Stretching Spokes
GitHub’s Spokes system stores multiple distributed copies of Git repositories. This article discusses how we got Spokes replication to span widely separated datacenters. Background: Spokes GitHub developed a system called…
GitHub’s Spokes system stores multiple distributed copies of Git repositories. This article discusses how we got Spokes replication to span widely separated datacenters.
Background: Spokes
GitHub developed a system called Spokes to store multiple replicas of our users’ Git repositories and to keep the replicas in sync. Spokes uses several strategies to ensure that every Git update is safely replicated to all of the replicas in most cases and to at least a quorum of replicas in every case. Spokes does replication at the Git application level, replacing an older system that did replication at the filesystem block level.
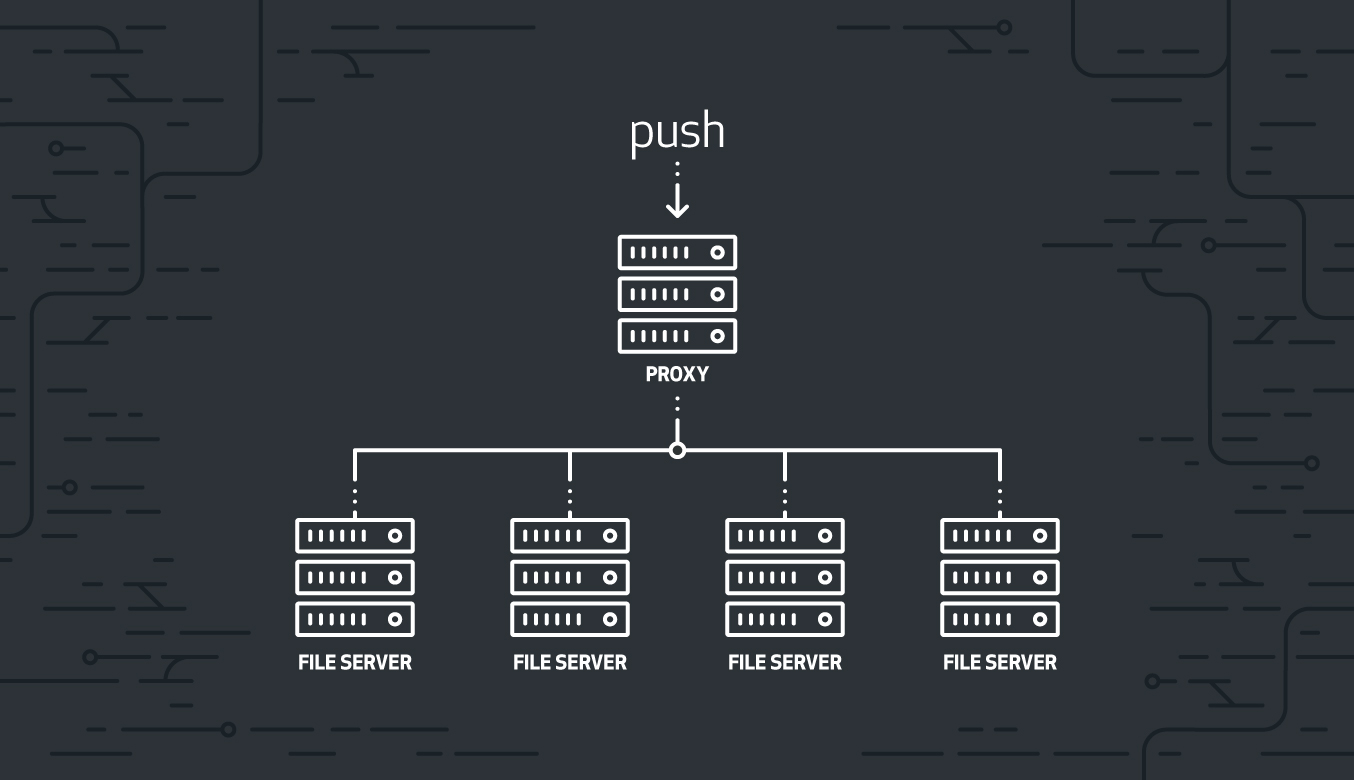
Every push to a Git repository goes through a proxy, which transparently replicates it to multiple fileservers. Early versions of Spokes required low-latency communication between the proxy and all of the replicas to sustain high update rates. Therefore, the replicas had to be located relatively close to each other.
But there are well-known advantages to being able to place data replicas distant from each other:
- The further replicas are spread out, the more likely that some of them will survive a disaster affecting a large geographic area (e.g. hurricane, earthquake, alien invasion).
- If replicas are available in multiple regions, Git read requests can be directed to the nearest replica, reducing transit time.
This article explains why latency was a problem in the first place, how we overcame the problems to allow continent-wide distributed storage of Git data, and what improvements this has brought our users.
Distant replicas. What’s all the fuss?
Before Spokes, we used DRBD filesystem block-level replication to keep repositories duplicated. This system was very sensitive to latency, so we were forced to keep fileserver replicas right next to each other. This was obviously not ideal, and getting off of it was the motivation that drove the initial development of Spokes.
As soon as we had Spokes running, we started pushing the limits of how distant Spokes replicas could be from each other. The farther apart the replicas, the longer the latency between them. Higher latency limits the maximum rate of Git reference updates that Spokes can sustain for each repository.
It might seem surprising that we are concerned about this. A single repository doesn’t get pushed to that often, does it?
Well, most users don’t push often at all. But if you host nearly 70 million repositories, you will find that some projects use workflows that you never would have foreseen. We work very hard to make GitHub Just Work for all but the most ludicrous use cases.
Also, GitHub generates a surprisingly large number of reference updates for its own internal bookkeeping purposes. For example, every time a user pushes to a pull request branch, we have to record the push itself, we might need to sync that branch to the target repository, and we compute a test merge and test rebase of the pull request, creating references for each of those. And if a user pushes to a project’s master branch, we compute a test merge and a test rebase for every active pull request whose target is master. In some repositories, this can trigger updates of more than a hundred references.
It is crucial to the workability of Spokes with distant replicas that reference updates be sufficiently quick even with high latency. Specifically, we’d like to support at least a few updates per second in a single repository. This translates to a budget of a few hundred milliseconds per update. And remember that whatever we do to optimize writes mustn’t slow down reads, which outnumber writes by about 100:1.
Reducing round-trips
Due to the speed of light and other annoying facts, every round-trip communication to a distant replica takes time. For example, a network round-trip across the continental US takes something like 60-80 milliseconds. It wouldn’t take very many round trips to use up our time budget.
We use the three-phase commit protocol to update the replicas and additionally use the replicas as a distributed lock to ensure that the database is updated in the correct order. All in all, this costs four round-trips to the distant replicas; expensive, but not prohibitive. (We have plans to reduce the number of round trips through the use of a more advanced consensus algorithm.)
As much as possible, we also make use of the time spent waiting on the network to get other work done. For example, while one replica is acquiring its lock, another replica might be computing a checksum and the coordinator might be reading from the database.
Git reference update transactions
Three-phase commit is a core part of keeping the replicas in sync. Implementing it requires each of the replicas to be able to answer the question “can you carry out the following reference updates?”, and then to either commit or roll back the transaction based on the coordinator’s instructions. To make this possible, we implemented transactions for Git reference updates in the open source Git project (these are exposed, for example, via git update-ref --stdin), and we did a lot of work to make sure that the results of a transaction are deterministic across replicas. First Git acquires all necessary local reference locks, then it verifies that the old values were as expected and that the new values make sense. If everything is OK, the tentative transaction is committed; otherwise, it is rolled back in its entirety.
Faster Git reference updates
Aside from the network latency, we also have to consider the time that it takes to update a Git reference on a single replica. Therefore, we have also implemented a number of speedups to reference-related operations. These changes have also been contributed back to the open source Git project.
Using checksums to compare replicas
To summarize the state of a replica, we use a checksum over the list of all of its references and their values, plus a few other things. We call this the “Spokes checksum”. If two replicas have the same Spokes checksums, then they definitely hold the same logical contents. We compute the Spokes checksum for every replica after every update as an extra check that they are all in sync.
In a busy repository with a lot of references, computing the Spokes checksum from scratch is relatively expensive, and would limit the maximum rate of reference updates. Therefore, we compute the Spokes checksum incrementally whenever possible. We define it to be the exclusive-or of the hash of each (refname, value) pair. So when a reference is updated, we can update this part of the checksum via
new_checksum = old_checksum XOR hash(refname, oldvalue) XOR hash(refname, newvalue)This makes it cheap to compute the new Spokes checksum if we know the old one.
Prioritizing user-initiated updates
Even with all of these optimizations, a reference update still costs about a third of a second. This is fine in most situations. But in the case that we mentioned earlier, where an update to master might cause a cascade of more than a hundred bookkeeping reference updates, processing the updates could keep the repository busy for something like 30 seconds. If these updates would block user-initiated reference updates for such a long time, user requests would be highly delayed or even time out.
We’ve gotten around this problem by coalescing some of the bookkeeping updates into fewer transactions, and by giving user-initiated updates priority over bookkeeping updates (which aren’t time-critical).
Geo-replication for GitHub.com and GitHub Enterprise
The most tangible benefit that Spokes brings to GitHub users is that Git reads (fetches and clones) can often be served by a nearby Spokes replica. Since Spokes can quickly figure out which replicas are up to date, it routes reads to the closest replica that is in sync. This aspect of Spokes is already speeding up transfers for many users of GitHub.com, and it will only improve with time as we add replicas in more geographical areas.
GitHub Enterprise, the on-premises version of GitHub, now also supports Geo-replication, using the same underlying Spokes technology. Users close to such a replica can enjoy faster Git transfers, even if they are distant from the main GHE host(s). These replicas are configured to be non-voting, so that Git pushes to the main GHE hosts continue to work even if the Geo-replicated hosts become temporarily unreachable.
Conclusion
Spokes’s design, plus careful optimization of the performance of distributed reference updates, now allows Spokes to replicate Git repositories over long distances. This improves robustness, speed, and flexibility for both GitHub.com and GitHub Enterprise.
Written by

Related posts
The uphill climb of making diff lines performant
The path to better performance is often found in simplicity.
Continuous AI for accessibility: How GitHub transforms feedback into inclusion
AI automates triage for accessibility feedback, allowing us to focus on fixing barriers—turning a chaotic backlog into continuous, rapid resolutions.
How we rebuilt the search architecture for high availability in GitHub Enterprise Server
Here’s how we made the search experience better, faster, and more resilient for GHES customers.