Validating agentic behavior when “correct” isn’t deterministic
How to build the “Trust Layer” for GitHub Copilot cloud agent without brittle scripts or black-box judgements by using dominatory analysis.
Modern software testing is built on a fragile assumption: correct behavior is repeatable. For deterministic code, that assumption mostly holds. But for autonomous agents like Github Copilot cloud agent, especially as we explore the frontiers of integrated “Computer Use,” that assumption breaks down almost immediately.
As agents move beyond simple code suggestions to interacting with real environments like UIs, browsers, and IDEs, correctness becomes multi-path. Loading screens can appear or disappear, timing shifts, and multiple valid action sequences can lead to the same result. Unless our GitHub Actions workflows are robust enough to account for this variability, it’s common for an agent to succeed at a task while the test still fails—a “false negative” that halts production.
This blog post explores how to move past brittle, step-by-step scripts and toward an independent “Trust Layer” for agentic validation. We will demonstrate a model that focuses on essential outcomes rather than rigid paths, providing a way to validate behavior that is explainable, lightweight, and ready for real-world CI pipelines.
The challenges of agent-driven validation
Imagine you’re responsible for a GitHub Actions pipeline that relies on Copilot cloud agent to validate real-world workflows. The agent could be leveraging Computer Use, navigating within a containerized cloud environment, for the workflow validation.
On Tuesday, the build is green. On Wednesday, the test fails—even though no code has changed.
Here’s what happened: A minor network lag on the hosted runner caused a loading screen to persist for a few extra seconds. The agent waited, adapted, and successfully completed the tasks correctly. But your CI pipeline still flagged the run as a failure—not because the task failed, but because the execution path no longer matched the recorded script or assertion timing.
The agent didn’t fail. The validation did.
This surfaces three recurring pain points that create a “trust gap” in agent-driven testing:
- False negatives: The task succeeded, but the test runner could not tolerate variation.
- Fragile infrastructure: Tests fail due to timing, rendering, or environmental noise unrelated to correctness.
- The compliance trap: The outcome may be correct, but a regression is flagged because the agent’s behavior diverges from what the automated test expected.
We’re in a transition period where agentic systems like Github Copilot Coding Agent are enabling faster development, but our traditional validation approaches remain rigid. In deterministic software, correctness is as simple as matching a specific input to a known output. But with agents, the process in between is intentionally non-deterministic. As agents are increasingly deployed in production, correctness isn’t about following a prescribed set of steps—it’s about “reliably achieving the essential outcomes.”
To scale these systems, we need a validation framework that can distinguish between “incidental noise” (e.g., a loading screen) and “critical failures” (e.g., failing to save data). Correctness shifts from “did this happen?” to “what had to happen for success to be real?”
Why existing testing approaches break down for autonomous agents
Traditional testing tools work well when execution paths are fixed. They struggle when behavior branches—the tools begin to fracture, not because they’re poorly engineered, but because they assume a stable sequence.
When we apply these to a Copilot Coding Agent, including when navigating a containerized environment, the limitations become clear across four common paradigms:
- Assertion-based testing: Requires manual, labor-intensive specifications for every check and fails to account for valid alternative execution paths.
- Record-and-replay tools: Highly sensitive to environmental noise; minor rendering differences or timing variations often trigger false failures.
- Visual regression testing: Compares screenshots in isolation without understanding the broader execution flow or semantic meaning.
- ML oracles: These “black boxes” require thousands of training examples and offer no explainability when they flag a behavior as incorrect.
While these approaches differ in implementation, they share a common structural assumption: Correctness is defined by adherence to a particular sequence of observable states.
For agentic systems, that assumption breaks down. To build true developer trust in these systems, including Github Copilot, we must move beyond checking linear scripts and start validating structured behaviors.
Reframing correctness: Essential vs. optional behavior
To move past brittle tests and build the Trust Layer, we have to fundamentally change how we define “correct.” In agentic systems, correct executions don’t have to look identical. They do need to share a common logical structure.
The conceptual shift
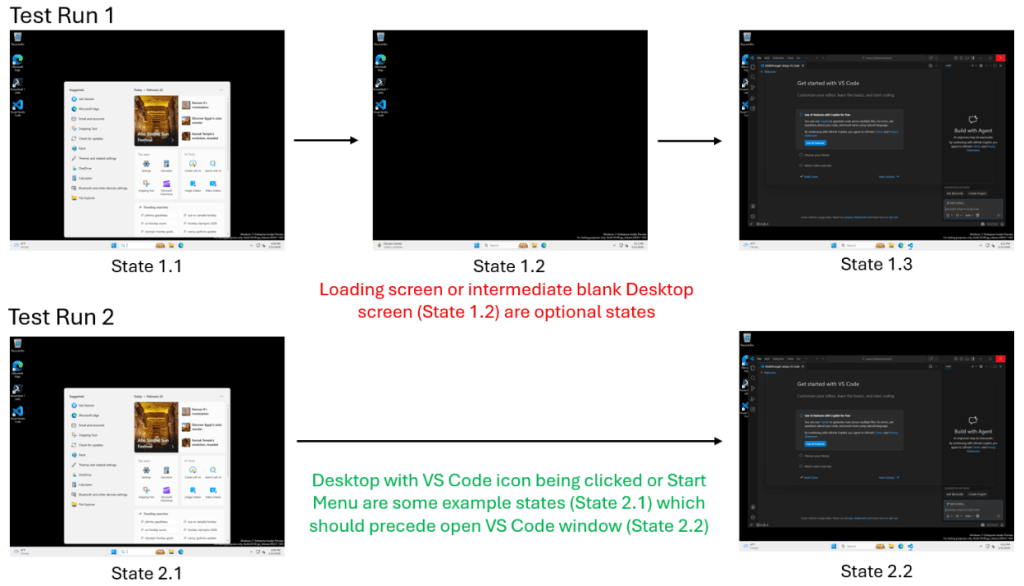
Think of a computer use-enabled Github Copilot Coding Agent performing a search in VS Code in a containerized cloud environment. In one run, a loading screen appears for several seconds; in another, the UI loads instantly (shown below).
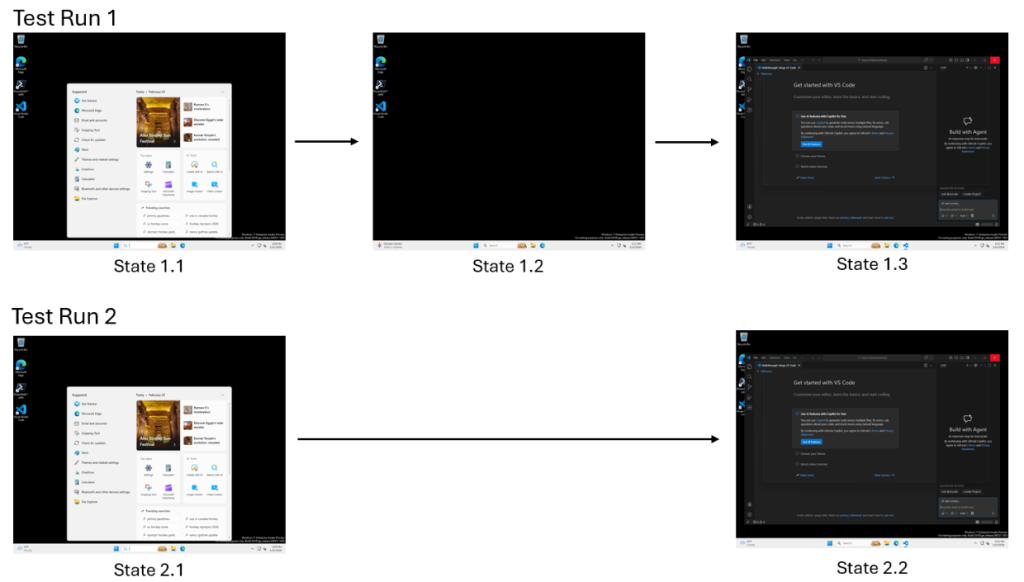
A traditional test sees these as two different results. But to a developer, the loading screen is incidental; it doesn’t change whether the task was successful.
We can classify agent behavior into three categories:
- Essential states: Milestones that must occur for success to be real, such as reaching the “Search Results” screen.
- Optional variations: Incidental states such as loading spinners or decorative UI changes that vary based on environment.
- Convergent paths: Different sequences of steps (like using a hotkey vs. a menu) that ultimately rejoin at the same outcome.
A loading screen may appear or not. But search results must appear. Only one of these determines correctness.
From intuition to theory: Dominator analysis
The distinction between “must-have” and “incidental” behaviors is a concept rooted in compiler theory known as dominator relationships.
In a control-flow graph, a node A “dominates” node B if every path from the start to B must go through A.
By applying dominator analysis to agent execution traces, we can automatically identify:
- Which states are mandatory
- Which states are optional
- Where different paths converge
This lets us extract a minimal, explainable definition of correctness.
Modeling executions as graphs, not scripts
To capture the complexity of agentic behavior, we must move away from treating executions as linear, one-dimensional scripts. Instead, our framework models behavior using a graph-based structure known as a Prefix Tree Acceptor (PTA).
From linear traces to structured graphs
In this model, an execution is not a series of commands but a directed graph where:
- Nodes represent observable states, such as screenshots for UI agents or code snapshots for development agents.
- Edges represent transitions, capturing the actions (clicks, keystrokes, or API calls) taken to move between states.
Why graphs matter
Treating executions as graphs allows us to represent branching and convergence—concepts that are impossible to capture in a linear script.
- Branching accounts for non-deterministic environment changes, like the presence or absence of a loading screen.
- Convergence identifies where these different paths rejoin, signaling that the agent has successfully navigated a variation and returned to the primary task flow.
By shifting the representation from a sequence of steps to a structured behavior model, we stop penalizing agents for taking a different path and start validating whether they followed a logically sound one.
How we solve it: A structural approach to correctness
To move agents from experimental demos to production-grade infrastructure, our team developed a novel validation algorithm that moves away from rigid scripts and instead learns by example. To test this, we focused on a complex non-deterministic environment: an AI agent navigating Visual Studio Code via “Computer Use.” By observing just 2–10 successful sessions, our algorithm automatically constructs a “ground truth” model that distinguishes between an agent’s valid variations and actual failures.
The workflow: From traces to a “master” graph
- Capture (PTA Construction): We collected 2–10 successful execution traces and converted them into Prefix Tree Acceptors (PTAs), directed graphs where nodes represent observable UI states and edges represent actions.
- Generalize (Semantic Merging): Our algorithm merged these traces into a unified graph. It employed a three-tiered equivalence detection framework—combining fast visual metrics with LLM semantic analysis—to decide if two states are logically equivalent, such as ignoring a timestamp change while flagging a missing UI control.
- Extract the Skeleton (Dominator Analysis): We applied dominator analysis to the merged graph to identify “essential states,” milestones every successful run must pass through—while automatically filtering out “optional” states like loading spinners.
This approach is uniquely powerful for developers because it requires no manual specification and no large-scale model training. Because the resulting model is a graph of actual execution states, the decisions are entirely explainable. When validation fails, our algorithm provides clear failure reasoning by identifying exactly which essential state was missed.
Deciding when two states are “the same”
State equivalence is the hardest problem in agent validation. For example, how do we know if two different screenshots represent the same logical UI state?
We solve this using a three-tier equivalence detection framework that moves from fast visual metrics to deep semantic understanding:
- Visual metrics: We use fast perceptual hashes and structural similarity (SSIM) to catch near-identical states immediately.
- Semantic analysis via LLM: When visual metrics are ambiguous, we use a multimodal LLM to decide if differences are semantically meaningful. For example, the LLM knows to ignore a timestamp change or a different window decoration but will flag a different error message or missing UI control.
- Conservative merging: We only merge states when the model is certain they are equivalent, allowing the graph to naturally branch where execution paths genuinely diverge.
This is not a naive pixel-by-pixel comparison, nor is it “LLM hand-waving” where the model is asked to judge the whole task. By using the LLM defensively and sparingly to resolve specific ambiguities, our framework remains robust enough to handle UI noise but precise enough to detect a real regression.
Extracting what actually matters with dominator analysis
Once the various execution traces are merged into a unified graph, our algorithm applies dominator analysis to isolate the core skeleton of the task.
- Defining “essential” through dominance: In graph theory, State A dominates State B if every possible path from the start to B must pass through A. In our model, we define a state as essential if it is a dominator for the successful completion of the task.
- The filtering process: By calculating these mathematical relationships, the algorithm automatically distinguishes between “must-have” milestones and “incidental” noise.
In our VS Code experiments, the “Search Dialog” state is identified as an essential milestone because it is a mathematical dominator—it is logically impossible to reach the results without first triggering the search. Conversely, a “Loading” screen dominates nothing; because it is bypassed in faster runs, the algorithm flags it as an optional variation rather than a requirement for success. This ensures the “Trust Layer” framework only alerts you when a critical step is missed—not when the environment fluctuates.
By extracting these essential nodes into a dominator subtree, we create a “ground truth” model that represents the minimal, explainable definition of correctness. This shifts the validation focus away from the specific steps the agent took and toward the critical checkpoints it was required to hit.
Validating new executions in practice
With the dominator tree established as our ground truth, validating a new, unseen execution becomes a process of structural comparison rather than a search for a perfect match. This ensures that as long as a cloud agent hits the “must-have” milestones, it is free to navigate the environment, or adapt its integrated Computer Use path, as it sees fit.
When a new execution trace arrives, our validation algorithm extracts its sequence of states and checks it against the dominator tree using topological subsequence matching.
- The logic: We don’t require the new trace to be identical to the reference; we only require that the essential states appear in the correct relative order.
- Handling extras: If the reference sequence is A → B → C and the agent produces A → X → B → Y → C, the test still passes because the extra states (X, Y) are treated as incidental noise.
- Detecting failure: A failure is triggered only if an essential state is skipped or if the states appear out of the required logical order.
Scoring and explainability
Our framework produces more than just a binary pass/fail; it provides a coverage metric and a clear explanation:
- Coverage: Calculated as the percentage of matched essential states relative to the total number of states in the reference model.
- Failure reasoning: If a trace fails, our algorithm identifies exactly which state was missing (e.g., “Failed: State ‘Search Results’ never reached after ‘Search Dialog’”).
This level of detail transforms the validation from a “black box” into a diagnostic tool that developers can actually use to debug their agents and their environments.
What we learned from evaluation
To prove the efficacy of this structural approach for Trust Layer, we conducted a controlled experiment comparing our Dominator Tree method against an agent’s self-assessment (where the Computer-Use Agent, or CUA, reports its own success) in a real-world scenario: a Copilot Agent custom VS Code extension test suite.
The accuracy gap
In tests designed to differentiate successful executions from those failing due to product bugs or agent errors, the results were definitive:
| Metric | CUA Self-Assessment | PTA (Dominator Tree) |
|---|---|---|
| Accuracy | 82.2% | 100% (+17.8) |
| Precision | 83.3% | 100% (+16.7) |
| Recall | 60.0% | 100% (+40.0) |
| F1-Score | 69.8% | 100% (+30.2) |
While the agent (CUA) frequently misreported failures as successes, often due to timing out or misinterpreting its own state, the Dominator Tree achieved perfect differentiation by focusing on whether essential milestones were actually reached.
Identifying “not a bug” scenarios
The most significant impact for developers is in the reduction of “false alarms.” When a test fails, you need high-signal feedback to know if the product code is broken or if the agent simply stumbled due to environmental noise.
- The “Self-Verification” Gap: In our evaluation, the agent’s internal self-assessment (CUA) was completely unable to identify “Not a Bug” scenarios (0% F1-score). This shows that agents cannot yet reliably grade their own homework in non-deterministic environments.
- The Structural Advantage: By using state and action equivalence within the dominator model, our independent Trust Layer achieved a 52.2% F1-score in correctly identifying when a failure was an agent execution error rather than a product regression.
The takeaway
Structural validation beats self-reported success by a wide margin. By moving the “source of truth” from the agent’s internal logic to a learned external structure, we can significantly reduce the manual review time wasted on flaky test results and false positives in CI pipelines.
Where this fits in developer workflows today
For this Trust Layer framework to be effective, it must move beyond a research prototype and integrate directly into the systems developers use every day. By treating correctness as a learned structure rather than a rigid script, we can significantly improve the reliability of production-grade automation within the GitHub ecosystem.
Integration points
This approach is designed to strengthen several critical areas of the software development lifecycle:
- GitHub Actions Pipelines: By reducing false negatives caused by environmental noise (like transient loading screens), this method provides a “higher signal” for automated builds, preventing unnecessary pipeline blocks.
- Regression testing: Developers can use a handful of verified traces from a stable version to create a “ground truth” model that automatically validates future updates.
- Agent evaluation: Instead of relying on an agent to report its own success, teams can use structural validation to measure how often an agent actually hits essential milestones.
- UI automation: The framework allows for more robust automation of complex desktop and web apps where UI elements or paths may shift slightly between versions.
The ultimate goal of this framework is to move agents from “experimental demos” to “production infrastructure.” By providing reasoning, where a failure clearly points to a missing essential state, we give developers the transparency they need to trust autonomous systems in their workflows.
What’s next
While structural validation represents a significant leap forward, our current framework has a few boundaries as it moves toward full maturity.
Current limitations include:
- Requirement for success traces: The algorithm “learns by example,” meaning it requires 2–10 successful execution traces to build its ground truth model. It cannot yet learn or define correctness exclusively from failure logs.
- LLM dependency: Our semantic equivalence checking currently relies on multimodal LLM access. While this enables the “intelligence” to ignore timestamps or window decorations, it introduces an external API dependency and associated latency into the validation layer.
- Temporal blind spots: The current implementation validates the order of events, but cannot yet flag if a specific state (like a loading spinner) persists for too long.
Future work includes:
- Temporal and negative constraints: Future work focuses on capturing timing requirements (e.g., “loading must resolve within five seconds”) and learning from negative examples to explicitly block known failure paths.
- Hierarchical and multimodal abstraction: The framework will evolve to cluster low-level screenshots into high-level concepts (e.g., a “Launch Sequence”) while integrating non-visual signals like DOM structures, accessibility trees, and network traffic.
- Online learning: We aim to implement real-time model refinement. As our algorithm validates new successful runs, it will recompute dominators to continuously improve its understanding of what is truly “essential.”
Why this matters now
As AI agents move from experimental demos to core infrastructure, validation has to evolve with them and move past brittle scripts to resilient systems.
We don’t need black-box models to judge other black-box models. We need structural guarantees developers can inspect, reason about, and trust.
By combining classic compiler theory (i.e., dominator analysis) with multimodal AI, we’ve demonstrated that it’s possible to learn an explainable, robust definition of success from just a handful of examples. This framework for the Trust Layer provides:
- Efficient learning: Automatic derivation of ground truth from passing examples.
- Operational robustness: Secure handling of non-deterministic behavior and environmental noise.
- Total transparency: Explainable results with clear reasoning that developers can act upon.
As we move forward, focusing on these practical, explainable paths will be essential to ensuring that the GitHub Copilot Coding Agent is not just powerful, but also a trustworthy component of the developer workflow. This is particularly critical with the increasing adoption of Computer Use in the overall AI-native development lifecycle. By moving the “source of truth” from an agent’s internal logic to a learned external structure, we provide the guarantees needed to make autonomous agents viable, production-grade tools in modern infrastructure.
Our journey toward verifiable autonomy is just beginning. For a deep dive into our Dominator Analysis-based framework, you can read the complete paper.
Tags:


Related posts
Copilot vs. raw API access: What are you actually paying for?
Copilot now bills usage at listed API rates. Compare direct model access with the coding workflow, policy, and harness work around it.

How to build interactive experiences with canvases
Canvases turn AI into interactive workspaces where you can visualize information, explore workflows, and take action across complex tasks.
Better tools made Copilot code review worse. Here’s how we actually improved it.
How migrating Copilot code review to shared Unix-style code exploration tools reduced review cost by reshaping agent workflows around pull request evidence.