Tip: If you’re looking for an overview on Git repositories and how they work, check out our Git guides and explore some of our interactive courses on GitHub Skills.
Applying GitOps principles to your operations
Could we use our Git repository as the source of truth for operational tasks, and somehow reconcile changes with our real-world view?

|
8 minutes
DevOps practices have helped demonstrate the value in bringing teams together to accelerate value for end-users. This typically includes automating build and release processes and bringing quality checks directly into the workflow.
Fundamentally, these processes depend on some source of the truth. In GitHub, that source is a Git repository hosted on GitHub. Git repositories are great for this, as they allow us to store our code in a way that versions can be changed and tracked over time. As a result, we are able to view a timeline of edits to files and their contents.
Building and releasing software is a common use case of these workflows, but it is not the only one. There are operational considerations behind your code; you rely heavily on the reliability and consistency of the environments that host and underpin your software. Ensuring that these systems are online, managed, and monitored is vital. This includes the day-to-day tasks of managing desired state configuration while avoiding configuration drift, managing access permissions and deploying and managing new environments. These operational tasks have traditionally been manual and error-prone, potentially spanning several different tools and platforms to achieve an outcome.
To ensure smooth service management throughout these changes, teams have typically relied upon frameworks such as Information Technology Infrastructure Library (ITIL) and other change management practices (such as change advisory boards) to minimize risk and disruption to the business.
Is there another way? Could we use our Git repository as the source of truth for these operational tasks, and somehow reconcile changes with our real-world view?
What is GitOps?
Let’s first establish a common definition of GitOps. The Linux Foundation’s OpenGitOps landing page describes four key principles:
- Declarative
A system managed by GitOps must have its desired state expressed declaratively. - Versioned and Immutable
Desired state is stored in a way that enforces immutability, versioning, and retains a complete version history. - Pulled Automatically
Software agents automatically pull the desired state declarations from the source. - Continuously Reconciled
Software agents continuously observe actual system state and attempt to apply the desired state.
In other words, GitOps builds upon the cloud native principles and ideas that we have been introduced to through platforms like Kubernetes. The ‘source of truth’ is stored and versioned in our Git repositories. That source is typically declarative, meaning that the state is described in a desired and immutable manner. In other words, we describe what we want, rather than how it should happen (otherwise known as imperative).
The idea of storing a desired state in Git is powerful. As a result, we’re able to get a full history of changes over time on the desired state of our environment, system or configuration. This gives us auditability into the changes that were made, who made them, and why.
Building on this concept of auditability, we can adopt features like GitHub branch protection rules or repository rules to put guardrails in place, ensuring that changes to the desired state pass a set of quality checks (such as linting, smoke tests) and perhaps manual reviews using the four eyes principle. That way, if the desired state needs updating (for example, deploying additional machines, reconfiguring an application, adjusting permissions, etc.), we can use the same continuous integration and continuous delivery (CI/CD) principles that we are familiar with when building and deploying software, and bring those changes in as a pull request from a feature branch.
But what if the current state (the live configuration of the environment) deviates from the desired state (in our Git repository)? Perhaps someone has manually tweaked a configuration setting, deployed a new machine or adjusted permissions manually.
An automated process (typically an agent) analyzes the current state and the desired state on an ongoing basis. It then makes the necessary changes to bring the current world to an accurate representation of the desired state. In other words, the agent is there to address any configuration drift that occurs. You could consider that as a ‘pull’ model, where the state of the existing environment is continuously reconciled against the desired state. As updates are made to the desired state, they are automatically detected by the agent, and it makes the needed changes to the environment.
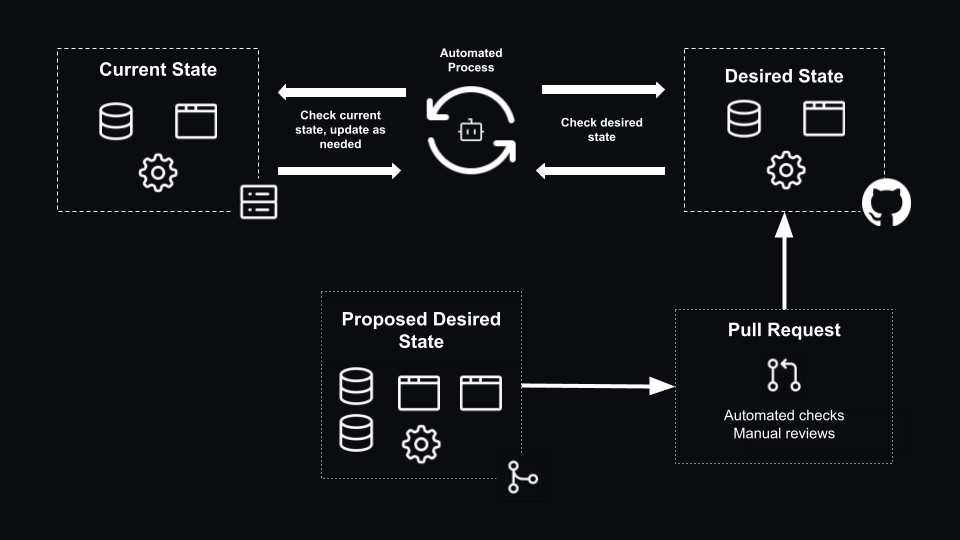
Consider a platform like Kubernetes or technologies like Flux or Argo CD. They rely upon an agent continuously evaluating the current state of the environment against the intended desired state.
However, there are many platforms which do not have an agent capability to enable continuous reconciliation. In these cases, I have seen teams opt to use CI/CD workflows to push the desired state to their environment. Compared to an agent continuously reconciling the changes, updates to the current state would be slower (that is based on the triggers of our CI/CD workflow). Worse still, discrepancies in the current state and the desired state could emerge, as drift detection would not be available out of the box. This would also technically break the third principle from the OpenGitOps definition. In other words, if an agent is not available for your scenario, then CI/CD tools such as GitHub Actions to deliver changes to your environment may be an option, but bear in mind the tradeoffs you would be taking.
GitOps principles are not just limited to applications, and could be considered from an operational perspective. Tools like Ansible or Terraform could be used to describe the configuration of your infrastructure. Then, platforms, such as Ansible Automation Platform or Terraform Cloud, could help reconcile updated configuration changes to the estate.
GitHub’s entitlements project
Let’s look at another example. Last year, GitHub open sourced its identity and access management solution, Entitlements. It’s something that we use day-in and day-out to manage access to applications, distribution lists, organizational structure, and more, here at GitHub.
Storing these permission mappings in source control provides a clear source of truth which is reliable, and auditable. We can easily navigate through the historical changes in our repository to determine why changes have been made and by whom. Assuming that pull requests have been used to update the desired state, additional context on the relevant discussions, approvals and checks may be traceable as well.
This once again drives the importance of good governance practices, not just in our software projects, but also in repositories where we’re adopting GitOps principles to drive infrastructure configuration, or our identity and access management permissions. In particular, branch protection rules or repository rules could:
- Ensure that the minimum number of required reviewers have approved the changes.
- Use the CODEOWNERs file to automatically assign required reviewers to the pull request based on the files which have been changed, so relevant approvers are kept in the loop.
- Lint contributions in pull requests to ensure they still meet the expected standards.
- Execute a dry-run of the configuration permissions to identify the impact of a change, before accepting a pull request.
This also takes away the risk of error-prone manual changes, allowing automation to scale and accelerate the operational needs of the business. Our operations teams are still fully involved in the process. Their role may evolve into managing the workflows to enable these quality checks, reviewing proposed changes to permissions, and approving or rejecting based on the business need and justification.
Recommended practices
As with many projects and patterns, there are several recommended practices that we can consider adopting:
- As practiced by open source communities and innersource communities; a clear and simple README in your repository is important to showcase what the project is, how folks can contribute, and your expectations around contributions.
- Quality is something I’ve kept highlighting throughout the post. It is an important part of any workflow to ensure you’re shipping valuable experiences to your customers. Consider this as an evolution to your change management practices, and how you can integrate quality directly into your workflows:
- Use branch protection rules or repository rules to bring quality into your contribution process, before code ever reaches your production branch:
- Consider requiring at least one reviewer, so direct merges to your production branch are disallowed.
- Consider turning off bypassing, if you prefer that all changes must go through the process without adhering to all checks.
- Consider requiring status checks (specific GitHub Action workflows) to ensure the needed automated checks are a core criteria to allow a merge.
- Use GitHub Action Workflows on a pull request trigger to automate quality checks before they reach your production code:
- Consider linting the changes, to ensure the code follows a set of standard practices.
- Consider a dry-run of your configuration changes, so that you know what is changing before merging to your production environment. This could be a terraform plan, a bicep deployment what-if, or similar with the tools in your own workflow.
- If you are particularly mature in your processes, you could consider a smoke test and deploy the changes in some temporary environment (not production), to assess that the changes are as you expect.
- Use branch protection rules or repository rules to bring quality into your contribution process, before code ever reaches your production branch:
Wrapping up
This has been a whistle stop tour on GitOps, with a special focus on our entitlements project which was open sourced last year! It has also highlighted the importance of quality checks outside of your software build and release pipelines, and how they can integrate into GitOps workflows as well.
Tags:
Written by

Related posts
GitHub recognized as a Leader in the Gartner® Magic Quadrant™ for Enterprise AI Coding Agents for the third year in a row
We are committed to empowering every developer by building an open, secure, and AI-powered platform that defines the future of software development.
Improving token efficiency in GitHub Agentic Workflows
Agentic workflows that run on every pull request can quietly accumulate large API bills. Here’s how we instrumented our own production workflows, found the inefficiencies, and built agents to fix them.
Automate repository tasks with GitHub Agentic Workflows
Discover GitHub Agentic Workflows, now in technical preview. Build automations using coding agents in GitHub Actions to handle triage, documentation, code quality, and more.