Experience faster, smarter code completions yourself. Try GitHub Copilot in VS Code >
The road to better completions: Building a faster, smarter GitHub Copilot with a new custom model
Find out about the latest custom models powering the completions experience in GitHub Copilot.

|
7 minutes
Code completion remains the most widely used GitHub Copilot feature, helping millions of developers stay in the flow every day. Our team has continuously iterated on the custom models powering the completions experience in GitHub Copilot driven by developer feedback. That work has had a big impact on giving you faster, more relevant suggestions in the editor.
We’re now delivering suggestions with 20% more accepted and retained characters, 12% higher acceptance rate, 3x higher token-per-second throughput, and a 35% reduction in latency.
These updates now power GitHub Copilot across editors and environments. We’d like to share our journey on how we trained and evaluated our custom model for code completions.
Why it matters
When Copilot completions improve, you spend less time editing and more time building. The original Copilot was optimized for the highest acceptance rate possible. However, we realized that a heavy focus on acceptance rates could lead to incorrectly favoring a high volume of simple and short suggestions.
We heard your feedback that this didn’t reflect real developer needs or deliver the highest quality experience. So, we pivoted to also optimize for accepted and retained characters, code flow, and other metrics.
- 20% higher accepted-and-retained characters results in more of each Copilot suggestion staying in your final code, not just ending up temporarily accepted and deleted later. In other words, suggestions provide more value with fewer keystrokes.
- 12% higher acceptance rate means you find suggestions more useful more often, reflecting better immediate utility.
- 3x throughput with 35% lower latency makes Copilot feel faster. It handles more requests at once while keeping your coding flow unbroken (throughput describes how much work the system can handle overall, while latency describes how quickly each individual request completes).
How we evaluate custom models
Copilot models are evaluated using combined signals from offline, pre-production, and production evaluations. Each layer helps us refine different aspects of the experience while ensuring better quality in real developer workflows.
1) Offline evaluations
Execution-based benchmark: As part of our offline evaluations, we first test against internal and public repositories with strong code by unit test and scenario coverage, spanning all major languages. Each test simulates real tasks, accepts suggestions, and measures build-and-test pass rates. This emphasizes functional correctness over surface fluency.
Below is an example of a partial token completion error: the model produced dataet instead of dataset.
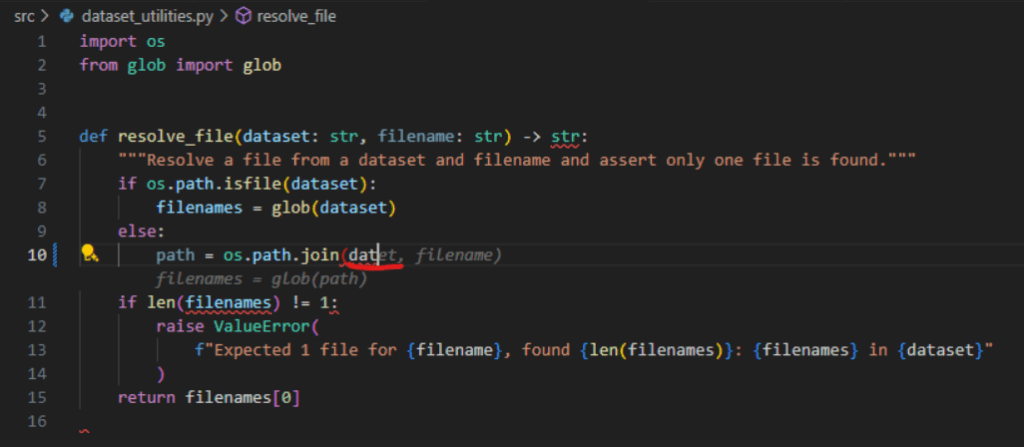
LLM-judge scoring: While we start with execution-based evaluation, this has downsides: it only tells if the code will compile, but the results are not always aligned with developer preferences. To ensure the best possible outcomes, we run an independent LLM to score completions across three axes:
- Quality: Ensure syntax validity, duplication/overlap, format and style consistency.
- Relevance: Focus on relevant code, avoid hallucination and overreach.
- Helpfulness: Reduce manual effort, avoid outdated or deprecated APIs.
2) Pre-production evaluations: Qualitative dogfooding
Our next step includes working with internal developers and partners to test models side-by-side in real workflows (to do the latter, we exposed the preview model to developers through Copilot’s model picker). We collect structured feedback on readability, trust, and “taste.” Part of this process includes working with language experts to improve overall completion quality. This is unique: while execution-based testing, LLM-based evaluations, dogfood testing, and A/B testing are common, we find language-specific evaluations lead to better outcomes along quality and style preferences.
3) Production-based evaluations: A/B testing
Ultimately, the lived experience of developers like you is what matters most. We measure improvements using accepted-and-retained characters, acceptance rates, completion-shown rate, time-to-first token, latency, and many other metrics. We ship only when statistically significant improvements hold up under real developer workloads.
How we trained our new Copilot completions model
Mid-training
Modern codebases use modern APIs. Before fine-tuning, we build a code-specific foundational model via mid-training using a curated, de-duplicated corpus of modern, idiomatic, public, and internal code with nearly 10M repositories and 600-plus programming languages. (Mid-training refers to the stage after the base model has been pretrained on a very large, diverse corpus, but before it undergoes final fine-tuning or instruction-tuning).
This is a critical step to ensure behaviors, new language syntax, and recent API versions are utilized by the model. We then use supervised fine- tuning and reinforcement learning while mixing objectives beyond next-token prediction—span infillings and docstring/function pairs—so the model learns structure, naming, and intent, not just next-token prediction. This helps us make the foundational model code-fluent, style-consistent, and context-aware, ready for more targeted fine-tuning via supervised fine-tuning.
Supervised fine-tuning
Newer general-purpose chat models perform well in natural language to generate code, but underperform on fill-in-the-middle (FIM) code completion. In practice, chat models experience cursor-misaligned inserts, duplication of code before the cursor (prefix), and overwrites of code after the cursor (suffix).
As we moved to fine-tuned behaviors, we trained models specialized in completions by way of synthetic fine-tuning to behave like a great FIM engine. In practice, this improves:
- Prefix/suffix awareness: Accurate inserts between tokens, mid-line continuations, full line completions, and multi-line block completions without trampling the suffix.
- Formatting fidelity: Respect local style (indentation, imports, docstrings) and avoid prefix duplication.
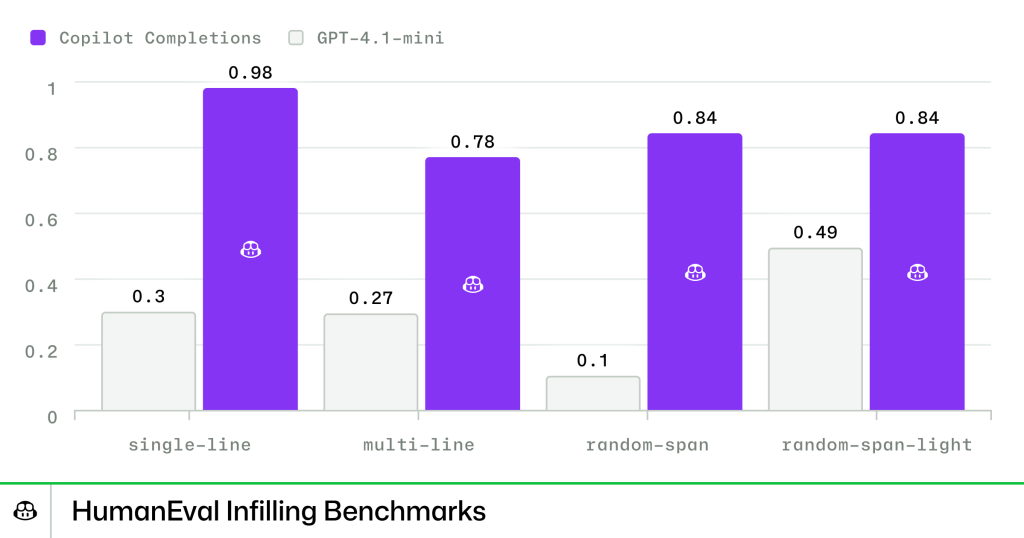
The result is significantly improved FIM performance. For example, here is a benchmark comparing our latest completions model to GPT-4.1-mini on OpenAI’s HumanEval Infilling Benchmarks.
Reinforcement learning
Finally, we used a custom reinforcement learning algorithm, teaching the model through rewards and penalties to internalize what makes code suggestions useful in real developer scenarios along three axes:
- Quality: Syntax-valid, compilable code that follows project style (indentations, imports, headers).
- Relevance: On-task suggestions that respect surrounding context and the file’s intent.
- Helpfulness: Suggestions that reduce manual effort and prefer modern APIs.
Together, these create completions that are correct, relevant, and genuinely useful at the cursor instead of being verbose or superficially helpful.
What we learned
After talking with programming language experts and finding success in our prompt-based approach, one of our most important lessons was adding related files like C++ header files to our training data. Beyond this, we also came away with three key learnings:
- Reward carefully: Early reinforcement learning version over-optimized for longer completions, adding too many comments in the form of “reward hacking.” To mitigate this problem, we introduced comment guardrails to keep completions concise and focused on moving the task forward while penalizing unnecessary commentary.
- Metrics matter: Being hyper-focused on a metric like acceptance rate can lead to experiences that look good on paper, but do not result in happy developers. That makes it critical to evaluate performance by monitoring multiple metrics with real-world impact.
- Train for real-world usage: We align our synthetic fine-tuning data with real-world usage and adapt our training accordingly. This helps us identify problematic patterns and remove them via training to improve real-world outcomes.
What’s next
We’re continuing to push the frontier of Copilot completions by:
- Expanding into domain-specific slices (e.g., game engines, financial, ERP).
- Refining reward functions for build/test success, semantic usefulness (edits that advance the user’s intent without bloat), and API modernity preference for up-to-date, idiomatic libraries and patterns. This is helping us shape completion behavior with greater precision.
- Driving faster, cheaper, higher-quality completions across all developer environments.
Acknowledgments
First, a big shoutout to our developer community for continuing to give us feedback and push us to deliver the best possible experiences with GitHub Copilot. Moreover, a huge thanks to the researchers, engineers, product managers, designers across GitHub and Microsoft who curated the training data, built the training pipeline, evaluation suites, client and serving stack — and to the GitHub Copilot product and engineering teams for smooth model releases.
Tags:


Related posts

GitHub Copilot CLI combines model families for a second opinion
Discover how Rubber Duck provides a different perspective to GitHub Copilot CLI.
Run multiple agents at once with /fleet in Copilot CLI
/fleet lets Copilot CLI dispatch multiple agents in parallel. Learn how to write prompts that split work across files, declare dependencies, and avoid common pitfalls.
Agent-driven development in Copilot Applied Science
I used coding agents to build agents that automated part of my job. Here’s what I learned about working better with coding agents.