
Although some ReDoS vulnerabilities can be very serious (particularly when they’re server-side and enable an untrusted remote attacker to DOS the server), very often they land much closer to the “annoying” end of the CVSS rating scale: not particularly serious, but easy to create by accident, obscure to understand, and sometimes tricky to fix.

The most annoying thing about ReDoS vulnerabilities is that they’re not caused by careless coding, but by an obscure edge-case in the regex engine. I place the blame squarely on the regex library and not the developer who used it.
The good news is that ReDoS vulnerabilities are very easy to detect, thanks to some CodeQL queries that have been included in code scanning since 2017, and greatly improved by my colleague, Erik Kristensen, in 2021. The bad news is that fixing those vulnerabilities is still a manual process. In this blog post, I’ll try to give you some tips that will help you to fix ReDoS bugs. In my experience, many of these bugs can be fixed by changing just one or two characters in the regex, but it can be tricky to figure out which characters you need to change. All of the examples in this blog post use Python, but the same principles apply to other languages such as Javascript.
Before the CodeQL ReDoS queries were released in 2021, we ran them on as many open source projects as we could and sent vulnerability reports to a large number of open source maintainers. It was a team effort, with the authors of the CodeQL queries (particularly Erik Kristensen, Rasmus Petersen, Nick Rolfe, Tony Torralba, and Joseph Farebrother) conducting the majority of the analysis, and GitHub Security Lab (the team that I’m on) writing the reports and sending them to the maintainers of the affected projects. I worked on approximately 20 of the reports myself. Unfortunately, several of the maintainers of projects that I reported ReDoS vulnerabilities to never responded to my messages, which meant that I couldn’t close the issues out. Since the vulnerabilities were low severity, and I wasn’t able to contact the maintainers, I decided that the best solution would be to submit (public) pull requests to fix the issues. That strategy was much more successful, and figuring out how to fix those bugs is how I learned the techniques that I’ll describe in this blog post.
I’d be very surprised if there’s any other programming notation that’s as dense as a regex. The amount of logic that you can pack into just 10 or so characters of a regex is astounding. As a result, regexes become little nuggets of wisdom that people like to share with each other. Sadly, that can also lead to buggy regexes spreading like a virus. An interesting example of this is a huge regex for URLs, variations of which we’ve seen in quite a few open source repositories. Some versions of it have a ReDoS and, due to its size, it’s quite a daunting one to fix. In fact, the last time I tried, I wrote it off as impossible, but I recently discovered that it has a simple solution, which I’ll discuss later in this blog post.
What’s a ReDoS?
A ReDoS is a denial-of-service (DOS) vulnerability in which a regex runs exceptionally slowly on some inputs. Here’s a simple example, loosely based on one of the vulnerabilities that our CodeQL query found:
(bb|b.)*a
This regex cannot handle long strings of the form “bbbbb…,” which you can see for yourself by running this python script:
import re
import time
for n in range(100):
start_time = time.time()
re.match("(bb|b.)*a", "b" * n)
print(n, time.time() - start_time)
The running time increases exponentially on each iteration of the loop.
I was very confused when I first heard about the concept of a ReDoS because I knew that regexes can be implemented as deterministic finite automata (DFA), which means that their runtime should be linear in the size of the input with constant memory usage. How do you go from that to exponential runtimes? The problem is that many programming languages use a regex engine that doesn’t convert the regex to a DFA. For example, Python uses a backtracking implementation of a non-deterministic finite automaton (NFA), which is what’s responsible for the atrocious performance. The algorithm that Python uses to evaluate the example above is roughly equivalent to this code:
def matchit(str, i):
if i+2 <= len(str) and str[i] == 'b' and str[i+1] == 'b' and matchit(str, i+2):
return True
elif i+2 <= len(str) and str[i] == 'b' and matchit(str, i+2):
return True
elif i+1 <= len(str) and str[i] == 'a':
return True
else:
return False
Notice that there are two recursive calls to matchit, which will both get called if the string doesn’t match. On strings of the form “bbbbb…,” the recursion goes as deep as the string is long, which means that the search tree is exponential in size.
The important principle to understand is that “choice” (for example a|b|c) is implemented as an if-then-else cascade and repetition (for example + or *) is implemented using recursion. When combined, these two elements can lead to exponentially large search trees.
Only some programming languages have regex engines that are vulnerable to ReDoS. Most of the ReDoS vulnerabilities that I’ve seen have been in Python or Javascript, but they can also happen in other languages such as C#, Java, Ruby, Perl, and PHP. On the other hand, Go, Rust, and the RE2 library for C++, are not vulnerable to ReDoS. Java (since version 9) and Ruby (since version 3.2.0) have made improvements to their regex engines which make ReDoS less likely. We have CodeQL queries for ReDoS in Javascript, Python, Java, C#, and Ruby.
How to fix a ReDoS
So, CodeQL says that your regex has a ReDoS. What should you do?
I’ll use the ReDoS from Airbnb’s streamalert project as an example:
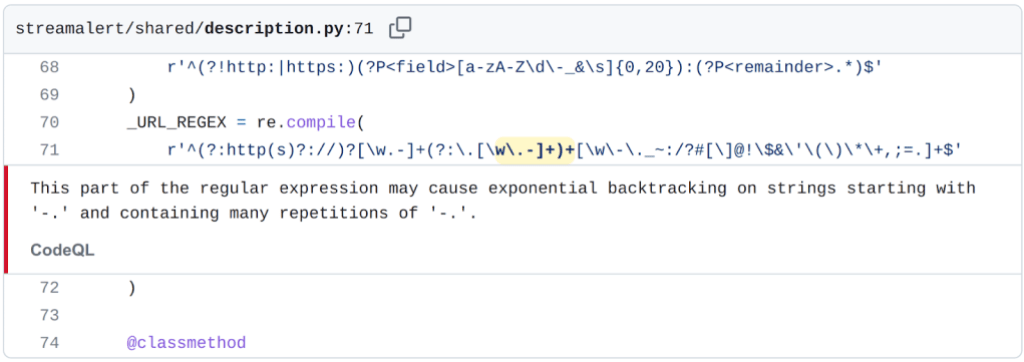
Step 1: create a PoC
The first step is to reproduce the problem. The code scanning alert gives instructions on how to trigger the bug:
“This part of the regular expression may cause exponential backtracking on strings starting with ‘-.’ and containing many repetitions of ‘-.’.”
I find that debugging is much easier if I create a standalone Python program to reproduce the bug:
import re
_URL_REGEX = re.compile(
r'^(?:http(s)?://)?[\w.-]+(?:\.[\w\.-]+)+[\w\-\._~:/?#[\]@!\$&\'\(\)\*\+,;=.]+$'
)
_URL_REGEX.fullmatch("-." + "-." * 100)
That program finishes instantly though. Why doesn’t it trigger the ReDoS? The answer is that the regex needs to not find a match, so that it’s forced to explore the whole exponential search tree. It’s usually possible to achieve that by adding an unusual character to the end of the string. In this case, a % character works well:
_URL_REGEX.fullmatch("-." + "-." * 100 + "%")
With that change, the test program triggers the ReDoS.
Step 2: reduce the problem
Regexes are dense. This one is only 77 characters long, but it still makes my head hurt:
^(?:http(s)?://)?[\w.-]+(?:\.[\w\.-]+)+[\w\-\._~:/?#[\]@!\$&\'\(\)\*\+,;=.]+$
I find it much easier to solve a ReDoS if I first get rid of everything that’s irrelevant to the problem. So, I edit my test program, trying to make the regex as short as possible while still preserving the ReDoS. For example, the first segment of this regex is (?:http(s)?://)?. The ? character at the end means that this segment is optional, so I can remove it, leaving a slightly simpler regex that still has a ReDoS:
^[\w.-]+(?:\.[\w\.-]+)+[\w\-\._~:/?#[\]@!\$&\'\(\)\*\+,;=.]+$
After every step, I rerun the test to make sure that the ReDoS is still happening. Here are some common simplification steps:
- Remove optional sections such as
X?orX*. - Replace
X+withX. - Replace
X|Ywith justXor justY. - Simplify character ranges. For example, replace
[a-z0-9]with[ab].
Applying some of those steps to simplify this regex further:
^[\w.-]+(?:\.[\w\.-]+)+[\w\-\._~:/?#[\]@!\$&\'\(\)\*\+,;=.]+$ |
remove + |
^[\w.-](?:\.[\w\.-]+)+[\w\-\._~:/?#[\]@!\$&\'\(\)\*\+,;=.]+$ |
remove + |
^[\w.-](?:\.[\w\.-]+)+[\w\-\._~:/?#[\]@!\$&\'\(\)\*\+,;=.]$ |
simplify character ranges |
^[-](?:\.[\.-]+)+[\w\-\._~:/?#[\]@!\$&\'\(\)\*\+,;=.]$ |
simplify character range |
^[-](?:\.[\.-]+)+[\w]$ |
use regular parens |
^[-](\.[\.-]+)+[\w]$ |
Finally, I replace characters like - and . with letters like x and y to make it easier to read. The input string in the PoC needs a corresponding change:
import re
_URL_REGEX = re.compile(
r'^x(y[yx]+)+z$'
)
_URL_REGEX.fullmatch("xy" + "xy" * 100 + "%")
Step 3: identify the problem and rewrite the regex
It’s clear now that this segment is responsible for the ReDoS:
(y[yx]+)+
That’s because there are multiple ways for it to match a string like “yxyxyxyxyxyx,” as illustrated below with parens added to show where the inner + could match:
- (yx)(yx)(yx)(yx)(yx)(yx)
- (yxyx)(yxyx)(yxyx)
- (y)(xyxyxyxyxyx)
- …
When you think about it, the inner segment of the regex (y[yx]+) can parse any string like “yxyyxxxyx…,” that is, any string that starts with a y and is followed by an arbitrary sequence of x or y characters. In other words, the inner segment is already sufficiently flexible to parse every valid string, and the outer + doesn’t add anything (other than a ReDoS). Therefore, I can fix the ReDoS by removing the outer +:
y[yx]+
Now, I can apply the same change to the original regex. Here are both versions, to show the change:
| old | ^(?:http(s)?://)?[\w.-]+(?:\.[\w\.-]+)+[\w\-\._~:/?#[\]@!\$&\'\(\)\*\+,;=.]+$ |
| new | ^(?:http(s)?://)?[\w.-]+(?:\.[\w\.-]+)[\w\-\._~:/?#[\]@!\$&\'\(\)\*\+,;=.]+$ |
Fixing the regex is always the most difficult step. You have to understand the pattern that it’s trying to parse and figure out whether you can achieve the same thing with fewer choice operators (such as + or |). But it’s much easier to find a solution if you’ve reduced the problem as much as possible first.
Don’t forget that you can use code scanning to confirm that your updated regex is indeed ReDoS-free.
Step 4: use a fuzzer to check your fix
Regexes are very difficult to get right, so there’s no substitute for thorough testing. It’s important to check that you haven’t accidentally changed the behavior of the regex. If you’re using Python, then I recommend using the atheris fuzzer for this. Below is an example script that uses atheris to compare two regexes:
#! /usr/bin/env python3
import atheris
import sys
import re
regex_old = re.compile(r"a(?P[b-z]+)c", flags=re.UNICODE)
regex_new = re.compile(r"a(?P[b-y]+)c", flags=re.UNICODE)
# Extract data from a Match object so that it can be tested for equality.
def getMatchData(result):
if result is None:
return None
return (result.group(), result.groups(), result.groupdict())
def TestOneInput(input_bytes):
try:
s = input_bytes.decode('utf-8')
except:
return
if getMatchData(regex_old.fullmatch(s)) != getMatchData(regex_new.fullmatch(s)):
raise RuntimeError("results don't match!")
atheris.instrument_all()
atheris.Setup(sys.argv, TestOneInput)
atheris.Fuzz()
Run the script like this:
python3 fuzz_regexes.py -max_len=10
Or, if you want to use all your cores and you have a corpus directory containing test cases then you can fuzz more effectively like this (the command-line syntax is the same as libFuzzer):
python3 `realpath fuzz_regexes.py` corpus/ -jobs=$(nproc) -workers=$(nproc) -max_len=10
The script checks that regex_old.fullmatch(s) and regex_new.fullmatch(s) both compute the same result. In the above example, the two regexes are deliberately different, and atheris is typically able to find a counterexample (such as “azc”) in a couple of minutes. It obviously might take longer on a complicated regex, so I would recommend leaving the fuzzer running for a few hours at least. Note that you can use the -max_len parameter to control the maximum size of the input string. Regex bugs are usually reproducible with a very short input string, but if your regex is very complicated then you might need to increase the maximum length to cover all the possibilities.
The tale of the viral ReDoS
People like to share regexes. We encountered an interesting example of this when we were searching for ReDoS vulnerabilities in open source projects because we kept finding the same ReDoS in many unrelated projects. The ReDoS is in a huge regex for parsing URLs. Here are a few examples: validators, textacy, and dparse. (Please click one of these links so that you can see what I’m talking about.) There’s no mystery about where the ReDoS originated from because many of the regexes have a comment like this:
# source: https://gist.github.com/dperini/729294
Interestingly, the regex at that gist does not have a ReDoS now, but if you go back through the revision history you’ll see that it did have a ReDoS prior to 2018-09-12. Many projects are still using an older, vulnerable version of the regex, which is not very surprising because this answer on Stack Overflow was written in 2012, so people have been sharing this regex for at least that long.
I made two big mistakes when I reported this ReDoS vulnerability to several projects back in 2021. My first mistake was that I never bothered to run our ReDoS query on the most up-to-date version of the regex from the gist. If I had, I would have realized that the ReDoS in the gist had already been fixed, and I could have advised projects to upgrade to the latest version. In fact, it was only when writing this blog post that I finally realized it: I was so focused on current bugs that I hadn’t researched the history of the regex.
My second mistake was to be intimidated by the size of the regex. I only made a half-hearted attempt to fix the ReDoS before jumping to the (incorrect) conclusion that such a large regex must be unfixable. Again, it was only when writing this blog post that I discovered it can be fixed by deleting just two + characters. I have since posted pull requests (here and here) to close out two of my remaining issues that have been hanging around since 2021.
Fixing the URL validator ReDoS
The steps to fix this ReDoS are exactly the same as I described earlier. And although the regex looks scary, it has huge segments that can be quickly eliminated. I’ll use textacy as an example. The ReDoS can be triggered with a long string like this:
http://0.00.00.00.00.00.00.00.00.00.00.00.00.00.00.00.00.00.00.00.00.00…
After I created a standalone PoC, I realized that large segments of the regex could be quickly removed during the reduction phase. For example, lines 56-69 are not involved in the ReDoS and can be deleted. After a few more reduction steps, the PoC is already much more manageable:
import re
url_regex = re.compile(
r"http://"
r"("
# host name
r"(([0-9]-?)*[0-9]+)"
# domain name
r"(\.([0-9]-?)*[0-9]+)*"
# TLD identifier
r"[a-z]"
r")",
flags=re.IGNORECASE
)
url_regex.fullmatch("http://0" + ".00" * 100)
After a few more reduction steps, it became clear that I could fix the ReDoS by removing the two + characters from this snippet:
# host name
r"(?:(?:[a-z\u00a1-\uffff0-9]-?)*[a-z\u00a1-\uffff0-9]+)"
# domain name
r"(?:\.(?:[a-z\u00a1-\uffff0-9]-?)*[a-z\u00a1-\uffff0-9]+)*"
After running the fuzzer for several hours to check that this solution is correct, I submitted this pull request which is now merged.
Conclusion
It makes me sad that ReDoS even exists as a vulnerability class. DFA theory has been understood since the 1940s, so, in my opinion, there’s no excuse for regex engines with exponential runtime behavior. Hopefully, more languages will follow the lead of Ruby 3.2.0 and improve their regex engines to reduce the number of ReDoS vulnerabilities. The good news is that code scanning can detect ReDoS vulnerabilities, so that should help to eradicate them. If you do discover that your project has a ReDoS, then I hope that the steps outlined in this blog post will help you to fix it quickly.
Tags:
Written by

Related posts
The case for a cooldown: Why Dependabot now waits before issuing version updates
A new default three-day cooldown delays version update pull requests so maintainers and security researchers can address findings in a release before it gets into your code.

Next chapter: Restructuring GitHub’s bug bounty program
GitHub is making some significant changes to its bug bounty program, shifting its focus to give researchers a better experience working with the GitHub team.
How GitHub gave every repository a durable owner
GitHub had over 14,000 repositories. Fewer than half had clear ownership. Here’s how we gave every active repository a validated owner in under 45 days, archived the rest, and made ownership the foundation for everything that followed.