Scaling merge-ort across GitHub
GitHub switched to performing merges and rebases using merge-ort. Come behind the scenes to see why and how we made this change.
At GitHub, we perform a lot of merges and rebases in the background. For example, when you’re ready to merge your pull request, we already have the resulting merge assembled. Speeding up merge and rebase performance saves both user-visible time and backend resources. Git has recently learned some new tricks which we’re using at scale across GitHub. This post walks through what’s changed and how the experience has improved.
Our requirements for a merge strategy
There are a few non-negotiable parts of any merge strategy we want to employ:
- It has to be fast. At GitHub’s scale, even a small slowdown is multiplied by the millions of activities going on in repositories we host each day.
- It has to be correct. For merge strategies, what’s “correct” is occasionally a matter of debate. In those cases, we try to match what users expect (which is often whatever the Git command line does).
- It can’t check out the repository. There are both scalability and security implications to having a working directory, so we simply don’t.
Previously, we used libgit2 to tick these boxes: it was faster than Git’s default merge strategy and it didn’t require a working directory. On the correctness front, we either performed the merge or reported a merge conflict and halted. However, because of additional code related to merge base selection, sometimes a user’s local Git could easily merge what our implementation could not. This led to a steady stream of support tickets asking why the GitHub web UI couldn’t merge two files when the local command line could. We weren’t meeting those users’ expectations, so from their perspective, we weren’t correct.
A new strategy emerges
Two years ago, Git learned a new merge strategy, merge-ort. As the author details on the mailing list, merge-ort is fast, correct, and addresses many shortcomings of the older default strategy. Even better, unlike merge-recursive, it doesn’t need a working directory. merge-ort is much faster even than our optimized, libgit2-based strategy. What’s more, merge-ort has since become Git’s default. That meant our strategy would fall even further behind on correctness.
It was clear that GitHub needed to upgrade to merge-ort. We split this effort into two parts: first deploy merge-ort for merges, then deploy it for rebases.
merge-ort for merges
Last September, we announced that we’re using merge-ort for merge commits. We used Scientist to run both code paths in production so we can compare timing, correctness, etc. without risking much. The customer still gets the result of the old code path, while the GitHub feature team gets to compare and contrast the behavior of the new code path. Our process was:
- Create and enable a Scientist experiment with the new code path.
- Roll it out to a fraction of traffic. In our case, we started with some GitHub-internal repositories first before moving to a percentage-based rollout across all of production.
- Measure gains, check correctness, and fix bugs iteratively.
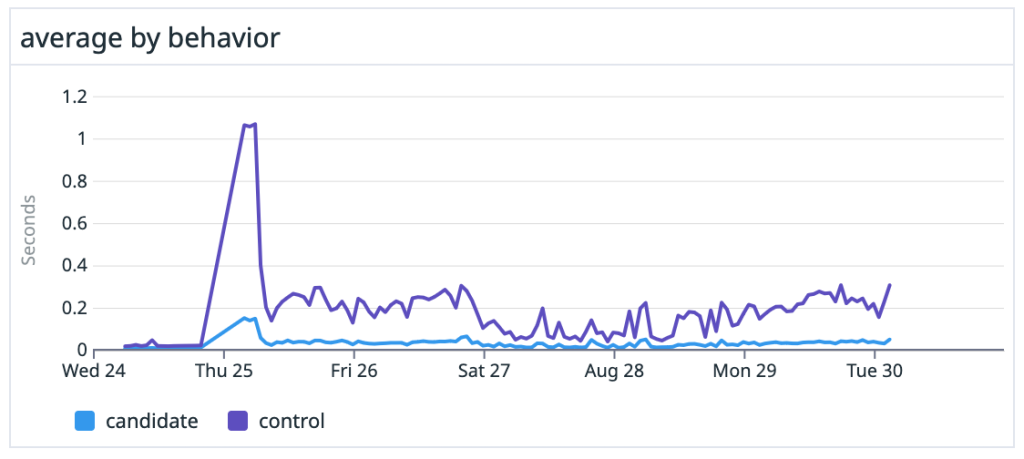
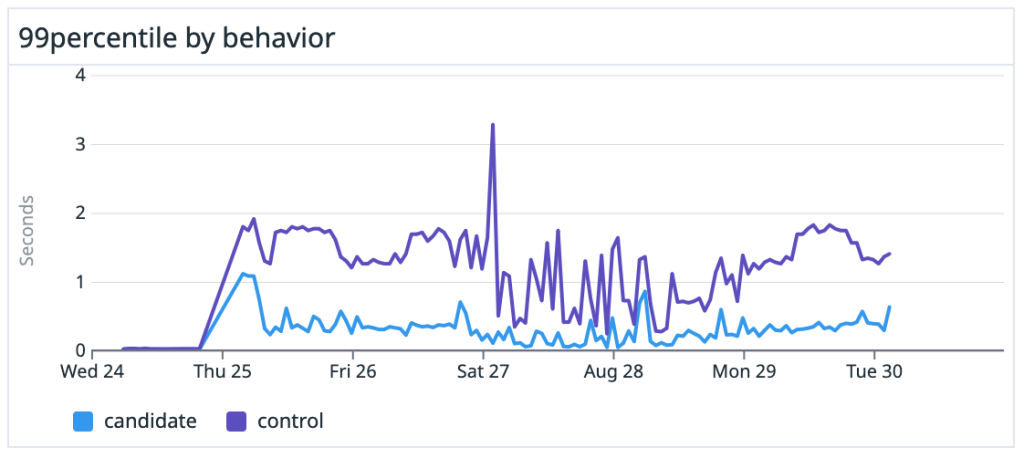
We saw dramatic speedups across the board, especially on large, heavily-trafficked repositories. For our own github/github monolith, we saw a 10x speedup in both the average and P99 case. Across the entire experiment, our P50 saw the same 10x speedup and P99 case got nearly a 5x boost.


merge-ort for rebases
Like merges, we also do a huge number of rebases. Customers may choose rebase workflows in their pull requests. We also perform test rebases and other “behind the scenes” operations, so we also brought merge-ort to rebases.
This time around, we powered rebases using a new Git subcommand: git-replay. git replay was written by the original author of merge-ort, Elijah Newren (a prolific Git contributor). With this tool, we could perform rebases using merge-ort and without needing a worktree. Once again, the path was pretty similar:
- Merge
git-replayinto our fork of Git. (We were running the experiment with Git 2.39, which didn’t include thegit-replayfeature.) - Before shipping, leverage our test suite to detect discrepancies between the old and the new implementations.
- Write automation to flush out bugs by performing test rebases of all open pull requests in
github/githuband comparing the results. - Set up a Scientist experiment to measure the performance delta between
libgit2-powered rebases and monitor for unexpected mismatches in behavior. - Measure gains, check correctness, and fix bugs iteratively.
Once again, we were amazed at the results. The following is a great anecdote from testing, as relayed by @wincent (one of the GitHub engineers on this project):
Another way to think of this is in terms of resource usage. We ran the experiment over 730k times. In that interval, our computers spent 2.56 hours performing rebases with
libgit2, but under 10 minutes doing the same work withmerge-ort. And this was running the experiment for 0.5% of actors. Extrapolating those numbers out to 100%, if we had done all rebases during that interval withmerge-ort, it would have taken us 2,000 minutes, or about 33 hours. That same work done withlibgit2would have taken 512 hours!
What’s next
While we’ve covered the most common uses, this is not the end of the story for merge-ort at GitHub. There are still other places in which we can leverage its superpowers to bring better performance, greater accuracy, and improved availability. Squashing and reverting are on our radar for the future, as well as considering what new product features it could unlock down the road.
Appreciation
Many thanks to all the GitHub folks who worked on these two projects. Also, GitHub continues to be grateful for the hundreds of volunteer contributors to the Git open source project, including Elijah Newren for designing, implementing, and continually improving merge-ort.
Tags:
Written by

Related posts

From latency to instant: Modernizing GitHub Issues navigation performance
How the GitHub Issues team used client-side caching, smart prefetching, and service workers to make navigation feel instant.

How GitHub uses eBPF to improve deployment safety
Learn how Github uses eBPF to detect and prevent circular dependencies in its deployment tooling.
The uphill climb of making diff lines performant
The path to better performance is often found in simplicity.