Pachyderm and the power of GitHub Actions: MLOps meets DevOps
This is a guest post by Jimmy Whitaker, senior data science evangelist at Pachyderm In the last few years, DevOps has begun to shift—from a culture of continuous integration and…

This is a guest post by Jimmy Whitaker, senior data science evangelist at Pachyderm
In the last few years, DevOps has begun to shift—from a culture of continuous integration and continuous deployment (CI/CD) best practices to leveraging Git-based techniques to manage software deployments. This transition has made software less error prone, more scalable, and has increased collaboration by making DevOps more developer-centric.
At its heart, this simplification lets developers use the same powerful version control system they’re used to with Git as a way to deliver infrastructure as code, documentation, and even Kubernetes configurations. It works by using Git as a single source of truth, letting you build robust declarative apps and infrastructure with ease. But when it comes to machine learning applications, DevOps gets much more complex.
The difference between MLOps and DevOps
The kinds of problems we face in machine learning are fundamentally different than the ones we face in traditional software coding. Functional issues, like race conditions, infinite loops, and buffer overflows, don’t come into play with machine learning models. Instead, errors come from edge cases, lack of data coverage, adversarial assault on the logic of a model, or overfitting. Edge cases are the reason so many organizations are racing to build AI Red Teams to diagnose problems before things go horribly wrong.
It’s simply not enough to port your CI/CD and infrastructure code to machine learning workflows and call it done. Handling this new generation of machine learning operations (MLOps) problems requires a brand new set of tools that focus on the gap between code-focused operations and MLOps. The key difference is data. We need to version our data and datasets in tandem with the code. That means we need tools that specifically focus on data versioning, model training, production monitoring, and many others unique to the challenges of machine learning at scale.
Pachyderm: Enabling DevOps for data
Luckily, we have a strong tool for MLOps that does seamless data version control: Pachyderm. When we link the power of Pachyderm to our declarative Git-based workflows, we can bring the smooth flow of CI/CD to the world of machine learning models.
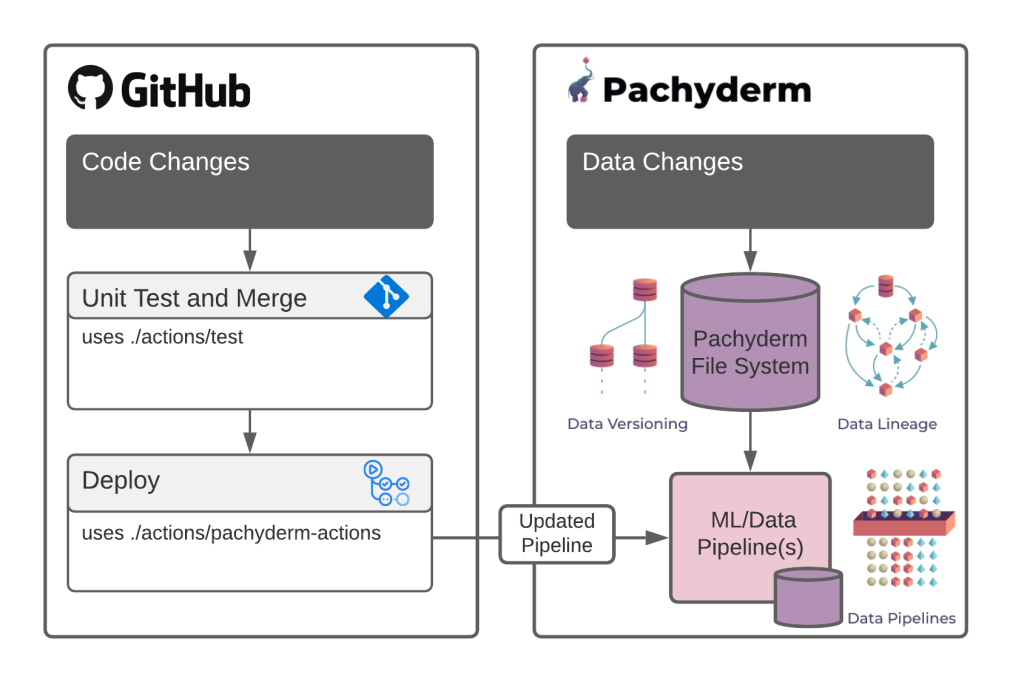
We’ll use two key tools to combine our existing CI/CD tooling and MLOps:
- GitHub Actions builds powerful, flexible automation directly into the developer workflow. Actions can be triggered by nearly any GitHub event, such as pull requests, releases, push events, etc. While the triggered workflow can be almost anything, in the context of this post, it will most commonly be a build, CI/CD step, or release.
- Pachyderm delivers data versioning and lineage to our data science project. It provides Git-like functionality, baked right into a version-controlled file system. This gives you the ability to control your binary assets, both big and small, and to create processing pipelines triggered by data changes.
Integrating Pachyderm with Actions serves as a reliable way to introduce data-driven workflows into the existing CI/CD workflow. It lets you push code along with any dependencies to a Pachyderm cluster to process data when a GitHub event is triggered.
The Pachyderm action performs the following steps:
- Build the repository’s code (in this case, your machine learning code) into a Docker image.
- Tag the Docker image with
github commit. - Push the image to your Docker registry.
- Build a GitHub runner Docker image containing your Pachyderm cluster credentials.
- The Runner image will then update the pipeline specification with the new tag.
- Submit the updated pipeline to the Pachyderm cluster.
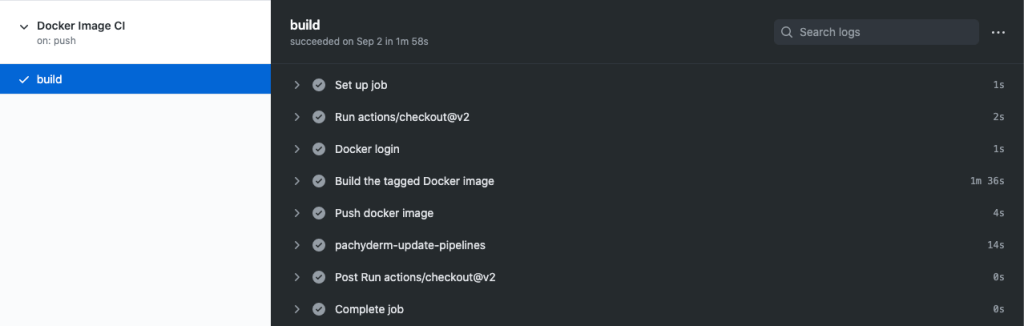
Getting Started
You can learn how to use Actions with Pachyderm in our full-fledged tutorial, where we added an action to our regression example. The action updates the running pipeline in our Pachyderm cluster whenever code is pushed to the main branch. The following code block can be modified to get started.
- uses: pachyderm/pachyderm-actions@master
env:
PACHYDERM_CLUSTER_URL: ${{ secrets.PACHYDERM_URL }}
PACHYDERM_TOKEN: ${{ secrets.PACHYDERM_TOKEN }}
DOCKER_IMAGE_NAME: ${{ secrets.DOCKER_IMAGE }}
PACHYDERM_PIPELINE_FILES: <list pipeline JSON files to be updated>Two main files dictate the behavior of our action. The push.yaml file serves as the workflow definition, where the steps above are defined for the push event, and the action definition, action.yaml, where we implement the connector that updates the Pachyderm pipeline.
Synchronizing code development with Pachyderm pipelines used to require manual intervention. An admin or coder would build, push, and update the cluster when pipeline changes were made, or rely on clunky watcher scripts to make these changes. With Pachyderm and Actions, the MLOps process can be automated. Engineers and data scientists can write their machine learning code, and it seamlessly and automatically gets deployed to a production-scale data workflow. Your pipelines will update whenever code is pushed, allowing both Pachyderm and GitHub to do what they do best.
Versioned code meets versioned data
The combination of DevOps and MLOps dramatically increases reliability of machine learning models. By combining the simplicity of Actions and Pachyderm’s data processing power into one comprehensive CI/CD workflow, you can finally unify your versioned code with your versioned data—and know beyond a shadow of a doubt that they’re in perfect sync from start to finish.
Check out the Pachyderm Pipeline Updater action or see our example to learn how you can integrate MLOps into your machine learning workflows. For more information about Pachyderm, visit the docs page or join our Slack channel.
You can also follow along with this step-by-step example on Pachyderm Hub.
Tags:
Written by

Related posts
Automate repository tasks with GitHub Agentic Workflows
Discover GitHub Agentic Workflows, now in technical preview. Build automations using coding agents in GitHub Actions to handle triage, documentation, code quality, and more.

Level up design-to-code collaboration with GitHub’s open source Annotation Toolkit
Prevent accessibility issues before they reach production. The Annotation Toolkit brings clarity, compliance, and collaboration directly into your Figma workflow.

How to use the GitHub and JFrog integration for secure, traceable builds from commit to production
Connect commits to artifacts without switching tools.