Crafting a better, faster code view
The new GitHub Code View brings users many new features to improve the code reading and exploration experiences, and we overcame a number of unique technical hurdles in order to deliver those features without compromising performance.

Reading code is not as simple as reading the text of a file end-to-end. It is a non-linear, sometimes chaotic process of jumping between files to follow a trail, building a mental picture of how code relates to its surrounding context. GitHub’s mission is to be the home for all developers, and reading code is one of the core experiences we offer. Every day, millions of users use GitHub to view and interact with code. So, about a year ago we set out to create a new code view that supports the entire code reading experience with features like a file tree, symbol navigation, code search integration, sticky lines, and code section folding. The new code view is powerful, intelligent, and interactive, but it is not an attempt to turn the repository browsing experience into an IDE.
While building the new code view, our team had a few guiding principles on which we refused to compromise:
- It must add these powerful new features to transform how users read code on GitHub.
- It must be intuitive and easy to use for all of GitHub’s millions of users.
- It must be fast.
Initial efforts
The first step was to build out the features we wanted in a natural, straightforward way, taking the advice that “premature optimization is the root of all evil.”1 After all, if simple code satisfactorily solves our problems, then we should stop there. We knew we wanted to build a highly interactive and stateful code viewing experience, so we decided to use React to enable us to iterate more quickly on the user interface. Our initial implementation for the code blob was dead-simple: our syntax highlighting service converted the raw file contents to a list of HTML strings corresponding to the lines of the file, and each of these lines was added to the document.
There was one key problem: our performance scaled badly with the number of lines in the file. In particular, our LCP and TTI times measurably increased at around 500 lines, and this increase became noticeable at around 2,000 lines. Around those same thresholds, interactions like highlighting a line or collapsing a code section became similarly sluggish. We take these performance metrics seriously for a number of reasons. Most importantly, they are user-centric—that is, they are meant to measure aspects of the quality of a user’s experience on the page. On top of that, they are also part of how search engines like Google determine where to rank pages in their search results; fast pages get shown first, and the code view is one of the many ways GitHub’s users can show their work to the world.
As we dug in, we discovered that there were a few things at play:
- When there are many DOM nodes on the page, style calculations and paints take longer.
- When there are many DOM nodes on the page, DOM queries take longer, and the results can have a significant memory footprint.
- When there are many React nodes on the page, renders and DOM reconciliation both take longer.
It’s worth noting that none of these are problems with React specifically; any page with a very large DOM would experience the first two problems, and any solution where a large DOM is created and managed by JavaScript would experience the third.
We mitigated these problems considerably by ensuring that we were not running these expensive operations more than necessary. Typical React optimization techniques like memoization and debouncing user input, as well as some less common solutions like pulling in an observer pattern went a long way toward ensuring that React state updates, and therefore DOM updates, only occurred as needed.
Mitigating the problem, however, is not solving the problem. Even with all of these optimizations in place, the initial render of the page remained a fundamentally expensive operation for large files. In the repository that builds GitHub.com, for example, we have a CODEOWNERS file that is about 18,000 lines long, and pushes the 2MB size limit for displaying files in the UI. With no optimizations besides the ones described above, React’s first pass at building the DOM for this page takes nearly 27 seconds.2 Considering more than half of users will abandon a page if it loads for more than three seconds, there was obviously lots of work left to do.
A promising but incomplete solution
Enter virtualization. Virtualization is a performance optimization technique that examines the scroll state of the page to determine what content to include in the DOM. For example, if we are viewing a 10,000 line file but only about 75 lines fit on the screen at a time, we can save lots of time by only rendering the lines that fit in the viewport. As the user scrolls, we add any lines that need to appear, and remove any lines that can disappear, as illustrated by this demo.3
This satisfies the most basic requirements of the page with flying colors. It loads on average more quickly than the existing experience, and the experience of scrolling through the file is nearly indistinguishable from the non-virtualized case. Remember that 27 second initial render? Virtualizing the file content gets that time down to under a second, and that number does not increase substantially even if we artificially remove our file size limit and pull in hundreds of megabytes of text.
Unfortunately, virtualization is not a cure-all. While our initial implementation added features to the page at the expense of performance, naïvely virtualizing the code lines delivers a fast experience at the expense of vital functionality. The biggest problem was that without the entire text of the file on the page at once, the browser’s built-in find-in-file only surfaced results that are visible in the viewport. Breaking users’ ability to find text on the page breaks our hard requirement that the page remain intuitive and easy to use. Before we could ship any of this to real users, we had to ensure that this use case would be covered.
The immediate solution was to implement our own version of find-in-file by implementing a custom handler for the Ctrl+F shortcut (⌘+F on Mac). We added a new piece of UI in the sidebar to show results as part of our integration with symbol navigation and code search.
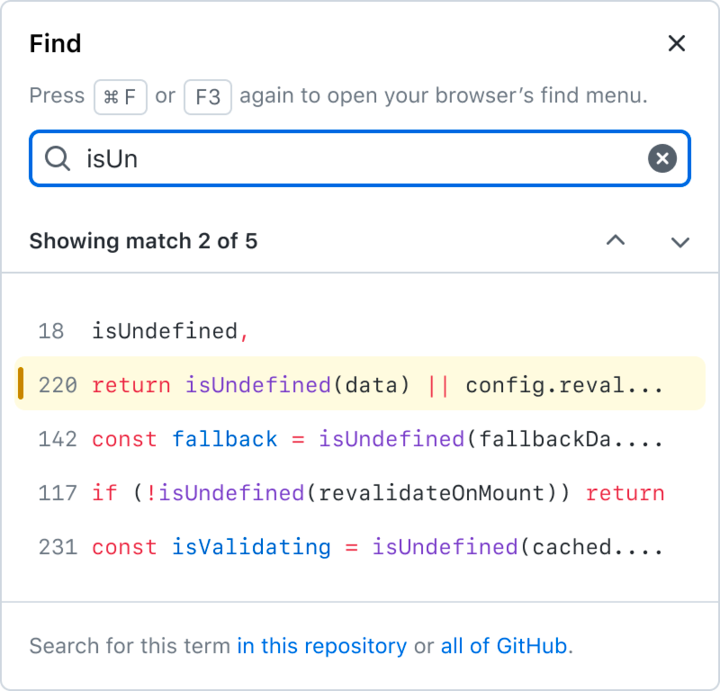
There is precedent for overriding this native browser feature to allow users to find text in virtualized code lines. Monaco, the text editor behind VS Code, does exactly this to solve the same problem, as do many other online code editors, including Repl.it and CodePen. Some other editors like the official Ruby playground ignore the problem altogether and accept that Ctrl+F will be partially broken within their virtualized editor.
At the time, we felt confident leaning on this precedent. These examples are applications that run in a browser window, and as users, we expect applications to implement their own controls. Writing our own way to find text on the page was a step toward making GitHub’s Code View less of a web page and more of a web application.
When we released the new code view experience as a private beta at GitHub Universe, we received clear feedback that our users think of GitHub as a page, not as an app. We tried to rework the experience to be as similar as possible to the native implementation, both in terms of user experience and performance. But ultimately, there are plenty of good reasons not to override this kind of native browser behavior.
- Users of assistive technologies often use Ctrl+F to locate elements on a page, so restricting the scope to the contents of the file broke these workflows.
- Users rely heavily on specific muscle memory for common actions, and we followed a deep rabbit hole to get the custom control to support all of the shortcuts used by various browsers.
- Finally, the native browser implementation is simply faster.
Despite plenty of precedent for an overridden find experience, this user feedback drove us to dig deeper into how we could lean on the browser for something it already does well.
Virtualization has an important role to play in our final product, but it is only one piece of the puzzle.
How the pieces fit together
Our complete solution for the code view features two pieces:
- A textarea that contains the entire text of the raw file. The contents are accessible, keyboard-navigable, copyable, and findable, yet invisible.
- A virtualized, syntax-highlighted overlay. The contents are visible, yet hidden from both mouse events and the browser’s find.
Together, these pieces deliver a code view that supports the complete code reading experience with many new features. Despite the added complexity, this new experience is faster to render than the static HTML page that has displayed code on GitHub for more than a decade.
A textarea and a read-only cursor
The first half of this solution came to us from an unexpected angle.
Beyond adding functionality to the code view, we wanted to improve the code reading experience for users of assistive technologies like screen readers. The previous code view was minimally accessible; a code document was displayed as a table, which created a very surprising experience for screen reader users. A code document is not a table, but likewise it is not a paragraph of text. To support a familiar interface for interacting with the code on the page, we added an invisible textarea underneath the virtualized, syntax-highlighted code lines so that users can move through the code with the keyboard in a familiar way. And for the browser, rendering a textarea is much simpler than using JavaScript to insert syntax-highlighted HTML. Browsers can render megabytes of text in a textarea with ease.
Since this textarea contains the entire text of the raw file, it is not just an accessibility feature, but an opportunity to remove our custom implementation of Ctrl+F in favor of native browser implementations.
Hiding text from Ctrl+F
With the addition of the textarea, we now have two copies of every line that is visible in the viewport: one in the textarea, and another in the virtualized, syntax-highlighted overlay. In this state, searching for text yields duplicated results, which is more confusing than a slow or unfamiliar experience.
The question, then, is how to expose only one copy of the text to the browser’s native Ctrl+F. That brings us to the next key part of our solution: how we hid the syntax-highlighted overlay from find.
For a code snippet like this line of Python:
print("Hello!")
the old code view created a bit of HTML that looks like this:
<span class="pl-en">print</span>(<span class="pl-s">"Hello!"</span>)
But the text nodes containing print, (,"Hello!", and ) are all findable. It took two iterations to arrive at a format that looks identical but is consistently hidden fromCtrl+F on all major browsers. And as it turns out, this is not a question that is very easy to research!
The first approach we tried relied on the fact that :before pseudoelements are not part of the DOM, and therefore do not appear in find results. With a bit of a change to our HTML format that moves all text into a data- attribute, we can use CSS to inject the code text into the page without any findable text nodes.
HTML
<span class="pl-en" data-code-text="print"></span>
<span data-code-text="("></span>
<span class="pl-s" data-code-text=""Hello!""></span>
<span data-code-text=")"></span>
CSS
[data-code-text]:before {
content: attr(data-code-text);
}
But that’s not the end of the story, because the major browsers do not agree on whether text in :before pseudoelements should be findable; Firefox in particular has a powerful Ctrl+F implementation that is not fooled by our first trick.
Our second attempt relied on a fact on which all browsers seem to agree: that text in adjacent pseudoelements is not treated as a contiguous block of text.4 So, even though Firefox would find print in the first example, it would not find print(. The solution, then, is to break up the text character-by-character:
<span class="pl-en">
<span data-code-text="p"></span>
<span data-code-text="r"></span>
<span data-code-text="i"></span>
<span data-code-text="n"></span>
<span data-code-text="t"></span>
</span>
<span data-code-text="("></span>
<span class="pl-s">
<span data-code-text="""></span>
<span data-code-text="H"></span>
<span data-code-text="e"></span>
<span data-code-text="l"></span>
<span data-code-text="l"></span>
<span data-code-text="o"></span>
<span data-code-text="!"></span>
<span data-code-text="""></span>
</span>
<span data-code-text=")"></span>
At first glance, this might seem to complicate the DOM so much that it might outweigh the performance gains for which we worked so hard. But since these lines are virtualized, we create this overlay for at most a few hundred lines at a time.
Syntax highlighting in a compact format
The path we took to build a faster code view with more features was, like the path one might follow when reading code in a new repository, highly non-linear. Performance optimizations led us to fix behaviors which were not quite right, and those behavior fixes led us to need further performance optimizations. Knowing how we wanted the HTML for the syntax-highlighted overlay to look, we had a few options for how to make it happen. After a number of experiments, we completed our puzzle with a performance optimization that ended this cycle without causing any behavior changes.
Our syntax-highlighting service previously gave us a list of HTML strings, one for each line of code:
[
"<span class=\"pl-en\">print</span>(<span class=\"pl-s\">"Hello!"</span>)"
]
In order to display code in a different format, we introduced a new format that simply gives the locations and css classes of highlighted segments:
[
[
{"start": 0, "end": 5, "cssClass": "pl-en"},
{"start": 6, "end": 14, "cssClass": "pl-s"}
]
]
From here, we can easily generate whatever HTML we want. And that brings us to our final optimization:
within our syntax-highlighted overlay, we save React the trouble of managing the code lines by generating the HTML strings ourselves. This can deliver a surprisingly large performance boost in certain cases, like scrolling all the way through the 18,000-line CODEOWNERS file mentioned earlier. With React managing the entire DOM, we hit the “end” key to move all the way to the end of the file, and it takes the browser 870 milliseconds to finish handling the “keyup” event, followed by 3,700 milliseconds of JavaScript blocking the main thread. When we generate the code lines as HTML strings, handling the “keyup” event takes only 80 milliseconds, followed by about 700 milliseconds of blocking JavaScript.5
In summary
GitHub’s mission is to be the home for all developers. Developers spend a substantial amount of their time reading code, and reading code is hard! We spent the past year building a new code view that supports the entire code reading experience because we are passionate about bringing great tools to the developers of the world to make their lives a bit easier.
After a lot of difficult work, we have created a code view that introduces tons of new features for understanding code in context, and those features can be used by anyone. And we did it all while also making the page faster!
We’re proud of what we built, and we would love for everyone to try it out and send us feedback!
Notes
- This quote, popularized by and often attributed to Donald Knuth, was first said by Sir Tony Hoare, the developer of the quicksort algorithm. ↩
- All performance metrics generated for this post use a development build of React in order to better compare apples to apples. ↩
- Check out the source code for this virtualization demo here! ↩
- The fact that browsers do not treat adjacent :before elements as part of the same block of text also introduces another complication: it resets the tab stop location for each node, which means that tabs are not rendered with the correct width! We need the syntax-highlighted overlay to align exactly with the text content underneath because any discrepancy creates a highly confusing user experience. Luckily, since the overlay is neither findable nor copyable, we can modify it however we like. The tab width problem is solved neatly by converting tabs to the appropriate number of spaces in the overlay. ↩
- Although code on GitHub is often nested deeply, the syntax information for a line of code can still be described linearly much of the time—we have a keyword followed by some plain text and then a string literal, etc. But sometimes it is not so simple—we might have a Markdown document with a code section. That code section might be an HTML document with a script tag. That script tag might contain JavaScript. That JavaScript might contain doc comments on a function. Those doc comments might contain @param tags which are rendered as keywords. We can handle this kind of arbitrarily nested syntax tree with a recursive React component. But that means the shape of our tree of React nodes, and therefore the amount of time it takes to perform DOM reconciliation, is determined by the code our users have chosen to write. On top of that, React adds DOM nodes one-at-a-time, and our overlay uses one DOM node per character of code. These are the main reasons that sidestepping React for this part of the page gives us such a dramatic performance boost. ↩
Tags:
Written by

Related posts
Tame Dependabot: Group your updates, slow the cadence, keep security fast
Dependabot keeps your dependencies current, but its defaults can flood your repository with pull requests. Here’s how grouping updates, slowing the cadence, and keeping security fixes fast cut the noise on a Microsoft open source project.

The cost of saying yes has changed
The cost of writing code dropped; the cost of owning it didn’t. A framework for deciding which changes are actually cheap in the AI era.
Better tools made Copilot code review worse. Here’s how we actually improved it.
How migrating Copilot code review to shared Unix-style code exploration tools reduced review cost by reshaping agent workflows around pull request evidence.