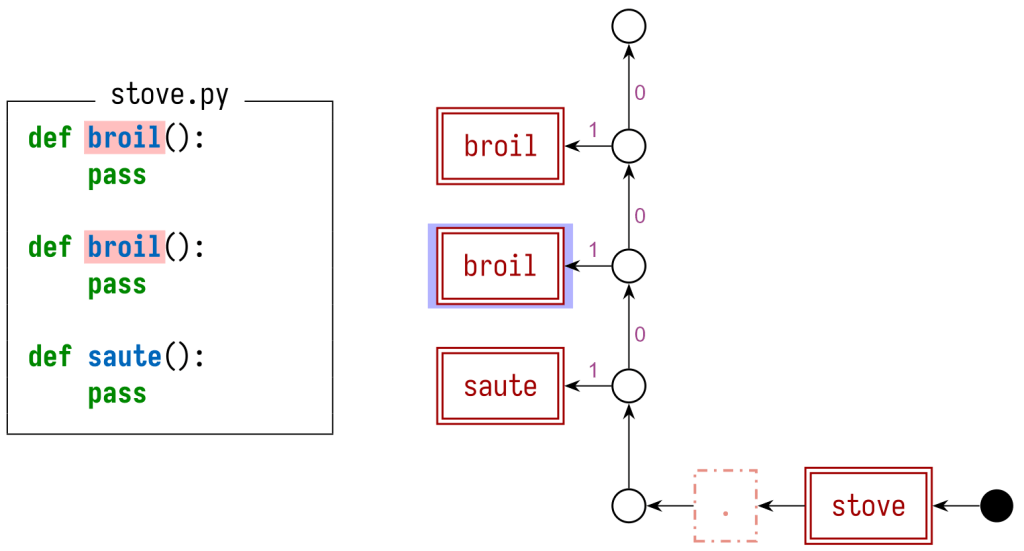
In this graph, we annotate some of the graph edges with a precedence value. Paths that include edges with a higher precedence value are preferred over those with lower precedences. This lets us correctly handle Python’s shadowing behavior.
For other programming languages, which don’t implement the same shadowing behavior as Python, we’d use a different pattern of edges to connect everything. For instance, the stack graph for my Rust example from earlier would be:

To model Rust’s rule that top-level definitions with the same name are conflicts, we have a single node that all definitions hang off of. We can use precedences to choose whether to show all conflicting definitions (by giving them all the same precedence value), or just the first one (by assigning precedences sequentially).
With a stack graph available to us, we can implement “jump to definition:”
- The user clicks on a reference.
- We load in the stack graphs for each file in the commit, and merge them
together. - We perform a path-finding search starting from the reference node
corresponding to the symbol that the user clicked on, considering
symbol stacks and precedences to ensure that we don’t create any invalid
paths. - Any valid paths that we find represent the definitions that the reference
refers to. We display those in a hover card.
Creating stack graphs using Tree-sitter
I’ve described how to use stack graphs to perform code navigation lookups, but I haven’t mentioned how to create stack graphs from the source code that you push to GitHub.
For that, we turned to Tree-sitter, an open source parsing framework. The Tree-sitter community has already written parsers for a wide variety of programming languages, and we already use Tree-sitter in many places across GitHub. This makes it a natural choice to build stack graphs on.
Tree-sitter’s parsers already let us efficiently parse the code that our users upload. For instance, the Tree-sitter parser for Python produces a concrete syntax tree (CST) for our stove.py example file:
$ tree-sitter parse stove.py
(module [0, 0] - [10, 0]
(function_definition [0, 0] - [1, 8]
name: (identifier [0, 4] - [0, 8])
parameters: (parameters [0, 8] - [0, 10])
body: (block [1, 4] - [1, 8]
(pass_statement [1, 4] - [1, 8])))
(function_definition [3, 0] - [4, 8]
name: (identifier [3, 4] - [3, 9])
parameters: (parameters [3, 9] - [3, 11])
body: (block [4, 4] - [4, 8]
(pass_statement [4, 4] - [4, 8])))
(function_definition [6, 0] - [7, 8]
name: (identifier [6, 4] - [6, 9])
parameters: (parameters [6, 9] - [6, 11])
body: (block [7, 4] - [7, 8]
(pass_statement [7, 4] - [7, 8]))))
Tree-sitter also provides a query language that lets us look for patterns within the CST:
(function_definition
name: (identifier) @name) @function
This query would locate all three of our example method definitions, annotating each definition as a whole with a @function label and the name of each method with a @name label.
As part of developing stack graphs, we’ve added a new graph construction language to Tree-sitter, which lets you construct arbitrary graph structures (including but not limited to stack graphs) from parsed CSTs. You use stanzas to define the gadget of graph nodes and edges that should be created for each occurrence of a Tree-sitter query, and how the newly created nodes and edges should connect to graph content that you’ve already created elsewhere. For instance, the following snippet would create the stack graph definition node for my example Python method definitions:
(function_definition
name: (identifier) @name) @function
{
node @function.def
attr (@function.def) kind = "definition"
attr (@function.def) symbol = @name
edge @function.containing_scope -> @function.def
}
This approach lets us create stack graphs incrementally for each source file that we receive, while only having to analyze the source code content, and without having to invoke any language-specific tooling or build systems. (The only language-specific part is the set of graph construction rules for that language!)
But wait, there’s more!
This post is already quite long, and I’ve only scratched the surface. You might be wondering:
- Performing a full path-finding search for every “jump to definition” query seems wasteful. Can we precalculate more information at index time while still being incremental?
-
All the examples we’ve shown are pretty trivial. Can we handle more complex examples?
For instance, how about the following Python file, where we need to use dataflow to trace what particular value was passed in as a parameter to
passthroughto correctly resolve the reference tooneon the final line?def passthrough(x): return x class A: one = 1 passthrough(A).oneOr the following Java file, where we have to trace inheritance and generic type parameters to see that the reference to
lengthshould resolve toString.lengthfrom the Java standard library?import java.util.HashMap; class MyMap extends HashMap<String, String> { int firstLength() { return this.entrySet().iterator().next().getKey().length(); } } - Why aren’t we using the Language Server Protocol (LSP) or Language Server Index Format (LSIF)?
To dig even deeper and learn more, I encourage you to check out my Strange Loop talk and the stack-graphs crate: our open source Rust implementation of these ideas. And in the meantime, keep navigating!
Tags:
Written by

Related posts

$100 million for open source: A milestone built by the community
Celebrating $100 million contributed by the community to the people who build and sustain open source every day.
6 security settings every GitHub maintainer should enable this week
These six free settings will not make your project unhackable. Nothing will. What they will do is close the easy doors. Turn these on, and your project will be meaningfully harder to attack than it was before.
How GitHub maintains compliance for open source dependencies
Explore how the Open Source Program Office uses GitHub’s new license compliance product to manage open source dependencies at scale.