Harness the power of GitHub Actions. Learn more or get started now.
Get started with v4 of GitHub Actions Artifacts
We listened to your feedback and released new versions (v4) of actions/upload-artifact and actions/download-artifact. While this version of the actions to upload and download artifacts includes up to 10x performance improvements and several new features, there are also key differences from previous versions that may require updates to your workflows.

|
10 minutes
We recently released the latest iteration (v4) of the actions to upload and download artifacts in GitHub Actions. Artifacts are a powerful tool to augment your GitHub Actions workflows, allowing data to be persisted between jobs, and even after a workflow run has completed. For example, artifacts can store test results, code coverage reports, binary files, core dumps, and more. There are approximately four million artifacts created every day on GitHub, and we’re proud to announce they have become up to 10x faster, more reliable, and even more flexible to use.
In this post, we’ll give a brief overview of how the artifacts feature in GitHub Actions came to be, how it’s evolved over the years, and all the decisions on rebuilding it to better support our customer’s needs.
History of the actions to upload and download artifacts
When GitHub Actions launched in 2019, our initial versions of upload-artifact and download-artifact were extremely simple. In this version, aptly referred to as v1, we utilized existing functionality and plugins within the GitHub Actions runner. For example, the runner’s log upload service was adapted to facilitate artifact uploads and downloads. This approach allowed us to provide crucial download and upload capabilities as soon as GitHub Actions was launched.
Because the v1 upload and download functionality was so tightly coupled with the runner, releases between the artifact actions and the runner were also tied together. This proved to be problematic, so we decided to decouple the upload and download functionality from the runner and rewrite everything in NodeJS, just like other actions. However, we wanted developers to be able to leverage artifact upload and download functionality in their own actions, so we decided to create an @actions/artifact npm package with all the functionality that anyone could use. This npm package served as the foundation for v2 of upload-artifact and download-artifact. There were also releases of v3 upload-artifact and download-artifact; however, they were largely identical to the v2 releases just with a newer node runtime. Fundamentally, v1-v3 were all powered by the same internal APIs to upload and download artifacts that were based off of the runners log upload service.
Challenges with the previous versions of the artifact actions
The retrofitted log upload service that powers v1-v3 artifact upload/download was fine for small uploads, and it covered basic customer needs, but it wasn’t without its drawbacks. The following issues became recurring pain points for our users and so it was essential for us to address them in the latest release.
Internal APIs
The first three versions of the actions to upload and download artifacts were initially created to facilitate sharing artifacts between isolated jobs within the same workflow run. Because of this, an artifact is scoped to an entire workflow run and is not “finalized” until the very end of that run. This is necessary for things like billing where the size of an artifact could be changed between jobs, and it wouldn’t be until the end of the entire workflow run that the final size would be known. Scoping artifacts to the entire workflow run meant that the artifacts would not be available in the UI or REST API until after the workflow run is completed. Many users, however, wanted to share artifacts with jobs outside of the current workflow run. This inflexibility made it difficult to scaffold more solutions on artifacts during the course of a workflow run to achieve certain processes, like viewing artifacts produced from a “build” job before an approval gate to use those artifacts in a “release” job. We often found users building around the internal APIs which are not publicly documented and lack strict API stability or polling public APIs in different workflow runs until a run was completed to list artifacts to fit their use cases, which shouldn’t be necessary.
File “stomping” and corrupted artifacts
In the previous upload-artifact versions, it’s possible to upload from the same named artifact multiple times, in multiple jobs, concurrently. This, unfortunately, made it extremely easy to accidentally overwrite same named files in matrix scenarios, causing undefined behavior with concurrent writes to different chunks of a file.
Another common case of corruption was transient errors during artifact downloads (via zip). This is due to the nature of how artifact archives are generated for downloads in the previous versions. In the backend blob storage, v3 and below are stored as loose files. On upload, files are gzipped, chunked, and reassembled by the backend service before their final rest in blob storage. When artifact zips are requested via the REST API or the UI, they must be dynamically generated and populated with each file. This design not only increased the likelihood of transient network errors and corruption but also prevented us from providing any sort of checksum or estimated size for the artifact archive.
Artifact size discrepancies
Often, it was unclear how the reported and billed size of an artifact, the size of the files on upload, and the size of the zip archive downloaded from the UI were computed. As mentioned previously, artifacts in v3 and below are stored in the blob backend as loose files, and the zip is generated dynamically on download. Depending on the type of content, gzip compression could cause the reported size to be drastically different from the actual size and both of those sizes are completely different from the dynamically generated archive size.
Speed and general performance
The most frequently heard pain point related to v3 and below was the overall speed of artifact download and upload operations. There are two specific cases that can cause major slowdowns:
- Large, poorly compressible files. On the runner, these are chunked (and gzipped) which can create a lot of wasted CPU time. Once they are sent to our backend, it must be decompressed and reassembled into the blob storage.
- A lot of individual files. Since these are “loosely” stored in the backend, a reference is created for every file, which drastically slows down the total upload time. Similarly for download, each file must be fetched and placed into the dynamic zip archive.
This is especially a problem for our customers on self-hosted runners outside our hosted compute environment, which worsened the speed of both upload and download operations.
What’s improved in v4
Performance and speed
Our primary focus with the new release was speed. To achieve better operations holistically, we had to simplify the entire process and remove as many moving parts as possible.
First, we eliminated having a proxy service in between uploads for the runner and blob storage. Our backend API delegates shared access signatures (SAS) based on token authorization to a specific file path in blob storage. This allows for direct, secure and limited access for the runner clients to upload the artifact. The SAS is minted against a well-known path, which is how we properly scope customer data and track usage on the uploaded content size. The process is exactly the same for downloads, except the SAS is read only. This is agnostic to all clients, so the same process for the runner, UI, and REST API downloads.
As part of the above solution, we scoped all the artifact content to a single archive zip on upload. The runner will assemble the zip archive in memory, streaming in files as part of the upload specification and chunked uploads to blob storage. This allows us to better calculate the file size, as well as compute a checksum of the content. And since this is a singular file upload, it saves precious time on all the network round trips that previously had to be made for every single file. We also have additional inputs like compression-level that can be tweaked to further increase upload speed (or artifact size) depending on how well the content can be compressed.
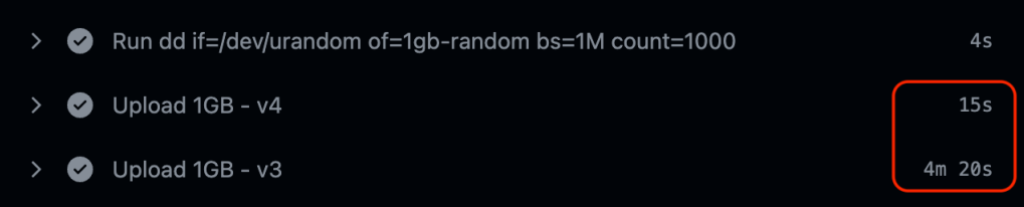
With all of these improvements, it’s night and day for the worst case scenarios. For instance, like uploading hefty node_modules.

And now that our file is already stored in blob as a zip, we no longer need to manually assemble the archive anymore, it’s just a direct download from blob.

From numerous artificial and real world tests we’ve seen over 10x improvement in upload and download operations from these changes.
Workflow YAML
name: Artifacts Comparison
on:
workflow_dispatch:
jobs:
node-modules:
runs-on: ubuntu-latest
steps:
- uses: actions/setup-node@v4
- run: |
npm i react react-dom react-script create-react-app webpack
- uses: actions/upload-artifact@v4
name: "Upload Node Modules - v4"
with:
name: node_modules-v4
path: node_modules
- uses: actions/upload-artifact@v3
name: "Upload Node Modules - v3"
with:
name: node_modules-v3
path: node_modules
- uses: actions/download-artifact@v4
name: "Download Node Modules - v4"
with:
name: node_modules-v4
path: node_modules-v4
- uses: actions/download-artifact@v3
name: "Download Node Modules - v3"
with:
name: node_modules-v3
path: node_modules-v3
big-artifact:
runs-on: ubuntu-latest
steps:
- run: |
dd if=/dev/urandom of=1gb-random bs=1M count=1000
- uses: actions/upload-artifact@v4
name: "Upload 1GB - v4"
with:
name: 1gb-v4
path: 1gb-random
compression-level: 0
- uses: actions/upload-artifact@v3
name: "Upload 1GB - v3"
with:
name: 1gb-v3
path: 1gb-random
- uses: actions/download-artifact@v4
name: "Download 1GB - v4"
with:
name: 1gb-v4
path: 1gb-v4
- uses: actions/download-artifact@v3
name: "Download 1GB - v3"
with:
name: 1gb-v3
path: 1gb-v3
Immediate public API availability
Another common request from our users was the ability to download artifacts from the UI or API while the workflow run is in progress. Previously, this was not possible because of the internal APIs and how the data is populated in the backend and because artifacts were scoped to an entire workflow run and not “finalized” until the very end.
Now, in v4, the artifact becomes immediately available in the UI and the API. Even better, the actions/upload-artifact action now has outputs for both the ID of the artifact, and the URL for the artifact.
This allows for even more powerful workflows that use artifacts. For instance, you now have the ability to create an approval gate and inspect an artifact’s content manually via the UI before approving for a release. Artifact URLs can also be embedded using bots and comments in pull requests for easy sharing.
Cross-run (or repository) downloads
The action to download artifacts has some new addons as well. In the list of inputs, we now have github-token, repository and run-id. Given a properly scoped token with actions:read, artifacts can now be downloaded from other workflow runs and repositories. By default with no token specified, the action will only be able to download from the current workflow run and any previous run attempts.
Reported size and immutability
Thanks to the single archive file upload, the stated size of the artifact is now consistent between the content uploaded, content downloaded, and what is reported in UI and APIs. Similarly, we are now able to produce checksums as the data is being uploaded on the runner, which we plan to expose for integrity checks soon. Stay tuned for future enhancements that will expose even more artifact metadata.
Compatibility
In an ideal world, we’d add all these new improvements, and everything would just work. Unfortunately, these improvements do come with some tradeoffs. First and foremost, the new major version tag, v4, cannot be mixed and matched with v3 and below. If you are uploading with actions/upload-artifact@v4, you must download with actions/download-artifact@v4.
In v4, users lose the ability to upload to the same named artifact multiple times. Once an artifact is uploaded cannot be altered, and there cannot be multiple v4 artifacts with the same name, in the same workflow run. An example scenario where this would cause friction is a job matrix where multiple jobs would concurrently push uploads to the same artifact. In v4, this would cause an error. To make this scenario possible, artifacts can have the matrix attributes suffixed to the name, and then all the artifacts can be downloaded to the same directory.
Example YAML diff
jobs:
upload:
strategy:
matrix:
runs-on: [ubuntu-latest, macos-latest, windows-latest]
runs-on: ${{ matrix.runs-on }}
steps:
- name: Create a File
run: echo "hello from ${{ matrix.runs-on }}" > file-${{ matrix.runs-on }}.txt
- name: Upload Artifact
- uses: actions/upload-artifact@v3
+ uses: actions/upload-artifact@v4
with:
- name: my-artifact
+ name: my-artifact-${{ matrix.runs-on }}
path: file-${{ matrix.runs-on }}.txt
download:
needs: upload
runs-on: ubuntu-latest
steps:
- name: Download All Artifacts
- uses: actions/download-artifact@v3
+ uses: actions/download-artifact@v4
with:
- name: my-artifact
path: my-artifact
+ pattern: my-artifact-*
+ merge-multiple: true
- run: ls -R my-artifact
To ensure fair use of these actions, we've imposed a limitation where a single job can only produce 500 artifacts at maximum.
Since there is no longer a proxy, users configured on self-hosted runners must have appropriate network configuration to reach our new array of storage backends. See the self hosted documentation to ensure all endpoints are reachable.
For additional common migration scenarios, you can reference our migration documentation.
GHES
For updates on bringing v4 of the artifact actions to GitHub Enterprise Server, please follow the GitHub public roadmap.
Tags:


Related posts

What’s coming to our GitHub Actions 2026 security roadmap
A look at GitHub Actions’ 2026 roadmap, outlining how secure defaults, policy controls, and CI/CD observability harden the software supply chain end to end.
Updates to GitHub Copilot interaction data usage policy
From April 24 onward, interaction data—specifically inputs, outputs, code snippets, and associated context—from Copilot Free, Pro, and Pro+ users will be used to train and improve our AI models unless they opt out.

GitHub availability report: February 2026
In February, we experienced six incidents that resulted in degraded performance across GitHub services.