Evolving GitHub Copilot’s next edit suggestions through custom model training
GitHub Copilot’s next edit suggestions just got faster, smarter, and more precise thanks to new data pipelines, reinforcement learning, and continuous model updates built for in-editor workflows.

Editing code often involves a series of small but necessary changes ranging from refactors to fixes to cleanup and edge-case handling. In February, we launched next edit suggestions (NES), a custom Copilot model that predicts the next logical edit based on the code you’ve already written. Since launch, we’ve shipped several major model updates, including the newest release earlier this month.
In this post, we’ll look at how we built the original model, how we’ve improved it over time, what’s new, and what we’re building next.
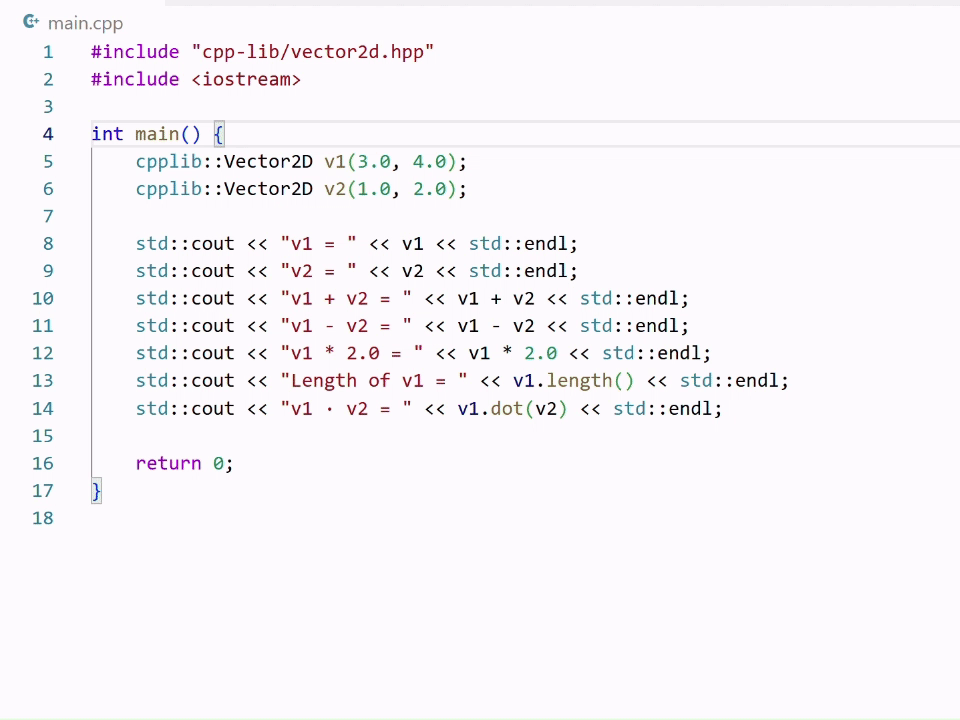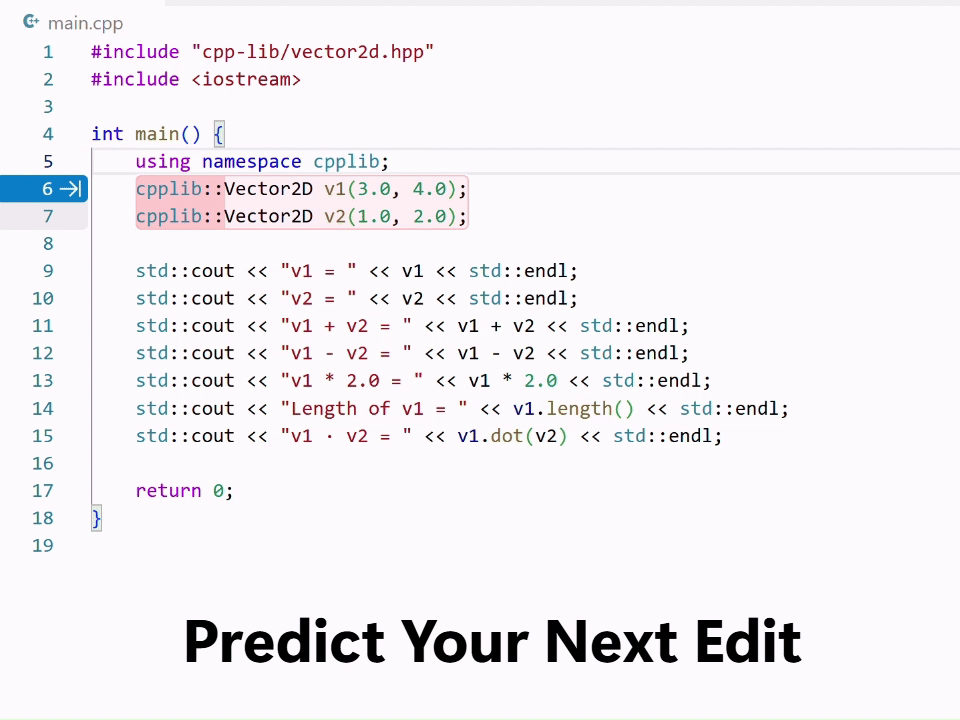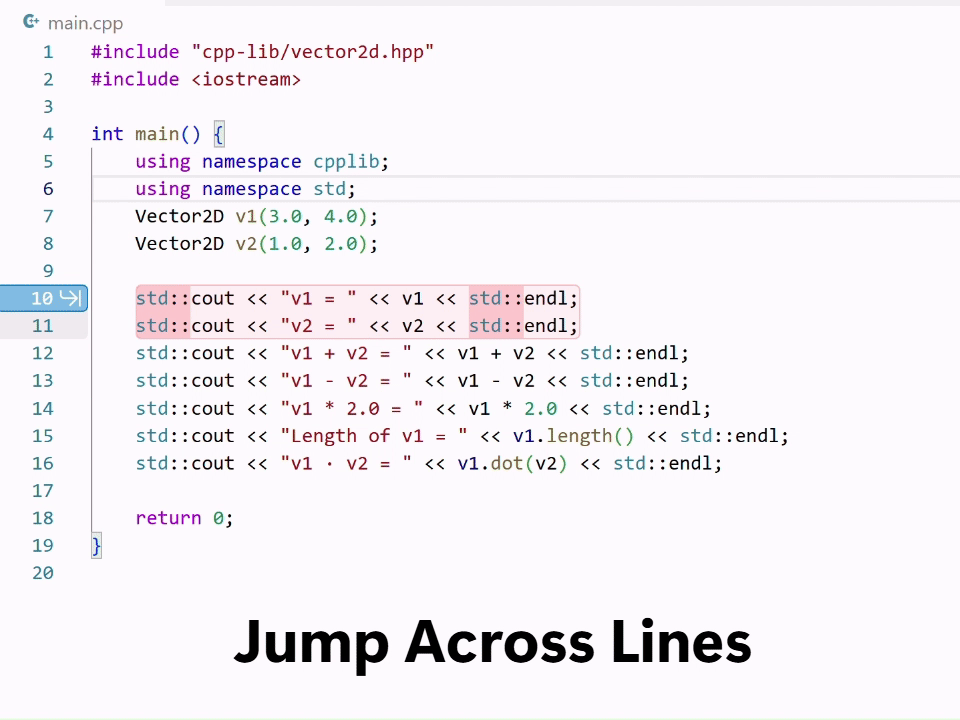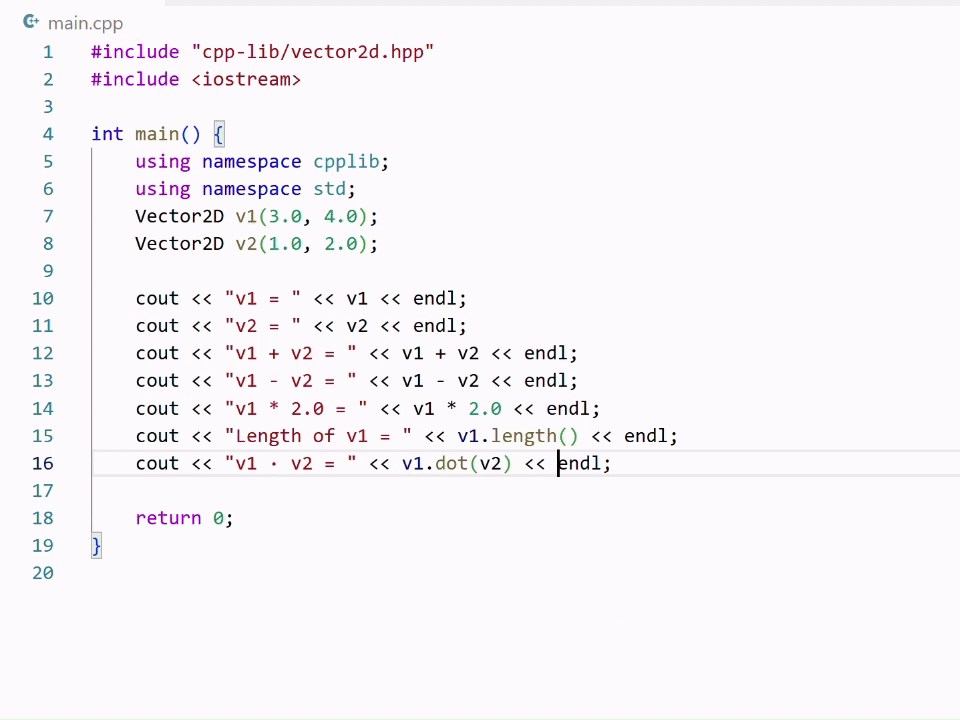
Why edit suggestions are challenging
Predicting the next edit is a harder problem than predicting the next token. NES has to understand what you’re doing, why you’re doing it, and what you’ll likely do next. That means:
- The model must respond quickly to keep up with your flow.
- It has to know when not to suggest anything (too many suggestions can break your focus).
- It must infer intent from local context alone without your explicit prompts.
- It must integrate deeply with VS Code so suggestions appear exactly where you expect them.
Frontier models didn’t meet our quality and latency expectations. The smaller ones were fast but produced low-quality suggestions, while the larger ones were accurate but too slow for an in-editor experience. To get both speed and quality, we needed to train a custom model.
NES isn’t a general-purpose chat model. It’s a low-latency, task-specific model that runs alongside the editor and responds in real time. It’s the result of aligning model training, prompting, and UX around a single goal: seamless editing inside the IDE. That required tight coordination between model training, prompt design, UX design, and the VS Code team—the model only works because the system was co-designed end-to-end.
This “AI-native” approach where every part of the experience evolves together is very different from training a general-purpose model for any task or prompt. It’s how we believe AI features should be built: end to end, with the developer experience at the center.
How we trained
The hard part wasn’t the architecture; it was the data. We needed a model that could predict the next edit a developer might make, but no existing dataset captured real-time editing behavior.
Our first attempt used internal pull request data. It seemed reasonable: pull requests contain diffs, and diffs look like edits. But internal testing revealed limitations. The model behaved overly cautiously—reluctant to touch unfinished code, hesitant to suggest changes to the line a user was typing, and often chose to do nothing. In practice, it performed worse than a vanilla LLM.
That failure made the requirement clear: we needed data that reflected how developers actually edit code in the editor, not how code looks after review.
Pull request data wasn’t enough because it:
- Shows only the final state, not the intermediate edits developers make along the way
- Lacks temporal ordering, so the model can’t learn when changes happen
- Contains almost no negative samples (cases where the correct action is “don’t edit”)
- Misses abandoned edits, in-progress rewrites, and other common editing behavior
So we reset our approach and built a much richer dataset by performing a large-scale custom data collection effort that captured code editing sessions from a set of internal volunteers. We found data quality to be key at this stage: a smaller volume of high-quality edit data led to better models than those trained with a larger volume of data that was less curated.
Supervised fine-tuning (SFT) of a model on this custom dataset produced the first model to outperform the vanilla models. This initial model provided a significant lift to quality and served as a foundation for the next several NES releases.
Model refinement with reinforcement learning
After developing several successful NES models with SFT, we focused on two key limitations of our training approach:
- SFT can teach the model what constitutes a good edit suggestion, but it cannot explicitly teach the model what makes an edit suggestion bad.
- SFT can effectively leverage labeled edit suggestions, but it cannot fully utilize the much larger number of unlabeled code samples.
To address these two limitations, we turned to reinforcement learning (RL) techniques to further refine our model. Starting with the well-trained NES model from SFT, we optimized the model using a broader set of unlabeled data by designing a grader capable of accurately judging the quality of the model’s edit suggestions. This allows us to refine the model outputs and achieve higher model quality.
The key ideas in the grader design can be summarized as follows:
- We use a large reasoning model with specific grading criteria.
- We routinely analyze model outputs to update the grading criteria, constantly searching for new qualities that indicate unhelpful edits.
- The grader should not only consider the correctness of the edit suggestion, but also strive to make the code diff displayed in the UI more user-friendly (easy to read).
Continued post-training with RL has improved the model’s generalization capability. Specifically, RL extends training to unsupervised data, expanding the volume and diversity of data that we have available for training and removing the requirement that the ground truth next edit is known. This ensures that the training process consistently explores harder cases and prevents the model from collapsing into simple scenarios.
Additionally, RL allows us to define our preferences through the grader, enabling us to explicitly establish criteria for “bad edit suggestions.” This enables the trained model to better avoid generating bad edit suggestions when faced with out-of-distribution cases.
Lessons from training our latest custom NES model
Our most recent NES release builds on that foundation with improvements to data, prompts, and architecture:
- Prompt optimization: NES runs many times per minute as you edit, so reducing the amount of context we send on each request has a direct impact on latency. We trimmed the prompt, reused more cached tokens between calls, and removed unneeded markup, which makes suggestions appear faster without reducing quality.
- Data quality filtering: Used LLM-based graders to filter out ambiguous or low-signal samples in order to reduce unhelpful or distracting suggestions.
- Synthetic data: Distilled data from larger models to train a smaller one without losing quality.
- Hyperparameter tuning: Tuned hyperparameters for the new base architecture to optimize suggestion quality.
How we evaluate model candidates
We train dozens of model candidates per month to ensure the version we ship offers the best experience possible. We modify our training data, adapt our training approach, experiment with new base models, and target fixes for specific feedback we receive from developers. Every new model goes through three stages of evaluation: offline testing, internal dogfooding, and online A/B experiments.
- Offline testing: We evaluate models against a set of targeted test cases to understand how well they perform in specific scenarios.
- Internal dogfooding: Engineers across GitHub and Microsoft use each model in their daily workflows and share qualitative feedback.
- A/B experiments: Subject the most promising candidates to a small percentage of real-world NES requests to track acceptance, hide, and latency metrics before deciding what to ship.
Continuous improvements
Since shipping the initial NES model earlier this year, we’ve rolled out three major model updates with each balancing speed and precision.
- April release: This release strongly improved model quality and restructured the response format to require fewer tokens. The result? Faster, higher-quality suggestions.
- May release: To address developer feedback that NES was showing too many suggestions, we improved suggestion quality and reduced the model’s eagerness to make changes. This led to more helpful suggestions and fewer workflow disruptions.
- November release: After testing nearly thirty candidate models over the summer—none of which were strong enough to replace the May model—this release finally cleared the bar in A/B testing. It delivers higher-quality suggestions with lower latency by shortening prompts, reducing response length, and increasing token caching.
The table below summarizes the quality metrics measured for each release. We measure the rate at which suggestions are shown to developers, the rate at which developers accept suggestions, and the rate at which developers hide the suggestion from the UI. These are A/B test results comparing the current release with production.
| Release | Shown rate | Acceptance rate | Hide rate |
|---|---|---|---|
| April | +17.9% | +10.0% | -17.5% |
| May | -18.8% | +23.2% | -20.0% |
| November | -24.5% | +26.5% | -25.6% |
Community feedback
Developer feedback has guided almost every change we’ve made to NES. Early on, developers told us the model sometimes felt too eager and suggested edits before they wanted them. Others asked for the opposite: a more assertive experience where NES jumps in immediately and continuously. Like the tabs-vs-spaces debate, there’s no universal preference, and “helpful” looks different depending on the developer.
So far, we’ve focused on shipping a default experience that works well for most people, but that balance has shifted over time based on real usage patterns:
- Reducing eagerness: We added more “no-edit” samples and tuned suggestion thresholds so the model only intervenes when it’s likely to be useful, not distracting.
- Increasing speed: Because NES runs multiple times per minute, we continue to reduce latency at the model, prompt, and infrastructure levels to keep suggestions inside the editing flow.
- Improving developer experience: We refined how edits are displayed, so suggestions feel visible but not intrusive, and expanded settings that let developers customize how NES behaves.
Looking ahead, we’re exploring adaptive behavior where NES adjusts to each developer’s editing style over time, becoming more aggressive or more restrained based on interaction patterns (e.g., accepting, dismissing, or ignoring suggestions). That work is ongoing, but it’s directly informed by the feedback we receive today.
As always, we build this with you. If you have thoughts on NES, our team would love to hear from you! File an issue in our repository or submit feedback directly to VS Code.
What’s next
Here’s what we’re building:
- Edits at a distance: Suggestions across multiple files—not just where you’re typing.
- Faster responses: Continued latency improvements across the model and infrastructure.
- Smarter edits: Better anticipation of context and cross-file dependencies.
Experience faster, smarter next-edit suggestions yourself
To experience the newest NES model, make sure you have the latest version of VS Code (and the Copilot Chat extension), then ensure NES is enabled in your VS Code settings.
Acknowledgements
A special thanks to Yuting Sun (CoreAI Post Training), Zeqi Lin (Core AI Post Training), Alexandru Dima (VS Code), Brigit Murtaugh (VS Code), and Soojin Choi (GitHub Copilot) for contributing to this blog post. We would also like to express our gratitude to the developer community for their continued engagement and feedback as we improve NES. Also, a massive thanks to all the researchers, engineers, product managers, and designers across GitHub and Microsoft who contributed (and continue to contribute) to model training, client development, infrastructure, and testing.
Tags:


Related posts
Building AI-powered GitHub issue triage with the Copilot SDK
Learn how to integrate the Copilot SDK into a React Native app to generate AI-powered issue summaries, with production patterns for graceful degradation and caching.
How Squad runs coordinated AI agents inside your repository
An inside look at repository-native orchestration with GitHub Copilot and the design patterns behind multi-agent workflows that stay inspectable, predictable, and collaborative.
Continuous AI for accessibility: How GitHub transforms feedback into inclusion
AI automates triage for accessibility feedback, allowing us to focus on fixing barriers—turning a chaotic backlog into continuous, rapid resolutions.