Improving Git push times through faster server side hooks
The history of pre-receive hooks, how we discovered that the performance was problematic, and how we went about safely replacing them.

At GitHub, we relentlessly pursue performance. Join me now for the tale of how we dropped a P99 time by 95% on code that runs for every single Git push operation.
Every time you push to GitHub, we run a set of checks to validate your push before accepting it. If you ever tried to push an object larger than 100MB, you are already familiar with them, as these pre-receive hooks contain that logic. Similarly, they do other checks, such as verifying that LFS objects have been successfully uploaded. These hooks help keep our servers healthy and improve the user experience.
We recently rewrote these hooks from their original Ruby implementation into Go. This rewrite was something we had in mind for a while, but what really sold us on the effort was the potential performance improvement.
Today, we’ll talk about the history of these hooks, how we discovered that the performance was problematic, and how we went about safely replacing them.
How did we get here?
We created the first hook in 2013 to warn users that a repository was renamed. The only action was a database check for a previous name and to send a warning to the user to update their remote URL. At the time, almost all of GitHub was part of one Ruby on Rails application, so it was the logical choice for hooks as well. As time passed, more and more functionality was added to the hooks, requiring additional configuration, exception reporting, and logging.
This meant that hooks imported the same dependencies as the Ruby application. Over time, the number of dependencies, and therefore startup time, only increased. In a Rails application, these dependencies are loaded only once at startup time, and then each request has them available, making the startup time not important for the user experience. However, these hooks are run as subprocesses underneath the Git executable, so they are loaded for each request, making the startup time critical to performance. When we investigated, loading these dependencies took a rather long time. Hooks took about 880 milliseconds to execute on average, and almost all of that time was spent loading dependencies. In addition, there are two sets of hooks: one with the new data under quarantine and a second set once the data is available in the repository. Especially with this double execution, this startup time significantly affects each push. An empty push could take more than two seconds, which was unacceptable.
Why rewrite?
Since the performance issues were related to startup time, we had a few options. We could reduce the number of dependencies, we could change the architecture so that hooks only started up once, or we could rewrite the hooks to run independently of the monolith. Rewrites and changing the architecture carry risk, so we tried the simplest alternative first.
Loading fewer dependencies while staying within the Rails monolith proved quite tricky. There were a lot of dependencies (more than 450 gems leading to over 1,000 require calls), and they were all quite tangled up in the app’s configuration, because they were not designed to be used outside of the GitHub Rails monolith. However, careful use of the debugger and strace revealed a few outliers that we could avoid loading when running the hooks. This removal dropped 350-400 milliseconds from the startup time.
While this was already a decent improvement for a small tweak, the startup time was still quite slow, and we weren’t satisfied yet. Additionally, new dependencies are frequently added to the Rails application, which means that the startup time would creep up again over time even if our hook code did not change.
How did we rewrite?
We could not ignore the configuration from the Rails app as that is how we know how to connect to the database, send stats, etc. Some of that could be duplicated at the risk of having two parallel configuration paths that would almost certainly end up diverging.
To pass configuration along that only the app knows about, we were able to use an existing mechanism, which was already in use to pass along information, such as the name of a repository and whether it is over its quota. This comes alongside other information necessary to perform updates so it gets called for every push, and adding some more data there adds very little overhead. We identified the information necessary to perform the checks and added this information.
For the past few years, the Git Systems Team has been extracting more and more of our service code from the Rails monolith and rewriting it as a dedicated service written in Go. Based on this experience with Go, and given what we learned about the Ruby hooks, moving the hooks into this Go service seemed like a natural fit as well. Just extracting the hooks to run independently of the Rails apps would have removed most of the boot time, but Go gives us the last few milliseconds and lets us make them part of the service in which the backend code increasingly lives. We expected such a significant rewrite to be worth the risk, because afterwards the hooks should be much faster.
Further, as we commonly do for high-impact changes, we put these rewritten hooks behind a feature flag. This gave us the ability to enable them for individual repositories or groups of them. We started with a few internal GitHub repositories to confirm the effect in production.
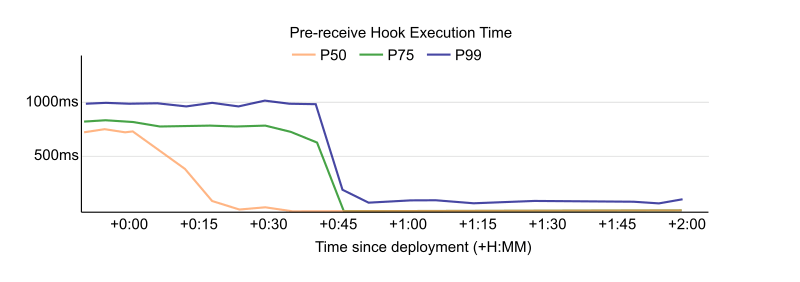
The results were so impressive that we had to double check that the hooks were still running. It was hard to distinguish between really fast hooks and completely disabled hooks. The median time was now 10ms, compared to roughly 880ms when we started the project. This made pushes noticeably faster for everyone. We even got unprompted questions about whether pushing had become faster after someone noticed it on their own.
Lessons learned
This is a project we had in mind for a long time. We had wanted to rewrite these hooks outside of the monolith to separate our area of responsibility better. However, merely having a better architecture often isn’t enough to make something a business priority. By tying the change to its impact on users we could prioritize this work. We came away with the dual benefits of a much better user experience and an architectural improvement.
This change has now been live on github.com for a couple of months, and has been shipped in GHES 3.4, so everyone now saves some time pushing to their GitHub repositories.
Tags:


Related posts

From latency to instant: Modernizing GitHub Issues navigation performance
How the GitHub Issues team used client-side caching, smart prefetching, and service workers to make navigation feel instant.

How GitHub uses eBPF to improve deployment safety
Learn how Github uses eBPF to detect and prevent circular dependencies in its deployment tooling.
The uphill climb of making diff lines performant
The path to better performance is often found in simplicity.