Introducing DGit
Edit: DGit is now called Spokes GitHub hosts over 35 million repositories and over 30 million Gists on hundreds of servers. Over the past year, we’ve built DGit, a new…
Edit: DGit is now called Spokes
GitHub hosts over 35 million repositories and over 30 million Gists on
hundreds of servers. Over the past year, we’ve built DGit, a new
distributed storage system that dramatically improves the availability,
reliability, and performance of serving and storing Git content.
DGit is short for “Distributed Git.” As many readers already know, Git
itself is distributed—any copy of a Git repository contains every file,
branch, and commit in the project’s entire history. DGit uses
this property of Git to keep three copies of every repository,
on three different servers. The design of DGit keeps repositories fully
available without interruption even if one of those servers goes down. Even
in the extreme case that two copies of a repository become unavailable at
the same time, the repository remains readable; i.e., fetches, clones, and
most of the web UI continue to work.
DGit performs replication at the application layer, rather than at the disk
layer. Think of the replicas as three loosely-coupled Git repositories kept
in sync via Git protocols, rather than identical disk images full of
repositories. This design gives us great flexibility to decide where to
store the replicas of a repository and which replica to use for read
operations.
If a file server needs to be taken offline, DGit automatically determines
which repositories are left with fewer than three replicas and creates new
replicas of those repositories on other file servers. This “healing” process
uses all remaining servers as both sources and destinations. Since healing
throughput is N-by-N, it is quite fast. And all this happens
without any downtime.
DGit uses plain Git
Most end users store their Git repositories as objects, pack files, and
references in a single .git directory. They access the repository using
the Git command-line client or using graphical clients like GitHub Desktop
or the built-in support for Git in IDEs like Visual Studio. Perhaps it’s
surprising that GitHub’s repository-storage tier, DGit, is built using the same
technologies. Why not a SAN? A distributed file system? Some other magical
cloud technology that abstracts away the problem of storing bits durably?
The answer is simple: it’s fast and it’s robust.
Git is very sensitive to latency. A simple git log or git blame might
require thousands of Git objects to be loaded and traversed sequentially. If there’s any
latency in these low-level disk accesses, performance suffers dramatically.
Thus, storing the repository in a distributed file system is not viable. Git
is optimized to be fast when accessing fast disks, so the DGit file servers
store repositories on fast, local SSDs.
At a higher level, Git is also optimized to exchange updates between Git
repositories (e.g., pushes and fetches) over efficient protocols.
So we use these protocols to keep the DGit replicas in sync.
Git is a mature and well-tested technology. Why reinvent the wheel
when there is a Formula One racing car already available?
It has always been GitHub’s philosophy to use Git on our servers in a manner
that is as close as possible to how Git is used by our users. DGit continues
this tradition. If we find performance bottlenecks or other problems, we
have several core Git and libgit2 contributors
on staff who fix the problems and contribute the fixes to the open-source
project for everybody to use. Our level of experience and expertise with Git
helped make it the obvious choice to use for DGit replication.
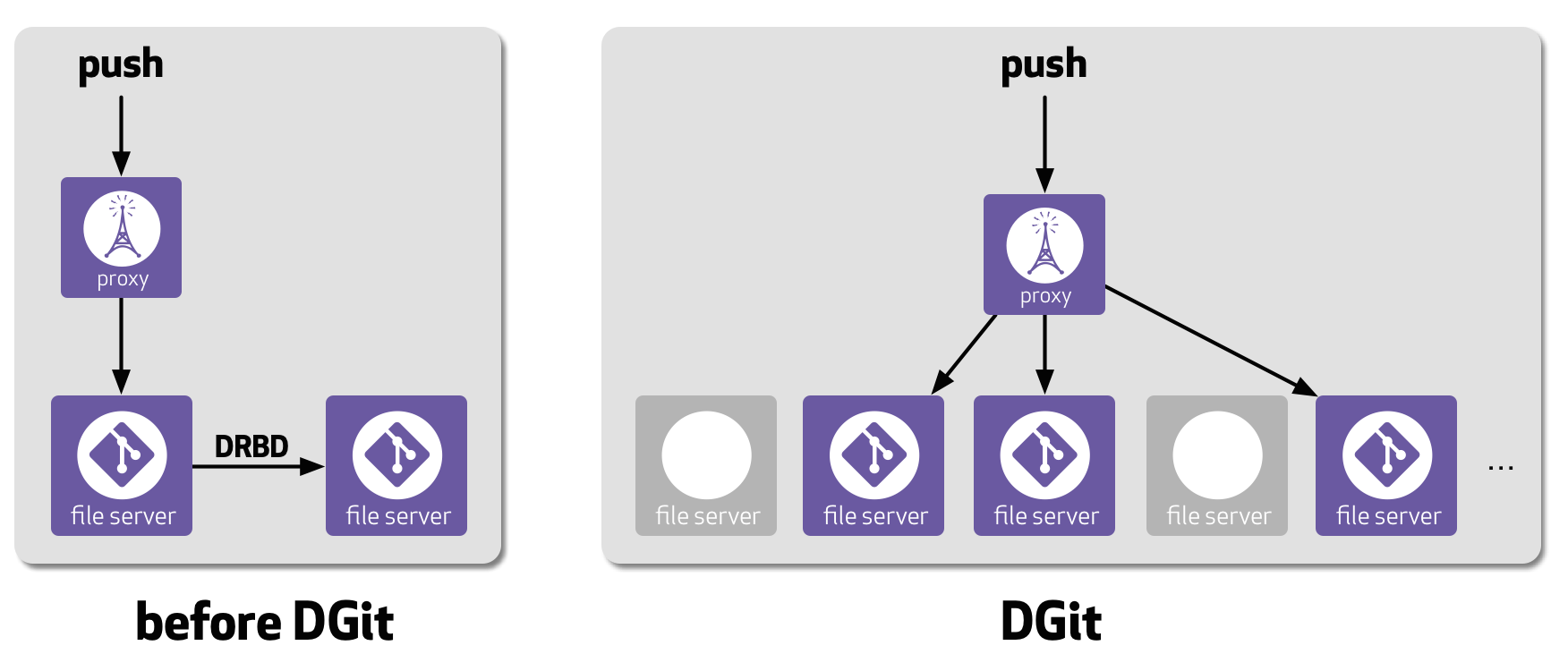
GitHub architecture, before and after
Until recently, we kept copies of repository data using off-the-shelf,
disk-layer replication technologies—namely, RAID and
DRBD. We organized our file servers in
pairs. Each active file server had a dedicated, online spare
connected by a cross-over cable. Each disk had four copies: two
copies on the main file server, using RAID, and another two copies on that
file server’s hot spare, using DRBD. If anything went wrong with a file
server—e.g., hardware failure, software crash, or an overload situation—a
human would confirm the fault and order the spare to take over. Thus, there
was a good level of redundancy, but the failover process required manual
intervention and inevitably caused a little bit of downtime for the
repositories on the failed server. To make such incidents as rare as
possible, we have always stored repositories on specialized, highly reliable
servers.
Now with DGit, each repository is stored on three servers chosen
independently in locations distributed around our large pool of
file servers. DGit automatically selects the servers to host each repository,
keeps those replicas in sync, and picks the best server to handle each
incoming read request. Writes are synchronously streamed to all three
replicas and are only committed if at least two replicas confirm success.
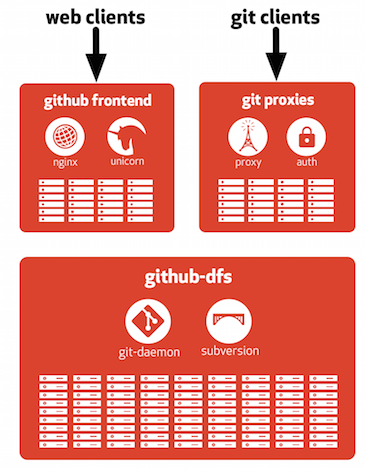
GitHub now stores repositories in a cluster called github-dfs—dfs is short
for “DGit file server.” The repositories are stored on
local disks on these file servers and are served up by Git and libgit2.
The clients of this cluster include the web front end and the proxies that
speak to users’ Git clients.
DGit benefits
DGit delivers many advantages both to GitHub users and to the
internal GitHub infrastructure team. It is also a key foundation that will
enable more upcoming innovations.
-
File servers no longer have to be deployed as pairs of identical servers,
located near each other, and connected one-to-one by crossover cables. We
can now use a pool of heterogeneous file servers in whatever spatial
configuration is best. -
When an entire server fails, replacing it used to be urgent, because its
backup server was operating with no spare. A two-server outage could take
hundreds of thousands of repositories offline. Now when a server fails, DGit
quickly makes new copies of the repositories that it hosted and
automatically distributes them throughout the cluster. -
Routing around failure gets much less disruptive. Rather than having
to reboot and resynchronize a whole server, we just stop routing traffic
to it until it recovers. It’s now safe to reboot production servers, with
no transition period. Because server outages are less disruptive in
DGit, we no longer have to wait for humans to confirm an outage; we can
route around it immediately. -
We no longer need to keep hot-spare file servers that sit mostly idle. In
DGit, every CPU and all memory is available for handling user traffic. While
write operations like pushes must go to every replica of a repository, read
operations can be served from any replica. Since read operations far
outnumber writes, every repository can now handle nearly three times the
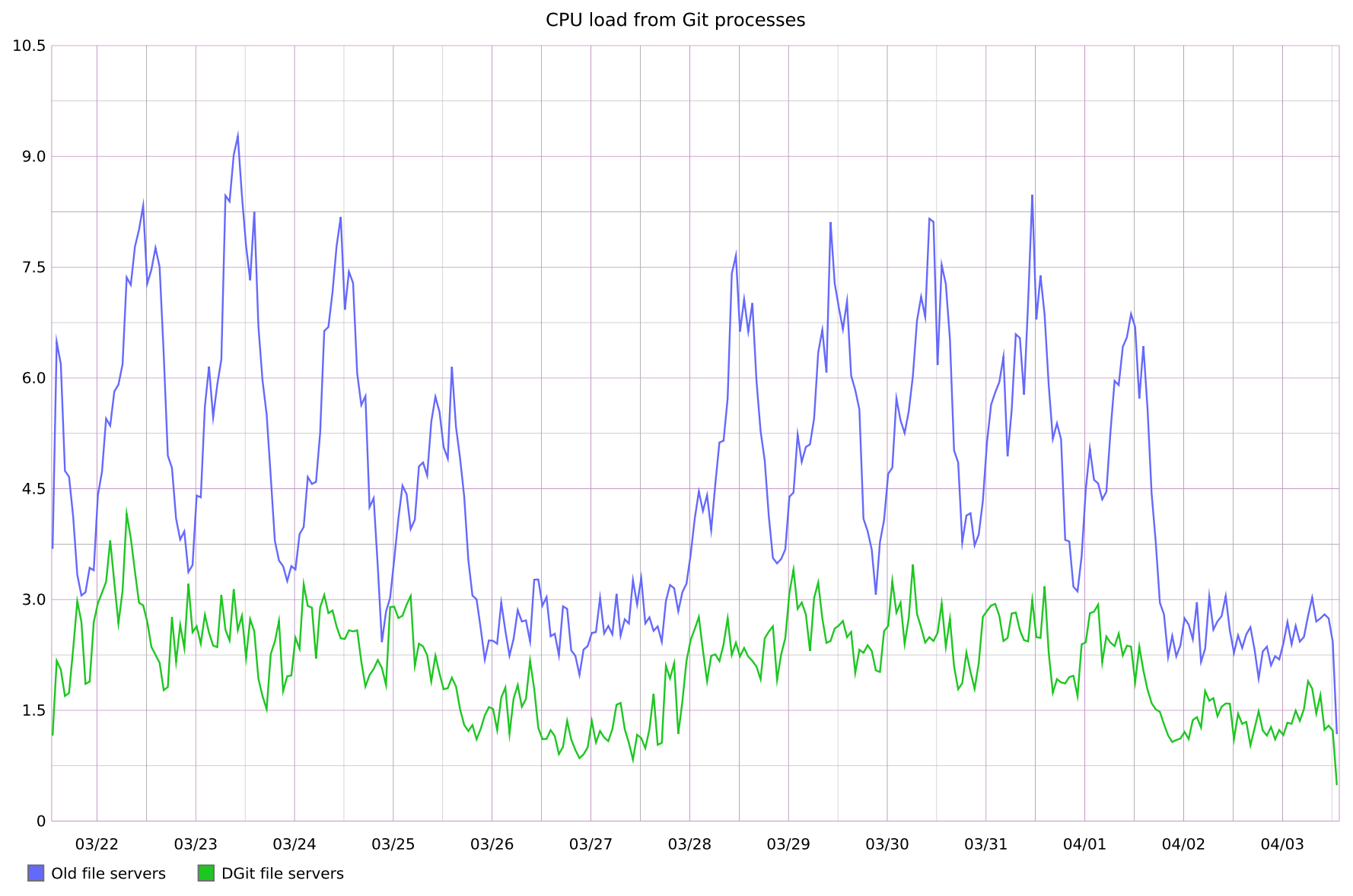
traffic it could previously. The graph below shows the CPU load due to
gitprocesses on old file servers (blue) and on DGit servers (green).
The blue line is the average of only the active servers; their hot spares
are not included. The load on the DGit servers is lower: approximately
three times lower at the peaks, and roughly two times lower at the
troughs. The troughs don’t show a 3x improvement because all the file
servers have background maintenance tasks that cannot be divided among the
replicas.
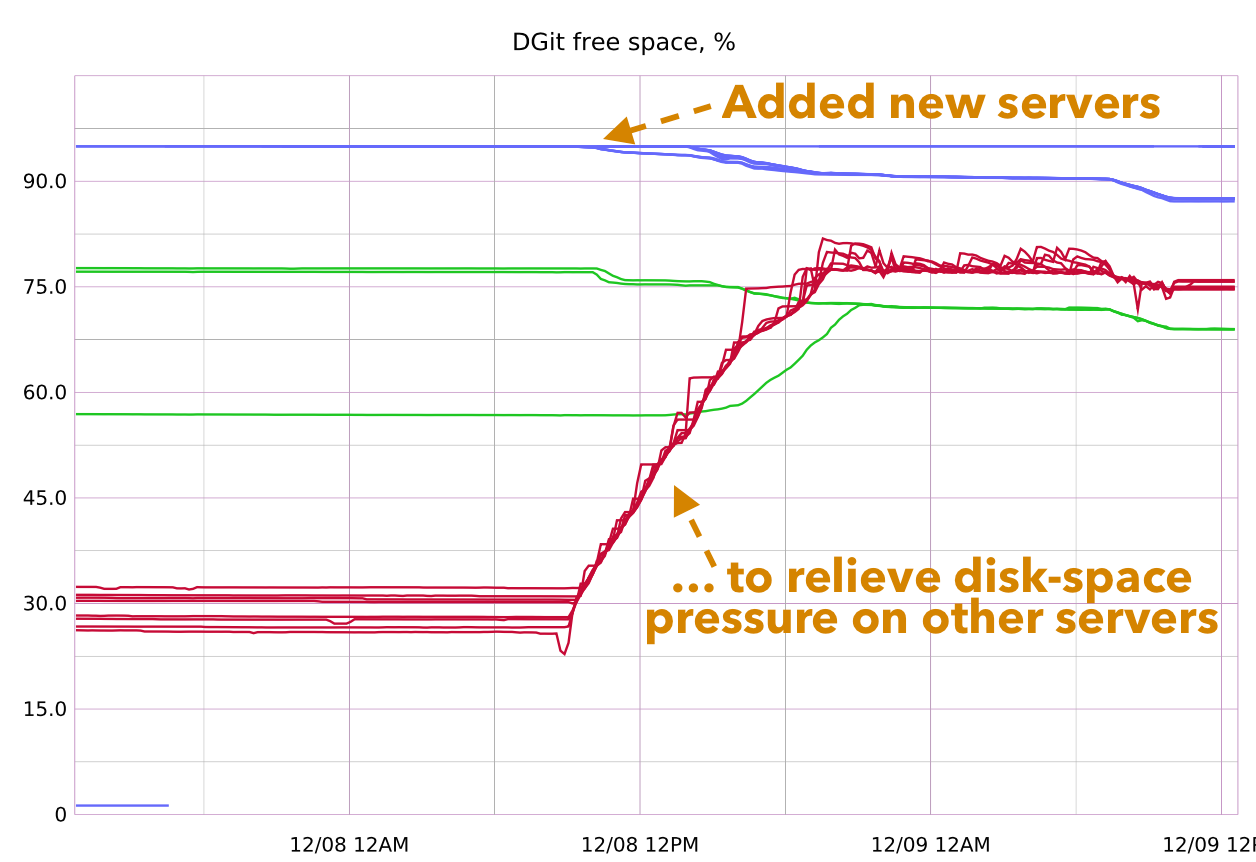
- DGit automatically balances disk and CPU hot spots. Adding servers
requires no planning at all: DGit simply moves existing repositories, at
random, to the new servers until disk space and CPU load are back in
balance. As existing repositories expand or shrink, DGit moves them to
keep disk space balanced. As they become more or less popular, DGit
shifts load to alleviate CPU and memory hot spots. In the graph below,
one cluster of DGit servers, shown in red, was mostly full until we added
a new cluster of servers with much larger disks, shown in blue, to relieve
the disk-space pressure. A third cluster, in green, had two servers
receiving repositories and one server relinquishing them. Moving
repositories around continued until all servers had a similar fraction of
their disk space free.
-
DGit reduces fate sharing among repositories. Prior to DGit, a fixed set
of repositories were stored together on a single server and on that server’s
spare. If one repository was too big, or too expensive, or too popular, the
other repositories on that file server could become slow. In DGit, those
other repositories can be served from their other replicas, which are very
unlikely to be on the same servers as the other replicas of the busy
repository. -
The decoupling of replicas means we can put replicas of a repository in
different availability zones, or even in different data centers.
Availability is improved, and we can (eventually) serve users’ content from
servers geographically close to those users.
Rollout
DGit is a big change, and so we’ve been rolling it out gradually. The most
complicated aspect of DGit is that replication is no longer transparent:
every repository is now stored explicitly on three servers,
rather than on one server with an automatically synchronized hot spare.
Thus, DGit must implement its own
serializability, locking, failure detection, and resynchronization,
rather then relying on DRBD and the RAID controller to keep the copies in
sync. Those are rich topics that we’ll explore in later posts; suffice it to
say, we wanted to test them all thoroughly before relying on DGit to store
customer data. Our deployment progressed over many steps:
- We moved the DGit developers’ personal repositories first.
- We moved some private, GitHub-owned repositories that weren’t part of
running the website. We opened an issue in each repository first, asking
for our colleagues’ permission. That was both a polite heads-up and a way
to begin explaining DGit to the rest of GitHub. - We moved most of the rest of GitHub’s private repositories.
- We stopped moving repositories for about three months while we conducted
extensive testing, automated DGit-related processes, documented DGit at the
operations level, and (ahem) fixed the occasional bug. - After three months of stability, we moved most GitHub-owned public
repositories, along with forks of those repositories owned by outside users.
For example, Linguist is owned by
GitHub, but its roughly 1,500 forks are not. Hosting public repositories
tested DGit’s ability to handle large repository networks and higher traffic
loads. - We started to move public repositories not owned by GitHub. We immediately
went for busy repositories with lots of forks:
Ruby,
Rails,
Bootstrap,
D3,
and on and on, drawing from GitHub’s
showcases and trending
repositories. We aimed to get as much traffic and as many different
usage patterns into DGit as we could, while still hand-picking a limited
number of repositories. - Six months after we first moved our own repositories, we were
satisfied that DGit worked well enough to host the site, and we began
moving repositories in bulk.
During the rollout phase we routinely powered down servers, sometimes
several at once, while they were serving live production traffic. User
operations were not affected.
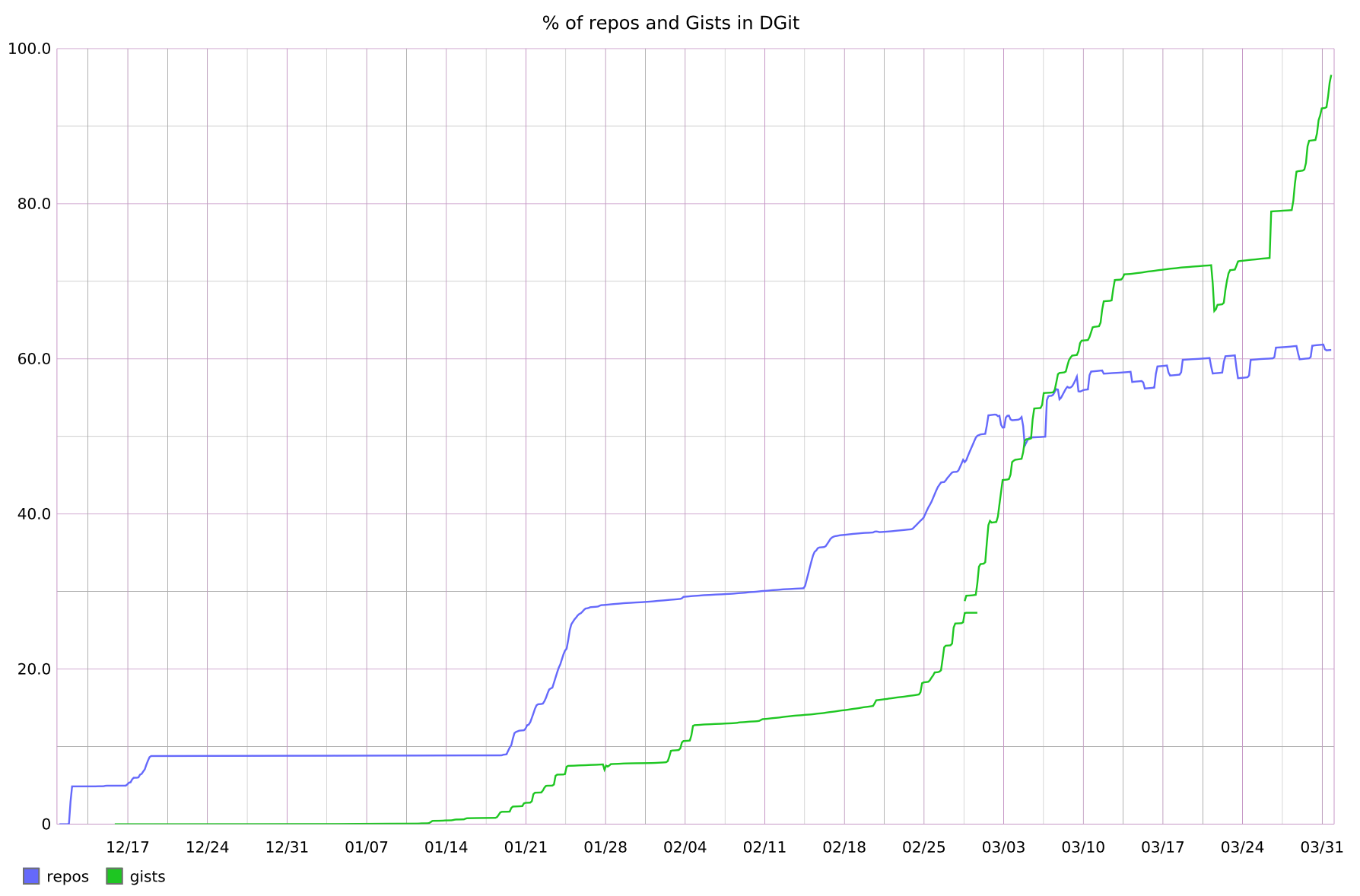
As of this writing, 58% of repositories and 96% of Gists, representing 67% of
Git operations, are in DGit. We are moving the rest as quickly as we
can turn pre-DGit file server pairs into DGit servers.
Conclusion
GitHub always strives to make fetching, pushing, and viewing repositories quick
and reliable. DGit is how our repository-storage tier will meet those
goals for years to come while allowing us to scale horizontally and increase fault tolerance.
Over the next month we will be following up with in-depth posts on the technology behind DGit.
Written by

Related posts

From latency to instant: Modernizing GitHub Issues navigation performance
How the GitHub Issues team used client-side caching, smart prefetching, and service workers to make navigation feel instant.

How GitHub uses eBPF to improve deployment safety
Learn how Github uses eBPF to detect and prevent circular dependencies in its deployment tooling.
The uphill climb of making diff lines performant
The path to better performance is often found in simplicity.