Cueing up a calculator: an introduction to exploit development on Linux
Using CVE-2023-43641 as an example, I’ll explain how to develop an exploit for a memory corruption vulnerability on Linux. The exploit has to bypass several mitigations to achieve code execution.

In this follow-up to my previous blog post, I’ll explain how to exploit CVE-2023-43641 (a memory corruption vulnerability in libcue) to create a reliable 1-click RCE on Ubuntu 23.04 and Fedora 38. I have also published the source code of the proof of concept.
To quickly recap the previous blog post:
- libcue is a library used for parsing cue sheets—a metadata format for describing the layout of the tracks on a CD.
- CVE-2023-43641 is an out-of-bounds array access vulnerability in libcue, which enables an attacker to overwrite the memory of the process.
- The attacker is able to control both the array index and the value that’s written, making it a very powerful vulnerability.
- tracker-miners is an application that’s included by default with GNOME.
- tracker-miners automatically scans new files in your
~/Downloadsfolder and if the filename extension is.cuethen it uses libcue to scan the file.
Because tracker-miners uses libcue to automatically scan the downloaded file, it only takes one click on a malicious webpage for an attacker to get code execution on your computer:
I’m using this vulnerability as an excuse to write an “introduction to exploit development” blog post. (If you already know a lot about this topic, you can skip directly to the “Thread context” section, which is where I start discussing the specifics of how to exploit CVE-2023-43641.) A few years ago, I didn’t know anything about exploiting memory corruption vulnerabilities and decided I wanted to learn. Most of what I know now has come from studying the examples in the (awesome) how2heap repository, and from trying to apply those techniques to real-life vulnerabilities that I’ve found. I find that creating a working exploit is often very hard work, but, once you understand the principles, it’s not as magical as it might look. This blog post is written for somebody who understands C, but doesn’t know anything about exploit development (me a few years ago).
Every exploitation challenge is different. There is no one technique that will always work because it depends greatly on what kind of bug you have, and what capabilities it gives you. However, individual techniques are often reusable. This is particularly true for glibc malloc exploitation, which has a long history. A famous document called the Malloc Maleficarum introduced many of the techniques and gave them names like “House of Force” and “House of Spirit.” The how2heap repository contains examples of all of those techniques, and also categorizes them according to which glibc versions they work on, as some of the older techniques have since been foiled by integrity checks. Some of the techniques that I’ll describe in this blog post are reusable, while others are very specific to the tracker-extract and libcue codebases.
The traditional way to prove that you’ve achieved code execution is by “popping a calc.” So, the end goal of this blog post is to get tracker-extract to execute the following command:
gnome-calculator -e 1337
The extra arguments are so that the calculator starts with 1337 on the screen. It’s an important detail. 😁
Bypassing mitigations
Most of the challenge of exploiting a memory corruption vulnerability is in bypassing the various mitigations that have been designed to thwart you. These are the main ones on Linux:
- No-execute memory
- ASLR
- Stack canaries
- Integrity checks in glibc
malloc - Sandboxing
No-execute memory
Back in the good ole days, you could use a simple buffer overflow to put some shellcode on the stack and jump to it. That’s no longer possible, because, by default, the stack and heap are not executable: they are only given rw- permissions, which means readable and writable, but not executable. The developer would have to explicitly call mprotect to override that, and the only legitimate reason that I’m aware of why anyone would do that is if they’re writing a JIT compiler. In other words, you can’t just create your own machine code and execute it—you have to find a way to reuse the existing code of the application. The existing code has r-x permissions, which means it’s readable and executable, but not writable.
ASLR
No-execute memory really isn’t that much of an obstacle though, because you can just overwrite a code pointer instead. A very common variant of this technique is to overwrite the return address on the stack. This strategy is known as creating a ROP chain. The stack contains the address of the code where execution should continue after the function returns, so by overwriting that pointer, you can jump to a completely different function. A prime target for this is glibc’s system function, which starts a shell and runs an arbitrary command. The goal of the second mitigation, ASLR, is, therefore, to prevent this by randomizing the addresses so that you cannot predict the addresses of functions like system.
The exploit in this blog post does not use a ROP chain, because I will overwrite a function pointer in the heap instead, but I do need to defeat ASLR, which is the most complicated part of the exploit.
Stack canaries
Stack canaries protect against buffer overflow vulnerabilities on the stack. The stack canary is a random 64-bit number that gets written at the top of every stack frame. If you’re using a buffer overflow vulnerability, such as an unbounded memcpy, to write a contiguous array of bytes to the stack, then you cannot overwrite the return pointer without also overwriting the stack canary. The value of the canary is checked before the function returns, and the program will abort if it has been corrupted. Stack canaries only protect against a very specific class of vulnerabilities: if you’ve got a vulnerability like an out-of-bounds array access which lets you choose which parts of the stack to overwrite, then the canary has no effect. Also, if you’re able to deduce the value of the canary (which is constant for the lifetime of the process) then you can just write the correct value to the stack to bypass the mitigation. Stack canaries are irrelevant for the rest of this blog post, because CVE-2023-43641 corrupts the heap, not the stack.
Integrity checks in glibc malloc
If your vulnerability lets you corrupt the heap, rather than the stack, then the glibc malloc implementation is often a very useful stepping stone on the road to code execution. By using your vulnerability to overwrite malloc’s metadata, you can trick it into doing weird things, like allocating the same block of memory twice.
There’s a concept in exploitation that’s known as a “weird machine“: a vulnerability lets you use the existing logic of a program in unintended ways, which gives you a set of “weird instructions” that you can use as a (usually very cumbersome) programming language. The glibc malloc implementation is often very useful as a weird machine, particularly because it’s almost always there: every program has to allocate memory and if you can cause malloc to do weird things then you can influence almost everything else that the program does too. For example, if you trick malloc into allocating two objects at the same address then you can modify the fields of the first object by writing to the fields of the second.
In an attempt to prevent it from being used for exploitation, the developers have added numerous integrity checks to the malloc implementation. For example, you’ve probably seen a program crash with an error message like this:
free(): double free detected in tcache 2
Aborted (core dumped)
That error message can be quite useful for developers who are debugging their code, but it also has a dual purpose of detecting memory corruptions caused by vulnerabilities. A relatively recent addition is “safe linking,” which was added in glibc version 2.32. I thought it would be a significant obstacle while I was developing the exploit, but in hindsight I was actually just confused. It uses XOR to “sign” certain pointers, which makes debugging harder, but apart from that it has almost zero practical impact on the techniques that I want to use.
Sandboxing
Unlike the other mitigations discussed so far, this one isn’t automatic: it needs to be deliberately enabled by the developer. In the case of tracker-extract, the developers have added a seccomp sandbox. The sandbox disallows various system calls—for example, fork and exec are both prohibited. But, as I briefly mentioned in my previous blog post, there was a loophole in tracker-extract’s sandbox, which I exploited completely by accident. Although sandboxing sounds like a bullet-proof solution, we routinely hear of sandbox-escape vulnerabilities, particularly in web browsers.
Do the mitigations work?
There’s no question that the mitigations make exploitation much harder, but that’s not the same thing as making it impossible. With some exploits allegedly selling for millions of dollars, just making it harder isn’t good enough. However, the mitigations do make some bugs unexploitable. For example, stack canaries work against the very specific memcpy-to-stack class of vulnerability that they’re designed to block. But you only need to glance at the news to see the evidence that the mitigations are frequently failing in practice. The reality is that if you have a better bug, or multiple bugs, then the mitigations don’t work. It makes me a little sad, because most of these mitigations have a cost: how much electricity does it cost us all collectively, every time a 1% slowdown is added to malloc? And what’s the point, if it doesn’t actually stop the exploits from working?
A good example of the mitigations failing is CVE-2023-4911, the privilege escalation vulnerability in ld.so found recently by Qualys. They were able to bypass ASLR with brute force. Apparently, it only took them 30s to break it on Debian and 5m on Ubuntu and Fedora. The problem is that ASLR only adds 19 bits of entropy to the stack addresses, which is incredibly weak from a cryptographic perspective. It means that you can easily brute force ASLR if you have the opportunity to run your exploit in a loop. ASLR is slightly more effective against remote exploits, like the one that I’m discussing here, because the remote scenario might prevent an attacker from running the exploit in a loop. My exploit is an example of this because I want it to work immediately on the first click.
Planning the exploit
The reason why I started by explaining about the mitigations is that exploit development is almost entirely about finding a way to navigate around them. I picture it as a kind of treasure hunt:
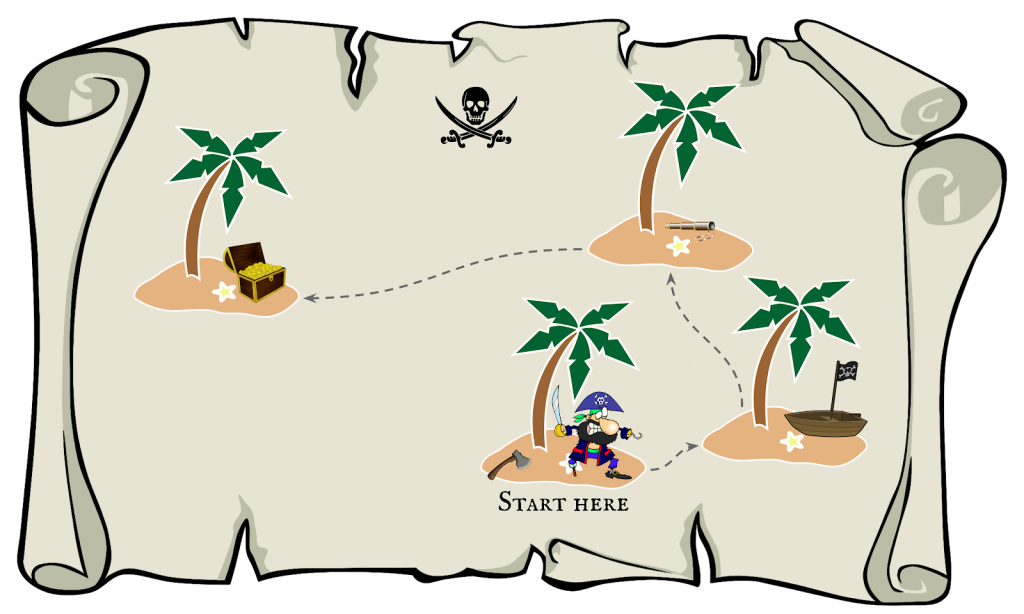
The pirate is trying to get to the treasure, but there’s no direct route. Instead, he has to use the ax to chop down the tree and build a raft to get to the next island, where he finds a better boat. The boat gets him to another nearby island where he finds a telescope, which helps him to reach the final island where the treasure is. Building an exploit is often very similar: it takes multiple steps and you have to find or build useful gadgets along the way.
Therefore, my first step in developing this exploit is to research how libcue is used by tracker-extract and to search for various gadgets in the code that I might be able to use. Then, I’ll make a rough plan for how the exploit will work.
Thread context
As I explained in my previous blog post, tracker-miners consists of two processes: tracker-miner-fs and tracker-extract. tracker-miner-fs runs continuously, whereas tracker-extract is started on demand when a new file is created in ~/Downloads. The exploit is targeted at tracker-extract, because that’s where libcue is used.
As a reminder, the vulnerability is this line of code in track_set_index:
track->index[i] = ind;
I have full control of the values of i and ind, so I can use this to write an arbitrary 64-bit value at an arbitrary offset from track (which is a heap object). There are just two limitations:
imust be negative.indis parsed withatoi(a 32-bit function), so I only have full control over the lower 32-bits of the 64-bit value.
This is the stack trace at the moment when the vulnerability is triggered in track_set_index:
track_set_index (ind=-8984, i=-2864, track=0x7f2270017f00)yyparse ()cue_parse_string (string=0x7f2282060010 "PERFORMER Kev"...)tracker_extract_get_metadata (info=0x7f2270000d10, error=0x7f2282a0f2f0)get_file_metadata (task=task@entry=0x55c712f00440, info_out=info_out@entry=0x7f2282a0f2e8, error=error@entry=0x7f2282a0f2f0)get_metadata (task=0x55c712f00440)single_thread_get_metadata (queue=0x55c712eed750)g_thread_proxy (data=0x55c712ef97c0)start_thread (arg=<optimized out>)
There are a few things to notice here:
1. This is a fresh thread
Tracker-extract starts a fresh thread to run libcue. I have found that this makes the layout of the memory in the heap very predictable, which I’ll discuss in more detail in the next section.
2. Tracker-extract uses glib
glib is an extensive library used by many GNOME applications. It creates a framework for the application and handles things like threading and message queues. It has its own object system, similar to an object-oriented programming language, so it uses function pointers heavily. That means that the easiest way to get code execution is by overwriting one of the function pointers that glib stores in the heap. The function pointer that I will target in this exploit is the dispose method that gets called during g_object_unref:
G_OBJECT_GET_CLASS (object)->dispose (object);
The stack trace at that moment looks like this:
g_object_unref (_object=0x7f2270000d50)tracker_extract_info_unref (info=0x7f2270000d10)…
(I’ve omitted the rest of that stack trace to avoid irrelevant detail.) tracker_extract_info_unref is the callback function that cleans up the info object (of type TrackerExtractInfo) that’s allocated at the beginning of get_file_metadata. It gets called after the code returns from get_file_metadata. It’s a good target because info is a heap object that I can easily overwrite, as I’ll explain in the next section.
3. The bug is triggered during parsing
The bug is triggered every time the downloaded file contains a line like this:
INDEX 4294964432 4294958312
That means that I can trigger the bug many times. I can also interleave it with other statements like TITLE and TRACK to trigger weird behavior in other parts of the parser. My goal is to use this to overwrite the heap, converting info into a fake heap object that will trigger code execution when tracker_extract_info_unref is called on it.
Memory layout
I mentioned ASLR earlier. It randomizes addresses so that you cannot guess the absolute address of a function like system. But it doesn’t affect relative addresses (that is, the distance between two addresses). For example, if a freshly started process calls malloc(0x500) twice in a row, then the second malloc will always return an address that’s exactly 0x510 higher in memory than the first, because fresh allocations come from a large contiguous block of memory. (The extra 0x10 bytes are used for metadata.) A buffer overflow vulnerability also operates on relative addresses. For example, if I have an out-of-bounds write in the first chunk then I can use it to overwrite the contents of the second chunk. It doesn’t matter that I don’t know the absolute address of the second chunk because I know its address relative to the first. So in the early stages of the exploit, I can use my knowledge of the relative addresses of the objects in memory to gain a foothold, in preparation for a proper ASLR bypass later.
The malloc implementation uses a system call (mmap or brk) to request large blocks of memory from the operating system, and then divides those block into smaller malloc_chunk objects (aka “chunks”) which it manages itself, mainly with two data-structures: the malloc_state and the tcache_perthread_struct (aka “tcache”). These data-structures store caches of small-sized memory chunks so that small memory allocations are very fast. The malloc_state also stores larger blocks of memory which can be divided up to create new chunks when the caches are empty. If the application is multi-threaded then each thread gets its own per-thread arena, with its own malloc_state and tcache. The per-thread arena is a freshly mmap-ed block of memory. This is a diagram of the layout of the per-thread arena of the libcue thread:

Notice that the base address of the mmap-ed memory is 0x7f2270000000. It’s always aligned to a multiple of 0x4000000. ASLR only affects the upper bits: the ..2270.. part of the address. (I wasn’t kidding when I said that ASLR is “weak” from a cryptographic perspective.) Relative to this (weakly) randomized base address, I’ve found that the addresses of the heap objects that I care about are incredibly consistent. For example, the info object which I mentioned previously is always at offset 0xd10 from the base address of the mmap-ed memory. The cd object which is the root of the parse tree is always at offset 0x125e0. Some of these offsets are slightly different on Fedora 38 than on Ubuntu 23.04 but on each distribution they never change. For the rest of this blog post, whenever I say something like “at offset 0xe60”, I mean from the base address of the mmap-ed memory.
The alignment of the mmap-ed memory is also very convenient. The bottom 3 bytes of the address are not affected by ASLR, which means that I can forge addresses by overwriting a different pointer with the final 3 bytes of a string. For example, I can convert the address 0x7f227001c500 to 0x7f2270004150 by overwriting the bottom 3 bytes with the string “PA” (P is 0x50 and A is 0x41).
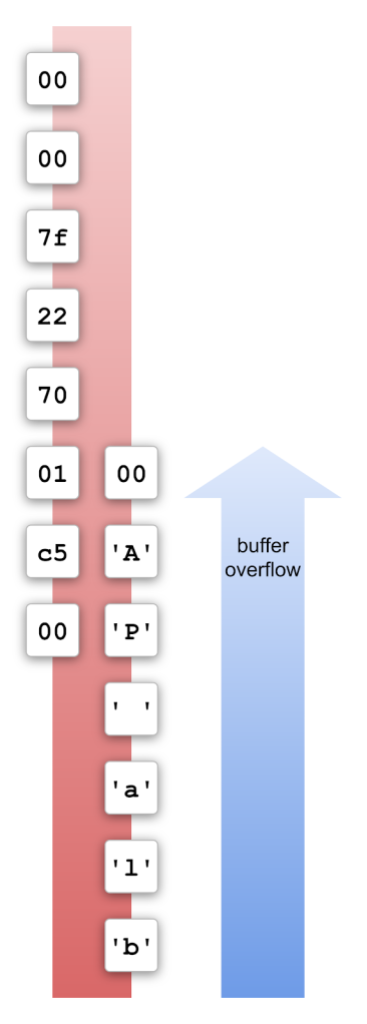
The null-byte at the end of the string overwrites the 3rd byte with 0x00, which means that I can’t forge addresses with an offset greater than 0xffff, but that’s not a problem because most of the addresses that I want to forge have small offsets, like 0xd10 for the address of info.
Stuck on an island
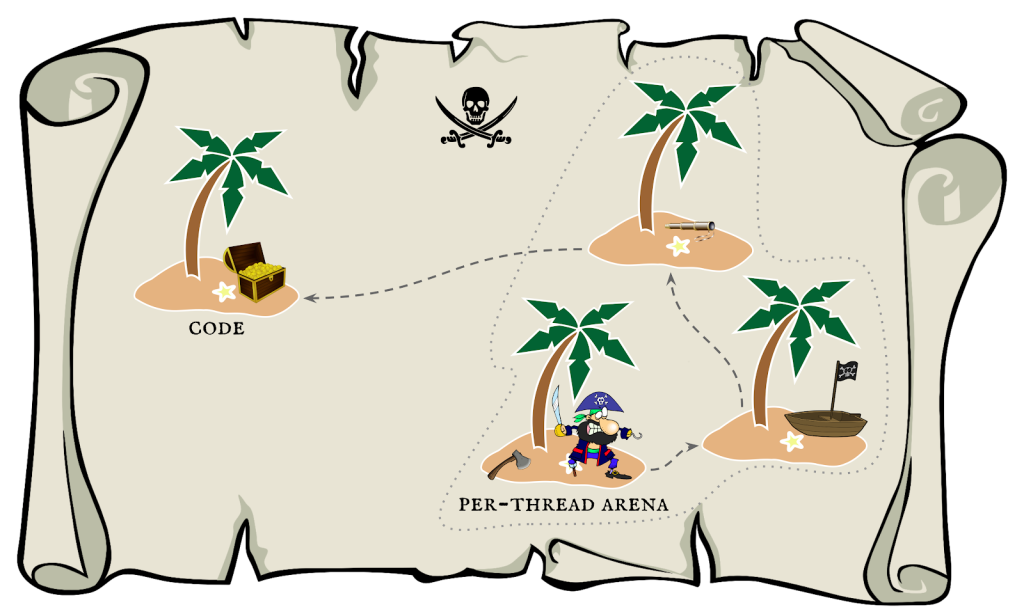
Returning to the treasure hunt analogy, the per-thread arena is a bit like the pirate being stuck on an island in the middle of a large ocean. There are few other islands nearby that he can reach fairly easily if he uses the ax to build a raft, but he’s going to need a better boat and navigation tools to get to the treasure, which is on an island much further away.
I can easily manipulate the memory within the per-thead arena, creating fake objects with forged pointers to other objects within the arena. But I cannot read or write outside the arena for two reasons:
- Other parts of the memory, such as the stack and the code, have different ASLR offsets, which I don’t know.
- The vulnerability in libcue only enables me to overwrite memory at a maximum distance of 16GB from my current location, so I couldn’t directly reach those other parts of the memory, even if I knew where they were.
Luckily, the object-oriented features of glib, which I mentioned earlier, make this challenge much easier than it might have been. I do not need to overwrite other parts of the memory. To get code execution, I only need to compute a valid function pointer (pointing to something like system) and place it within a fake object hierarchy which I can build in the per-thread arena.
So, the only way in which I need to “escape” the per-thread arena is to find a way to compute a valid function pointer (i.e. bypass the ASLR on code addresses). Using gdb’s examine memory command (x/512gx where 512 is the size argument), I searched for function pointers in the per-thread arena and discovered that a pointer to the function g_file_input_stream_real_query_info_finish is consistently stored at offset 0xe60. It’s stored there by g_file_input_stream_class_init:
static void
g_file_input_stream_class_init (GFileInputStreamClass *klass)
{
klass->query_info_async = g_file_input_stream_real_query_info_async;
klass->query_info_finish = g_file_input_stream_real_query_info_finish;
}
That happens before the libcue parsing starts (during the call to g_file_load_contents); and the pointer is still there during parsing.
This discovery is represented by the telescope in the treasure map: the function pointer lets me “see” where the treasure is, because it tells me where the code is. It’s a bit like I now know the location of the tree on the island: it’s not exactly where the treasure is, but it’s very close. The function g_file_input_stream_real_query_info_finish is the tree: it’s not the code that I want to execute, but I can get to the code that I do want to execute by adding a fixed offset to that pointer. The function that I actually want to call is initable_init. It’s very similar to system, but lives in the same shared object (libgio) as g_file_input_stream_real_query_info_finish, so the offset between the two functions is always exactly 0x3b290.
Unlike pointers in the per-thread arena, which are very easy to forge by overwriting the bottom three bytes of the address, code pointers have significantly better ASLR, so I will need to find a way of performing an addition operation to compute the address of initable_init.
Gadgets
This section is mostly very specific to libcue and doesn’t contain any reusable techniques because it relies on specific functions in libcue. But the general principle, which also applies to other targets, is that I need to find gadgets that will let me do things like calling malloc and free, or performing arithmetic operations. Although libcue is quite a simple project, it contains enough useful gadgets to construct a working exploit.
Allocating and freeing strings
Statements like these allocate a new string (and free an old one if it isn’t NULL):
FILE pwned.mp3 MP3
ISRC abcd-efg
TITLE "my title"
PERFORMER "Kev"
For example, a TITLE statement triggers this code:
void cdtext_set(int pti, char *value, Cdtext *cdtext)
{
if (NULL != value) /* don't pass NULL to strdup */
for (; PTI_END != cdtext->pti; cdtext++)
if (pti == cdtext->pti) {
free (cdtext->value);
cdtext->value = strdup (value);
}
}
It calls free on the previous title (which is NULL on the first call) and then strdup to allocate memory for the new title. This gadget is useful for manipulating the heap: allocate some memory, use the vulnerability to corrupt its metadata, then free it again, thereby returning a fake chunk to the allocator.
The cdtext is a simple key-value store, indexed by pti. I considered using this to allocate or free a pointer at a location of my choosing by creating a fake table with the appropriate pti value at the location that I want to overwrite, but I found that I don’t need it, because it’s easier to use cd_add_track, as I’ll explain next.
Writing a pointer to any location
Cue sheets are intended to describe a CD with multiple tracks. This statement adds a new track:
TRACK pwned.mp3 MP3
It triggers a call to cd_add_track:
Track *cd_add_track(Cd *cd)
{
if (MAXTRACK > cd->ntrack)
cd->ntrack++;
else
fprintf(stderr, "too many tracks\n");
/* this will reinit last track if there were too many */
cd->track[cd->ntrack - 1] = track_init();
return cd->track[cd->ntrack - 1];
}
This function is designed to avoid a buffer overflow when the cue sheet contains too many tracks (MAXTRACK==99). In that scenario it prints an error message and doesn’t increment cd->ntrack to avoid writing past the last index of cd->track. But it doesn’t error out and it still writes to cd->track! This code is a very useful gadget because I can use the vulnerability in track_set_index to overwrite the value of cd->ntrack. (The cd object is always at a predictable relative offset from the current track, so I can reliably overwrite its ntrack field.) For example, if I overwrite cd->ntrack with an out-of-bounds value like 1000, then cd_add_track will allocate a new track and write its address to cd->track[999]. I can use this to drop a pointer to a track anywhere in the per-thread arena, so I’ll use this to construct fake object trees there. I’ll also use it when I want to forge a pointer by overwriting the bottom 3 bytes of a valid address, because I can use it to drop a pointer at a location where it’s convenient to overwrite.
Adding an offset
The most crucial requirement for defeating ASLR is the ability to perform some very basic arithmetic. Sometimes, a single addition is all it takes. As I mentioned earlier, I just need to add 0x3b290 to an address that’s stored at offset 0xe60 to get a pointer to the function that I want to call. But I can only find one gadget that will let me do arithmetic and it’s very cumbersome to use. It’s this code in the parser:
| INDEX NUMBER time '\n' {
long prev_length;
/* Set previous track length if it has not been set */
if (NULL != prev_track && NULL == cur_filename
&& track_get_length (prev_track) == -1) {
/* track shares file with previous track */
prev_length = $3 - track_get_start(prev_track);
track_set_length(prev_track, prev_length);
}
if (1 == $2) {
/* INDEX 01 */
track_set_start(track, $3);
long idx00 = track_get_index (track, 0);
if (idx00 != -1 && $3 != 0)
track_set_zero_pre (track, $3 - idx00);
}
track_set_index (track, $2, $3);
}
It’s actually the same part of the parser that I use to trigger the vulnerability, but this time I’m not interested in the call to track_set_index, but instead the two if-statements that precede it. Notice this line in the first if-statement:
prev_length = $3 - track_get_start(prev_track);
and this one in the second:
track_set_zero_pre (track, $3 - idx00);
I control the value of $3, so I can use this to add an offset to the function pointer in two steps. It takes two steps because the input value gets negated in the first step, so I need to un-negate it in the second step. I set $3 == 0 in the first step and $3 == 0x3b290 in the second step to get the desired result.
To make this gadget work, I need to allocate two consecutive tracks with overlapping addresses. It looks like this in memory:
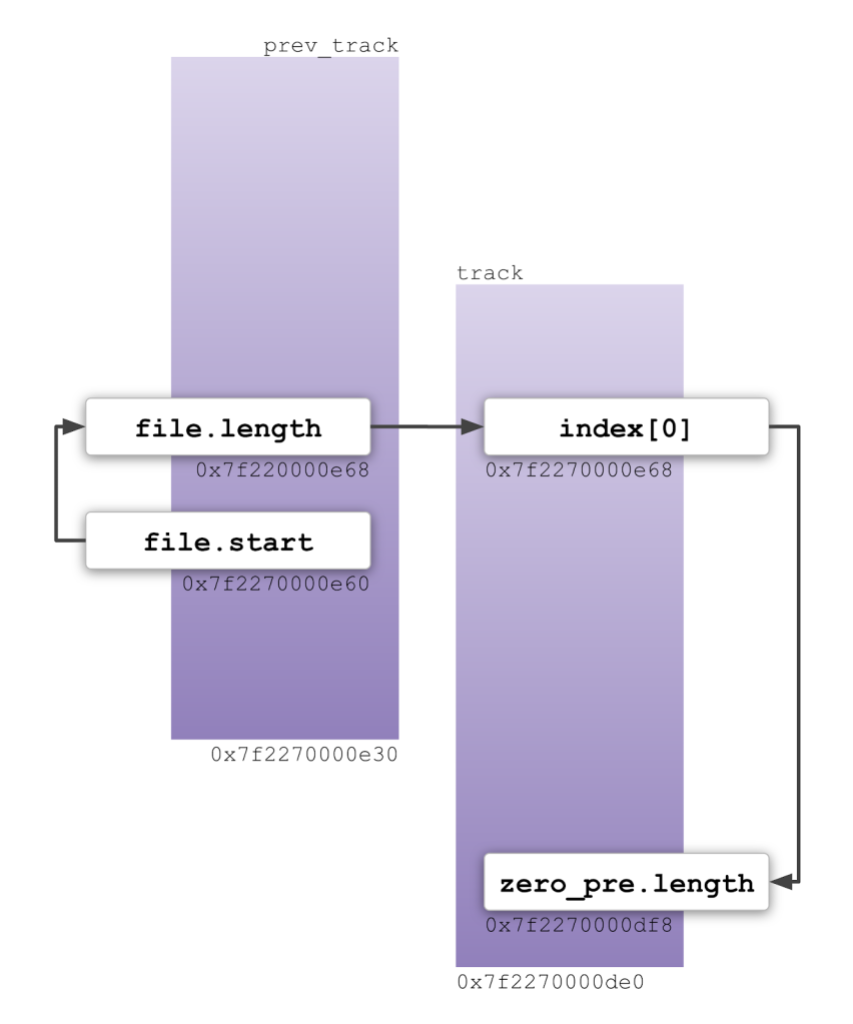
I need to position the first track so that its file.start field overlaps with offset 0xe60, which is where the function pointer is stored. And I need to position the second track so that prev_track->file.length and track->index[0] both have the same address. Then I trigger the two subtraction operations in succession and the updated function pointer is written to the zero_pre.length field of the second track.
The missing gadget
The gadget that I really want, but can’t find, is something that will let me copy data from one part of the memory to another. A memcpy that I could control would be ideal, but I can’t find one. I want it so that I can make a copy of the function pointer that’s stored at offset 0xe60. When I allocate a new track, its memory gets zeroed. So, the gadget with the overlapping tracks that I just described will destroy the function pointer unless I can make a backup of it and restore it to its original location after the two tracks have been created. Instead, I found a way to use malloc’s tcache to make the backup, which I’ll explain later.
Debug setup
I use gdb to develop exploits. It’s a painstaking process: I set breakpoints at each step of the exploit and use gdb to examine the memory to check that I’ve modified the heap in the way that I intended. Luckily, it’s quite easy to debug tracker-extract. Just start gdb like this:1
gdb --args /usr/libexec/tracker-extract-3
The only issue is that tracker-extract has a timeout which triggers after 30 seconds of stepping through the code. So, I’ve created my own build of the binary with a much longer timeout to make debugging easier. Since I’m rebuilding the binary anyway, I’ve built it with debug flags to make it easier to step through the code and view the values of the variables. The drawback of using a debug build to develop an exploit is that it can affect subtle details like memory offsets. When I’m getting close to a working exploit, I switch back to the original binary to fix those issues.
Rough plan
I have everything that I need now to start writing an exploit. Here’s a rough plan of how it will work:
- Manipulate the heap so that I can allocate two tracks with overlapping addresses.
- Backup the function pointer at offset
0xe60. - Allocate the two tracks.
- Restore the function pointer to offset
0xe60. - Run the arithmetic gadget to calculate the address of
initable_init. - Overwrite
infowith pointers to fake objects so thattracker_extract_info_unrefwill callinitable_initon exit.
Implementing the exploit
I won’t go through the exploit line by line—exploits become obsolete as soon as the bug is fixed, so some of the minor details are already no longer interesting. Instead, I’ll focus on the main steps and the techniques that I used. For maximum detail, the source code is available here.
Heap Feng Shui
Also known as heap grooming, the idea of heap feng shui is to tidy the memory to make the rest of the exploit easier. The glibc malloc implementation uses multiple buckets and lists to cache memory chunks that are ready for use; and every heap exploitation technique depends on those data structures. I find that it’s much easier to start the exploit from a clean slate with all the caches empty. That’s why I start the exploit by creating a large number of tracks with strings of varying lengths for the metadata fields like TITLE, PERFORMER, and SONGWRITER. By the end of that, all the caches are empty and subsequent allocations come from a contiguous block of memory.
Heap feng shui is sometimes also used for other purposes such as heap spraying or creating a NOP slide, but I don’t need to use those techniques in this exploit.
I had to decide early on how big to make the file. At the end of the PoC, I pad the file with newline characters to make it 0xffe0 bytes long. I wasn’t sure how many statements the PoC would need, so I wanted to make it big enough to accommodate a fairly large number if necessary. But I also wanted the file to be small enough that it wouldn’t get allocated in a separate mmap-ed region.2 That’s because I thought I might need to overwrite the input file while it was being parsed as a way of adding some conditional logic to the exploit. In hindsight, I’m not sure if that idea would have worked, so I’m glad I found a simpler solution. Because the string is allocated in the same per-thread arena, changing its size can affect the offsets of other heap objects, so that’s why it’s still set to the size that I chose early on.
Creating fake chunks
One of the key steps in this exploit is to allocate two tracks at specific (overlapping) addresses, so that I can run the arithmetic gadget. I’ll do that by using a standard technique called the “House of Spirit.” The how2heap repository has a small demo of the technique here. Here’s a diagram of how I’m using it:
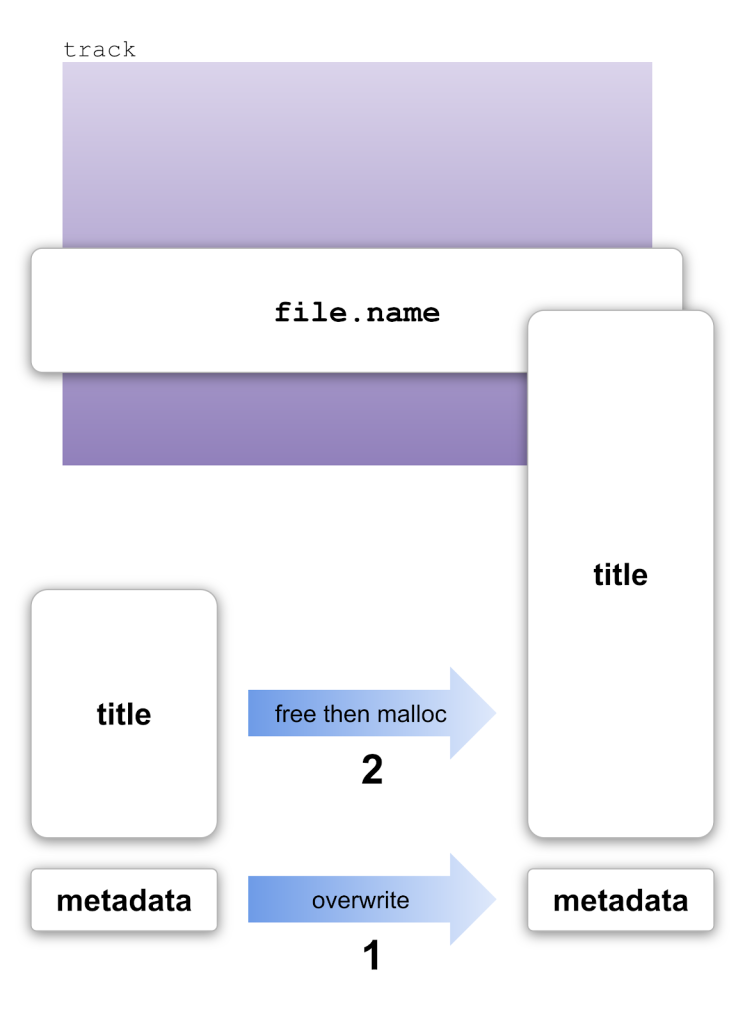
The preliminary step, which isn’t shown in the diagram, is to leave a gap in the memory by allocating and freeing a string, with these two statements:
TITLE "for freeing to tcache index 1"
TITLE "free previous title"
Then, I create a new track and give it a title:
TRACK 048 AUDIO
TITLE "Allocate previously freed string"
The allocator reuses the previously freed string, so the title is allocated just below the new track in memory. Now, I can use the House of Spirit on the title. First, I use the vulnerability to corrupt the metadata of the chunk:
INDEX 4294967268 149
That tricks the allocator into thinking that the chunk is bigger than it really is (149 is the new metadata, which includes the new size). Then, with a single TITLE statement, I can free it and reallocate it:
TITLE "long string to overwrite low bytes of address ... ð^L"
malloc returns the exact same address that was just freed, despite the new string being much longer than the old one. The new string is long enough that it overlaps with the current track, and I’m using it to overwrite the file.name field. The two weird characters at the end of that string overwrite the bottom bytes of the address stored in file.name so that it now contains a forged pointer.
Now, I can run the House of Spirit a second time on the forged pointer that I’ve created in file.name:
INDEX 4294955254 69
FILE pwned.mp3 MP3
The INDEX statement overwrites the metadata and the FILE statement frees the pointer. The next time malloc is called with the appropriate size argument, it will return my forged pointer.
A quick note on chunk metadata
You might be wondering where the numbers 149 and 69 came from in the examples above. In hexadecimal, those numbers are 0x95 and 0x45, respectively. The 0x5 part is a bitfield: 0x1 indicates that the previous chunk is in use and 0x4 indicates that this chunk is from a per-thread arena. The 0x90 / 0x40 part is the chunk size. It is always a multiple of 0x10 and it includes the size of the metadata, so it is always slightly larger than the size argument that was passed to malloc.
Saving and restoring the function pointer
I have a valuable function pointer at offset 0xe60, which I want to use as the input for the arithmetic gadget, but I have a problem because it will get overwritten when I allocate the two tracks that are required for the gadget. So, I need a way to save the function pointer to a different location and then restore it back after the tracks are allocated. And, unfortunately, I do not have a memcpy gadget. The solution that I’ve found is to use the tcache. While I was developing the exploit, I spent a lot of time thinking about how to bypass the recently introduced “safe linking” mitigation. But I was actually just confused: safe linking has no practical impact on the technique that I’ll describe here. What it does do is scramble some of the pointers in memory, which makes debugging more confusing, which is what caused me to overthink it.
The tcache is a simple cache for commonly used chunk sizes. It’s a 64-element array, with each index of the array corresponding to different chunk sizes. For example, chunks up to size 0x20 go in index 0, up to size 0x30 go in index 1, etc. Each array element is a pointer to a linked list of chunks, so the tcache looks like this:
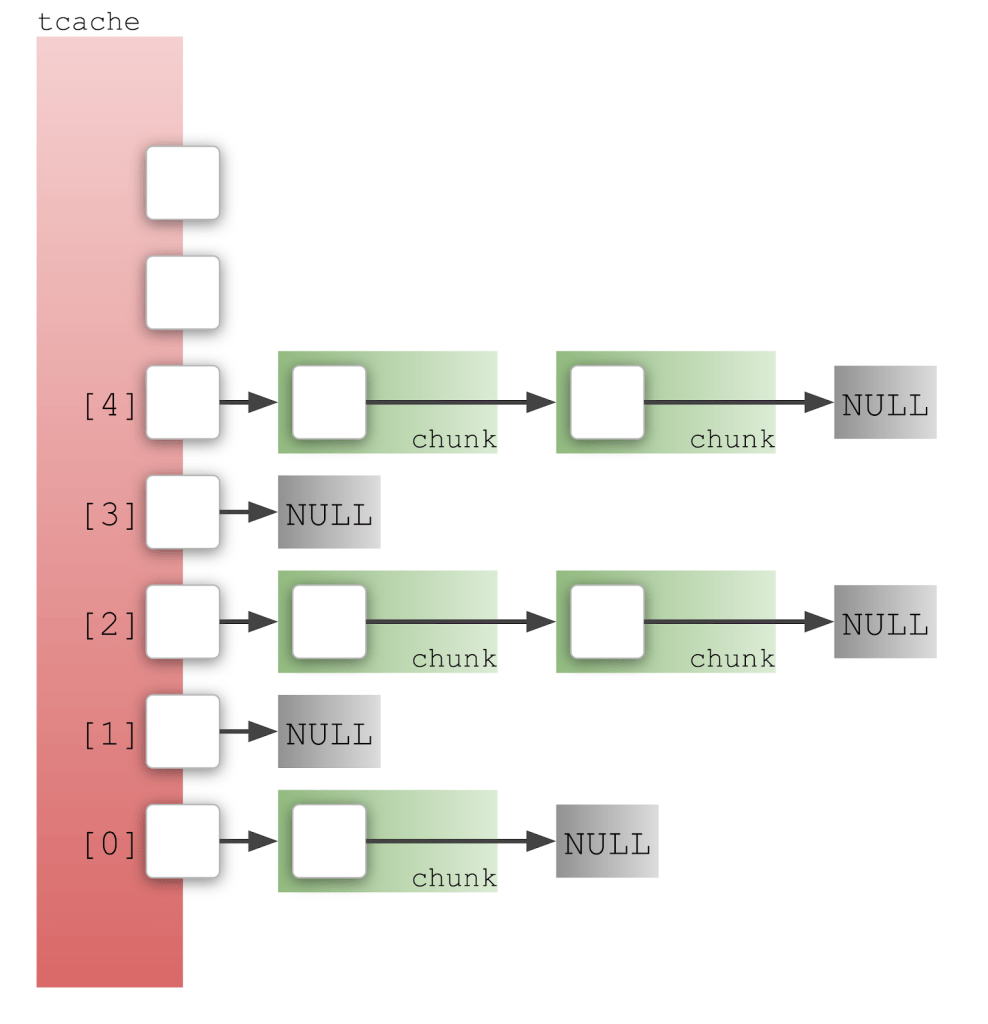
The little box inside each chunk represents the next pointer in the tcache_entry:
typedef struct tcache_entry
{
struct tcache_entry *next;
/* This field exists to detect double frees. */
uintptr_t key;
} tcache_entry;
Now, consider what happens when you allocate and then free a chunk from the tcache:
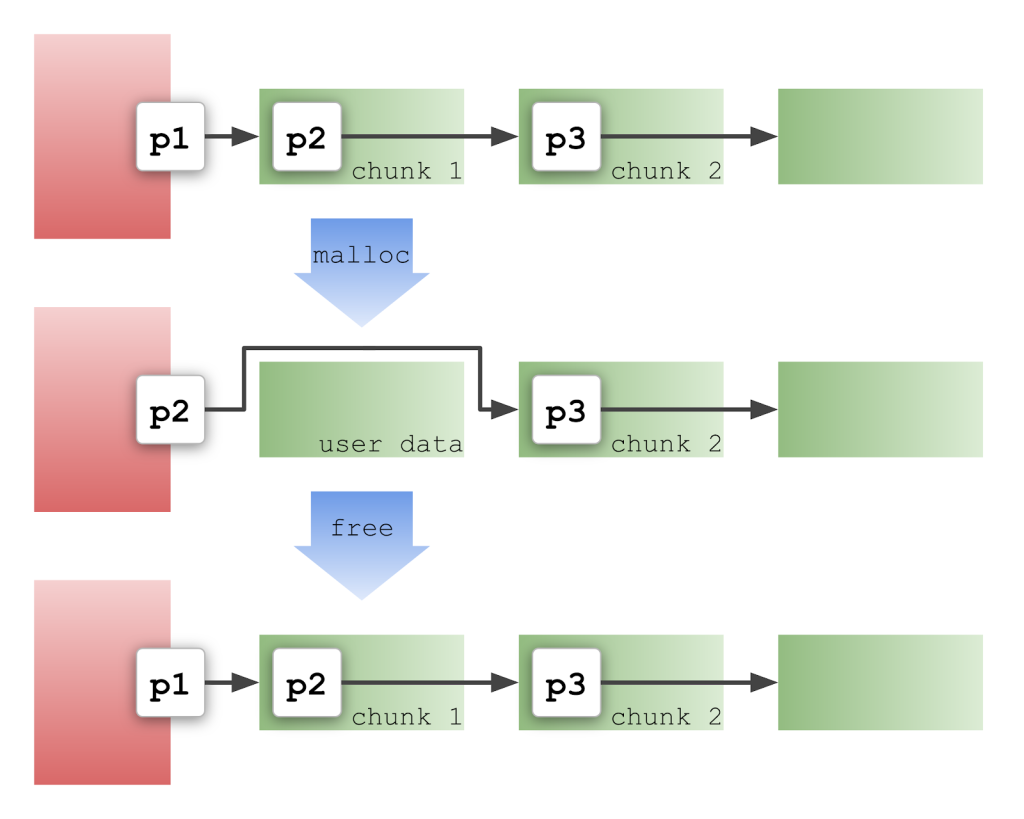
In the diagram, p1 is the address of chunk 1, p2 is the address of chunk 2, etc. When malloc is called, it pops p1 from the head of the list and makes p2 the new head. Notice how p2 is moved to a different location. When free is called, it reverses the process and puts everything back the way it was before. This is exactly what I need to save and restore the function pointer stored at offset 0xe60: all I need to do is overwrite the tcache with a forged pointer to offset 0xe60, allocate the memory, then free it later. My function pointer is temporarily moved to a safe location, like p2 in the diagram.
How does safe linking affect this? The short answer is it doesn’t. But it’s a bit more complicated under the hood. Safe linking tries to make it harder to forge pointers by using XOR to “sign” the next pointer. Rather than storing the address of chunk 2 in the next field of chunk 1, it stores this value: (p1 >> 12) & p2. The idea is to use the ASLR component of p1 to “sign” p2. (ASLR never affects the bottom 12 bits of an address, so that’s why p1 is shifted right by 12.) When I apply my save/restore technique, I don’t have a correctly signed pointer in the next field of the chunk. Instead, I just have a regular function pointer there, which sounds like a catastrophic problem and is the reason why I was stuck on this for quite some time. But the hilarious thing is that it doesn’t matter. When I allocate the memory, p2 gets “unsigned” by XOR-ing with p1 >> 12, which actually has the opposite effect of “signing” it. Then when I free the memory, p2 gets “signed” which again has the opposite effect of actually “unsigning” it. So, just like before, free reverses the previous steps and puts everything back exactly the way it started. In other words, a whole lot of “signing” and “unsigning” happens under the hood, but the net effect is zero. Everything works exactly as it would have without safe linking. 🤣
There’s a minor variation of this technique which enables me to copy the function pointer to a different location: if I free a different address than malloc returned then my function pointer will get restored to the address that I’m freeing. Safe linking does restrict this variation slightly. The address that I free must be in the same memory page (a page is 0x1000 bytes) as the allocated memory. Otherwise the “unsigning” will XOR with a different key than was used for “signing” and the function pointer will get corrupted. The keys are the same for every address with the same page due to the 12-bit right shift in the algorithm.
A setback
Using everything that I’ve described so far, I was able to write an exploit that got as far as calling initable_init, but then crashed. The problem is very frustrating. initable_init has three parameters:
static gboolean
initable_init (GInitable *initable,
GCancellable *cancellable,
GError **error)
But, I’m calling it as the dispose method of a g_object, so I can only control the first parameter:
G_OBJECT_GET_CLASS (object)->dispose (object);
I had hoped that the other two parameters would be NULL, in which case the exploit would have worked, but I wasn’t so lucky. cancellable is non-zero, which causes an immediate crash in initable_init.
The only solution is to find another gadget which will call initable_init with two arguments. (I can get away with just two, because the error parameter is not used.) I used a CodeQL query to search for suitable gadgets:
import cpp
from Struct s, Field f, FunctionPointerType ftype, ExprCall call, VariableAccess access, int offset
where
f = s.getAField() and
ftype = f.getType().getUnspecifiedType() and
ftype.getNumberOfParameters() > 1 and
offset = f.getByteOffset() and
offset.bitAnd(15) = 8 and
access = f.getAnAccess() and
call.getExpr().getAChild*() = access and
call.getEnclosingFunction().getParameter(0).getAnAccess() =
call.getArgument(0).getAChild*()
select f, access
The query searches for a function that calls a function pointer with more than one parameter, and passes its own first parameter directly to the sub-function. It returns 242 results, so it’s not super precise, but it gives me a nice list of options to look through. I’ve chosen g_option_context_parse, which calls pre_parse_func:
list = context->groups;
while (list)
{
GOptionGroup *group = list->data;
if (group->pre_parse_func)
{
if (!(* group->pre_parse_func) (context, group,
group->user_data, error))
goto fail;
}
list = list->next;
}
It’s all a major nuisance because it means that I have to create two function pointers rather than just one, which means that I have to construct two copies of the arithmetic gadget. But there’s nothing fundamentally difficult about it, it’s just more work, using the same techniques that I’ve already described.
Avoiding a crash
In an earlier version of the exploit that I shared with the Distros mailing list and the tracker-miners developers, the calculator would start but then crash a second later. The reason is that the code in tracker-extract would return from initable_init and immediately crash, taking the calculator with it. I have since found a way to fix that problem.
The crash happens immediately after exiting the while loop that calls pre_parse_func (see code snippet above). It’s impossible to stop the crash from happening if the code exits the loop, so, instead, I make the list infinite by pointing the next pointer back to the start of the list. The only drawback of this solution is that it will try to start an infinite number of calculators, which will fork bomb the system. But that’s easy to fix with a small amount of bash scripting. This is the command that I use:
killall -SIGSTOP tracker-extract-3;
flock -w 3 ~/Downloads/pwned.lock -c 'gnome-calculator -e 1337' &&
(sleep 10; rm ~/Downloads/pwned.lock; killall -SIGKILL tracker-extract-3)
First, it uses killall to send the SIGSTOP signal to tracker-extract to pause the loop and avoid a fork bomb. Then, it uses flock to create a lock file, so that only one of the processes will successfully launch a calculator. (The others timeout after 3s.) Finally, after the calculator exits, it deletes the lock file and sends the SIGKILL signal to tracker-extract. With these steps, tracker-extract shuts down without crashing, so there is no indication to the user (besides the calculator) that anything weird happened.
Sandbox escape
tracker-extract has a seccomp sandbox, which I exploited completely by accident. There is quite a lot of discussion about it in this issue. It turns out that the main thread is exempt from the sandbox. The main thread is more difficult to sandbox than the other threads because it needs to do a lot more system calls, and parsers like libcue are not run on the main thread, so it was a pragmatic decision that most of the security benefit would be gained from sandboxing only the non-main threads. I got lucky because my exploit uses tracker_extract_info_unref to trigger the code execution. It turns out that tracker_extract_info_unref doesn’t get called immediately, but instead is put on a queue to be executed by the main thread:
if (!filter_module (task->extract, task->module) &&
get_file_metadata (task, &info, &error)) {
g_task_return_pointer (G_TASK (task->res), info,
(GDestroyNotify) tracker_extract_info_unref);
} else {
There’s actually a second way to trigger tracker_extract_info_unref, which I accidentally hit with a previous iteration of the exploit. If an error occurs during parsing then it gets called immediately:
if (!task->success) {
tracker_extract_info_unref (info);
info = NULL;
}
That caused me to get this error message:
Disallowed syscall "close_range" caught in sandbox
But I misunderstood what was causing that error message and “fixed” the wrong problem. During that process, I accidentally flipped the value of task->success to true, which is what actually fixed it.
Carlos Garnacho has very quickly implemented some changes to strengthen the sandbox, which will prevent this exploitation path from working in the future. Carlos has also written a very interesting blog post about it.
Summary of the exploit
The final exploit is slightly more complicated than the rough plan that I described earlier, mainly because I had to add a second gadget to call initable_init via g_option_context_parse. This is an updated outline, this time with links to the corresponding parts of the exploit source code:
- Heap feng shui.
- Use House of Spirit to create numerous fake chunks in the per-thread arena.
- Use the first arithmetic gadget to compute the address of g_option_context_parse.
- Use the second arithmetic gadget to compute the address of initable_init.
- Create more fake objects in the heap to complete the info object that will be passed to tracker_extract_info_unref.
- Add a back-pointer to make the linked list infinite, so that tracker-extract won’t crash.
- Remove any remaining fake chunks from the tcache to get back to a clean slate.
- Pad the file with newline characters to make it the correct size.
The treasure hunt is complete!

Conclusion
Exploit development is an important part of security research because it keeps us grounded in reality. Knowing what it would take to exploit a vulnerability enables us to accurately assess its severity. In the absence of a proper PoC, we’re just guessing, which occasionally leads to over-hyping of the severity of the bug, but can equally easily cause the risk to be overlooked. It doesn’t help that mitigations like ASLR and stack canaries can create a false sense of security. For example, this bug could easily have been dismissed as unexploitable, particularly considering that tracker-extract is also protected by a seccomp sandbox.
A second reason why I find exploit development valuable is that it helps me to learn much more about how the code works, which sometimes leads to additional discoveries. In this case, it led to the additional discovery that tracker-extract’s sandbox isn’t as watertight as people thought. Thanks to Carlos Garnacho, the sandbox has now been improved.
If you’re new to exploit development, I hope this blog post helped to explain some of the concepts. Every exploitation challenge is unique, and there’s no one-size-fits-all solution. Some of the techniques that I used for this exploit, particularly the well-known ones like the House of Spirit, are reusable. But others, like the arithmetic gadget that I built, are single-use. More important is the general principle of how you search for gadgets (aka weird instructions) in the code and use them as stepping stones to get where you need to go.
Notes
Tags:
Written by

Related posts
How GitHub gave every repository a durable owner
GitHub had over 14,000 repositories. Fewer than half had clear ownership. Here’s how we gave every active repository a validated owner in under 45 days, archived the rest, and made ownership the foundation for everything that followed.
How GitHub used secret scanning to reach inbox zero
GitHub had 20,000+ secret scanning alerts across 15,000 repositories. Here’s how we separated signal from noise, built remediation workflows, and reached inbox zero in nine months.
6 security settings every GitHub maintainer should enable this week
These six free settings will not make your project unhackable. Nothing will. What they will do is close the easy doors. Turn these on, and your project will be meaningfully harder to attack than it was before.