Building your first Atom plugin
Authored by GitHub Campus Expert @NickTikhonov. This tutorial will teach you how to write your first package for the Atom text editor. We’ll be building a clone of Sourcerer, a…
Authored by GitHub Campus Expert @NickTikhonov.
This tutorial will teach you how to write your first package for the Atom text editor.
We’ll be building a clone of Sourcerer,
a plugin for finding and using code snippets from StackOverflow. By the end
of this tutorial you will have written a plugin that converts programming
problems written in English into code snippets pulled from StackOverflow:

What you need to know
Atom is written using web technologies. Our package will be built entirely using the EcmaScript 6 standard for JavaScript. You will need to be familiar with:
Tutorial repository
You can follow this tutorial step-by-step or check out the
supplementary repository on GitHub, which contains
the plugin source code. The repository history contains one commit for each step outlined here.
Getting Started
Installing Atom
Download Atom by following the instructions on the Atom website.
We will also need to install apm, the Atom Package Manager command line tool.
You can do this by opening Atom and navigating to Atom > Install Shell Commands
in the application menu. Check that apm was installed correctly by opening your
command line terminal and running apm -v, which should print the version of
the tool and related environments:
apm -v
> apm 1.9.2
> npm 2.13.3
> node 0.10.40
> python 2.7.10
> git 2.7.4Generating starter code
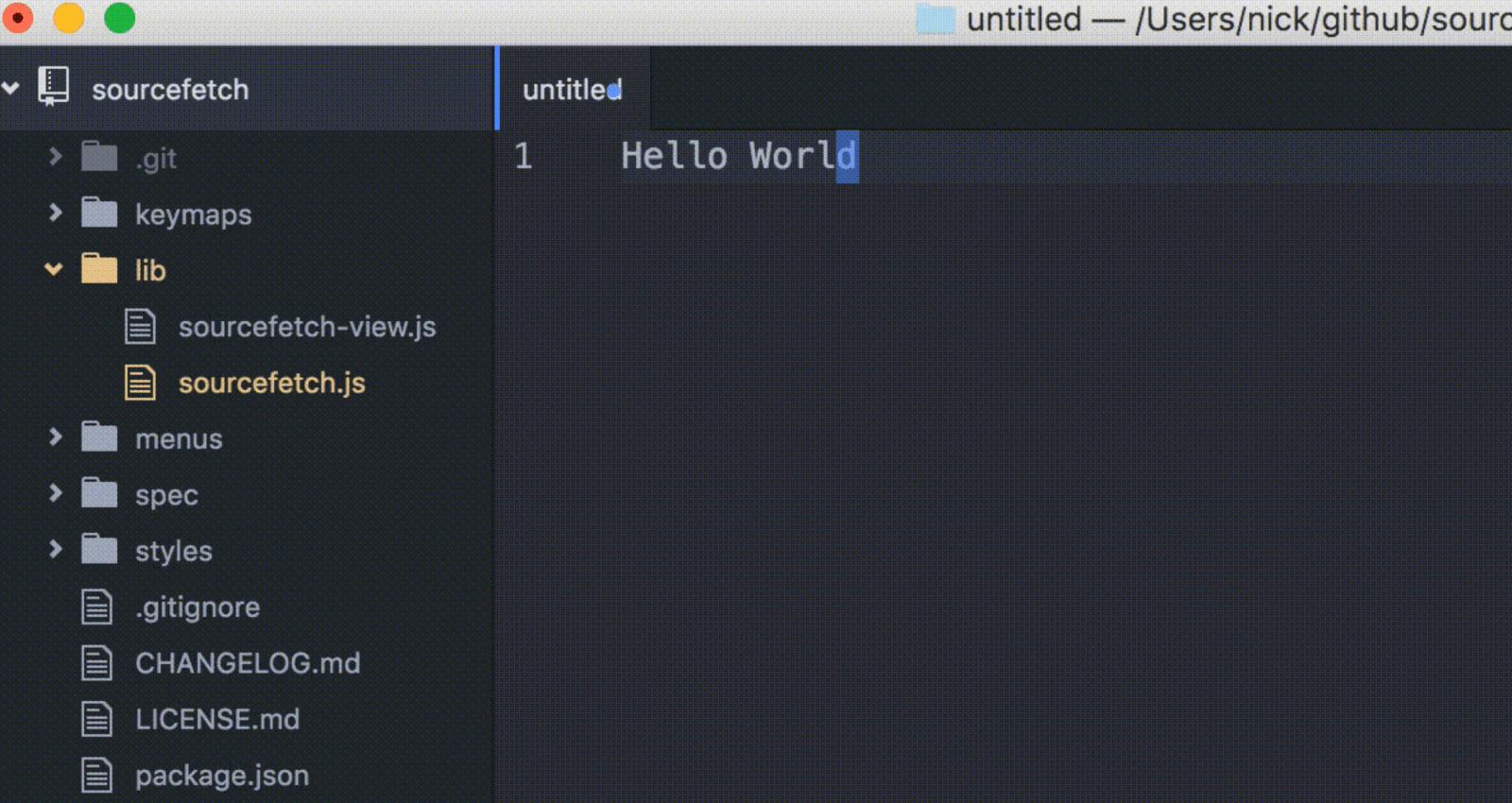
Let’s begin by creating a new package using a utility provided by Atom.
- Launch the editor and press Cmd+Shift+P (on MacOS) or
Ctrl+Shift+P
(on Windows/Linux) to open the Command Palette. - Search for “Package Generator:
Generate Package” and click the corresponding item on the list. You will see a
prompt where you can enter the name of the package – “sourcefetch”. - Press enter to generate the starter package, which should automatically be opened in Atom.
If you don’t see package files appear in the sidebar, press
Cmd+K Cmd+B (on
MacOS) or Ctrl+K
Ctrl+B (on Windows/Linux).
The Command Palette lets you find and run package commands using fuzzy search.
This is a convenient way to run commands without navigating menus or
remembering shortcuts. We will be using it throughout this tutorial.
Running the starter code
Let’s try out the starter package before diving into the code itself. We will
first need to reload Atom to make it aware of the new package that was added.
Open the Command Palette again and run the “Window: Reload” command.
Reloading the current window ensures that Atom runs the latest version of our
source code. We will be running this command every time we want to test the
changes we make to our package.
Run the package toggle command by navigating to Packages > sourcefetch > Toggle
using the editor menu, or run sourcefetch: Toggle using the Command Palette.
You should see a black box appear at the top of the screen. Hide it by running
the command again.

The “toggle” command
Let’s open lib/sourcefetch.js, which contains the package logic and defines
the toggle command.
toggle() {
console.log('Sourcefetch was toggled!');
return (
this.modalPanel.isVisible() ?
this.modalPanel.hide() :
this.modalPanel.show()
);
}toggle is a function exported by the module. It uses a
ternary operator to call show and hide
on the modal panel based on its visibility. modalPanel is an instance of
Panel, a UI element provided by the
Atom API. We declare modalPanel inside export default, which lets us access it as an
instance variable with this.
this.subscriptions.add(atom.commands.add('atom-workspace', {
'sourcefetch:toggle': () => this.toggle()
}));The above statement tells Atom to execute toggle every time the user runs
sourcefetch:toggle. We subscribe an anonymous function, () => this.toggle(),
to be called every time the command is run. This is an example of
event-driven programming,
a common paradigm in JavaScript.
Atom Commands
Commands are nothing more than string identifiers for events triggered by the
user, defined within a package namespace. We’ve already used:
package-generator:generate-packagewindow:reloadsourcefetch:toggle
Packages subscribe to commands in order to execute code in response to these events.
Making your first code change
Let’s make our first code change—we’re going to change toggle to reverse
text selected by the user.
Change “toggle”
- Change the
togglefunction to match the snippet below.
toggle() {
let editor
if (editor = atom.workspace.getActiveTextEditor()) {
let selection = editor.getSelectedText()
let reversed = selection.split('').reverse().join('')
editor.insertText(reversed)
}
}Test your changes
- Reload Atom by running
Window: Reloadin the Command Palette - Navigate to
File > Newto create a new file, type anything you like and
select it with the cursor. - Run the
sourcefetch:togglecommand using the Command Palette, Atom menu, or
by right clicking and selecting “Toggle sourcefetch”
The updated command will toggle the order of the selected text:

See all code changes for this step in the sourcefetch tutorial repository.
The Atom Editor API
The code we added uses the TextEditor API
to access and manipulate the text inside the editor. Let’s take a closer look.
let editor
if (editor = atom.workspace.getActiveTextEditor()) { /* ... */ }The first two lines obtain a reference to a TextEditor
instance. The variable assignment and following code is wrapped in a conditional
to handle the case where there is no text editor instance available, for example,
if the command was run while the user was in the settings menu.
let selection = editor.getSelectedText()Calling getSelectedText gives us access to text selected by the user. If
no text is currently selected, the function returns an empty string.
let reversed = selection.split('').reverse().join('')
editor.insertText(reversed)Our selected text is reversed using JavaScript String methods
. Finally, we call insertText to replace the selected text with the
reversed counterpart. You can learn more about the different TextEditor methods
available by reading the Atom API documentation.
Exploring the starter package
Now that we’ve made our first code change, let’s take a closer look at how an
Atom package is organized by exploring the starter code.
The main file
The main file is the entry-point to an Atom package. Atom knows where to find the
main file from an entry in package.json:
"main": "./lib/sourcefetch",The file exports an object with lifecycle functions which Atom calls on
certain events.
-
activate is called when the package is initially loaded by Atom.
This function is used to initialize objects such as user interface
elements needed by the package, and to subscribe handler functions to package
commands. -
deactivate is called when the package is deactivated, for example, when
the editor is closed or refreshed by the user. -
serialize is called by Atom to allow you to save the state of the package
between uses. The returned value is passed as an argument toactivatewhen
the package is next loaded by Atom.
We are going to rename our package command to fetch, and remove user interface
elements we won’t be using. Update the file to match the version below:
'use babel';
import { CompositeDisposable } from 'atom'
export default {
subscriptions: null,
activate() {
this.subscriptions = new CompositeDisposable()
this.subscriptions.add(atom.commands.add('atom-workspace', {
'sourcefetch:fetch': () => this.fetch()
}))
},
deactivate() {
this.subscriptions.dispose()
},
fetch() {
let editor
if (editor = atom.workspace.getActiveTextEditor()) {
let selection = editor.getSelectedText()
selection = selection.split('').reverse().join('')
editor.insertText(selection)
}
}
};Activation commands
To improve performance, Atom packages can be lazy loading. We can tell Atom to
load our package only when certain commands are run by the user. These commands
are called activation commands and are defined in package.json:
"activationCommands": {
"atom-workspace": "sourcefetch:toggle"
},Update this entry to make fetch an activation command.
"activationCommands": {
"atom-workspace": "sourcefetch:fetch"
},Some packages, such as those which modify Atom’s appearance need to be loaded
on startup. In those cases, activationCommands can be omitted entirely.
Triggering commands
Menu items
JSON files inside the menus folder specify which menu items are created for
our package. Let’s take a look at menus/sourcefetch.json:
"context-menu": {
"atom-text-editor": [
{
"label": "Toggle sourcefetch",
"command": "sourcefetch:toggle"
}
]
},The context-menu object lets us define new items in the right-click menu. Each
item is defined by a label to be displayed in the menu and a command to run when
the item is clicked.
"context-menu": {
"atom-text-editor": [
{
"label": "Fetch code",
"command": "sourcefetch:fetch"
}
]
},The menu object in the same file defines custom application menu items created
for the package. We’re going to rename this entry as well:
"menu": [
{
"label": "Packages",
"submenu": [
{
"label": "sourcefetch",
"submenu": [
{
"label": "Fetch code",
"command": "sourcefetch:fetch"
}
]
}
]
}
]Keyboard shortcuts
Commands can also be triggered with keyboard shortcuts, defined with JSON files
in the keymaps directory:
{
"atom-workspace": {
"ctrl-alt-o": "sourcefetch:toggle"
}
}The above lets package users call toggle with Ctrl+Alt+O
on Windows/Linux or Cmd+Alt+O on MacOS.
Rename the referenced command to fetch:
"ctrl-alt-o": "sourcefetch:fetch"Reload Atom by running the Window: Reload command. You should see that the
application and right-click menus are updated, and the reverse functionality
should work as before.
See all code changes for this step in the sourcefetch tutorial repository.
Using NodeJS modules
Now that we’ve made our first code change and learned about Atom package structure,
let’s introduce our first dependency—a module from
Node Package Manager (npm). We will use the request
module to make HTTP requests and download the HTML of a website. This functionality
will be needed later, to scrape StackOverflow pages.
Installing dependencies
Open your command line application, navigate to your package root directory
and run:
npm install --save request@2.73.0
apm installThese commands add the request Node module to our dependencies list and
install the module into the node_modules directory. You should see a new entry
in package.json. The @ symbol tells npm to install
the specific version we will be using for this tutorial. Running apm install
lets Atom know to use our newly installed module.
"dependencies": {
"request": "^2.73.0"
}Downloading and logging HTML to the Developer Console
Import request into our main file by adding an import statement to the top
of lib/sourcefetch.js:
import { CompositeDisposable } from 'atom'
import request from 'request'Now, add a new function, download to the module’s exports, below fetch:
export default {
/* subscriptions, activate(), deactivate() */
fetch() {
...
},
download(url) {
request(url, (error, response, body) => {
if (!error && response.statusCode == 200) {
console.log(body)
}
})
}
}This function uses request to download the contents of a web page and logs
the output to the Developer Console. When the HTTP request completes, our
callback function
will be called with the response as an argument.
The final step is to update fetch so that it calls download:
fetch() {
let editor
if (editor = atom.workspace.getActiveTextEditor()) {
let selection = editor.getSelectedText()
this.download(selection)
}
},Instead of reversing the selected text, fetch now treats the selection as a
URL, passing it to download. Let’s see our changes in action:
- Reload Atom by running the
Window: Reloadcommand. - Open the Developer Tools. To do this, navigate to
View > Developer > Toggle Developer Toolsin the menu. - Create a new file, navigate to
File > New. - Enter and select a URL, for example,
http://www.atom.io. - Run our package command in any of the three ways previously described:

Developer Tools make it easy to debug Atom packages. Any console.log statement
will print to the interactive console, and you can use the Elements tab to
explore the visual structure of the whole application—which is just an HTML
Document Object Model (DOM).
See all code changes for this step in the sourcefetch tutorial repository.
Using Promises to insert downloaded HTML into the editor
Ideally, we would like our download function to return the HTML as a string
instead of just printing page contents into the console. Returning body won’t work,
however, since we get access to body inside of the callback rather than
download itself.
We will solve this problem by returning a Promise
rather than the value itself. Let’s change download to return a Promise:
download(url) {
return new Promise((resolve, reject) => {
request(url, (error, response, body) => {
if (!error && response.statusCode == 200) {
resolve(body)
} else {
reject({
reason: 'Unable to download page'
})
}
})
})
}Promises allow us to return values obtained asynchronously by wrapping asynchronous
logic in a function that provides two callbacks— resolve for returning a
value successfully, and reject for notifying the caller of an error. We call
reject if an error is returned by request, and resolve the HTML otherwise.
Let’s change fetch to work with the Promise returned by download:
fetch() {
let editor
if (editor = atom.workspace.getActiveTextEditor()) {
let selection = editor.getSelectedText()
this.download(selection).then((html) => {
editor.insertText(html)
}).catch((error) => {
atom.notifications.addWarning(error.reason)
})
}
},In our new version of fetch, we get access to the HTML by calling
then on the Promise returned by download. This lets us insert the HTML into
the editor. We also accept and handle any errors returned by calling catch.
We handle errors by displaying a warning notification using the
Atom Notification API.
Let’s see what changed. Reload Atom and run the package command on a selected URL:

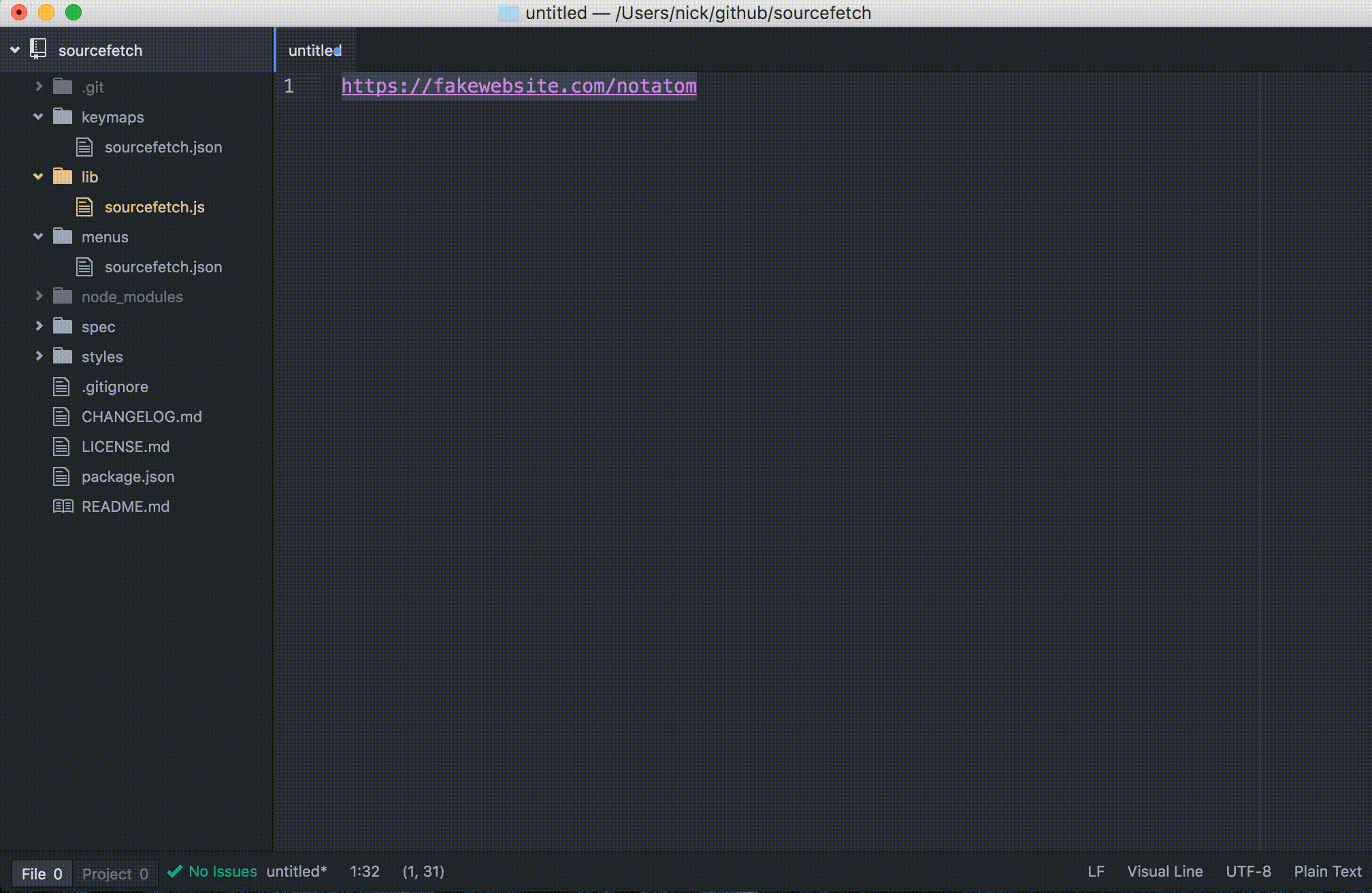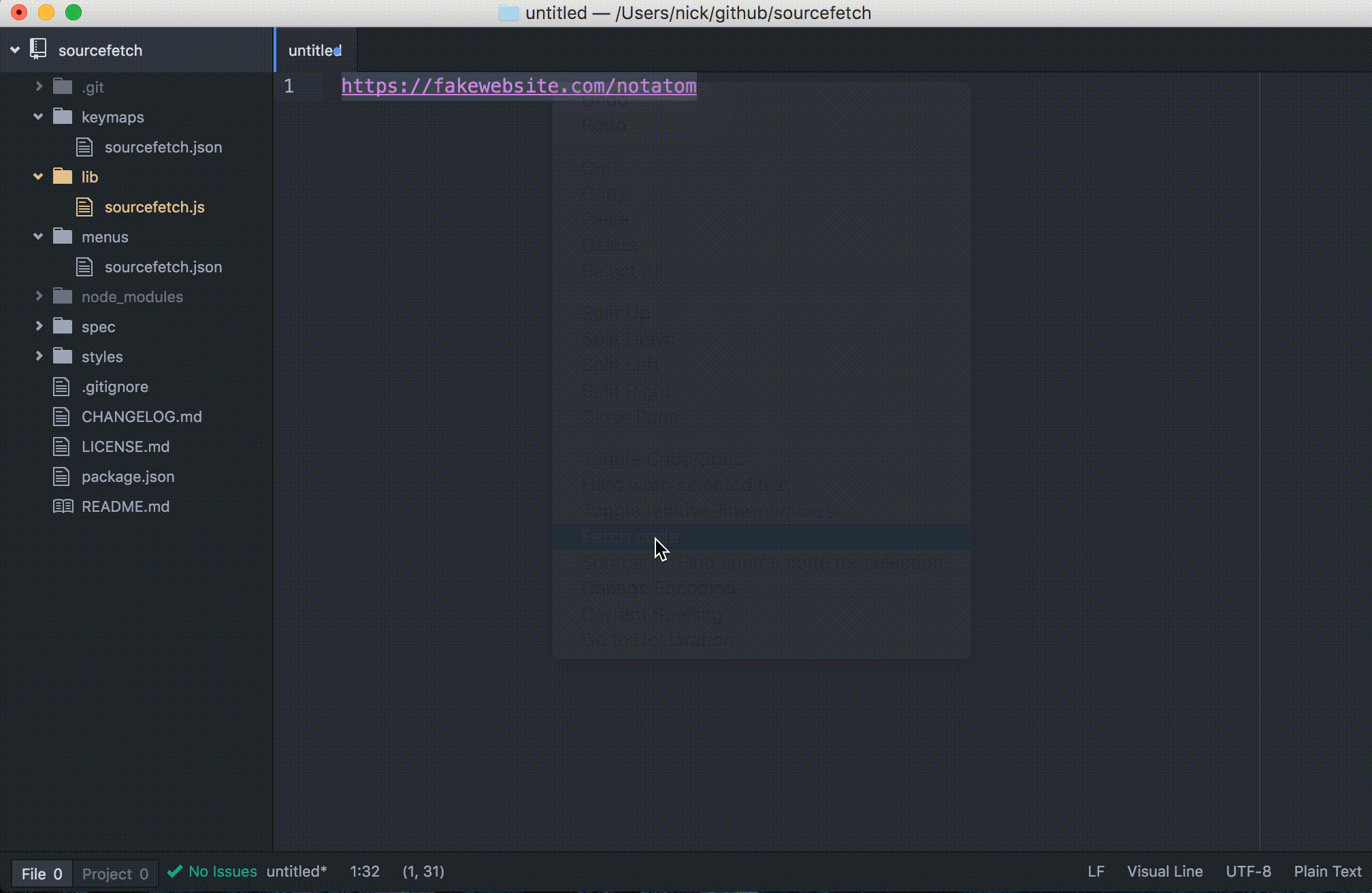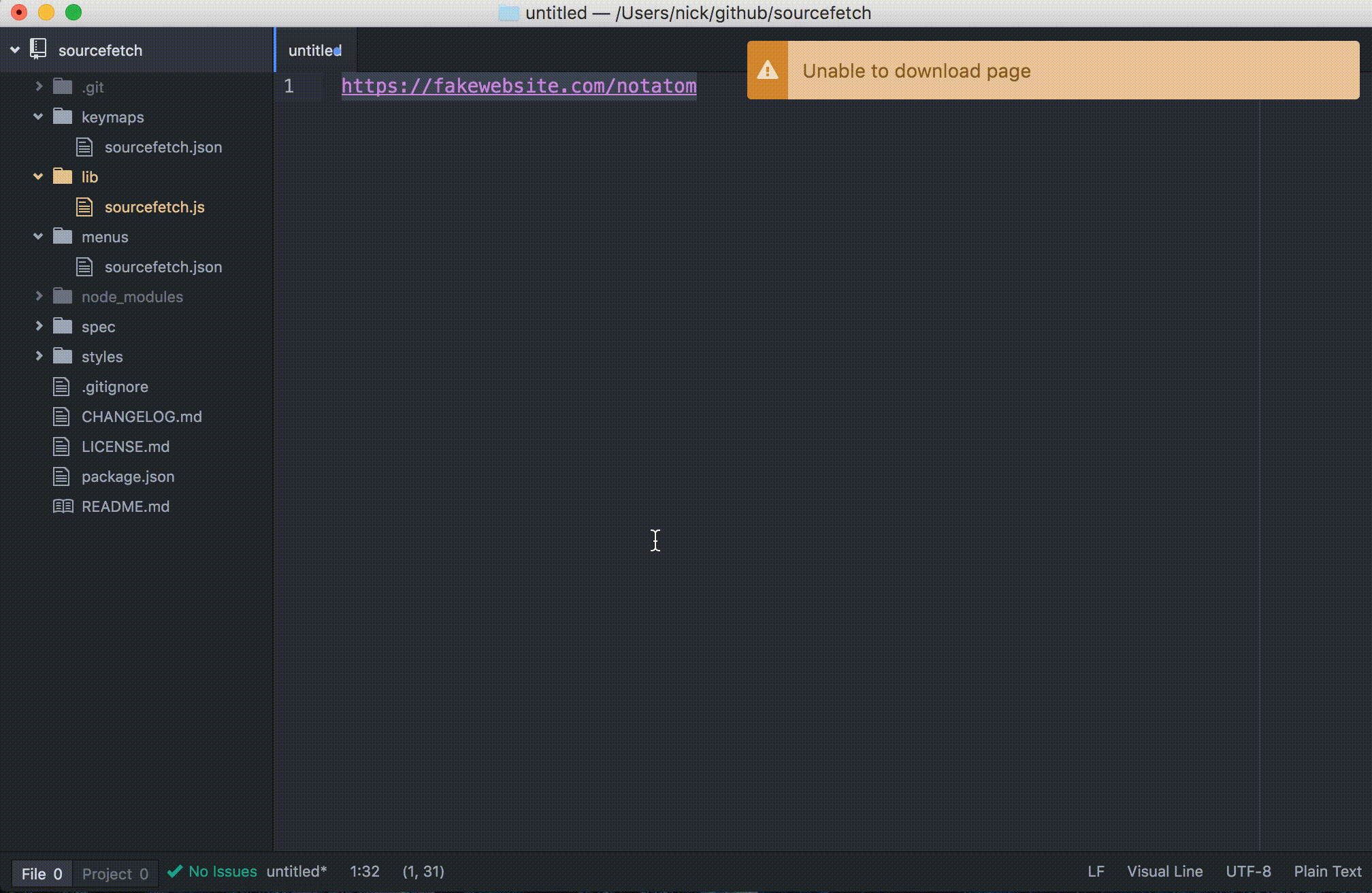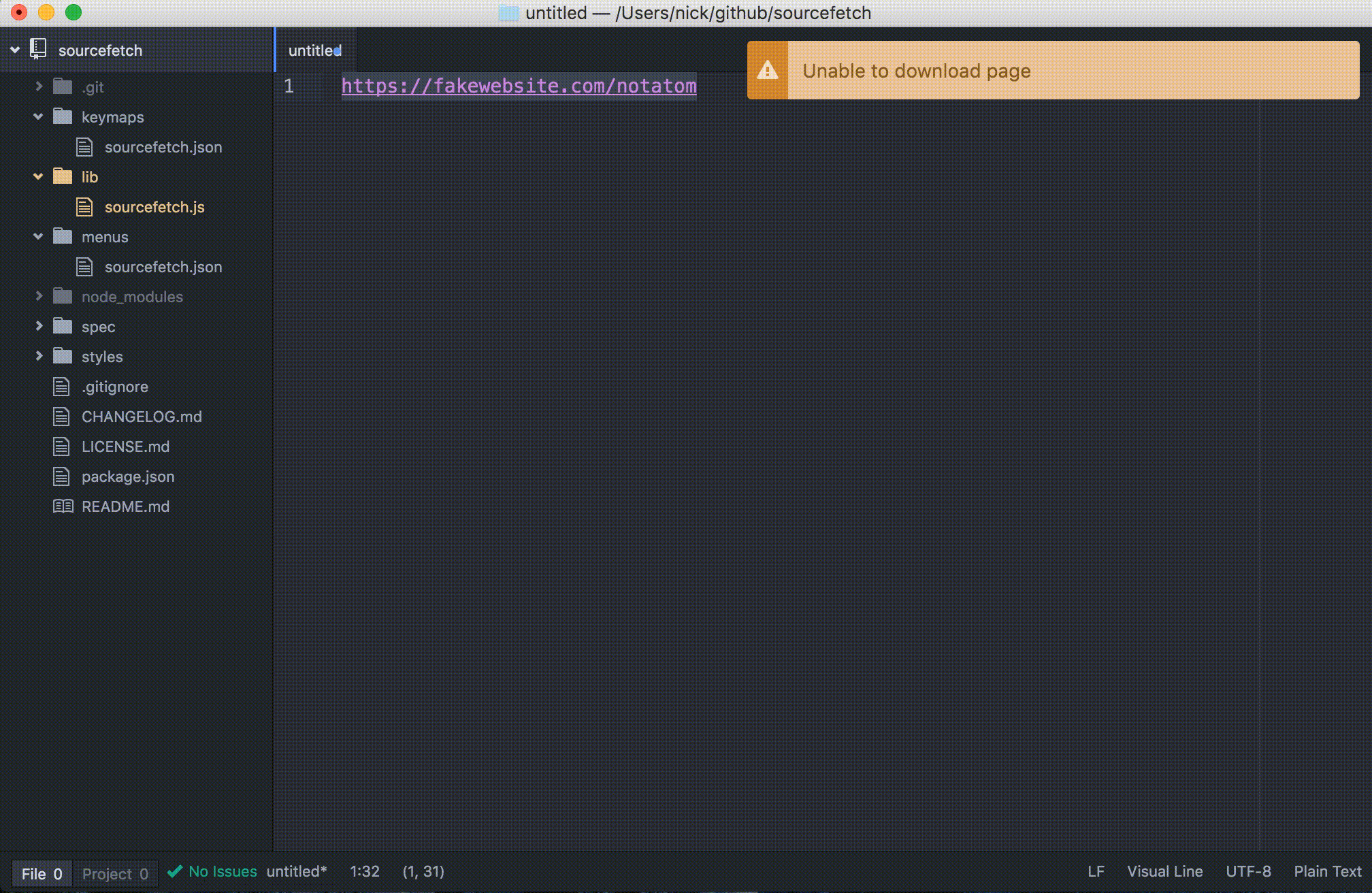
If the command is run on an invalid URL, a warning notification will be displayed:
See all code changes for this step in the sourcefetch tutorial repository.
Building a scraper to extract code snippets from StackOverflow HTML
The next step involves extracting code snippets from the HTML of a
StackOverflow page we obtained in the previous step.
In particular, we’re interested in code from the accepted answer—an answer
chosen to be correct by the question author. We can greatly simplify our
package implementation by assuming any such answer to be relevant and correct.
Constructing a query using jQuery and Chrome Developer Tools
This section assumes you are using the Chrome web
browser. You may be able to follow along using another browser, but instructions
may change.
Let’s take a look at a typical StackOverflow page that contains an accepted
answer with a code snippet. We are going to explore the HTML using Chrome
Developer Tools:
- Open Chrome and navigate to any StackOverflow page containing an accepted
answer with code, such as this hello world example in Python or this question
about reading text from a file in C. - Scroll down to the accepted answer and highlight a section of the code snippet.
- Right click and select
Inspect - Inspect the location of the code snippet within the HTML code using the Elements
browser.
- The accepted answer is denoted by a
divwith classaccepted-answer - Block code snippets are located inside a
preelement - Elements that render the code snippet itself sit inside a
codetag

Now let’s construct a jQuery statement for extracting code snippets:
- Click the Console tab within Developer Tools to access the JavaScript console.
- Type
$('div.accepted-answer pre code').text()into the console and press Enter.
You should see the accepted answer code snippets printed out in the console.
The code we just ran uses a special $ function provided by jQuery. $
accepts a query string to select and return certain HTML elements from the
website. Let’s take a look at how this code works by considering a couple of
intermediate example queries:
$('div.accepted-answer')
> []The above query will match all <div> elements that contain the class
accepted-answer, in our case – just one div.
$('div.accepted-answer pre code')
> [<code>...</code>]Building upon the previous, this query will match any <code> element that
is inside a <pre> element contained within the previously matched <div>.
$('div.accepted-answer pre code').text()
> "print("Hello World!")"The text function extracts and concatenates all text from the list of elements
that would otherwise be returned by the previous query. This also strips out elements
used for syntax highlighting purposes from the code.
Introducing Cheerio
Our next step involves using the query we created to implement a scraping
function using Cheerio, a jQuery
implementation for server-side applications.
Install Cheerio
- Open your command line application, navigate to your package root directory
and run:
npm install --save cheerio@0.20.0
apm installImplement the scraping function
- Add an import statement for
cheerioinlib/sourcefetch.js:
import { CompositeDisposable } from 'atom'
import request from 'request'
import cheerio from 'cheerio'- Now create a new function that extracts code snippets given
StackOverflow HTML, calledscrape:
fetch() {
...
},
scrape(html) {
$ = cheerio.load(html)
return $('div.accepted-answer pre code').text()
},
download(url) {
...
}- Finally, let’s change
fetchto pass downloaded HTML toscrapeinstead
of inserting it into the editor:
fetch() {
let editor
let self = this
if (editor = atom.workspace.getActiveTextEditor()) {
let selection = editor.getSelectedText()
this.download(selection).then((html) => {
let answer = self.scrape(html)
if (answer === '') {
atom.notifications.addWarning('No answer found :(')
} else {
editor.insertText(answer)
}
}).catch((error) => {
console.log(error)
atom.notifications.addWarning(error.reason)
})
}
},Our scraping function is implemented in just two lines because cheerio does
all of the work for us! We create a $ function by calling load with our
HTML string, and use this function to run our jQuery statement and return the
results. You can explore the entire Cheerio API in their
developer documentation.
Testing the updated package
- Reload Atom and run
soucefetch:fetchon a selected StackOverflow URL to
see the progress so far.
If we run the command on a page with an accepted answer, it will be inserted
into the editor:

If we run the command on a page with no accepted answer, a warning
notification will be displayed instead:

Our new iteration of fetch gives us the code snippet within a StackOverflow page
instead of the entire HTML contents. Note that our updated fetch function
checks for the absence of an answer and displays a notification to alert the user.
See all code changes for this step in the sourcefetch tutorial repository.
Implementing Google search to find relevant StackOverflow URLs
Now that we can turn StackOverflow URLs into code snippets, let’s implement
our final function, search, which will return a relevant URL given the
description of a snippet, such as “hello world” or “quicksort”. We will be
using Google search via the unofficial google npm module, which allows us to
search programmatically.
Installing the Google npm module
- Install
googleby opening your command line application at the package root
directory, and run:
npm install --save google@2.0.0
apm installImporting and configuring the module
Add an import statement for google at the top of lib/sourcefetch.js:
import google from "google"We will configure the library to limit the number of results returned
during search. Add the following line below the import statement to limit
returned results to just the top one.
google.resultsPerPage = 1Implementing the search function
Next, let’s implement our search function itself:
fetch() {
...
},
search(query, language) {
return new Promise((resolve, reject) => {
let searchString = `${query} in ${language} site:stackoverflow.com`
google(searchString, (err, res) => {
if (err) {
reject({
reason: 'A search error has occured :('
})
} else if (res.links.length === 0) {
reject({
reason: 'No results found :('
})
} else {
resolve(res.links[0].href)
}
})
})
},
scrape() {
...
}The code above searches Google for a StackOverflow page relevant to the given
query and programming language, returning the URL of the top result. Let’s take
a look at how it works:
let searchString = `${query} in ${language} site:stackoverflow.com`We construct the search string using the query entered by the user and
the current language selected. For example, if the user types
“hello world” while editing Python, the query will be hello world in python site:stackoverflow.com. The final part of the string
is a filter provided by Google Search that lets us limit results
to those linked to StackOverflow.
google(searchString, (err, res) => {
if (err) {
reject({
reason: 'A search error has occured :('
})
} else if (res.links.length === 0) {
reject({
reason: 'No results found :('
})
} else {
resolve(res.links[0].href)
}
})We wrap the call to google inside a Promise so that we can return our URL
asynchronously. We propagate any errors returned by the library, also returning
an error when there are no results available. We resolve the URL of
the top result otherwise.
Updating fetch to use search
Our final step is to update fetch to use search:
fetch() {
let editor
let self = this
if (editor = atom.workspace.getActiveTextEditor()) {
let query = editor.getSelectedText()
let language = editor.getGrammar().name
self.search(query, language).then((url) => {
atom.notifications.addSuccess('Found google results!')
return self.download(url)
}).then((html) => {
let answer = self.scrape(html)
if (answer === '') {
atom.notifications.addWarning('No answer found :(')
} else {
atom.notifications.addSuccess('Found snippet!')
editor.insertText(answer)
}
}).catch((error) => {
atom.notifications.addWarning(error.reason)
})
}
}Let’s take a look at what changed:
- Our selected text is now treated as the
queryentered by the user. - We obtain the
languageof the current editor tab using the
TextEditor API - We call
searchto obtain a URL, which we access by callingthenon the
resulting Promise - Instead of calling
thenon the Promise returned bydownload, we instead
return the Promise itself and chain anotherthencall onto the original call.
This helps us avoid callback hell
See all code changes for this step in the sourcefetch tutorial repository.
Testing the final plugin
And we’re done! See the final plugin in action by reloading Atom and running
our package command on a problem description, and don’t forget to select a language
in the bottom-right corner.
Next steps
Now that you know the basics of hacking Atom, feel free to practice what you’ve learned by forking the sourcefetch repository and adding your own features.
Tags:
Written by

Related posts

What’s coming to our GitHub Actions 2026 security roadmap
A look at GitHub Actions’ 2026 roadmap, outlining how secure defaults, policy controls, and CI/CD observability harden the software supply chain end to end.
Updates to GitHub Copilot interaction data usage policy
From April 24 onward, interaction data—specifically inputs, outputs, code snippets, and associated context—from Copilot Free, Pro, and Pro+ users will be used to train and improve our AI models unless they opt out.

GitHub availability report: February 2026
In February, we experienced six incidents that resulted in degraded performance across GitHub services.