The code that wasn’t there: Reading memory on an Android device by accident
CVE-2022-25664, a vulnerability in the Qualcomm Adreno GPU, can be used to leak large amounts of information to a malicious Android application. Learn more about how the vulnerability can be used to leak information in both the user space and kernel space level of pages, and how the GitHub Security Lab used the kernel space information leak to construct a KASLR bypass.

In this post I’ll cover the details of CVE-2022-25664, a vulnerability in the Qualcomm Adreno GPU that I reported to Qualcomm in November 2021. The bug was a somewhat accidental find, and although it can only be used to leak information, it is nevertheless a very powerful bug that can be used to leak large amounts of information to a malicious Android app; it can be used an unlimited number of times with no adverse effects on the running state of the phone. I’ll show how it can be used to leak information at the page level in the user space and kernel space. I’ll then use the kernel space information leak to construct a KASLR bypass. From a vulnerability research point of view, it’s also a rather subtle and perhaps one the most unusual bugs that I’ve ever found. In October 2022, the bug was both disclosed publicly in the Qualcomm security bulletin, and the fix was applied to Android devices in the Android Security patch.
The Adreno GPU commands
Qualcomm devices, such as the U.S. versions of the S Series Samsung Galaxy phone and Google’s Pixel phone, use the Adreno GPU. In order to perform computations on the GPU, applications need to be able to interact with and send commands to it. While this is normally done via shader languages like OpenGL ES and Vulkan, under the hood, programs written in shader languages are compiled into GPU instruction sets and sent to the GPU by using the kernel graphics surface layer (KGSL) kernel driver. As it is crucial for applications to render themselves via the GPU with little latency, user applications are allowed to access the KGSL driver directly.
While the GPU instruction sets are proprietary and there is little public documentation about their format, the kernel driver also uses a limited number of GPU instructions in various places. By looking at how the kernel driver uses GPU commands, it is possible to gain some insights and construct some simple commands. In Attacking the Qualcomm Adreno GPU, Ben Hawkes gave some examples of how to construct commands for writing to memory using the GPU. For example, to instruct the GPU to write to a certain memory address, the following instruction can be used:
uint32_t* write_cmds;
*write_cmds++ = cp_type7_packet(CP_MEM_WRITE, 2 + num_words);
write_cmds += cp_gpuaddr(write_cmds, write_to_gpuaddr);
The above instructions in write_cmds instruct the GPU to write num_words words to the address specified by write_to_gpuaddr, which is some memory that is already mapped into the GPU address space. cp_type7_packet and cp_gpuaddr are functions that construct the relevant GPU instructions and CP_MEM_WRITE is an opcode that specifies the operation. The definitions of these can be found in the adreno_pm4types.h file in the kernel source code. To construct simple GPU instructions, I can simply copy these functions and macros to my applications and use them to write instructions similar to the example above. There are some examples of GPU instructions in the adreno_pm4types.h file, but, in general, an instruction consists of first creating a packet with the opcode and the size of the instruction, followed by specific inputs to the instruction. For example, the cp_protected_mode instruction (a privileged instruction that cannot be run by user applications) consists of the following:
static inline u32 cp_protected_mode(struct adreno_device *adreno_dev,
u32 *cmds, int on)
{
cmds[0] = cp_packet(adreno_dev, CP_SET_PROTECTED_MODE, 1); //<-------- 1.
cmds[1] = on; //<-------- 2.
return 2;
}
In the first line, a cp_packet is constructed with the CP_SET_PROTECTED_MODE opcode and the size of the instruction is one word (third argument to cp_packet). The next word is the input to the instruction, specifying whether to switch on or turn off the protected mode.
In order to send these instructions to the GPU, the commands need to be written to a location that can be accessed by the GPU. This can be done by sharing application memory with the GPU using various ioctl in the KGSL driver. For example, the IOCTL_KGSL_MAP_USER_MEM ioctl takes a user space memory address and maps it to the GPU address space. It then returns the address of the memory in the GPU to the user.
struct kgsl_map_user_mem req = {
.len = len,
.offset = 0,
.hostptr = addr, //<--------- user space address
.memtype = KGSL_USER_MEM_TYPE_ADDR,
};
if (readonly) {
req.flags |= KGSL_MEMFLAGS_GPUREADONLY;
}
int ret;
ret = ioctl(fd, IOCTL_KGSL_MAP_USER_MEM, &req);
if (ret)
return ret;
*gpuaddr = req.gpuaddr; //<--------- address that the GPU can use for accessing the user memory
After mapping user memory to the GPU, GPU commands can be written in the mapped user space address and accessed by the GPU via the address returned by the IOCTL_KGSL_MAP_USER_MEM ioctl. In order to run the command on the GPU, the IOCTL_KGSL_GPU_COMMAND ioctl can be used. It takes the GPU address of the command buffer and executes the commands stored within it.
So for example, to write some data to memory via the GPU, I can do the following:
uint32_t* write_cmds = mmap(NULL, 0x1000, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0);
uint32_t* write_to = mmap(NULL, 0x1000, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0);
//Map command buffer to GPU
struct kgsl_map_user_mem_req cmd_req = {.hostptr = (uint64_t)write_cmds,...};
ioctl(kgsl_fd, IOCTL_KGSL_MAP_USER_MEM, &cmd_req);
uint64_t write_cmd_gpuaddr = cmd_req.gpuaddr;
//Map destination buffer to GPU
struct kgsl_map_user_mem_req write_req = {.hostptr = (uint64_t)write_to,...};
ioctl(kgsl_fd, IOCTL_KGSL_MAP_USER_MEM, &write_req);
uint64_t write_to_gpuaddr = write_req.gpuaddr;
//Construct write command
*write_cmds++ = cp_type7_packet(CP_MEM_WRITE, 2 + 1);
write_cmds += cp_gpuaddr(write_cmds, write_to_gpuaddr);
write_cmds++ = 0x41;
struct kgsl_command_object cmd_obj = {.gpuaddr = write_cmd_gpuaddr,...};
struct kgsl_gpu_command cmd = {.cmdlist = (uint64_t)(&cmd_obj),...};
...
ioctl(kgsl_fd, IOCTL_KGSL_GPU_COMMAND, &cmd);
The GPU should then write 0x41 to the destination buffer write_to.
Only it doesn’t.
The code that should not have been there
When I tried sending commands to the GPU using the above code, I often encountered errors, and the value 0x41 was not written to the destination memory. As GPU errors are sometimes handled and reported in the kernel log, I decided to take a look at the kernel log (on a rooted phone) to see if there was any hint as to why the code wouldn’t work. Often I saw errors like the following:
[ 4775.765921] c3 289 kgsl kgsl-3d0: |a6xx_cp_hw_err_callback| CP opcode error interrupt | opcode=0x0000007e
[ 4776.189015] c3 0 kgsl kgsl-3d0: |adreno_hang_int_callback| MISC: GPU hang detected
[ 4776.197549] c2 289 kgsl kgsl-3d0: adreno_ion[4602]: gpu fault ctx 13 ctx_type ANY ts 1 status 00800005 rb 00f3/00f3 ib1 0000000040000FEC/036c ib2 0000000000000000/0000
The first line indicates that an error occurs at the opcode with value 0x7e. This is rather strange, as the command buffer does not contain the value 0x7e at all. And, what’s more strange, is that the problematic opcode seems to vary on each run, and most of those values are also not contained in the command buffer.
While I was puzzled by what I’d seen, I noticed that in Ben Hawkes’ code, there is a delay between the writing of the command buffer and the sending of it to the GPU:
...
*payload_cmds++ = cp_type7_packet(CP_MEM_WRITE, 3);
payload_cmds += cp_gpuaddr(payload_cmds, 0x40403000+20);
*payload_cmds++ = 0x13371337;
payload_cmds_size = (payload_cmds - payload_buf) * 4;
usleep(50000);
...
Although I wasn’t really convinced that it was the problem, I decided to give it a go and add a delay before sending the command to the GPU. To my surprise, it worked, and the command succeeded much more often after the delay was added. At this point, the story could have ended – everything seemed to be working as it should.
But the mysterious opcode bugged me, so I decided to go down the rabbit hole…
The fact that an opcode that is not in the command buffer appears in the kernel log seems to indicate that the GPU is seeing something that I don’t see, so the first step is to find out what the GPU is actually reading–but how? The commands that are used in the kernel code only include the write instruction, not the read instruction, so there is no obvious way to read from the GPU using the low level commands. To understand how to read, it is perhaps useful to take a closer look at how the write instruction works. The write instruction consists of 3 + num_to_write words, where num_to_write is the length of the write in words. The first word is constructed using cp_type7_packet(CP_MEM_WRITE, 2 + num_to_write), which encodes the write command CP_MEM_WRITE and the size of the command 2 + num_to_write. The next two words are just the GPU address of the destination buffer (which is of 8 bytes, so it splits into two words) and the rest of the instruction just contains the values to be written.
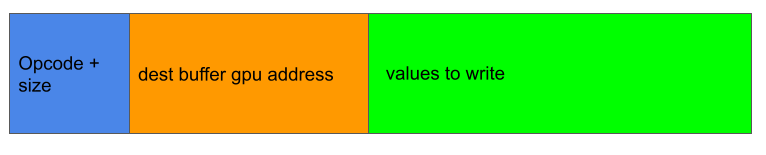
When writing, the GPU actually has to read num_to_write words from the command buffer and then write those words to the destination buffer. The content in the destination buffer actually does give us a view of what the GPU is seeing. There is, however, one problem. What I’m trying to find out is what happens when the GPU command fails, and I suspect that, in that case, what the GPU is reading may not be what I’ve put in the command buffer. If that happens, then the write command will fail and I won’t be able to copy the content of the command buffer to the destination buffer. This means it won’t be possible for me to know what the GPU is reading at this point. If, on the other hand, the write command succeeds, then the GPU is reading the command correctly and there will be no discrepancy between what is in the command buffer and what the GPU is reading. This is indeed the case. So it seems that there is no way to find out more about the content that the GPU reads when the command fails.
While this is impossible with a single buffer, it is possible with two command buffers that are mapped separately. Suppose we have two command buffers, each one page long, that are adjacent to each other in the GPU address space. If I put the GPU command near the end of the first buffer, so that the first three words of the command, which contains the GPU instructions, lie in the first buffer, while the values that are to be written lie in the second buffer:
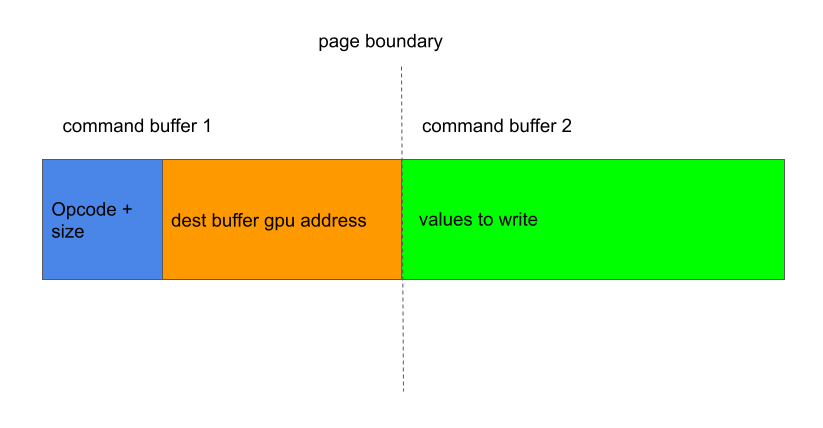
Then it is possible to have a situation where the GPU view of the first buffer is consistent with my view of the buffer, while the GPU view of the second buffer is not. In this case, the GPU will read the valid write instructions from the first buffer and copy the content of the second buffer to my destination buffer. This will show me the inconsistent view of the GPU of the second buffer. Moreover, since I already know that introducing a delay after writing to a buffer increases the chance that the GPU is getting the correct view, I can use this to my advantage and do the following:
- Map a first buffer in the user space and then to the GPU, write the first three write instructions towards the end of the buffer from user space and then wait for a short time, so the GPU is more likely to read the correct instructions that I put in the buffer.
- Map a second buffer in the user space.
- Map the second buffer to the GPU so it becomes adjacent to the first buffer, and then send the GPU instructions without any delay.
If done right, then the destination buffer should contain the content of the second buffer, as read by the GPU. This works and I often get this kind of data in the destination buffer, which I definitely have not written and look suspiciously like user space addresses to me.
dest_buf[0] 0x7e52c58b16
dest_buf[1] 0x7e52c5a731
dest_buf[2] 0x7e52c5b68c
dest_buf[3] 0x7e52c5c78d
dest_buf[4] 0x7e52c60e81
It appears that the GPU is reading data that was left in the second buffer by a previous use. To test this, I can mmap a page, and fill it with some easily recognisable “magic value,” such as 0x41414141, and then unmap the page right before the second buffer is mapped. This will likely cause the second buffer to reuse the page that is filled with my “magic value,” and if the GPU really is reading stale content from the page, then I should see these “magic values” appearing in the destination buffer. This is indeed the case:
dest_buf[0] 0x4141414141414141
dest_buf[1] 0x4141414141414141
dest_buf[2] 0x4141414141414141
dest_buf[3] 0x4141414141414141
dest_buf[4] 0x4141414141414141
At this point, I believed that I had a case for an information leak bug and a reasonable understanding of how to trigger it, so I reported it even though I was still not entirely sure about the cause.
The code that should have been there
I suspected that this bug was a cache coherency issue. When writing to memory from my application, or when the kernel is clearing stale data in pages, the memory access is done via the CPU and the content is first written to the CPU cache, and only synchronized with the physical memory when the cache is flushed. In modern architectures, CPU cache is coherent between different CPU cores, meaning that different CPU cores will always see the same copy of the data. This, however, is not true for devices like the GPU that access the physical memory directly, which can read stale copies of the data that is different to that in the CPU cache. The kernel provides different functions to synchronize physical memory with the CPU cache when needed, and my suspicion is that the memory is not synchronized before the user page is mapped to the GPU, which causes the current issue.
To find out more about this, let’s take a look at how the GPU gets user pages. When using the IOCTL_KGSL_MAP_USER_MEM ioctl, the KGSL driver uses get_user_pages to obtain references to the pages that are backing the user memory.
What is interesting is that, get_user_pages actually calls flush_anon_page and flush_dcache_page, which suggests that the cache does get flushed before the page is returned to the caller. It looks like that memory coherent issue is being taken care of by the use of get_user_pages and there is no need to synchronize the memory from the driver side. Except that names can be rather deceptive sometimes.
On Arm64, the function flush_anon_page is defined in highmem.h:
#ifndef ARCH_HAS_FLUSH_ANON_PAGE
static inline void flush_anon_page(struct vm_area_struct *vma, struct page *page, unsigned long vmaddr)
{
}
#endif
As ARCH_HAS_FLUSH_ANON_PAGE is not defined on Arm64, the function flush_anon_page is actually a no op. At the same time, the function flush_dcache_page does not actually flush the CPU cache, but rather marks it as dirty for later flushing:
/*
* This function is called when a page has been modified by the kernel. Mark
* it as dirty for later flushing when mapped in user space (if executable,
* see __sync_icache_dcache).
*/
void flush_dcache_page(struct page *page)
{
if (test_bit(PG_dcache_clean, &page->flags))
clear_bit(PG_dcache_clean, &page->flags);
}
Neither of these actually synchronizes the memory and the driver does need to flush the CPU cache after all. And as the KGSL driver does not flush the cache explicitly (the developers also assumed that get_user_pages would flush the cache), this causes the current problem.
As this bug does not cause any adverse effect and there is no limit to how many values can be written with the CP_MEM_WRITE GPU command, leaking user space memory is fairly trivial; I just need to repeatedly trigger this bug and use it to copy pages of memory to the destination buffer. The amount of memory that can be leaked in one go is somewhat limited by how fast memory can be read before the cache is flushed, but can easily be a couple of pages. While this gives a risk free way of leaking memory freed by other user processes, it’s pot luck what I get as there is no obvious way to know or manipulate which process frees the page that I’m reusing as the second command buffer.
Leaking kernel memory
Leaking kernel memory and using it to construct a KASLR bypass is somewhat trickier, because the kernel page allocator allocates pages according to their zones and migrate type, and pages do not generally get allocated to a different zone or migrate type, even in the slow path. The possible zones and migration types can be found in the mmzone.h file. Most platforms will have ZONE_NORMAL, ZONE_DMA/ZONE_DMA32 (depending on the configuration) and ZONE_MOVABLE, as well as the migrate types MIGRATE_UNMOVABLE, MIGRATE_MOVABLE and MIGRATE_RECLAIMABLE. Kernel pages, such as those used by the SLUB allocator for object allocation, are usually allocated in ZONE_NORMAL with MIGRATE_UNMOVABLE type. Depending on the GFP mask that is passed to the alloc_page function when allocating a page, it can also sometimes have the MIGRATE_RECLAIMABLE type. Pages that are mapped to user space, such as those allocated for mmap, are usually allocated with the GFP_HIGHUSER or the GFP_HIGHUSER_MOVABLE mask. On platforms with CONFIG_HIGHMEM enabled, these will be allocated in the ZONE_HIGHMEM zone with either MIGRATE_UNMOVABLE (with GFP_HIGHUSER) or MIGRATE_UNMOVABLE (with GFP_HIGHUSER_MOVABLE). On Android, however, as CONFIG_HIGHMEM is not enabled, these are allocated in ZONE_NORMAL instead. So in order to reuse a kernel page, I need to find a user page that is allocated with the GFP_HIGHUSER flag so that it is allocated in ZONE_NORMAL with the MIGRATE_UNMOVABLE migration type. User pages that are allocated with an anonymous mmap, however, are allocated as GFP_HIGHUSER_MOVABLE pages.
So in order to leak kernel memory, I need to find a way to map a page to the user space that is of the type MIGRATE_UNMOVABLE. One way to do this is to look for drivers or file systems that allocate and map pages of this type to the user space via their mmap operation, but not all drivers that do so are suitable. For example, the ion driver creates pages with the GFP_HIGHUSER mask:
static gfp_t low_order_gfp_flags = GFP_HIGHUSER | __GFP_ZERO;
...
static int ion_system_heap_create_pools(struct ion_page_pool **pools)
{
int i;
for (i = 0; i < NUM_ORDERS; i++) {
struct ion_page_pool *pool;
gfp_t gfp_flags = low_order_gfp_flags;
...
pool = ion_page_pool_create(gfp_flags, orders[i]); //<---- memory pool created using GFP_HIGHUSER
...
}
return 0;
...
}
When mmap is called to map the direct memory access (DMA) files that are created by using the ION_IOC_ALLOC ioctl, these pages are mapped to the user space using remap_pfn_range. These regions, however, cannot be used for our purpose because remap_pfn_range adds the VM_IO and VM_PFNMAP flags to the mmapped region. These flags are checked in the __get_user_pages function and would result in an error if they are found:
static int check_vma_flags(struct vm_area_struct *vma, unsigned long gup_flags)
{
...
if (vm_flags & (VM_IO | VM_PFNMAP))
return -EFAULT;
...
}
So I need to find a driver or file system with the following requirements:
- Accessible from untrusted user applications.
- Allocates pages with the
MIGRATE_UNMOVABLEmigrate type and maps those pages to user space. - Does not mark the user space memory area with the
VM_IOorVM_PFNMAPflag. In particular, it cannot useremap_pfn_rangeto map the memory to user space.
There are several choices. In particular, the asynchronous I/O file system meets these requirements. The io_setup syscall allocates pages with the GFP_HIGHUSER mask and then maps these pages to user space:
static int aio_setup_ring(struct kioctx *ctx, unsigned int nr_events)
{
...
file = aio_private_file(ctx, nr_pages);
...
for (i = 0; i < nr_pages; i++) {
struct page *page;
page = find_or_create_page(file->f_mapping,
i, GFP_HIGHUSER | __GFP_ZERO); //<------- Creates pages with GFP_HIGHUSER
...
ctx->ring_pages[i] = page;
}
ctx->nr_pages = i;
...
ctx->mmap_size = nr_pages * PAGE_SIZE;
...
ctx->mmap_base = do_mmap_pgoff(ctx->aio_ring_file, 0, ctx->mmap_size,
PROT_READ | PROT_WRITE,
MAP_SHARED, 0, &unused, NULL); //<-------- map pages to user space
up_write(&mm->mmap_sem);
}
The user space region that is mapped here doesn’t have either the VM_IO or the VM_PFNMAP flag and can be mapped to the GPU using the IOCTL_KGSL_MAP_USER_MEM ioctl.
There is, however, another slight inconvenience that I need to overcome before I can map this memory to the GPU. When mapping memory to the GPU, the kgsl_setup_useraddr function first tries to set up the memory region as a DMA region:
static int kgsl_setup_useraddr(struct kgsl_device *device,
struct kgsl_pagetable *pagetable,
struct kgsl_mem_entry *entry,
unsigned long hostptr, size_t offset, size_t size)
{
...
/* Try to set up a dmabuf - if it returns -ENODEV assume anonymous */
ret = kgsl_setup_dmabuf_useraddr(device, pagetable, entry, hostptr);
if (ret != -ENODEV)
return ret;
...
}
During which, it checks whether the memory region is mapped to a file and then checks whether the file is associated with a dma_buf:
static int kgsl_setup_dmabuf_useraddr(struct kgsl_device *device,
struct kgsl_pagetable *pagetable,
struct kgsl_mem_entry *entry, unsigned long hostptr)
{
struct vm_area_struct *vma;
struct dma_buf *dmabuf = NULL;
int ret;
/*
* Find the VMA containing this pointer and figure out if it
* is a dma-buf.
*/
down_read(¤t->mm->mmap_sem);
vma = find_vma(current->mm, hostptr);
if (vma && vma->vm_file) {
...
/* Look for the fd that matches this the vma file */
fd = iterate_fd(current->files, 0, match_file, vma->vm_file);
if (fd != 0) {
dmabuf = dma_buf_get(fd - 1);
if (IS_ERR(dmabuf)) {
up_read(¤t->mm->mmap_sem);
return PTR_ERR(dmabuf);
}
}
}
...
}
If I try to map a memory region that is mapped by the asynchronous I/O to the GPU, then it’ll see that the region is mapped to a file that is not a DMA file and fail. However, since this test only applies to the first vm_area_struct in the region that I’m trying to map, I can simply create a region that consists of two separate but adjacent user space memory areas, with the first one mapped as an anonymous region, while the second one is mapped via the asynchronous I/O. As the DMA check is applied to the anonymous region, it will succeed because the region is not mapped to a file. This then allows me to map the whole region to the GPU without failing the DMA file check.
To summarize, I need to create the following regions with these requirements:
- A region to use as the first command buffer. This region needs to store the valid opcode containing the write instruction towards the end of the region and the CPU cache and physical memory of this region needs to be in sync. I’ll call this region the command buffer.
- A region mapped as an anonymous region so as to pass the DMA check in
IOCTL_KGSL_MAP_USER_MEM. In the GPU address space, this region needs to be located right behind (that is, has a higher address) the first region. The CPU cache and physical memory of this region does not need to be in sync. I’ll call this region the anonymous buffer. - A region mapped via the asynchronous I/O so that it can reuse kernel pages as its backing page. The user space address of this region needs to be right after the second region. The CPU cache and physical memory of this region should be out of sync when the GPU command is executed, which means that it should be mapped just before the GPU command is sent to minimize the delay. I’ll call this region the source buffer.
There is no user space address requirement between the command buffer and the other buffers.
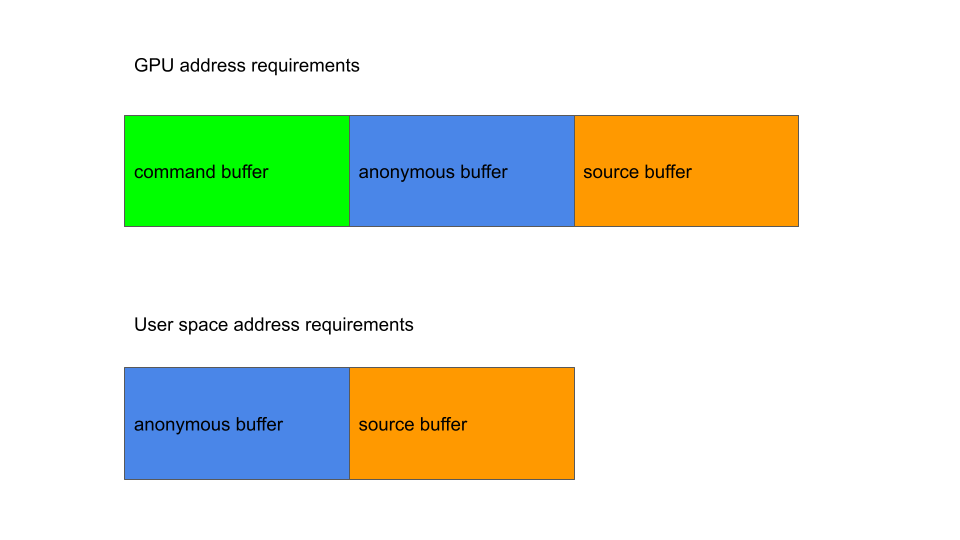
The GPU address requirement is fairly easy to satisfy, as they are mapped in increasing order: When memory is mapped to the GPU, the driver will try to find a gap in the user’s GPU address space that is big enough to fit the mapping in, starting from the lowest address. By mapping the command buffer to the GPU, and then mapping the combination of the anonymous and source buffers, the GPU address of the anonymous buffer will be adjacent to the command buffer.
For the user space address requirement, as mmap maps memory in a top-down manner and starts looking for free space from the highest address, the arrangement is slightly different. To meet the requirement, I first need to mmap a number of pages to fill out any potential gap in the memory space, so that subsequent mappings are done with contiguous memory addresses. As I need the source buffer to be mapped just before the GPU command is sent to minimize the delay, it has to be mapped after the anonymous buffer is mapped. However, due to the way that mmap assigns addresses in decreasing order, this will put the source buffer in front of the anonymous buffer instead of behind it.
This issue can be resolved easily by first mapping a region before the anonymous buffer as a placeholder, then unmapping it after the anonymous buffer is mapped to leave a “hole,” which will then be claimed by the source buffer that is mapped later.
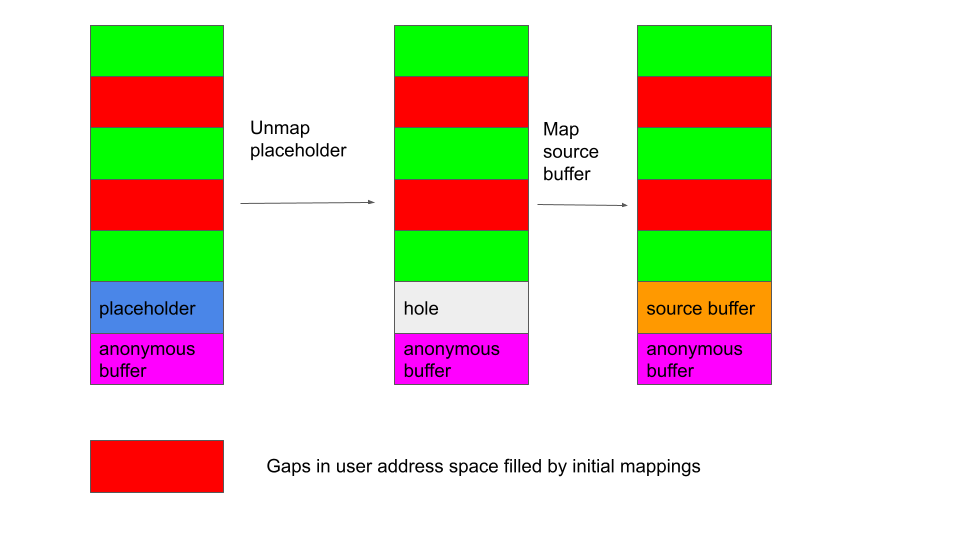
This memory layout now allows me to reuse kernel pages and leak information from the kernel. To turn this into a KASLR bypass, I now need to gain some control of the kernel page that’s going to be reused by the asynchronous I/O file.
The idea is very similar to the technique used in Jann Horn’s How a simple Linux kernel memory corruption bug can lead to complete system compromise, but much simpler because in this case – I just need to leak some memory rather than replacing a page precisely.
To recap, kernel objects allocated via kmalloc (and its variants) are allocated via the SLUB allocator. The SLUB allocator allocates objects from slabs, which are backed by memory pages. . Each slab may contain multiple pages depending on object size. Normally, when allocating and freeing objects, the object is taken from or returned to the slab. However, if a slab becomes empty and contains only free objects, then the whole slab may be freed and its backing pages may then be returned to the kernel page allocator. In this case, these pages may be reused for other purposes. My goal here is to create this situation and reuse the slab page as the backing page of the source buffer.
However, even when a slab is freed, its backing pages do not immediately go back to the kernel page allocator. When an object is freed from a backing page of a slab, the page is put into a per cpu partial list. The page remains in the cpu partial list even when it becomes empty and will only be freed and returned to the page allocator when the cpu partial list is full and flushed. So in order to reuse a page in the slab allocator, not only do I need to free all the objects from the page, but I also need to put enough pages into the cpu partial list afterwards so that the cpu partial list gets flushed. This generally involves the following (in what follows I assume the slabs I use contains only one page):
- Pin the current process to a specific CPU so that all these steps are performed on the same CPU. Allocate a number of kernel objects to fill up any partially filled slabs so that new objects allocated afterwards will use newly created slabs.
- Allocate
objects_per_slab * (cpu_partial + 1)of my target objects (which is the specific type of object that I want to read), whereobjects_per_slabis the number of objects in each slab andcpu_partialis the size of the per cpu partial list. This will now create at leastcpu_partialpages filled with these target objects. - Free the last
2 * objects_per_slabtarget objects to create an empty page. This page will then be stored in the per cpu partial list. - At this point I can either free all the objects allocated in step two, or just free one object in each page allocated in step two. Either way it’ll put all the pages into the per cpu partial list, flush it and return some pages filled with my target objects to the page allocator.
As the page allocator also maintains a per cpu cache, the pages freed in step four in the above will be added to this cache, meaning that if I now allocate a page from the same CPU, I’m likely to reuse one of these pages. This then allows me to reuse a page filled with my target object as the backing page of the source buffer. So by leaking the stale content in the source buffer using the vulnerability, I can read the fields in the target object.
A good target object to read from would be one that contains a pointer to some global kernel object and also a pointer to an object in the slab. This would allow me to compute the KASLR slide from the global object and also obtain addresses to objects in the kernel slab. For this purpose, I chose the kgsl_syncsource_fence object. It has a pointer to the global kgsl_syncsource_fence_ops object as the dma_fence_ops field, a pointer to itself as the cb_list and a pointer to a kgsl_syncsource object whose lifetime I can control as its parent. It can also be allocated easily via the IOCTL_KGSL_SYNCSOURCE_CREATE_FENCE ioctl and be freed by closing the file descriptor returned by the ioctl without allocating or freeing other objects in the same slab. This provides me all the information I need to construct a KASLR bypass.
The KASLR bypass and user space information leak can be found here with some setup notes. These work for all Qualcomm devices that I have tested.
Conclusion
In this post I’ve covered the details of CVE-2022-25664, an information leak bug that results from the coherency between the CPU cache and physical memory. By using the inconsistency between the CPU cache and physical memory, I was able to retrieve stale information that had been wiped in the CPU cache but not in the physical memory. As we’ve seen in this case, cache coherency issues can often be difficult to detect and debug, and the cache flushing API can also be rather confusing and behave differently depending on the architecture. In fact, I found the issue by mere accident while debugging a GPU command failure, and, even after discovering the issue, the root cause analysis was somewhat complicated by the unexpected behavior of the cache flushing functions on Arm64. However, precisely because of this, they can sometimes result in fairly powerful bugs that lurk in codebases for a long time and evade detection.
Tags:
Written by

Related posts
Tame Dependabot: Group your updates, slow the cadence, keep security fast
Dependabot keeps your dependencies current, but its defaults can flood your repository with pull requests. Here’s how grouping updates, slowing the cadence, and keeping security fixes fast cut the noise on a Microsoft open source project.
Disrupting supply chain attacks on npm and GitHub Actions
Explore the changes we’ve shipped across npm and GitHub Actions over the past few months to disrupt supply chain attack techniques and limit their impact.
The case for a cooldown: Why Dependabot now waits before issuing version updates
A new default three-day cooldown delays version update pull requests so maintainers and security researchers can address findings in a release before it gets into your code.