Git 2.5, including multiple worktrees and triangular workflows
The open source Git project has just released Git 2.5. Here’s our take on its most useful new features. git worktree: one Git repository with multiple working trees It’s not…

The open source Git project has just released Git 2.5. Here’s our take on its most useful new features.
git worktree: one Git repository with multiple working trees
It’s not very difficult to switch a single Git repository between multiple branches, or to create a second local clone of a repository. This lets you work on two branches simultaneously, or start long-running tests in one clone while continuing development in the other. However, maintaining multiple clones of a repository means extra work to keep the clones in sync with each other and with any remote repositories.
The new Git subcommand git worktree creates additional working trees connected to an existing Git repository [1]. Each linked working tree is a pseudo-repository with its own checked-out working copy. Its .git is actually a file that refers to the history and references from the main repository.
Please note that the worktree feature is experimental. It may have some bugs, and its interface may change based on user feedback. It’s not recommended to use git worktree with a repository that contains submodules.
Suppose you’re working in a Git repository on a branch called feature, when a user reports a high-urgency bug in master. First you create a linked working tree with a new branch, hotfix, checked out relative to master, and switch to that directory:
$ git worktree add -b hotfix ../hotfix origin/master
Enter ../hotfix (identifier hotfix)
Branch hotfix set up to track remote branch master from origin.
Switched to a new branch 'hotfix'
$ cd ../hotfixNow you’ve got a new working tree, with branch hotfix checked out and ready to go. You can fix the bug, push hotfix, and create a pull request. After you’ve committed the changes to the hotfix branch, you can delete the hotfix directory whenever you like, because the commits are stored in your main repository:
$ cd ../main
$ rm -rf ../hotfixThe main repository and any associated linked working trees all know about each other, which keeps them from getting in each other’s way. For example, it’s not allowed to have the same branch checked out in two linked working trees at the same time, because that would allow changes committed in one working tree to bring the other one out of sync. So suppose that you want to run long-running tests on the current commit. Create a detached HEAD state, using the --detach option, to check out the current commit independent of the branch:
$ git worktree add --detach ../tests HEAD
Enter ../tests (identifier tests)
HEAD is now at 977212e... add file
$ cd ../tests
$ make super-long-test
[...]While the test is running, you can continue working in your main repository.
[1] You may have heard of an older script called contrib/workdir/git-new-workdir that does something similar. That script never made it to mainstream because it was non-portable and somewhat fiddly.
Improved support for triangular workflows
When contributing to open source projects, it’s common to use what’s called a “triangular workflow”:
- You fetch from a canonical “upstream” repository to keep your local repository up-to-date.
- When you want to share your own modifications with other people, you push them to your own fork and open a pull request.
- If your changes are accepted, the project maintainer merges them into the upstream repository.
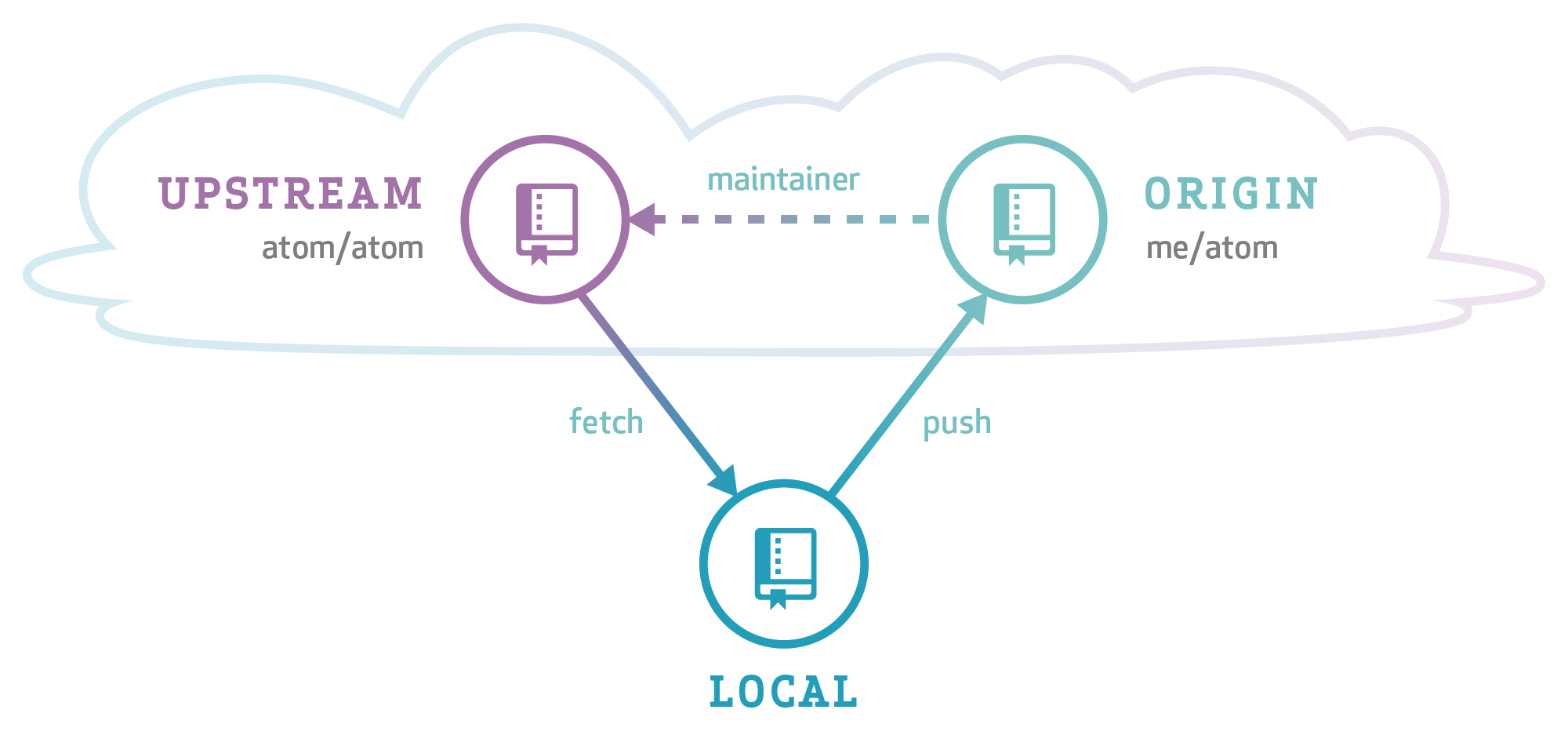
Git has many features that support triangular workflows, but it’s sometimes hard to see how to use them together in real life. Let’s take a closer look at triangular workflows, including the new command line shorthand <reference>@{push} that was added in Git 2.5.
Preparation
Suppose you want to contribute to the Atom editor. Although you likely don’t have push permission to the main Atom repository, you can fork that repo and push your changes to your own fork. Here’s how you set that up:
- Go to the main Atom repository and click “Fork”. This creates a new fork under your account with the URL
https://github.com/YOUR-USERNAME/atom. -
Create a local clone of your fork on your computer:
$ git clone https://github.com/YOUR-USERNAME/atom $ cd atom $ git config remote.pushdefault origin $ git config push.default currentAfter this step, the remote called
originrefers to your fork of Atom. It also sets the default remote for pushes to beoriginand the default push behavior tocurrent. Together this means that if you just typegit push, the current branch is pushed to theoriginremote. -
Create a second remote called
upstreamthat points at the mainatomrepository and fetch from it:$ git remote add upstream https://github.com/atom/atom $ git fetch upstream
Hacking
You only have to follow the above steps once. From then on, whenever you want to work on a new feature, you can more easily interact with the remote repositories:
-
Make sure that your local repository is up-to-date with the upstream repository:
$ git fetch upstream -
Create a branch
whizbangoff of upstreammasterto work on a new feature, and check out the branch:$ git checkout -b whizbang upstream/masterThis automatically sets up your local
whizbangbranch to track the upstreammasterbranch. This means that if more commits are added tomasterupstream, you can merge those commits into yourwhizbangbranch by typing$ git pullor rebase your branch on top of the new
masterby typing$ git pull --rebaseIf you’re ever unsure of the branch that would be pulled from, you can type
$ git rev-parse --abbrev-ref '@{u}' - Hack, commit, hack, commit.
-
Push your
whizbangbranch to your fork:$ git pushBecause of the above configuration, and because
whizbangis the current branch, the above command doesn’t need any arguments. - Continue to hack, commit, hack, commit.
-
See what commits you’ve added to your current branch since the last push:
$ git log @{push}..This uses the new
@{push}notation, which denotes the current value of the remote-tracking branch that the current branch would be pushed to bygit push, namelyorigin/whizbang. You can also refer to the push destination of an arbitrary branch using the notationwhizbang@{push}. -
Push the new commits to the
whizbangbranch on your GitHub fork:$ git pushIf you’re unsure of which branch would be pushed to, you can type
$ git push --dry-runor
$ git rev-parse --abbrev-ref '@{push}'
Performance improvements
Git 2.5 includes performance improvements aimed at large working trees and working trees stored on networked filesystems (e.g., NFS):
- You can run
git update-index --untracked-cacheto enable an experimental feature that tells Git to examine only the modification times of directories when looking for new files. This can speed upgit statuson many filesystems. -
git index-pack(run, for example, bygit gc) now makes far fewer scans of thepacked-refsdirectory. This can make a huge difference if the repository is on a networked filesystem. - Git now calls
utimefar less often when it’s about to reuse existing packed objects. This also mostly benefits repositories on networked filesystems.
Also, clean/smudge filters are no longer required to read all of their input. This can help speed up filters that don’t need to read the whole file contents to do their work (e.g., Git Large File Storage).
Go forth and collaborate
Of course there are many, many other changes in this release; for the full list, check out the 2.5.0 release notes.
We hope that you find something in Git 2.5 that makes your day just a little bit nicer. And the best part is that, through the magic of open source, Git just keeps getting better and better! If you’d like to get more involved in the Git open source community, come check out the community page.
Written by

Related posts
6 security settings every GitHub maintainer should enable this week
These six free settings will not make your project unhackable. Nothing will. What they will do is close the easy doors. Turn these on, and your project will be meaningfully harder to attack than it was before.
How GitHub maintains compliance for open source dependencies
Explore how the Open Source Program Office uses GitHub’s new license compliance product to manage open source dependencies at scale.

Highlights from Git 2.55
The open source Git project just released Git 2.55. Here is GitHub’s look at some of the most interesting features and changes introduced since last time.