Git 2.11 has been released
The open source Git project has just released Git 2.11.0, with features and bugfixes from over 70 contributors. Here’s our look at some of the most interesting new features: Abbreviated…

The open source Git project has just released Git 2.11.0, with features and bugfixes from over 70 contributors. Here’s our look at some of the most interesting new features:
Abbreviated SHA-1 names
Git 2.11 prints longer abbreviated SHA-1 names and has better tools for dealing with ambiguous short SHA-1s.
You’ve probably noticed that Git object identifiers are really long strings of hex digits, like 66c22ba6fbe0724ecce3d82611ff0ec5c2b0255f. They’re generated from the output of the SHA-1 hash function, which is always 160 bits, or 40 hexadecimal characters. Since the chance of any two SHA-1 names colliding is roughly the same as getting struck by lightning every year for the next eight years1, it’s generally not something to worry about.
You’ve probably also noticed that 40-digit names are inconvenient to look at, type, or even cut-and-paste. To make this easier, Git often abbreviates identifiers when it prints them (like 66c22ba), and you can feed the abbreviated names back to other git commands. Unfortunately, collisions in shorter names are much more likely. For a seven-character name, we’d expect to see collisions in a repository with only tens of thousands of objects2.
To deal with this, Git checks for collisions when abbreviating object names. It starts at a relatively low number of digits (seven by default), and keeps adding digits until the result names a unique object in the repository. Likewise, when you provide an abbreviated SHA-1, Git will confirm that it unambiguously identifies a single object.
So far, so good. Git has done this for ages. What’s the problem?
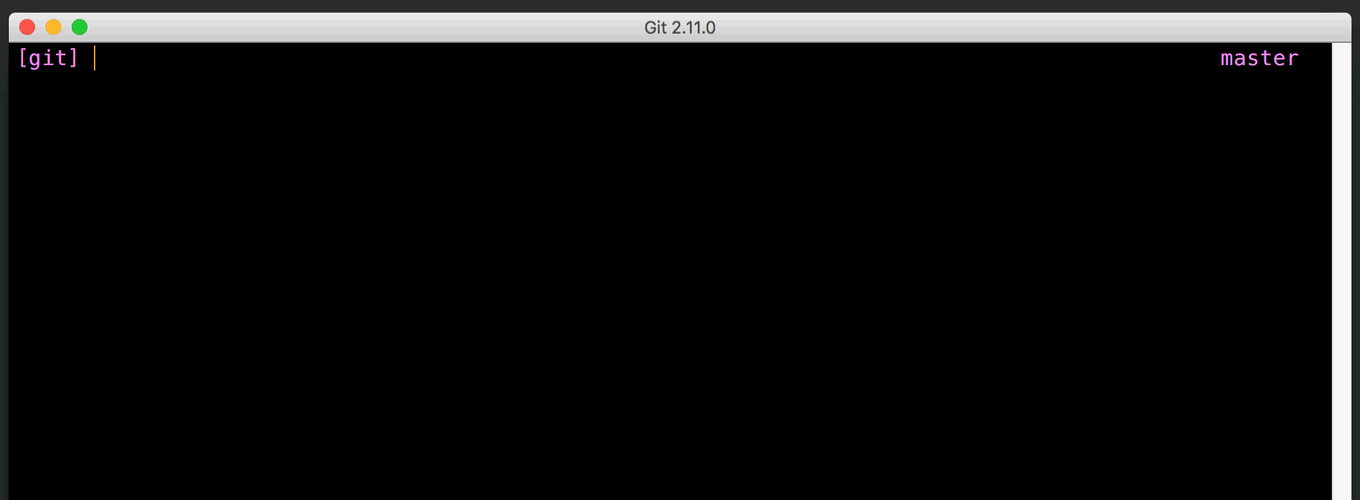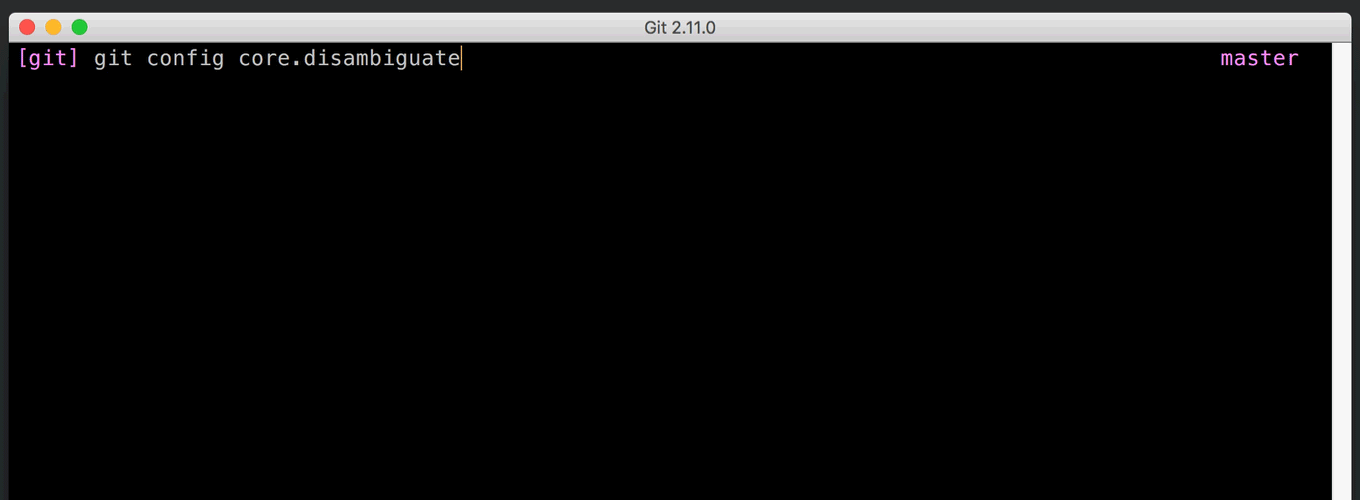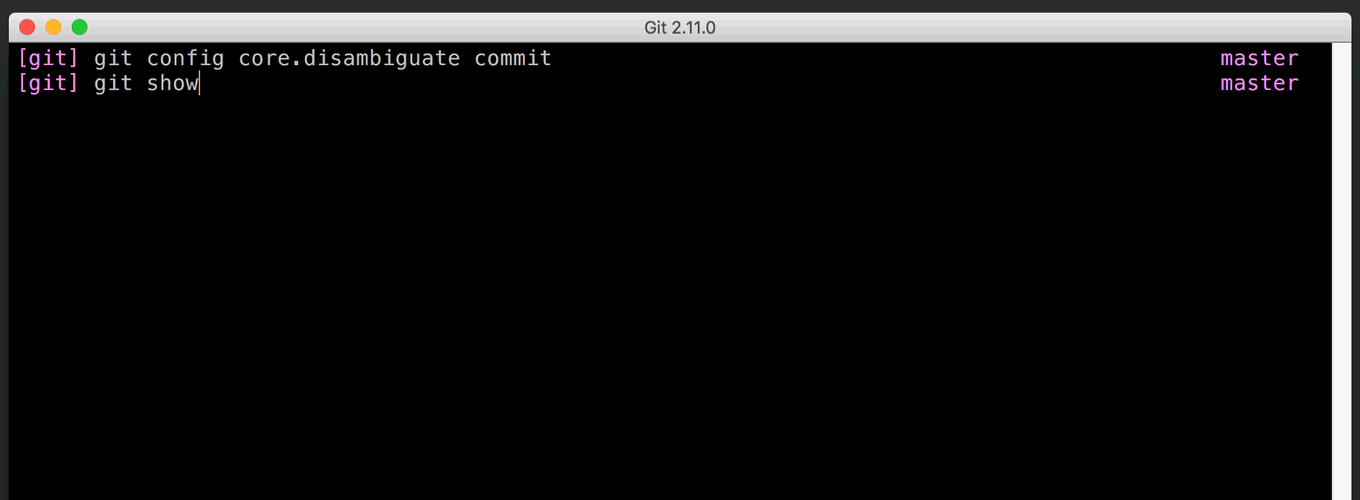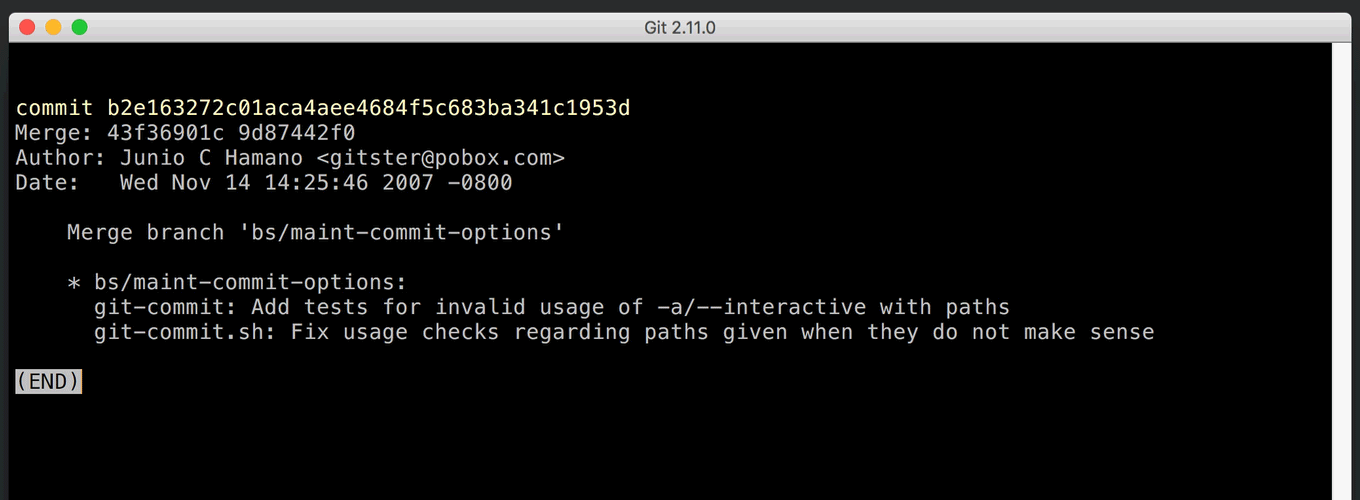
The issue is that repositories tend to grow over time, acquiring more and more objects. A name that’s unique one day may not be the next. If you write an abbreviated SHA-1 in a bug report or commit message, it may become ambiguous as your project grows. This is exactly what happened in the Linux kernel repository; it now has over 5 million objects, meaning we’d expect collisions with names shorter than 12 hexadecimal characters. Old references like this one are now ambiguous and can’t be inspected with commands like git show.
To address this, Git 2.11 ships with several improvements.
First, the minimum abbreviation length now scales with the number of objects in the repository. This isn’t foolproof, as repositories do grow over time, but growing projects will quickly scale up to larger, future-proof lengths. If you use Git with even moderate-sized projects, you’ll see commands like git log --oneline produce longer SHA-1 identifiers. [source]
That still leaves the question of what to do when you somehow do get an ambiguous short SHA-1. Git 2.11 has two features to help with that. One is that instead of simply complaining of the ambiguity, Git will print the list of candidates, along with some details of the objects. That usually gives enough information to decide which object you’re interested in. [source]
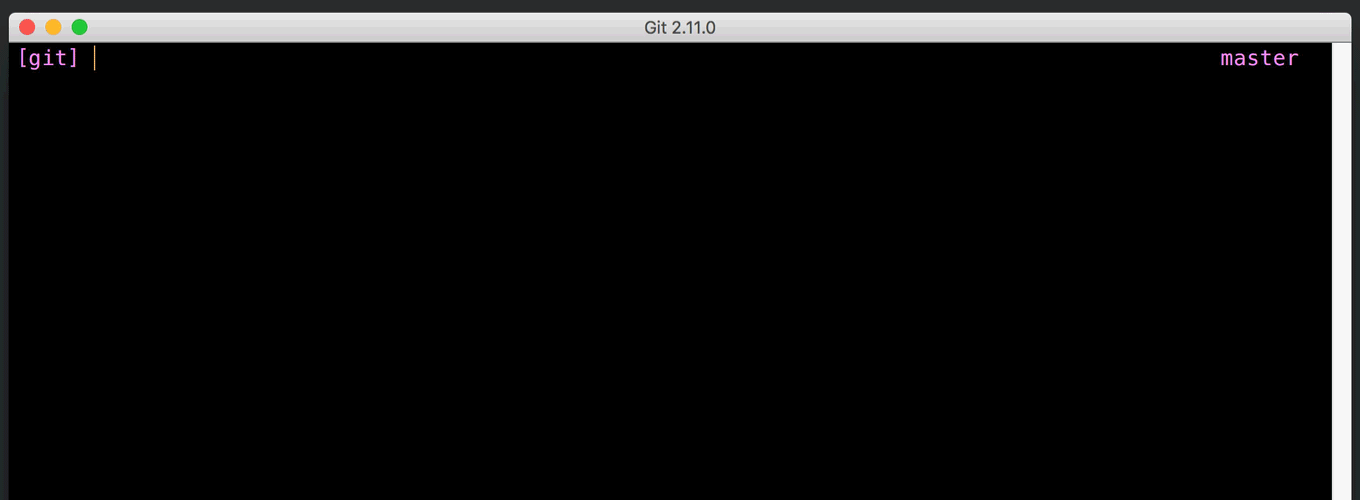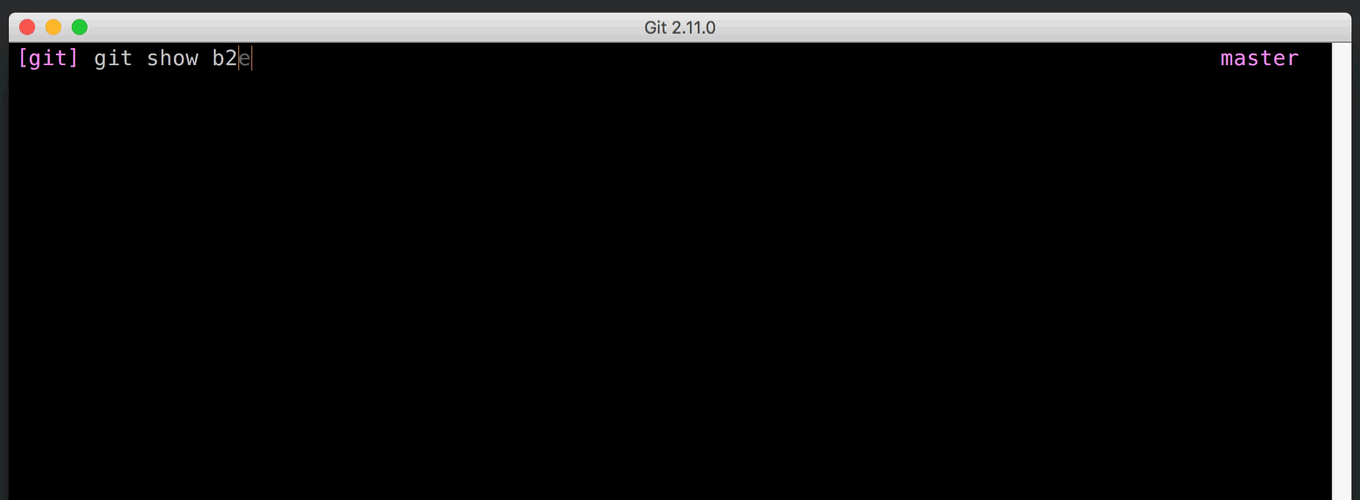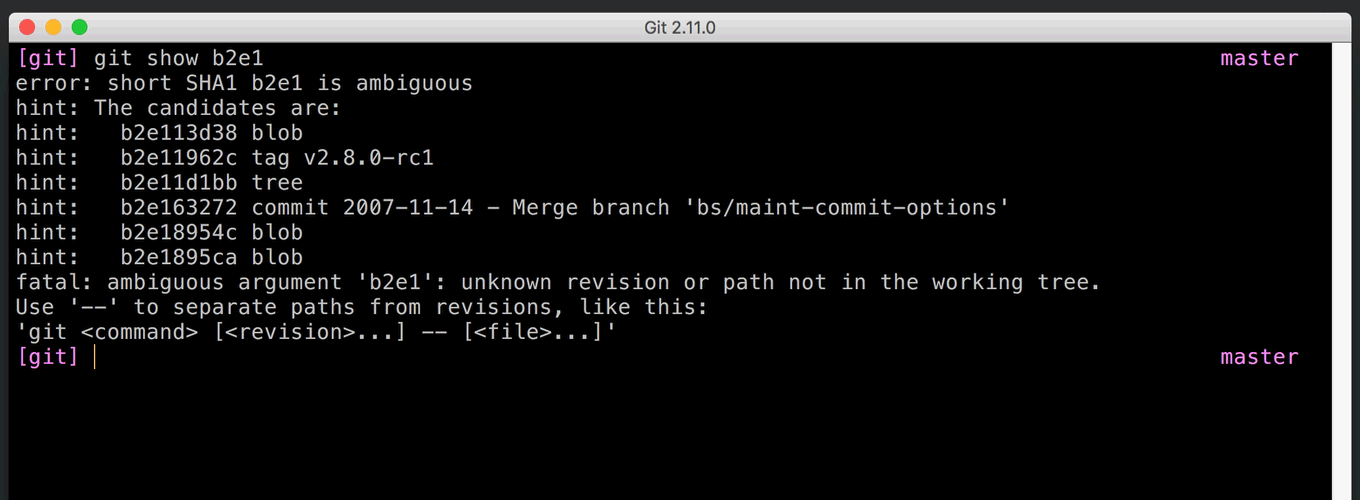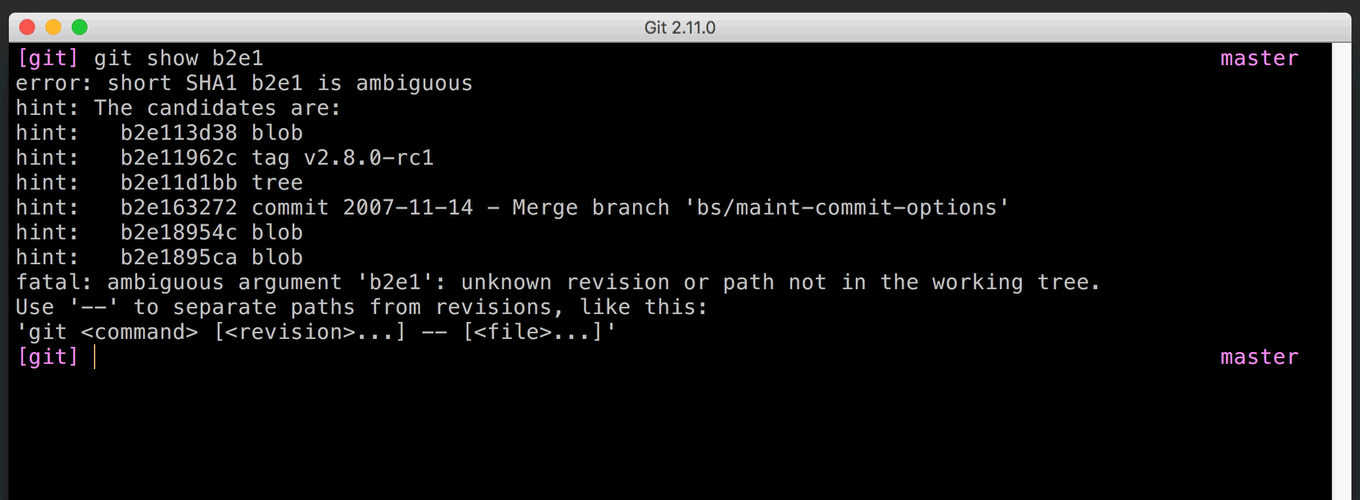
Of course, it’s even more convenient if Git simply picks the object you wanted in the first place. A while ago, Git learned to use context to figure out which object you meant. For example, git log expects to see a commit (or a tag that points to a commit). But other commands, like git show, operate on any type of object; they have no context to guess which object you meant. You can now set the core.disambiguate config option to prefer a specific type. [source]
Performance Optimizations
One of Git’s goals has always been speed. While some of that comes from the overall design, there are a lot of opportunities to optimize the code itself. Almost every Git version ships with more optimizations, and 2.11 is no exception. Let’s take a closer look at a few of the larger examples.
Delta Chains
Git 2.11 is faster at accessing delta chains in its object database, which should improve the performance of many common operations. To understand what’s going on, we first have to know what the heck a delta chain is.
You may know that Git avoids storing files multiple times, because all data is stored in objects named after the SHA-1 of the contents. But in a version control system, we often see data that is almost identical (i.e., your files change just a little bit from version to version). Git stores these related objects as “deltas”: one object is chosen as a base that is stored in full, and other objects are stored as a sequence of change instructions from that base, like “remove bytes 50-100” and “add in these new bytes at offset 50”. The resulting deltas are a fraction of the size of the full object, and Git’s storage ends up proportional to the size of the changes, not the size of all versions.
As files change over time, the most efficient base is often an adjacent version. If that base is itself a delta, then we may form a chain of deltas: version two is stored as a delta against version one, and then version three is stored as a delta against version two, and so on. But these chains can make it expensive to reconstruct the objects when we need them. Accessing version three in our example requires first reconstructing version two. As the chains get deeper and deeper, the cost of reconstructing intermediate versions gets larger.
For this reason, Git typically limits the depth of a given chain to 50 objects. However, when repacking using git gc --aggressive, the default is bumped to 250, with the assumption that it would make a significantly smaller pack. But that number was chosen somewhat arbitrarily, and it turns out that the ideal balance between size and CPU actually is around 50. So that’s the default in Git 2.11, even for aggressive repacks. [source]
Even 50 deltas is a lot to go through to construct one object. To reduce the impact, Git keeps a cache of recently reconstructed objects. This works out well because deltas and their bases tend to be close together in history, so commands like git log which traverse history tend to need those intermediate bases again soon. That cache has an adjustable size, and has been bumped over the years as machines have gotten more RAM. But due to storing the cache in a fairly simple data structure, Git kept many fewer objects than it could, and frequently evicted entries at the wrong time.
In Git 2.11, the delta base cache has received a complete overhaul. Not only should it perform better out of the box (around 10% better on a large repository), but the improvements will scale up if you adjust the core.deltaBaseCacheLimit config option beyond its default of 96 megabytes. In one extreme case, setting it to 1 gigabyte improved the speed of a particular operation on the Linux kernel repository by 32%. [source, source]
Object Lookups
The delta base improvements help with accessing individual objects. But before we can access them, we have to find them. Recent versions of Git have optimized object lookups when there are multiple packfiles.
When you have a large number of objects, Git packs them together into “packfiles”: single files that contain many objects along with an index for optimized lookups. A repository also accumulates packfiles as part of fetching or pushing, since Git uses them to transfer objects over the network. The number of packfiles may grow from day-to-day usage, until the next repack combines them into a single pack. Even though looking up an object in each packfile is efficient, if there are many packfiles Git has to do a linear search, checking each packfile in turn for the object.
Historically, Git has tried to reduce the cost of the linear search by caching the last pack in which an object was found and starting the next search there. This helps because most operations look up objects in order of their appearance in history, and packfiles tend to store segments of history. Looking in the same place as our last successful lookup often finds the object on the first try, and we don’t have to check the other packs at all.
In Git 2.10, this “last pack” cache was replaced with a data structure to store the packs in most recently used (MRU) order. This speeds up object access, though it’s only really noticeable when the number of packs gets out of hand.
In Git 2.11, this MRU strategy has been adapted to the repacking process itself, which previously did not even have a single “last found” cache. The speedups are consequently more dramatic here; repacking the Linux kernel from a 1000-pack state is over 70% faster. [source, source]
Patch IDs
Git 2.11 speeds up the computation of “patch IDs”, which are used heavily by git rebase.
Patch IDs are a fingerprint of the changes made by a single commit. You can compare patch IDs to find “duplicate” commits: two changes at different points in history that make the exact same change. The rebase command uses patch IDs to find commits that have already been merged upstream.
Patch ID computation now avoids both merge commits and renames, improving the runtime of the duplicate check by a factor of 50 in some cases. [source, source]
Advanced filter processes
Git includes a “filter” mechanism which can be used to convert file contents to and from a local filesystem representation. This is what powers Git’s line-ending conversion, but it can also execute arbitrary external programs. The Git LFS system hooks into Git by registering its own filter program.
The protocol that Git uses to communicate with the filter programs is very simple. It executes a separate filter for each file, writes the filter input, and reads back the filter output. If you have a large number of files to filter, the overhead of process startup can be significant, and it’s hard for filters to share any resources (such as HTTP connections) among themselves.
Git 2.11 adds a second, slightly more complex protocol that can filter many files with a single process. This can reportedly improve checkout times with many Git LFS objects by as much as a factor of 80.
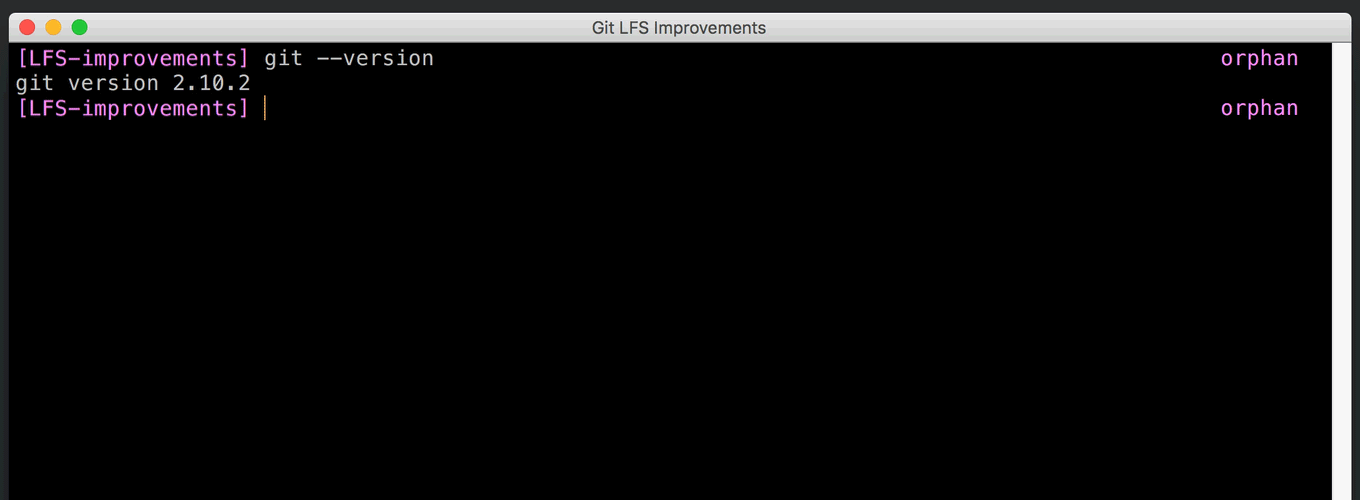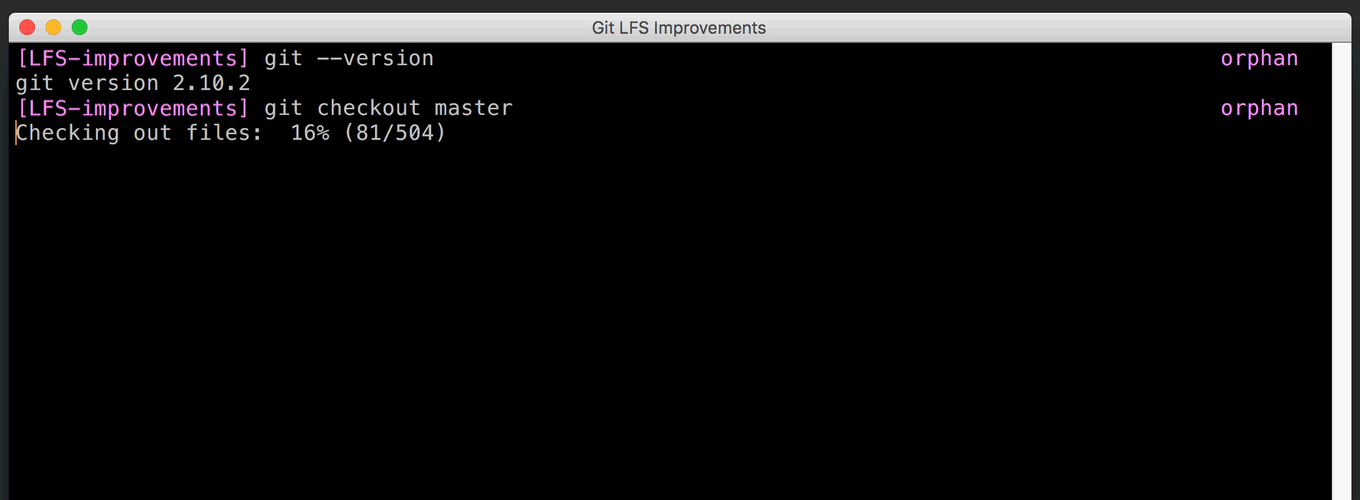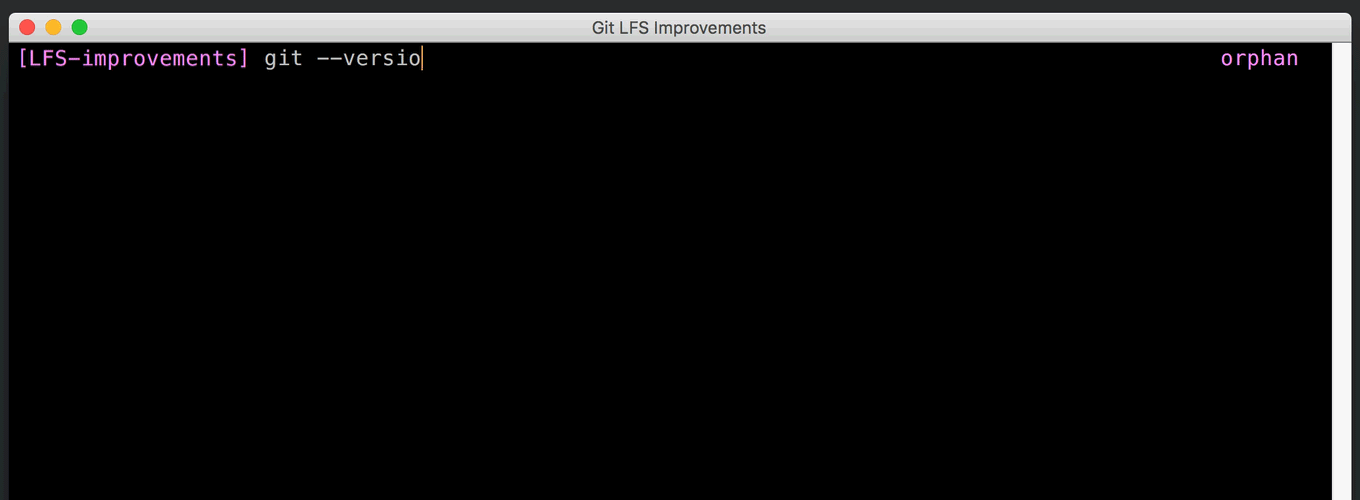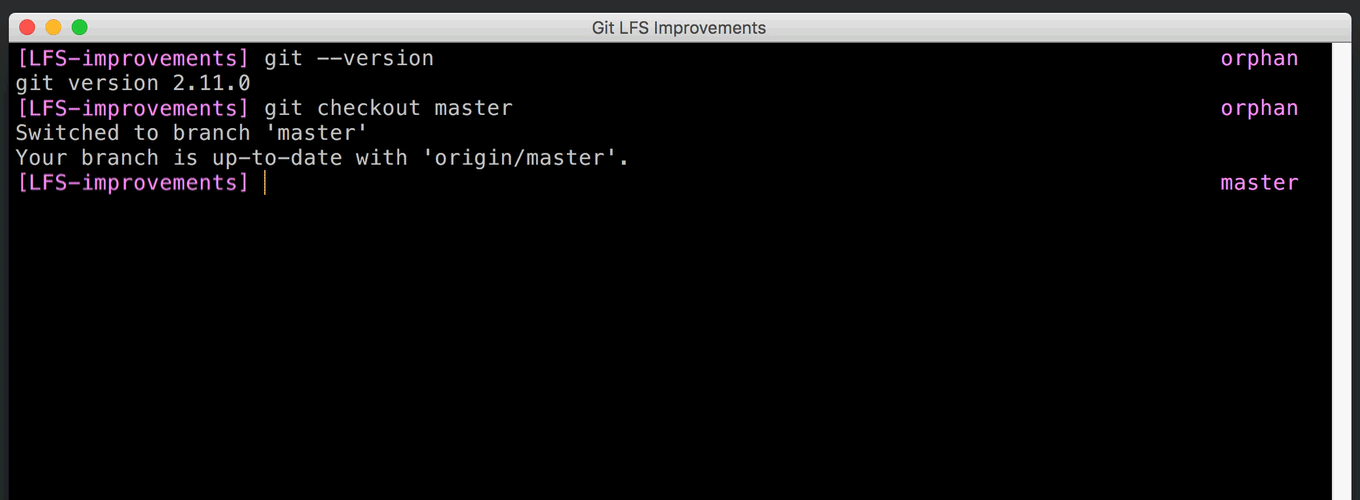
The original protocol is still available for backwards compatibility, and the new protocol is designed to be extensible. Already there has been discussion of allowing it to operate asynchronously, so the filter can return results as they arrive. [source]
Sundries
- In our post about Git 2.9, we mentioned some improvements to the diff algorithm to make the results easier to read (the
--compaction-heuristicoption). That algorithm did not become the default because there were some corner cases that it did not handle well. But after some very thorough analysis, Git 2.11 has an improved algorithm that behaves similarly but covers more cases and does not have any regressions. The new option goes under the name--indent-heuristic(anddiff.indentHeuristic), and will likely become the default in a future version of Git. [source] - Ever wanted to see just the commits brought into a branch by a merge commit? Git now understands negative parent-number selectors, exclude the given parent (rather than selecting it). It may take a minute to wrap your head around that, but it means that
git log 1234abcd^-1will show all of the commits that were merged in by1234abcd, but none of the commits that were already on the branch. You can also use^-(omitting the1) as a shorthand for^-1. [source] - There’s now a credential helper in
contrib/that can use GNOME libsecret to store your Git passwords. [source] - The
git diffcommand now understands--submodule=diff(as well as setting thediff.submoduleconfig todiff), which will show changes to submodules as an actual patch between the two submodule states. [source] -
git statushas a new machine-readable output format that is easier to parse and contains more information. Check it out if you’re interested in scripting around Git. [source] - Work has continued on converting some of Git’s shell scripts to C programs. This can drastically improve performance on platforms where extra processes are expensive (like Windows), especially in programs that may invoke sub-programs in a loop. [source, source]
The whole shebang
That’s just a sampling of the changes in Git 2.11, which contains over 650 commits. Check out the the full release notes for the complete list.
[1] It’s true. According to the National Weather Service, the odds of being struck by lightning are 1 in a million. That’s about 1 in 220, so the odds of it happening in 8 consecutive years (starting with this year) are 1 in 2160.
[2] It turns out to be rather complicated to compute the probability of seeing a collision, but there are approximations. With 5 million objects, there’s about a 1 in 1035 chance of a full SHA-1 collision, but the chance of a collision in 7 characters approaches 100%. The more commonly used metric is “numbers of items to reach a 50% chance of collision”, which is the square root of the total number of possible items. If you’re working with exponents, that’s easy; you just halve the exponent. Each hex character represents 4 bits, so a 7-character name has 228 possibilities. That means we expect a collision around 214, or 16384 objects.
Written by

Related posts

$100 million for open source: A milestone built by the community
Celebrating $100 million contributed by the community to the people who build and sustain open source every day.
6 security settings every GitHub maintainer should enable this week
These six free settings will not make your project unhackable. Nothing will. What they will do is close the easy doors. Turn these on, and your project will be meaningfully harder to attack than it was before.
How GitHub maintains compliance for open source dependencies
Explore how the Open Source Program Office uses GitHub’s new license compliance product to manage open source dependencies at scale.