GitHub recently experienced several availability incidents, both long running and shorter duration. We have since mitigated these incidents and all systems are now operating normally. Read on for more details about what caused these incidents and what we’re doing to mitigate in the future.
Last week, GitHub experienced several availability incidents, both long running and shorter duration. We have since mitigated these incidents and all systems are now operating normally. The root causes for these incidents were unrelated but in aggregate, they negatively impacted the services that organizations and developers trust GitHub to deliver. This is not acceptable nor the standard we hold ourselves to. We took immediate and direct action to remedy the situation, and we want to be very transparent about what caused these incidents and what we’re doing to mitigate in the future. Read on for more details.
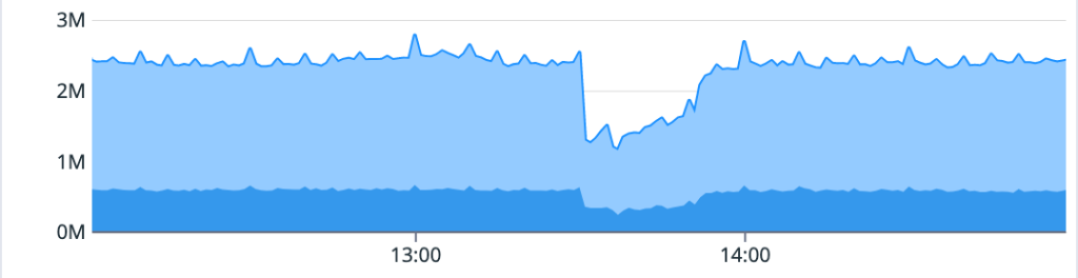
On May 9, we had an incident that caused 8 of the 10 services on the status portal to be impacted by a major (status red) outage. The majority of downtime lasted just over an hour. During that hour-long period, many services could not read newly-written Git data, causing widespread failures. Following this outage, there was an extended timeline for post-incident recovery of some pull request and push data.
This incident was triggered by a configuration change to the internal service serving Git data. The change was intended to prevent connection saturation, and had been previously introduced successfully elsewhere in the Git backend.
Shortly after the rollout began, the cluster experienced a failover. We reverted the config change and attempted a rollback within a few minutes, but the rollback failed due to an internal infrastructure error.
Once we completed a gradual failover, write operations were restored to the database and broad impact ended. Additional time was needed to get Git data, website-visible contents, and pull requests consistent for pushes received during the outage to achieve a full resolution.
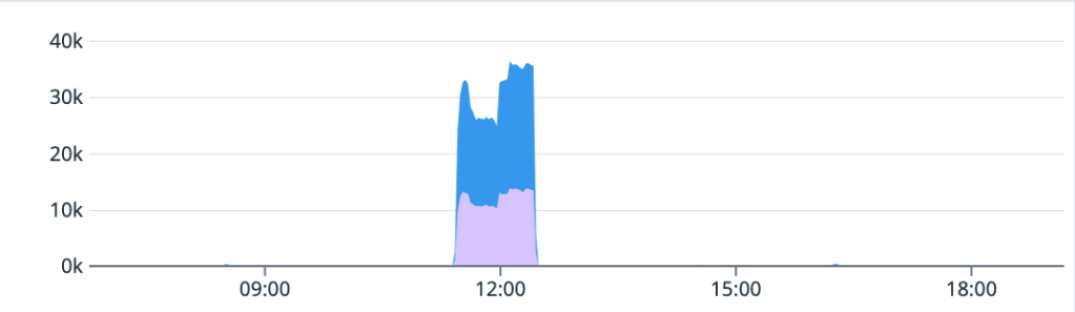
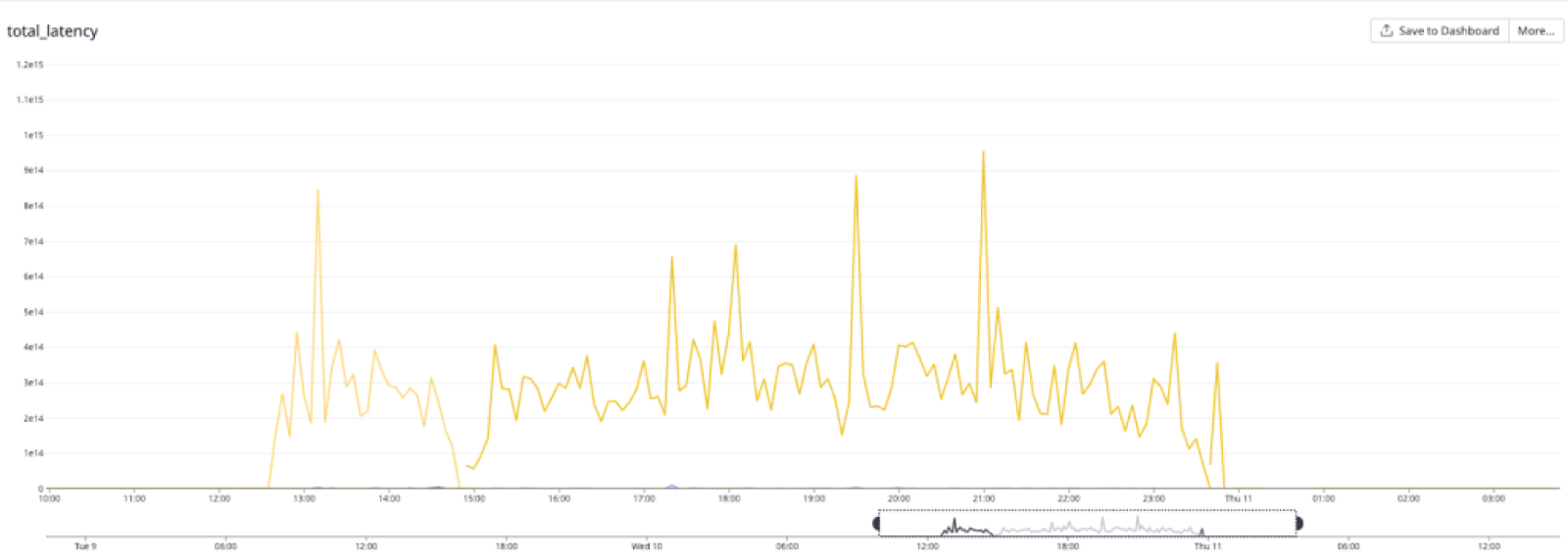
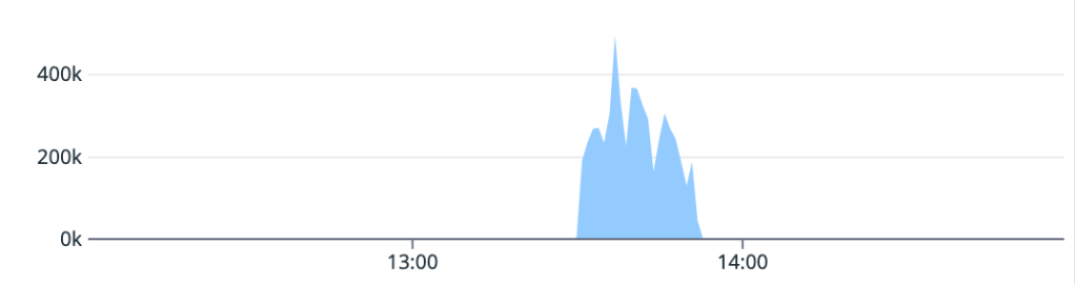
On May 10, the database cluster serving GitHub App auth tokens saw a 7x increase in write latency for GitHub App permissions (status yellow). The failure rate of these auth token requests was 8-15% for the majority of this incident, but did peak at 76% percent for a short time.
Total LatencyFetch Latency
We determined that an API for managing GitHub App permissions had an inefficient implementation. When invoked under specific circumstances, it results in very large writes and a timeout failure. This API was invoked by a new caller that retried on timeouts, triggering the incident. While working to identify root cause, improve the data access pattern, and address the source of the new call pattern, we also took steps to reduce load from both internal and external paths, reducing impact to critical paths like GitHub Actions workflows. After recovery, we re-enabled all suspended sources before statusing green.
While we update the backing data model to avoid this pattern entirely, we are updating the API to check for the shift in installation state and will fail the request if it would trigger these large writes as a temporary measure.
Beyond the problem with the query performance, much of our observability is optimized for identifying high-volume patterns, not low-volume high-cost ones, which made it difficult to identify the specific circumstances that were causing degraded cluster health. Moving forward, we are prioritizing work to apply the experiences of our investigations during this incident to ensure we have quick and clear answers for similar cases in the future.
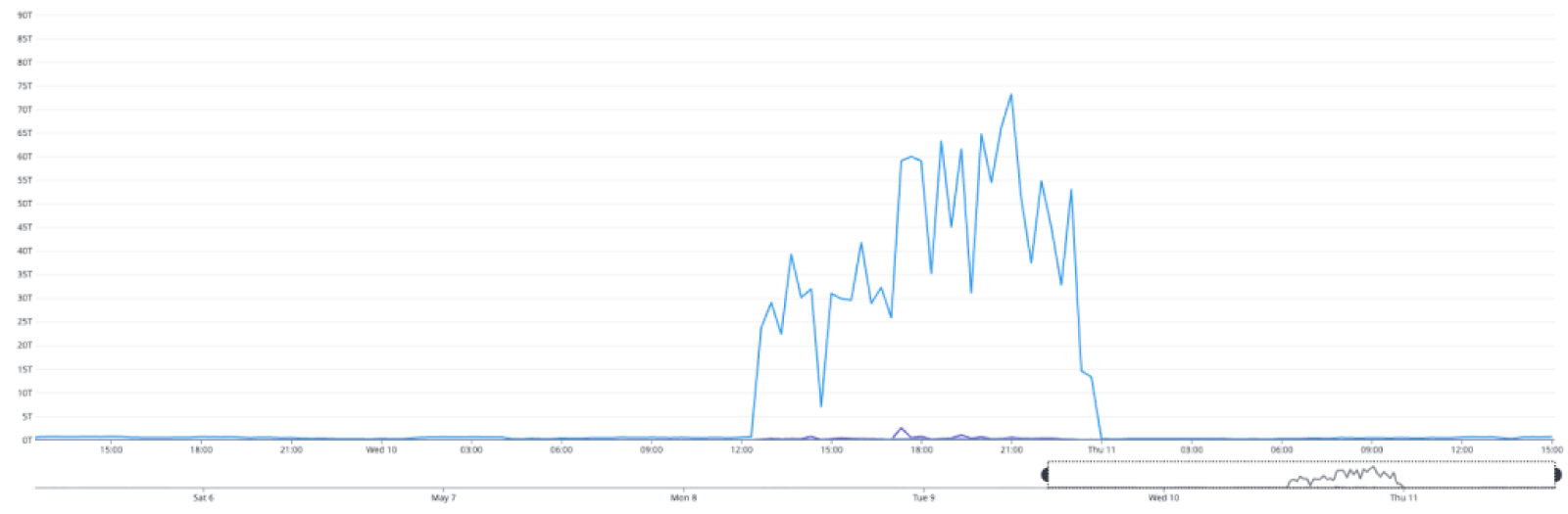
On May 11, a database cluster serving git data crashed, triggering an automated failover. The failover of the primary was successful, but in this instance read replicas were not attached. The primary cannot handle full read/write load, so an average of 15% of requests for Git data were failed or slow, with peak impact of 26% at the start of the incident. We mitigated this by reattaching the read replicas and the core scenarios recovered. Similar to the May 9 incident, additional work was required to recover pull request push updates, but we were eventually able to achieve full resolution.
Beyond the immediate mitigation work, the top workstreams underway are focused on determining and resolving what caused the cluster to crash and why the failure didn’t leave the cluster in a good state. We want to clarify that the team was already working to understand and address a previous cluster crash as part of a repair item from a different recent incident. This failover replica failure is new.
We expect our services to be as resilient as possible to failure. Failure in a distributed system is inevitable, but it shouldn’t result in significant outages across multiple services. We saw widespread degradation in all three of these incidents. In the Git database incidents, Git reads and writes are at the core of many GitHub scenarios, so increased latency and failures resulted in GitHub Actions workflows unable to pull data or pull requests not updating.
In the GitHub Apps incident, the impact on the token issuance also impacted GitHub features that rely on tokens for operation. This is the source of each GITHUB_TOKEN in GitHub Actions, as well as the tokens used to give GitHub Codespaces access to your repositories. They’re also how access to private GitHub Pages are secured. When token issuance fails, GitHub Actions and GitHub Codespaces are unable to access the data they need to run, and fail to launch as a result.
We are carefully reviewing our internal processes and making adjustments to ensure changes are always deployed safely moving forward. Not all of these incidents were caused by production changes, but we recognize this as an area of improvement.
In addition to the standard post-incident analysis and review, we are analyzing the breadth of impact these incidents had across services to identify where we can reduce the impact of future similar failures.
We are working to improve observability of high-cost, low-volume query patterns and general ability to diagnose and mitigate this class of issue quickly.
We are addressing the Git database crash that has caused more than one incident at this point. This work was already in progress and we will continue to prioritize it.
We are addressing the database failover issues to ensure that failovers always recover fully without intervention.
As part of our commitment to transparency, we publish summaries of all incidents that result in degraded performance of GitHub services in our monthly availability report. Given the scope and duration of these recent incidents we felt it was important to address them with the community now. The May report will include these incidents and any further detail we have on them, along with a general update on progress towards increasing the availability of GitHub. We are deeply committed to improving site reliability moving forward and will continue to hold ourselves accountable for delivering on that commitment.
Mike Hanley is the Chief Security Officer and SVP of Engineering at GitHub. Prior to GitHub, Mike was the Vice President of Security at Duo Security, where he built and led the security research, development, and operations functions. After Duo’s acquisition by Cisco for $2.35 billion in 2018, Mike led the transformation of Cisco’s cloud security framework and later served as CISO for the company. Mike also spent several years at CERT/CC as a Senior Member of the Technical Staff and security researcher focused on applied R&D programs for the US Department of Defense and the Intelligence Community.
When he’s not talking about security at GitHub, Mike can be found enjoying Ann Arbor, MI with his wife and eight kids.
We’re calling for targeted amendments to resolve conflicts with open source licensing and align with international transparency frameworks while preserving regulatory intent.
We do newsletters, too
Discover tips, technical guides, and best practices in our biweekly newsletter just for devs.