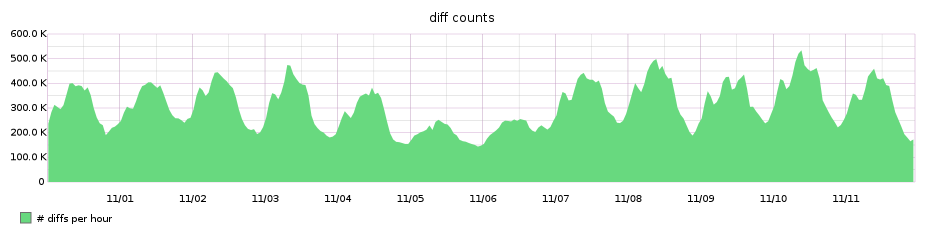
How we made diff pages three times faster
We serve a lot of diffs here at GitHub. Because it is computationally expensive to generate and display a diff, we’ve traditionally had to apply some very conservative limits on…
We serve a lot of diffs here at GitHub. Because it is computationally expensive to generate and display a diff, we’ve traditionally had to apply
some very conservative limits on what gets loaded. We knew we could do better, and we set out to do so.
Historical approach and problems
Before this change, we fetched diffs by asking Git for the diff between two commit objects. We would then parse the output, checking it against the various limits we had in place. At the time they were as follows:
- Up to 300 files in total.
- Up to 100KB of diff text per file.
- Up to 1MB of diff text overall.
- Up to 3,000 lines of diff text per file.
- Up to 20,000 lines of diff text overall.
- An overall RPC timeout of up to eight seconds, though in some places it would
be adjusted to fit within the remaining time allotted to the request.
These limits were in place to both prevent excessive load on the file servers, as well as prevent the browser’s DOM from growing too large and making the web page less responsive.
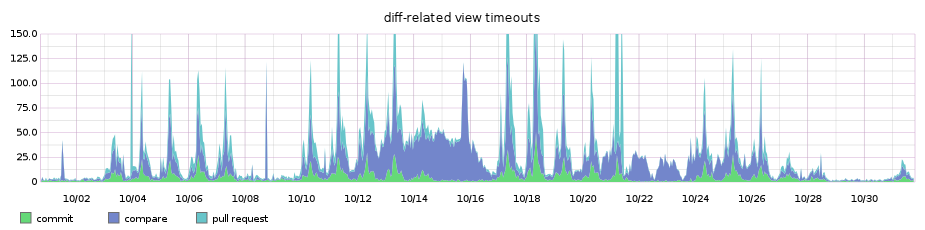
In practice, our limits did a pretty good job of protecting our servers and users’ web browsers from being overloaded. But because these limits were applied in the order Git handed us back the diff text, it was possible for a diff to be truncated before we reached the interesting parts. Unfortunately, users had to fall back to command-line tools to see their changes in these cases.
Finally, we had timeouts happening far more frequently than we liked. Regardless of the size of the requested diff, we shouldn’t force the user to wait up to eight seconds before responding, and even then occasionally with an error message.
Our Goals
Our main goal was to improve the user experience around (re)viewing diffs on GitHub:
- Allow users to (re)view the changes that matter, rather than just whatever
appears before the diff is truncated. - Reduce request timeouts due to very large diffs.
- Pave the way for previously inaccessible optimizations (e.g. avoid loading
suppressed diffs). - Reduce unnecessary load on GitHub’s storage infrastructure.
- Improve accuracy of diff statistics.
A new approach
To achieve the aforementioned goals, we had to come up with a new and better approach to handling large diffs. We wanted a solution that would allow us to get a high-level overview of all changes in a diff, and then load the patch texts for the individual changed files “progressively”. These discrete sections could later be assembled by the user’s browser.
But to achieve this without disrupting the user experience, our new solution also needed to be flexible enough to load and display diffs identically to how we were doing it in production to date. We wanted to verify accuracy and monitor any performance impact by running the old and new diff loading strategies in production, side-by-side, before changing to the new progressive loading strategy.
Lucky for us, Git provides an excellent plumbing command called git-diff-tree.
Diff “table of contents” with git-diff-tree
git-diff-tree is a low-level (plumbing) git command that can be used to compare the contents of two tree objects and output the comparison result in different ways.
The default output format is --raw, which prints a list of changed files:
> git-diff-tree --raw -r --find-renames HEAD~ HEAD
:100644 100644 257cc5642cb1a054f08cc83f2d943e56fd3ebe99 441624ae5d2a2cd192aab3ad25d3772e428d4926 M fileA
:100644 100644 5716ca5987cbf97d6bb54920bea6adde242d87e6 4ea306ce50a800061eaa6cd1654968900911e891 M fileB
:100644 100644 7c4ede99d4fefc414a3f7d21ecaba1cbad40076b fb3f68e3ca24b2daf1a0575d08cd6fe993c3f287 M fileCUsing git-diff-tree --raw we could determine what changed at a high level very quickly, without the overhead of generating patch text. We could then later paginate through this list of changes, or “deltas”, and load the exact patch data for each “page” by specifying a subset of the deltas’ paths to git-diff-tree --patch.
To better understand the obvious performance overhead of calling two git commands instead of one, and to ensure that we wouldn’t cause any regressions in the returned data, we initially focused on generating the same output as a plain call to git-diff-tree --patch, by calling git-diff-tree --raw and then feeding all returned paths back into git-diff-tree --patch.
We started a Scientist experiment which ran both algorithms in parallel, comparing accuracy and timing. This gave us detailed information on cases where results were not as expected, and allowed us to keep an eye on performance.
As expected, our new algorithm, which was replacing something that hadn’t been materially refactored in years, had many mismatches and performance was worse than before.
Most of the issues that we found were simply unexpected behaviors of the old code under certain conditions. We meticulously emulated these corner cases, until we were left only with mismatches related to rename detection in git diff.
Fetching diff text with git-diff-pairs
Loading the patch text from a set of deltas sounds like it should have been a pretty straightforward operation. We had the list of paths that changed, and just needed to look up the patch texts for these paths. What could possibly go wrong?
In our first attempt we loaded the diffs by passing the first 300 paths from our deltas to git-diff-tree --patch. This emulated our existing behaviour, – and we unexpectedly ran into rare mismatches. Curiously, these mismatches were all related to renames, but only when multiple files containing the same or very similar contents got renamed in the same diff.
This happened because rename detection in git is based on the contents of the tree that it is operating on, and by looking at only a subset of the original tree, git’s rename detection was failing to match renames as expected.
To preserve the rename associations from the initial git-diff-tree --raw run, @peff added a git-diff-pairs command to our fork of
Git. Provided a set of blob object IDs (provided by the deltas) it returns the corresponding diff text, exactly what we needed.
On a high level, the process for generating a diff in Git is as follows:
- Do a tree-wide diff, generating modified pairs, or added/deleted paths (which
are just considered pairs with a null before/after state). - Run various algorithms on the whole set of pairs, like rename detection. This
is just linking up adds and deletes of similar content. - For each pair, output it in the appropriate format (we’re interested in
--patch, obviously).
git-diff-pairs lets you take the output from step 2, and feed it individually into step 3.
With this new function in place, we were finally able to get our performance and accuracy to a point where we could transparently switch to this new diff method without negative user impact.
If you’re interested in viewing or contributing to the source for git-diff-pairs we submitted it upstream here.
Change statistics with git-diff-tree --numstat --shortstat
GitHub displays line change statistics for both the entire diff and each delta. Generating the line change statistics for a diff can be a very
costly operation, depending on the size and contents of the diff. However, it is very useful to have summary statistics on a diff at a glance so that the user can have a good overview of the changes involved.
Historically we counted the changes in the patch text as we processed it so that only one diff operation would need to run to display a diff. This operation and its results were cached so performance was optimal. However, in the case of truncated diffs there were changes that were never seen and therefore not included in these statistics. This was done to give us better performance at the cost of slightly inaccurate total counts for large diffs.
With our move to progressive diffs, it would become increasingly likely that we would only ever be looking at a part of the diff at any one time so the counts would be inaccurate most of the time instead of rarely.
To address this problem we decided to collect the statistics for the entire diff using git-diff-tree --numstat --shortstat. This would not only solve the problem of dealing with partial diffs, but also make the counts accurate in cases where they would have been incorrect before.
The downside of this change is that Git was now potentially running the entire diff twice. We determined this was acceptable, however as the remaining diff processing for presentation was far more resource intensive. Also, with progressive diffs, it was entirely probable that many larger diffs would never have the second pass since those deltas might never be loaded anyway.
Due to the nature of how git-diff-tree works, we were even able to combine the call for these statistics with the call for deltas into a single command, to further improve performance. This is because Git already needed to perform a full diff in order to determine what the statistics were, so having it also print the tree diff information is essentially free.
Patches in batches: a whole new diff
For the initial request of a page containing a diff, we first fetched the deltas along with the diff statistics. Next we fetched as much diff text as we could, but with significantly reduced limits compared to before.
To determine optimal limits, we turned to some of our copious internal metrics. We wanted results as quickly as possible, but we also wanted a solution which would display the full diff in “most” cases. Some of the information our metrics revealed was:
- 81% of viewed diffs contain changes to fewer than ten files.
- 52% of viewed diffs contain only changes to one or two files.
- 80% of viewed diffs have fewer than 20KB of patch text.
- 90% of viewed diffs have fewer than 1000 lines of patch text.
From these, it was clear a great number of diffs only involved a handful of changes. If we set our new limits with these metrics in mind, we could continue to be very fast in most cases while significantly improving performance in previously slow or inaccessible diffs.
In the end, we settled on the following for the initial request for a diff page:
- Up to 400 lines of diff text.
- Up to 20KB of diff text.
- A request cycle dependent timeout.
- A maximum individual patch size of 400 lines or 20KB.
This allowed the initial request for a large diff to be much faster, and the rest of the diff to automatically load after the first batch of patches was already rendered.
After one of the limits on patch text was reached during asynchronous batch loading, we simply render the deltas without their diff text and a “load diff” button to retrieve the patch as needed.
Overall, the effective limits we enforce for the entire diff became:
- Up to 3,000 files.
- Up to 60,000,000 lines (not loaded automatically).
- Up to 3GB of diff text (also not loaded automatically).
With these changes, you got more of the diff you needed in less time than ever before. Of course, viewing a 60,000,000 line diff would require the user to press the “load diff” button more than a couple thousand times.
The benefits to this approach were a clear win. The number of diff timeouts dropped almost immediately.
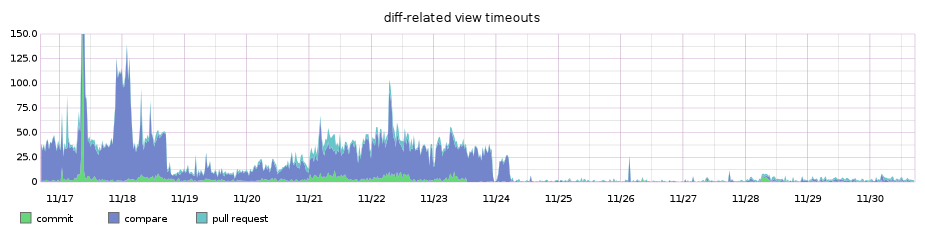
Additionally, the higher percentile performance of our main diffs pages improved by nearly 3x!
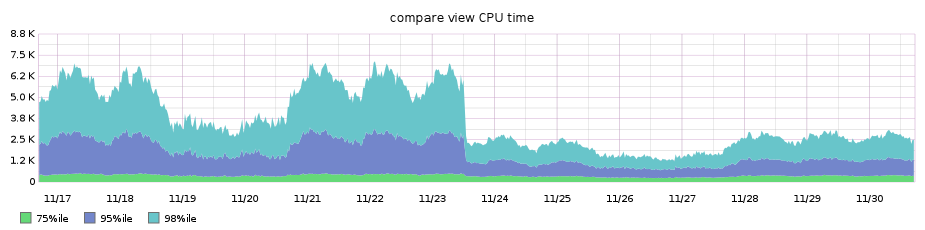
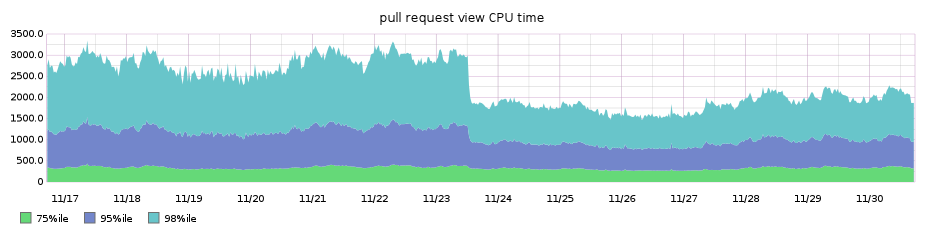
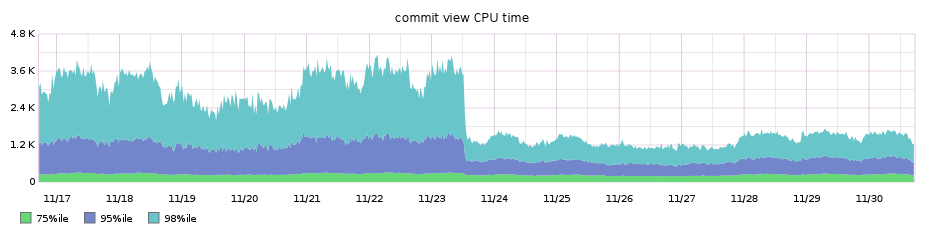
Our diff pages pages were traditionally among our worst performing, so the performance win was even noticeable on our high percentile graph for overall requests’ performance across the entire site, shaving off around 3.5s from the 99.9th percentile:
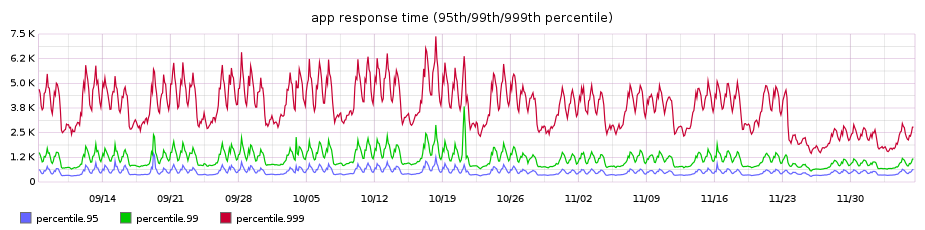
Looking to the future
This new approach opens the door to new types of optimizations and interface ideas that weren’t possible before. We’ll be continuing to improve how we fetch and render diffs, making them more useful and responsive.
Authors




Written by

Related posts

The cost of saying yes has changed
The cost of writing code dropped; the cost of owning it didn’t. A framework for deciding which changes are actually cheap in the AI era.
Better tools made Copilot code review worse. Here’s how we actually improved it.
How migrating Copilot code review to shared Unix-style code exploration tools reduced review cost by reshaping agent workflows around pull request evidence.
Automating cross-repo documentation with GitHub Agentic Workflows
Explore how the Aspire team turns merged product changes into SME-reviewed docs pull requests, closing the gap between release and documentation.