Commits are snapshots, not diffs
Git has a reputation for being confusing. Users stumble over terminology and phrasing that misguides their expectations. This is most apparent in commands that “rewrite history” such as git cherry-pick or git rebase. In my experience,…

Git has a reputation for being confusing. Users stumble over terminology and phrasing that misguides their expectations. This is most apparent in commands that “rewrite history” such as git cherry-pick or git rebase. In my experience, the root cause of this confusion is an interpretation of commits as diffs that can be shuffled around. However, commits are snapshots, not diffs!
I believe that Git becomes understandable if we peel back the curtain and look at how Git stores your repository data. After we investigate this model, we’ll explore how this new perspective helps us understand commands like git cherry-pick and git rebase.
If you want to go really deep, you should read the Git Internals chapter of the Pro Git book.
I’ll be using the git/git repository checked out at v2.29.2 as an example. Follow along with my command-line examples for extra practice.
Object IDs are hashes
The most important part to know about Git objects is that Git references each by its object ID (OID for short), providing a unique name for the object. We will use the git rev-parse <ref> command to discover these OIDs. Each object is essentially a plain-text file and we can examine its contents using the git cat-file -p <oid> command.
You might also be used to seeing OIDs given as a shorter hex string. This string is given as something long enough that only one object in the repository has an OID that matches that abbreviation. If we request the type of an object using an abbreviated OID that is too short, then we will see the list of OIDs that match
$ git cat-file -t e0c03
error: short SHA1 e0c03 is ambiguous
hint: The candidates are:
hint: e0c03f27484 commit 2016-10-26 - contrib/buildsystems: ignore irrelevant files in Generators/
hint: e0c03653e72 tree
hint: e0c03c3eecc blob
fatal: Not a valid object name e0c03What are these types: blob, tree, and commit? Let’s start at the bottom and work our way up.
Blobs are file contents
At the bottom of the object model, blobs contain file contents. To discover the OID for a file at your current revision, run git rev-parse HEAD:<path>. Then, use git cat-file -p <oid> to find its contents.
$ git rev-parse HEAD:README.md
eb8115e6b04814f0c37146bbe3dbc35f3e8992e0
$ git cat-file -p eb8115e6b04814f0c37146bbe3dbc35f3e8992e0 | head -n 8
[](https://github.com/git/git/actions?query=branch%3Amaster+event%3Apush)
Git - fast, scalable, distributed revision control system
=========================================================
Git is a fast, scalable, distributed revision control system with an
unusually rich command set that provides both high-level operations
and full access to internals.If I edit the README.md file on my disk, then git status notices that the file has a recent modified time and hashes the contents. If the contents don’t match the current OID at HEAD:README.md, then git status reports the file as “modified on disk.” In this way, we can see if the file contents in the current working directory match the expected contents at HEAD.
Trees are directory listings
Note that blobs contain file contents, but not the file names! The names come from Git’s representation of directories: trees. A tree is an ordered list of path entries, paired with object types, file modes, and the OID for the object at that path. Subdirectories are also represented as trees, so trees can point to other trees!

We will use diagrams to visualize how these objects are related. We use boxes for blobs and triangles for trees.
$ git rev-parse HEAD^{tree}
75130889f941eceb57c6ceb95c6f28dfc83b609c
$ git cat-file -p 75130889f941eceb57c6ceb95c6f28dfc83b609c | head -n 15
100644 blob c2f5fe385af1bbc161f6c010bdcf0048ab6671ed .cirrus.yml
100644 blob c592dda681fecfaa6bf64fb3f539eafaf4123ed8 .clang-format
100644 blob f9d819623d832113014dd5d5366e8ee44ac9666a .editorconfig
100644 blob b08a1416d86012134f823fe51443f498f4911909 .gitattributes
040000 tree fbe854556a4ae3d5897e7b92a3eb8636bb08f031 .github
100644 blob 6232d339247fae5fdaeffed77ae0bbe4176ab2de .gitignore
100644 blob cbeebdab7a5e2c6afec338c3534930f569c90f63 .gitmodules
100644 blob bde7aba756ea74c3af562874ab5c81a829e43c83 .mailmap
100644 blob 05f3e3f8d79117c1d32bf5e433d0fd49de93125c .travis.yml
100644 blob 5ba86d68459e61f87dae1332c7f2402860b4280c .tsan-suppressions
100644 blob fc4645d5c08bd005238fc72cfa709495d8722e6a CODE_OF_CONDUCT.md
100644 blob 536e55524db72bd2acf175208aef4f3dfc148d42 COPYING
040000 tree a58410edddbdd133cca6b3322bebe4fb37be93fa Documentation
100755 blob ca6ccb49866c595c80718d167e40cfad1ee7f376 GIT-VERSION-GEN
100644 blob 9ba33e6a141a3906eb707dd11d1af4b0f8191a55 INSTALLTrees provide names for each sub-item. Trees also include information such as Unix file permissions, object type (blob or tree), and OIDs for each entry. We cut the output to the top 15 entries, but we can use grep to discover that this tree has a README.md entry that points to our earlier blob OID.
$ git cat-file -p 75130889f941eceb57c6ceb95c6f28dfc83b609c | grep README.md
100644 blob eb8115e6b04814f0c37146bbe3dbc35f3e8992e0 README.mdTrees can point to blobs and other trees using these path entries. Keep in mind that those relationships are paired with path names, but we will not always show those names in our diagrams.
The tree itself doesn’t know where it exists within the repository, that is the role of the objects pointing to the tree. The tree referenced by <ref>^{tree} is a special tree: the root tree. This designation is based on a special link from your commits.
Commits are snapshots
A commit is a snapshot in time. Each commit contains a pointer to its root tree, representing the state of the working directory at that time. The commit has a list of parent commits corresponding to the previous snapshots. A commit with no parents is a root commit and a commit with multiple parents is a merge commit. Commits also contain metadata describing the snapshot such as author and committer (including name, email address, and date) and a commit message. The commit message is an opportunity for the commit author to describe the purpose of that commit with respect to the parents.
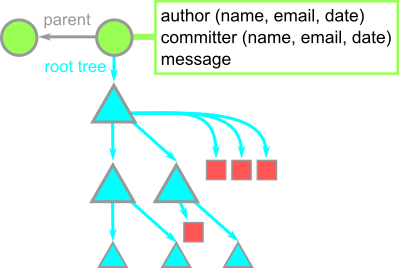
For example, the commit at v2.29.2 in the Git repository describes that release, and is authored and committed by the Git maintainer.
$ git rev-parse HEAD
898f80736c75878acc02dc55672317fcc0e0a5a6
/c/_git/git ((v2.29.2))
$ git cat-file -p 898f80736c75878acc02dc55672317fcc0e0a5a6
tree 75130889f941eceb57c6ceb95c6f28dfc83b609c
parent a94bce62b99be35f2ee2b4c98f97c222e7dd9d82
author Junio C Hamano <gitster@pobox.com> 1604006649 -0700
committer Junio C Hamano <gitster@pobox.com> 1604006649 -0700
Git 2.29.2
Signed-off-by: Junio C Hamano <gitster@pobox.com>Looking a little farther in the history with git log, we can see a more descriptive commit message talking about the change between that commit and its parent.
$ git cat-file -p 16b0bb99eac5ebd02a5dcabdff2cfc390e9d92ef
tree d0e42501b1cf65395e91e22e74f75fc5caa0286e
parent 56706dba33f5d4457395c651cf1cd033c6c03c7a
author Jeff King <peff@peff.net> 1603436979 -0400
committer Junio C Hamano <gitster@pobox.com> 1603466719 -0700
am: fix broken email with --committer-date-is-author-date
Commit e8cbe2118a (am: stop exporting GIT_COMMITTER_DATE, 2020-08-17)
rewrote the code for setting the committer date to use fmt_ident(),
rather than setting an environment variable and letting commit_tree()
handle it. But it introduced two bugs:
- we use the author email string instead of the committer email
- when parsing the committer ident, we used the wrong variable to
compute the length of the email, resulting in it always being a
zero-length string
This commit fixes both, which causes our test of this option via the
rebase "apply" backend to now succeed.
Signed-off-by: Jeff King <peff@peff.net> Signed-off-by: Junio C Hamano <gitster@pobox.com>In our diagrams, we will use circles to represent commits. Notice the alliteration? Let’s review:
- Boxes are blobs. These represent file contents.
- Triangles are trees. These represent directories.
- Circles are commits. These are snapshots in time.
Branches are pointers
In Git, we move around the history and make changes without referring to OIDs most of the time. This is because branches provide pointers to the commits we care about. A branch with name main is actually a reference in Git called refs/heads/main. These files literally contain hex strings referencing the OID of a commit. As you work, these references change their contents to point to other commits.
This means branches are significantly different from our previous Git objects. Commits, trees, and blobs are immutable, meaning you can’t change their contents. If you change the contents, then you get a different hash and thus a new OID referring to the new object! Branches are named by users to provide meaning, such as trunk or my-special-project. We use branches to track and share work.
The special reference HEAD points to the current branch. When we add a commit to HEAD, it automatically updates that branch to the new commit.
We can create a new branch and update our HEAD using git switch -c:
$ git switch -c my-branch
Switched to a new branch 'my-branch'
$ cat .git/refs/heads/my-branch
1ec19b7757a1acb11332f06e8e812b505490afc6
$ cat .git/HEAD
ref: refs/heads/my-branchNotice how creating my-branch created a file (.git/refs/heads/my-branch) containing the current commit OID and the .git/HEAD file was updated to point at this branch. Now, if we update HEAD by creating new commits, the branch my-branch will update to point to that new commit!
The big picture
Let’s put all of these new terms into one giant picture. Branches point to commits, commits point to other commits and their root trees, trees point to blobs and other trees, and blobs don’t point to anything. Here is a diagram containing all of our objects all at once:
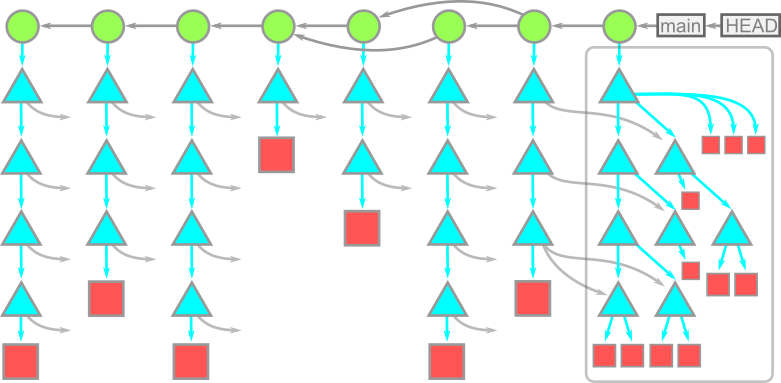
In this diagram, time moves from left to right. The arrows between a commit and its parents go from right to left. Each commit has a single root tree. HEAD points to the main branch here, and main points to the most-recent commit. The root tree at this commit is fully expanded underneath, while the rest of the trees have arrows pointing towards these objects. The reason for that is that the same objects are reachable from multiple root trees! Since these trees reference those objects by their OID (their content) these snapshots do not need multiple copies of the same data. In this way, Git’s object model forms a Merkle tree.
When we view the object model in this way, we can see why commits are snapshots: they link directly to a full view of the expected working directory for that commit!
Computing diffs
Even though commits are snapshots, we frequently look at a commit in a history view or on GitHub as a diff. In fact, the commit message frequently refers to this diff. The diff is dynamically generated from the snapshot data by comparing the root trees of the commit and its parent. Git can compare any two snapshots in time, not just adjacent commits.
To compare two commits, start by looking at their root trees, which are almost always different. Then, perform a depth-first-search on the subtrees by following pairs when paths for the current tree have different OIDs. In the example below, the root trees have different values for the docs, so we recurse into those two trees. Those trees have different values for M.md, so those two blobs are compared line-by-line and that diff is shown. Still within docs, N.md is the same, so that is skipped and we pop back to the root tree. The root tree then sees that the things directories have equal OIDs as well as the README.md entries.
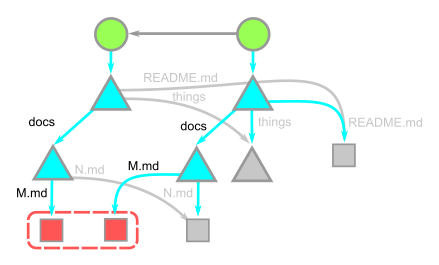
In the diagram above, we notice that the things tree is never visited, and so none of its reachable objects are visited. This way, the cost of computing a diff is relative to the number of paths with different content.
Now we have the understanding that commits are snapshots and we can dynamically compute a diff between any two commits. Then why isn’t this common knowledge? Why do new users stumble over this idea that a commit is a diff?
One of my favorite analogies is to think of commits as having a wave/partical duality where sometimes they are treated like snapshots and other times they are treated like diffs. The crux of the matter really goes into a different kind of data that’s not actually a Git object: patches.
Wait, what’s a patch?
A patch is a text document that describes how to alter an existing codebase. Patches are how extremely-distributed groups can share code without using Git commits directly. You can see these being shuffled around on the Git mailing list.
A patch contains a description of the change and why it is valuable, followed by a diff. The idea is that someone could use that reasoning as a justification to apply that diff to their copy of the code.
Git can convert a commit into a patch using git format-patch. A patch can then be applied to a Git repository using git apply. This was the dominant way to share code in the early days of open source, but most projects have moved to sharing Git commits directly through pull requests.
The biggest issue with sharing patches is that the patch loses the parent information and the new commit has a parent equal to your existing HEAD. Moreover, you get a different commit even if you use the same parent as before due to the commit time, but also the committer changes! This is the fundamental reason why Git has both “author” and “committer” details in the commit object.
The biggest problem with using patches is that it is hard to apply a patch when your working directory does not match the sender’s previous commit. Losing the commit history makes it difficult to resolve conflicts.
This idea of “moving patches around” has transferred into several Git commands as “moving commits around.” Instead, what actually happens is that commit diffs are replayed, creating new commits.
If commits aren’t diffs, then what does git cherry-pick do?
The git cherry-pick <oid> command creates a new commit with an identical diff to <oid> whose parent is the current commit. Git is essentially following these steps:
- Compute the diff between the commit
<oid>and its parent. - Apply that diff to the current
HEAD. - Create a new commit whose root tree matches the new working directory and whose parent is the commit at
HEAD. - Move the ref at
HEADto that new commit.
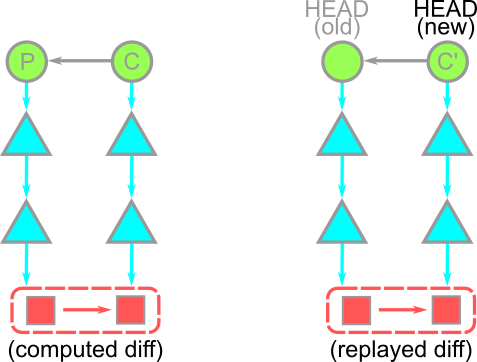
After Git creates the new commit, the output of git log -1 -p HEAD should match the output of git log -1 -p <oid>.
It is important to recognize that we didn’t “move” the commit to be on top of our current HEAD, we created a new commit whose diff matches the old commit.
If commits aren’t diffs, then what does git rebase do?
The git rebase command presents itself as a way to move commits to have a new history. In its most basic form it is really just a series of git cherry-pick commands, replaying diffs on top of a different commit.
The most important thing is that git rebase <target> will discover the list of commits that are reachable from HEAD but not reachable from <target>. You can show these yourself using git log --oneline <target>..HEAD.
Then, the rebase command simply navigates to the <target> location and starts performing git cherry-pick commands on this commit range, starting from the oldest commits. At the end, we have a new set of commits with different OIDs but similar diffs to the original commit range.
For example, consider a sequence of three commits in the current HEAD since branching off of a target branch. When running git rebase target, the common base P is computed to determine the commit list A, B, and C. These are then cherry-picked on top of target in order to construct new commits A', B', and C'.
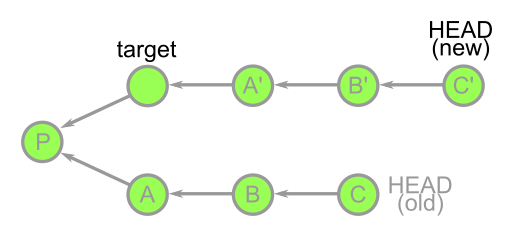
The commits A', B', and C' are brand new commits that share a lot of information with A, B, and C, but are distinct new objects. In fact, the old commits still exist in your repository until garbage collection runs.
We can even inspect how these two commit ranges are different using the git range-diff command! I’ll use some example commits in the Git repository to rebase onto the v2.29.2 tag, then modify the tip commit slightly.
$ git checkout -f 8e86cf65816
$ git rebase v2.29.2
$ echo extra line >>README.md
$ git commit -a --amend -m "replaced commit message"
$ git range-diff v2.29.2 8e86cf65816 HEAD
1: 17e7dbbcbc = 1: 2aa8919906 sideband: avoid reporting incomplete sideband messages
2: 8e86cf6581 ! 2: e08fff1d8b sideband: report unhandled incomplete sideband messages as bugs
@@ Metadata
Author: Johannes Schindelin <Johannes.Schindelin@gmx.de>
## Commit message ##
- sideband: report unhandled incomplete sideband messages as bugs
+ replaced commit message
- It was pretty tricky to verify that incomplete sideband messages are
- handled correctly by the `recv_sideband()`/`demultiplex_sideband()`
- code: they have to be flushed out at the end of the loop in
- `recv_sideband()`, but the actual flushing is done by the
- `demultiplex_sideband()` function (which therefore has to know somehow
- that the loop will be done after it returns).
-
- To catch future bugs where incomplete sideband messages might not be
- shown by mistake, let's catch that condition and report a bug.
-
- Signed-off-by: Johannes Schindelin <johannes.schindelin@gmx.de>
- Signed-off-by: Junio C Hamano <gitster@pobox.com>
+ ## README.md ##
+@@ README.md: and the name as (depending on your mood):
+ [Documentation/giteveryday.txt]: Documentation/giteveryday.txt
+ [Documentation/gitcvs-migration.txt]: Documentation/gitcvs-migration.txt
+ [Documentation/SubmittingPatches]: Documentation/SubmittingPatches
++extra line
## pkt-line.c ##
@@ pkt-line.c: int recv_sideband(const char *me, int in_stream, int out)Notice that the resulting range-diff claims that commits 17e7dbbcbc and 2aa8919906 are “equal”, which means they would generate the same patch. The second pair of commits are different, showing that the commit message changed and there is an edit to the README.md that was not in the original commit.
If you are following along, you can also see how the commit history still exists for these two commit sets. The new commits have the v2.29.2 tag as the third commit in the history while the old commits have the (earlier) v2.28.0 tag as the third commit.
$ git log --oneline -3 HEAD
e08fff1d8b2 (HEAD) replaced commit message
2aa89199065 sideband: avoid reporting incomplete sideband messages
898f80736c7 (tag: v2.29.2) Git 2.29.2
$ git log --oneline -3 8e86cf65816
8e86cf65816 sideband: report unhandled incomplete sideband messages as bugs
17e7dbbcbce sideband: avoid reporting incomplete sideband messages
47ae905ffb9 (tag: v2.28.0) Git 2.28Since commits aren’t diffs, how does Git track renames?
If you were looking carefully at the object model, you might have noticed that Git never tracks changes between commits in the stored object data. You might have wondered “how does Git know a rename happened?”
Git doesn’t track renames. There is no data structure inside Git that stores a record that a rename happened between a commit and its parent. Instead, Git tries to detect renames during the dynamic diff calculation. There are two stages to this rename detection: exact renames and edit-renames.
After first computing a diff, Git inspects the internal model of that diff to discover which paths were added or deleted. Naturally, a file that was moved from one location to another would appear as a deletion from the first location and an add in the second. Git attempts to match these adds and deletes to create a set of inferred renames.
The first stage of this matching algorithm looks at the OIDs of the paths that were added and deleted and see if any are exact matches. Such exact matches are paired together.
The second stage is the expensive part: how can we detect files that were renamed and edited? Git iterates through each added file and compares that file against each deleted file to compute a similarity score as a percentage of lines in common. By default, anything larger than 50% of lines in common counts as a potential edit-rename. The algorithm continues comparing these pairs until finding the maximum match.
Did you notice a problem? This algorithm runs A * D diffs, where A is the number of adds and D is the number of deletes. This is quadratic! To avoid extra-long rename computations, Git will skip this portion of detecting edit-renames if A + D is larger than an internal limit. You can modify this limit using the diff.renameLimit config option. You can also avoid the algorithm altogether by disabling the diff.renames config option.
I’ve used my awareness of the Git rename detection in my own projects. For example, I forked VFS for Git to create the Scalar project and wanted to re-use a lot of the code but also change the file structure significantly. I wanted to be able to follow the history of these files into the versions in the VFS for Git codebase, so I constructed my refactor in two steps:
- Rename all of the files without changing the blobs.
- Replace strings to modify the blobs without changing filenames.
These two steps ensured that I can quickly use git log --follow -- <path> to see the history of a file across this rename.
$ git log --oneline --follow -- Scalar/CommandLine/ScalarVerb.cs
4183579d console: remove progress spinners from all commands
5910f26c ScalarVerb: extract Git version check
...
9f402b5a Re-insert some important instances of GVFS
90e8c1bd [REPLACE] Replace old name in all files
fb3a2a36 [RENAME] Rename all files
cedeeaa3 Remove dead GVFSLock and GitStatusCache code
a67ca851 Remove more dead hooks code
...I abbreviated the output, but these last two commits don’t actually have a path corresponding to Scalar/CommandLine/ScalarVerb.cs, but instead it is tracking the previous path GVSF/GVFS/CommandLine/GVFSVerb.cs because Git recognized the exact-content rename from the commit fb3a2a36 [RENAME] Rename all files.
Won’t be fooled again!
You now know that commits are snapshots, not diffs! This understanding will help you navigate your experience working with Git.
Now you are armed with deep knowledge of the Git object model. You can use this knowledge to expand your skills in using Git commands or deciding on workflows for your team. In a future blog post, we will use this knowledge to learn about different Git clone options and how to reduce the data you need to get things done!
Written by

Related posts

$100 million for open source: A milestone built by the community
Celebrating $100 million contributed by the community to the people who build and sustain open source every day.
6 security settings every GitHub maintainer should enable this week
These six free settings will not make your project unhackable. Nothing will. What they will do is close the easy doors. Turn these on, and your project will be meaningfully harder to attack than it was before.
How GitHub maintains compliance for open source dependencies
Explore how the Open Source Program Office uses GitHub’s new license compliance product to manage open source dependencies at scale.