Write Better Commits, Build Better Projects
High-quality Git commits are the key to a maintainable and collaborative open- or closed-source project. Learn strategies to improve and use commits to streamline your development process.

How often have you found yourself thinking:
- What’s the point of this code?
- Isn’t this option deprecated?
- Is this comment out-of-date? I don’t think it describes what I’m seeing.
- This pull request is massive, where do I start?
- Where did this bug come from?
These questions all reflect the limitations of collaboratively-developed source code as a communication medium. While there are ways to mitigate these issues (code comments, style guides, documentation requirements), we still inevitably find ourselves spending hours on just trying to understand code. Luckily, the tools needed to solve these problems have been here all along!
Commits in Git repositories are more than just save points or logs of incremental progress in a larger project. In the words of GitHub’s “Git Guides“:
[Commits] are snapshots of your entire repository at specific times…based around logical units of change. Over time, commits should tell a story of the history of your repository and how it came to be the way that it currently is.
Commits are a firsthand historical record of exactly how and why each line of code came to be. They even come with human-readable messages! As a result, a repository’s commit history is the best tool a developer can use to explain and understand code.
It’s been my experience that commits are most effective when they’re tweaked and polished to deliberately convey a message to their audiences: reviewers, other contributors, and even your future self. This post will:
- Introduce some guidelines for organizing and revising commits.
- Outline pragmatic approaches for applying those guidelines.
- Describe some of the practical applications of a well-crafted commit history.
Writing better commits
Software development involves a lot of creativity, so your commits will reflect the context of your changes, your goals, and your personal style. The guidelines below are presented to help you utilize that creative voice to make your commits effective tools of communication.
As you read these guidelines, don’t worry about how you’ll be able to utilize all of this advice in the midst of writing code. Although you may naturally incorporate them into your development process with practice, each can be applied iteratively after you’ve written all of your code.
📚 Structure the narrative
Like your favorite novel, a series of commits has a narrative structure that contextualizes the “plot” of your change with the code. Before any polishing, the narrative of a branch typically reflects an improvised stream of consciousness. It might contain:
- A commit working on component A, followed by one on component B, followed by one finishing component A
- A multi-commit detour into trying again and again to get the right CI syntax
- A commit fixing a typo from an earlier commit
- A commit with a mixed bag of all of the review feedback
- A merge commit resolving conflicts with the
mainbranch
Although an accurate retelling of your journey, a branch like this tells a “story” that is neither coherent nor memorable.
The problem
Disorganized commits that eschew a clear narrative will affect two people: the reviewer, and the developer themself.
Reviewing commit-by-commit is the easiest way to avoid being overwhelmed by the changes in a sufficiently large pull request. If those commits do not tell a singular, easy-to-follow story, the reviewer will need to context-switch as the author’s commits jump from topic to topic. To ensure earlier commits properly set up later ones (for example, verifying a newly-created function is used properly), the reviewer ultimately needs to piece together the narrative on their own; for each commit, figure out which earlier changes establish the relevant background context and tediously click back and forth between them. Alternatively, they’ll remember some vague details and simply assume earlier commits properly set up later ones, failing to identify potential issues.
But how does a scatterbrained narrative hurt the developer? A developer’s first instinct when working on a new project is often to hack on it until they get something functional. Fluctuating between “fun” and “frustrating,” this approach eventually yields good results, but it’s far from efficient. Jumping in without a plan – the mindset of following a narrative – makes that process slower than it needs to be.
The solution
Outline your narrative, and reorganize your commits to match it.
The narrative told by your commits is the vehicle by which you convey the meaning of your changes. Also, like a story, it can take on many structures or forms.
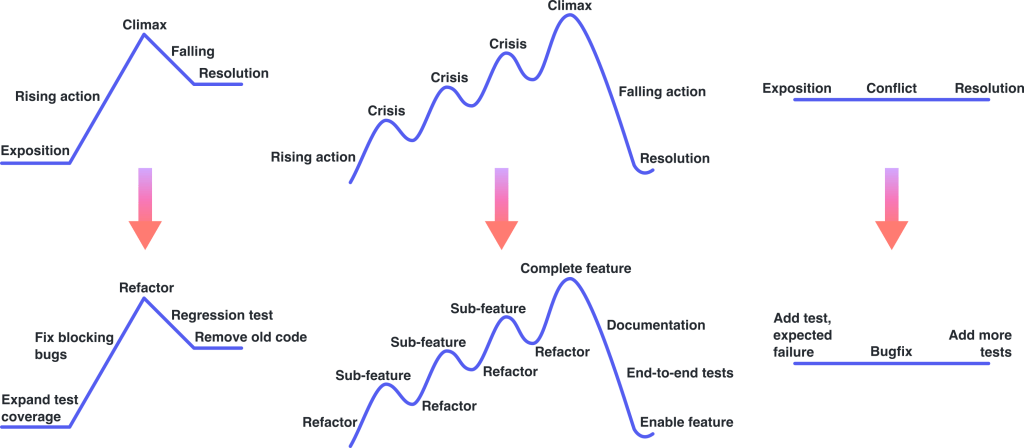
Your branch is your story to tell. While the narrative is up to you, here are some editorial tips on how to keep it organized:
| DO | DON’T |
|---|---|
| Write an outline and include it in the pull request description. | Wait until the end to form the outline – try using it to guide your work! |
| Stick to one high-level concept per branch. | Go down a tangentially-related “rabbit hole”. |
| Add your “implement feature” commit immediately after the refactoring that sets it up. | Jump back and forth between topics throughout your branch. |
| Treat commits as “building blocks” of different types: bugfix, refactor, stylistic change, feature, etc. | Mix multiple building block types in a single commit. |
⚛️ Resize and stabilize the commits
Although the structure of a commit series can tell the high-level story of an author’s feature, it’s the code within each commit that creates software. Code itself can be complex, dense, and cryptic but in order to collaborate, others need to understand it.
The problem
The cognitive burden of parsing code is exacerbated by having either too much or not enough information presented at once. Too much, and your reader will need to read and understand multiple conceptually-different topics that could get jumbled, misinterpreted, or simply missed; too little, and your reader will develop an incomplete mental model of a change.
For a reviewer, one of the big benefits of a commit-by-commit review is – like individual lectures in a semester-long course – pacing the development of their mental model with small, easy-to-digest changes. When a large commit doesn’t provide that sustainable learning pace, the reviewer may fail fail to identify questionable architectural decisions because they conflate unrelated topics, or even miss a bug because it’s in a section seemingly irrelevant to the impacted feature.
You might think reviewers’ problems would be solved with commits as small as possible, but an incomplete change leaves them unable to evaluate it fully as they read it. When a later commit “completes” the change, a reviewer may not easily draw connections to the earlier context. This is made worse when a later commit undoes something from the earlier, partial commit. The “churn” in these situations leads to the same weakened mental model – and same consequences – as when dealing with too-large commits.
Poorly-sized commits present more tangible issues as well. Most apparent is the inability to roll back your repository to a commit (for example, when debugging a strange feature interaction). Incomplete changes often fail to build, so a developer will be stuck searching nearby commits for a fix. Similarly, a bug narrowed down to a massive commit requires teasing apart its intermixed changes, a potentially more difficult task than it was during the initial review due to loss of institutional project knowledge over time.
The solution
Make each commit both “small” and “atomic.”
To best convey your story, commits should minimize the effort needed to build a mental model of the changes they introduce. With effort tied to having a “just right” amount of information, the key to a good commit is fitting into quantified upper and lower bounds on that information.
A small commit is one with minimal scope; it does one “thing.” This often correlates to minimizing the modified lines of cone, but that isn’t a firm requirement. For example, changing the name of a commonly-used function may modify hundreds of lines of code, but its constrained scope makes it simple to both explain and review.
A commit is atomic when it is a stable, independent unit of change. In concrete terms, a repository should still build, pass tests, and generally function if rolled back to that exact commit without needing other changes. In an atomic commit, your reader will have everything they need to evaluate the change in the commit itself.
❓ Explain the context
Commits are more than just the code they contain. Despite there being no shortage of jokes about them, commit messages are an extremely valuable – but often overlooked – component of a commit. Most importantly, they’re an opportunity to speak directly to your audience and explain a change in your own terms.
The problem
Even with a clear narrative and appropriately-sized commits, a niche change can still leave readers confused. This is especially true in large or open-source projects, where a reviewer or other future reader (even yourself!) likely won’t be clued into the implementation details or nuances of the code you’ve changed.
Code is rarely as self-evident as the author may believe, and even simple changes can be prone to misinterpretation. For example, what may appear to be a bug may instead be a feature implemented to solve an unrelated problem. Without understanding the intent of the original change, a developer may inadvertently modify an expected user-facing behavior. Conversely, something that appears intentional may have been a bug in the first place. A misinterpretation could cause a developer to enshrine a small mistake as a “feature” that hurts user experience for years.
Even in a best-case scenario, poorly explained changes will slow down reviewers and contributors as they attempt to interpret code, unnecessarily wasting everyone’s time and energy.
The solution
Describe what you’re doing and why you’re doing it in the commit message.
Because you’re writing for an audience, the content of a commit message should clearly communicate what readers need to understand. As the developer, you should already know the background and implementation well enough to explain them. Rather than write excessively long (and prone to obsoletion) code comments or put everything into a monolithic pull request description, you can use commit messages to provide piecewise clarification to each change.
“What” and “why” break down further into high- and low-level details, all of which can be framed as four questions to answer in each commit message:
| What you’re doing | Why you’re doing it | |
|---|---|---|
| High-level (strategic) | Intent (what does this accomplish?) | Context (why does the code do what it does now?) |
| Low-level (tactical) | Implementation (what did you do to accomplish your goal?) | Justification (why is this change being made?) |
Building better projects
Using the guidelines established above, you can mitigate the challenges of common software development tasks including code review, finding bugs, and root cause analysis.
Code review
Reviewing even the largest pull requests can be a manageable, straightforward process if you are able to evaluate changes on a commit-by-commit basis. Each of the guidelines detailed earlier focuses on making the commits readable; to extract information from commits, you can use the guidelines as a template.
- Determine the narrative by reading the pull request description and list of commits. If the commits seem to jump between topics or address, leave a comment asking for clarification or changes.
- Lightly scan the message and contents of each commit, starting from the beginning of the branch. Verify smallness and atomicity by checking that the commit does one thing and that doesn’t include any incomplete implementations. Recommend splitting or combining commits that are incorrectly scoped.
- Thoroughly read each commit. Ensure the commit message sufficiently explains the code by first checking that implementation matches the intent, then that the code matches the stated implementation. Use the context and justification to guide your understanding of the code. If any of the requisite information is missing, ask for clarification from the author.
- Finally, with a complete mental model of the commit’s changes and the overarching narrative, confirm the code is efficient and bug-free.
Finding bugs with git bisect
If you’ve ever found yourself with a broken deployment and no idea when the breakage was introduced, git bisect is the tool for you. Specifically, git bisect is a tool built into Git that, when given a known-good commit (for example, your last stable deployment) and a known-bad commit (the broken one), will perform a binary search of the commits in the middle to find which one introduced the error.
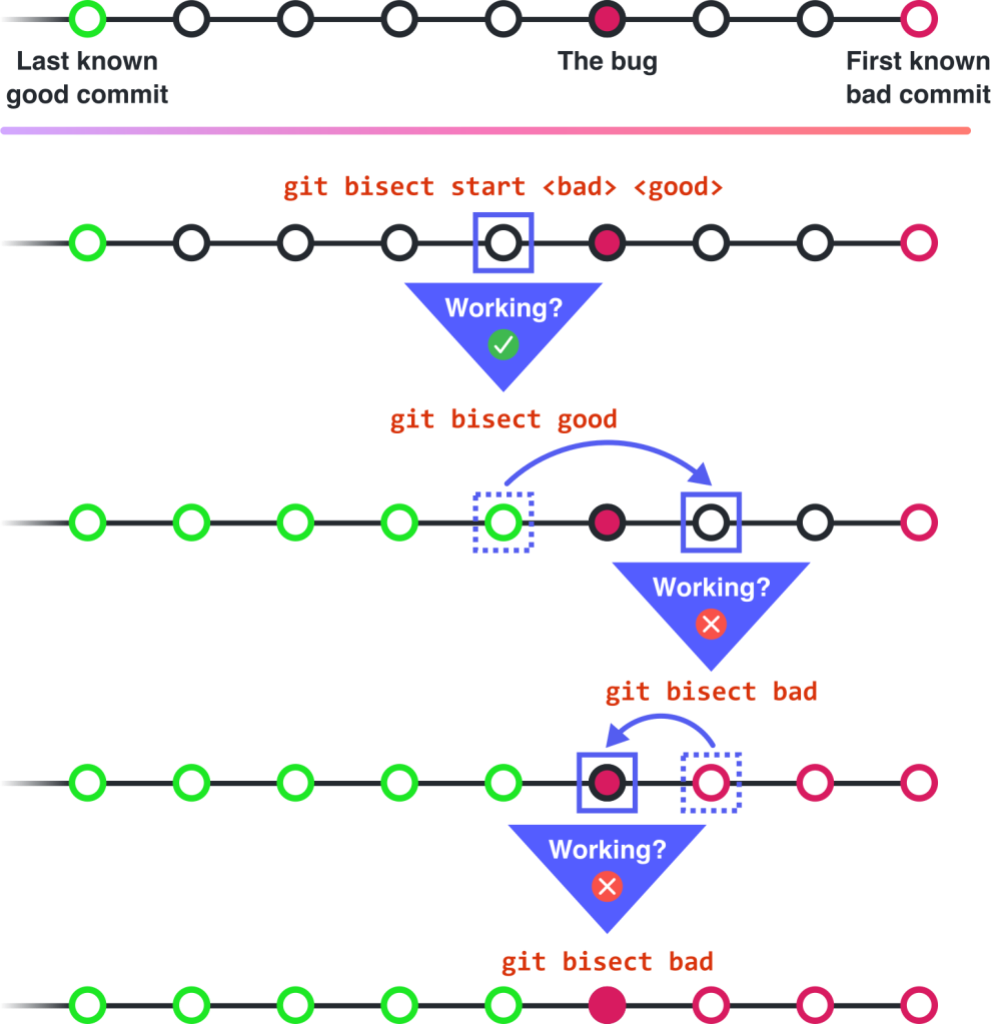
As useful as git bisect is, it absolutely requires that each commit it traverses is both atomic and small. If not atomic, you will be unable to test for repository stability at each commit; if not small, the source commit of your bug may be so large that you end up inefficiently reading code line-by-line to find the bug anyway.
Root cause analysis
Suppose you’ve used something like git bisect to isolate the source commit of a bug. If you’re lucky, the underlying problem is obvious and you can fix it immediately. More often than not, things aren’t so simple; the bug-causing code might be necessary for another feature, or does not make sense as the source of the error you’re seeing. You need to understand why the code was written, and to do that, you can again use the commit history to investigate.
There are two main tools to help you search through commits: git blame and git log.
git blame annotates the file with the commit that last changed it:
$ git blame -s my-file.py abd52642da46 my-file.py 1) import os 603ab927a0dd oldname.py 3) import re 603ab927a0dd oldname.py 4) 603ab927a0dd oldname.py 5) print(“Hello world”) abd52642da46 my-file.py 5) print(os.stat(“README”))
This can be particularly helpful in finding which commits modify the same area of code, which you can then read to determine if they interact poorly.
For a more generalized commit search, you can use git log. In its simplest form, git log will display a list of commits in reverse chronological order, starting at HEAD:
$ git log --oneline 09823ba09de1 README.md: update project title abd52642da46 my-file.py: add README stat printout 7392d7dbb9ae my-file.py: rename from oldname.py 5ad823d1bc48 test.py: commonize test setup 603ab927a0dd oldname.py: create printout script ...
The displayed list of commits can also be filtered by file(s), by function name, by line range in a file, by commit message text, and more. As with git blame, these filtered lists of commits can help you build a complete mental model of the changes that comprise a particular file or function, ultimately guiding you to the root cause of your bug.
Final thoughts
Although subjective and sometimes difficult to quantify, commit quality can make a massive difference in developer quality-of-life on any project: old or new, large or small, open- or closed-source. To make commit refinement part of your own development process, some guidelines to follow are:
- Organize your commits into a narrative.
- Make each commit both small and atomic.
- Explain the “what” and “why” of your change in the commit message.
These guidelines, as well as their practical applications, demonstrate how powerful commits can be when used to contextualize code. Regardless of what you do with them, commits will tell your project’s story; these strategies will help you make it a good one.
Additional Resources
- “Git Organized: A Better Git Flow,” an alternative methodology for revising commits
- “Fixing commits with git commit –fixup and git rebase –autosquash,” tips on how to use
fixup!commits and--autosquashto more efficiently clean up a branch git-absorb, a tool that automatically splits miscellaneous fixes into assignedfixup!commits- “A Note About Git Commit Messages,” advice on formatting and phrasing in commit messages
- “My favourite Git commit,” an in-depth review of a really good commit message
Tags:
Written by

Related posts
Building AI-powered GitHub issue triage with the Copilot SDK
Learn how to integrate the Copilot SDK into a React Native app to generate AI-powered issue summaries, with production patterns for graceful degradation and caching.

GitHub for Beginners: Getting started with GitHub Actions
Set up your first GitHub Actions workflow in this how-to guide.

Scaling AI opportunity across the globe: Learnings from GitHub and Andela
Developers connected to Andela share how they’re learning AI tools inside real production workflows.