Partitioning GitHub’s relational databases to handle scale
In 2019, to meet GitHub’s growth and availability challenges, we set a plan in motion to improve our tooling and ability to partition relational databases.

More than 10 years ago, GitHub.com started out like many other web applications of that time—built on Ruby on Rails, with a single MySQL database to store most of its data.
Over the years, this architecture went through many iterations to support GitHub’s growth and ever-evolving resiliency requirements. For example, we started storing data for some features (like statuses) in separate MySQL databases, we added read replicas to spread the load across multiple machines, and we started using ProxySQL to reduce the number of connections opened against our primary MySQL instances.
Yet at its core, GitHub.com remained built around one main database cluster (called mysql1) that housed a large portion of the data used by core GitHub features, like user profiles, repositories, issues, and pull requests.
With GitHub’s growth, this inevitably led to challenges. We struggled to keep our database systems adequately sized, always moving to newer and bigger machines to scale up. Any sort of incident negatively affecting mysql1 would affect all features that stored their data on this cluster.
In 2019, in order to meet the growth and availability challenges we faced, we set a plan in motion to improve our tooling and our ability to partition relational databases. As you can imagine, this was a complex challenge necessitating the introduction and creation of various tools as outlined below.
The result, we see in 2021, is a 50% load reduction on database hosts housing the data that once was on mysql1. This contributed significantly to reducing the number of database-related incidents and improved GitHub.com’s reliability for all our users.
Virtual partitions
The first concept we introduced was virtual partitions of database schemas. Before database tables can be moved physically, we have to make sure they are separated virtually in the application layer, and this has to happen without impacting teams working on new or existing features.
To do that, we group database tables that belong together into schema domains and enforce boundaries between the domains with SQL linters. This allows us to safely partition data later without ending up with queries and transactions that span partitions.
Schema domains
Schema domains are a tool we came up with to implement virtual partitions. A schema domain describes a tightly coupled set of database tables that are frequently used together in queries (such as, when using table joins or subqueries) and transactions. For example, the gists schema domain contains all of the tables supporting the GitHub Gist feature–like the gists, gist_comments and starred_gists tables. Since they belong together, they should stay together. A schema domain is the first step to codify that.
Schema domains put clear boundaries in place and expose sometimes-hidden dependencies between features. In the Rails application, the information is stored in a simple YAML configuration located at db/schema-domains.yml. Here’s an example illustrating the contents of that file:
gists:
- gist_comments
- gists
- starred_gists
repositories:
- issues
- pull_requests
- repositories
users:
- avatars
- gpg_keys
- public_keys
- users
A linter makes sure that the list of tables in this file matches our database schema. In turn, the same linter enforces the assignment of a schema domain to every table.
SQL linters
Building on top of schema domains, two new SQL linters enforce virtual boundaries between domains. They identify any violating queries and transactions that span schema domains by adding a query annotation and treating them as exemptions. If a domain has no violations, it is virtually partitioned and ready to be physically moved to another database cluster.
Query linter
The query linter verifies that only tables belonging to the same schema domain can be referenced in the same database query. If it detects tables from different domains, it throws an exception with a helpful message for the developer to avoid the issue.
Since the linter is only enabled in development and test environments, developers encounter violation errors early in the development process. In addition, during CI runs, the linter ensures that no new violations are introduced by accident.
The linter has a way to suppress the exception by annotating the SQL query with a special comment: /* cross-schema-domain-query-exempted */
We even built and upstreamed a new method to ActiveRecord to make adding such a comment easier:
Repository.joins(:owner).annotate("cross-schema-domain-query-exempted")
# => SELECT * FROM `repositories` INNER JOIN `users` ON `users`.`id` = `repositories.owner_id` /* cross-schema-domain-query-exempted */
By annotating all queries that cause failures, a backlog of queries needing modification can be built. Here’s a couple approaches we often use to eliminate exemptions:
- Sometimes, an exemption can easily be addressed by triggering separate queries instead of joining tables. One example is using
ActiveRecord‘spreloadmethod instead ofincludes.Another challenge is
has_many :throughrelations that lead toJOINs across tables from different schema domains. For that, we worked on a generic solution that got upstreamed to Rails as well:has_manynow has adisable_joins option that tells Active Record not to do anyJOINqueries across the underlying tables. Instead, it runs several queries passing primary key values. -
Joining data in the application instead of in the database is another common solution. For example, replacing
INNER JOINstatements with two separate queries and instead performing the “union” operation in Ruby (for example,A.pluck(:b_id) & B.where(id: ...)).In some cases, this leads to surprising performance improvements. Depending on the data structure and cardinality, MySQL’s query planner can sometimes create suboptimal query execution plans, whereas an application-side join has a more stable performance cost.
As with almost all reliability and performance-related changes, we ship them behind Scientist experiments that execute both the old and new implementations for a subset of requests, allowing us to assess the performance impact of each change.
Transaction linter
In addition to queries, transactions are a concern as well. Existing application code was written with a certain database schema in mind. MySQL transactions guarantee consistency across tables within a database. If a transaction includes queries to tables that will move to separate databases, it will no longer be able to guarantee consistency.
To understand which transactions need to be reviewed, we introduced a transaction linter. Similar to the query linter, it verifies that all tables which are used together in a given transaction belong to the same schema domain.
This linter runs in production with heavy sampling to keep the performance impact at a minimum. The linting results are collected and analyzed to understand where most cross-domain transactions happen, allowing us to decide to either update certain code paths or adapt our data model.
In cases where transactional consistency guarantees are crucial, we extract data into new tables that belong to the same schema domain. This ensures they stay on the same database cluster and therefore continue to have transactional consistency. This often happens with polymorphic tables that house data from different schema domains (for example, a reactions table storing records for different features like issues, pull requests, discussions, etc.)
Moving data without downtime
A schema domain that is virtually isolated is ready to be physically moved to another database cluster. To move tables on the fly, we use two different approaches: Vitess, and a custom write-cutover process.
Vitess
Vitess is a scaling layer on top of MySQL that helps with sharding needs. We use its vertical sharding feature to move sets of tables together in production without downtime.
To do that, we deploy Vitess’ VTGate in our Kubernetes clusters. These VTGate processes become the endpoint for the application to connect to, instead of direct connections to MySQL. They implement the same MySQL protocol and are indistinguishable from the application side.
The VTGate processes know the current state of the Vitess setup and talk to the MySQL instances via another Vitess component: VTTablet. Behind the scenes, Vitess’ table moving feature is powered by VReplication, which replicates data between database clusters.
Write-cutover process
Because Vitess’ adoption was still in its early stages at the beginning of 2020, we developed an alternative approach to move large sets of tables at once. This mitigated the risk of relying on a single solution to ensure the continued availability of GitHub.com.
We use MySQL’s regular replication feature to feed data to another cluster. Initially, the new cluster is added to the replication tree of the old cluster. Then a script quickly executes a series of changes to effect the cutover.
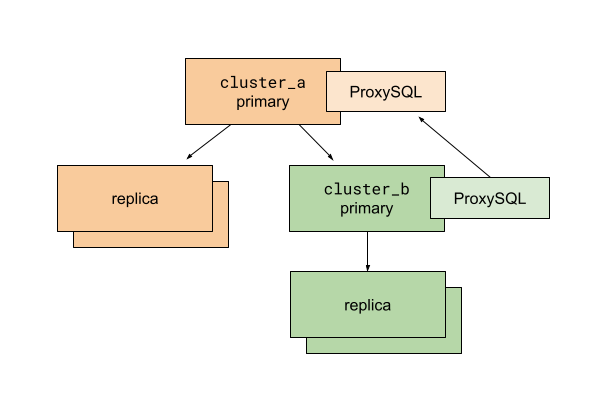
Before running the script, we prepare the application and database replication so that a destination cluster called cluster_b is a sub-cluster of the existing cluster_a. ProxySQL is used for multiplexing client connections to MySQL primaries. The ProxySQL instance on cluster_b is configured to route all traffic to the cluster_a primary. The use of ProxySQL allows us to change database traffic routing quickly and with minimal impact on database clients—in our case, the Rails application.
With this setup, we can move database connections to cluster_b without splitting anything. All read traffic still goes to hosts replicating from the cluster_a primary. All write traffic remains with the cluster_a primary too.
In this situation, we run a cutover script executing the following:
- Enable read-only mode for the
cluster_aprimary. At this point, all writes tocluster_aandcluster_bare prevented. All web requests that try to write to these database primaries fail and result in 500s. - Read the last executed MySQL GTID from the
cluster_aprimary. - Poll the
cluster_bprimary to verify the last executed GTID has arrived. - Stop replication on the
cluster_bprimary fromcluster_a. - Update ProxySQL routing configuration on
cluster_bto direct traffic to thecluster_bprimary. - Disable read-only mode for the
cluster_aandcluster_bprimaries. - Celebrate!
After thorough preparation and exercising, we learned that these six steps execute in only a few tens of milliseconds for our busiest database tables. Since we execute such cutovers during our lowest traffic time of day, we only cause a handful of user-facing errors because of failed writes. The results of this approach were better than we expected.
Learnings
The write-cutover process was used to split up mysql1, our original main database cluster. We moved 130 of our busiest tables at once––those that power GitHub’s core features: repositories, issues, and pull requests. This process was created as a risk-mitigation strategy to have multiple, independent tools at our disposal. In addition, because of factors like deployment topology and read-your-writes support, we didn’t choose Vitess as the tool to move database tables in every case. We anticipate the opportunity to use it for the majority of data migrations in the future though.
Results
The main database cluster mysql1, mentioned in the introduction, housed a large portion of the data used by many of GitHub’s most important features, like users, repositories, issues, and pull requests. Since 2019 we achieved the ability to scale this relational database with the following results:
- In 2019,
mysql1answered 950,000 queries/s on average, 900,000 queries/s on replicas, and 50,000 queries/s on the primary. - Today, in 2021, the same database tables are spread across several clusters. In two years, they saw continued growth, accelerating year-over-year. All hosts of these clusters combined answer 1,200,000 queries/s on average (1,125,000 queries/s on replicas, 75,000 queries/s on the primaries). At the same time, the average load on each host halved.
The load reduction contributed significantly to reducing the number of database-related incidents and improved GitHub.com’s reliability for all our users.
More partitioning
In addition to vertical partitioning to move database tables, we also use horizontal partitioning (aka sharding). This allows us to split database tables across multiple clusters, enabling more sustainable growth. We’ll detail the tooling, linters, and Rails improvements related to this in a future blog post.
Conclusion
Over the last 10 years, GitHub has been learning to scale according to its needs. We often choose to leverage “boring” technology that has been proven to work at our scale, as reliability remains the primary concern. But the combination of industry-proven tools with simple changes to our production code and its dependencies has provided us with a path for the continued growth of our databases into the future.
Written by

Related posts

How GitHub engineers tackle platform problems
Our best practices for quickly identifying, resolving, and preventing issues at scale.
GitHub Issues search now supports nested queries and boolean operators: Here’s how we (re)built it
Plus, considerations in updating one of GitHub’s oldest and most heavily used features.

Design system annotations, part 2: Advanced methods of annotating components
How to build custom annotations for your design system components or use Figma’s Code Connect to help capture important accessibility details before development.