How we found and fixed a rare race condition in our session handling
On March 8, we shared that, out of an abundance of caution, we logged all users out of GitHub.com due to a rare security vulnerability. We believe that transparency is…

On March 8, we shared that, out of an abundance of caution, we logged all users out of GitHub.com due to a rare security vulnerability. We believe that transparency is key in earning and keeping the trust of our users and want to share more about this bug. In this post we will share the technical details of this vulnerability and how it happened, what we did to respond to it, and the steps we are taking to ensure this does not happen again.
Reports from users
On March 2, 2021, we received a report via our support team from a user who, while using GitHub.com logged in as their own user, was suddenly authenticated as another user. They immediately logged out, but reported the issue to us, as it rightfully worried them.
We activated our security incident response procedures and immediately investigated the report, pulling in expertise from across the company in security, engineering, and customer support. A few hours after the initial report, we received a second report from another user with a very similar experience. After reviewing request and audit logs, we could validate the external reports received — a user’s session was indeed seen being suddenly shared across two IP addresses around the time of the reports.
Investigating recent infrastructure changes
Given that this bug was new behavior, we immediately suspected it to be tied to a recent change in our infrastructure and started by reviewing changes. We had recently upgraded components in our load balancing and routing tier. We identified that we had fixed an issue with HTTP keepalives which seemed like it could be related.
After investigating these changes, we were able to determine this was not the root cause. The requests of the affected users followed an entirely different path through our load balancing tier, touching different machines. We ruled out the possibility that the responses were being swapped at that level. Having ruled out the recent infrastructure changes as possible root causes, and with confidence the problem did not exist at the connection and protocol layers, we moved on to other potential causes.
Investigating recent code changes
The benefit of starting our investigation with recent infrastructure changes was that we did uncover that the requests that caused the incorrect session to be returned were handled on the same exact machine and in the same process. We run a multi-process setup using the Unicorn Rack web server for our main Rails application that handles things like viewing issues and pull requests.
From reviewing logs, we could gather that the HTTP body in the response to the client we sent was correct and only the cookies in the response to the user were wrong. The affected users from the support reports received a session cookie from a user who very recently had a request handled inside the same process. In one case, the two requests were handled sequentially, one after the other. In the second case, there were two other requests in between.
Our working theory then became that somehow something was leaking state between requests that ended up being handled in the same Ruby process. This left us wondering how this could happen.
By reviewing recently shipped features, we identified a potential thread safety issue that could be triggered by functionality that was recently rearchitected to improve performance. One such performance improvement involved moving the logic to check a user’s enabled features into a background thread that refreshed on an interval rather than checking their enablement while the request was being processed. This change seemed to touch the right areas and the undefined behavior of this thread safety issue now made it the focus of our investigation.
Thread safety and error reporting
In order to understand the thread safety issue, let’s set some context. The main application that handles most browser interactions on GitHub.com is a Ruby on Rails application and it was known to have components that were not written to run in multiple threads (i.e., are not thread-safe). Historically, the thread unsafe behavior could lead to an incorrect value being reported in an exception internally, but not to any user facing behavior change.
Threads were already used in other places in this application, but the new background thread produced a novel and unforeseen interaction with our exception handling routines. When exceptions were reported from a background thread, such as a query timeout, the error log would contain information from both the background thread and the currently running request, showing that the data was being pulled across threads.
We initially thought this to be an internal reporting problem only and that we would see some data logged for an otherwise unrelated request from the background thread. Though inconsistent, we considered this safe since each request has its own request data and Rails creates a new controller object instance for each request. It was still unclear to us how this could cause the problems we were seeing.
A reused object
The breakthrough was when the team identified that Unicorn, the underlying Rack HTTP server used in our Rails application, does not create a new and separate env object for each request. It instead allocates one single Ruby Hash that is then cleared (using Hash#clear) between each request that it handles. This led to the realization that the thread safety issue in our exception logging could result in not only inconsistent data being logged in these exceptions, but the sharing of request data on GitHub.com.
Our initial analysis led us to the hypothesis that two requests occuring within a short period of time were required to trigger the race condition. With this information, we tried to reproduce the issue in a development environment. When we attempted to sequence the exact requests, we found that one additional condition was needed and that was an anonymous request that started the whole sequence. The complete list of steps as follows:
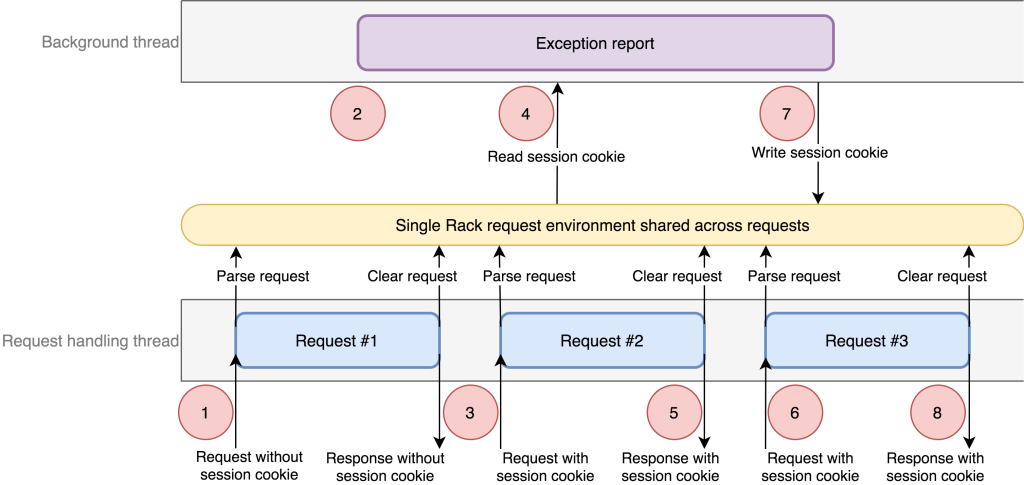
- In the request handling thread, an anonymous request (let’s call it Request #1) started. It registered callbacks in the current context for our internal exception reporting library. The callbacks included references to the current Rails controller object which had access to the single Rack request environment object provided by Unicorn.
- In the background thread, an exception occurred. The exception reporting copied the current context in order to include it in the report. This context included the callbacks registered by Request #1 including a reference to the single Rack environment.
- In the main thread, a new signed-in request started (Request #2).
- In the background thread, the exception reporting processed the context callbacks. One of the callbacks reads the user session identifier, but because the request at time of the context had no authentication, this data was not yet read and therefore triggered a new call to our authentication system via the Rails controller from Request #1. This controller tried to authenticate and pulled the session cookie from the single Rack environment. Because the Rack environment is the same object for all requests, the controller found Request #2’s session cookie.
- In the main thread, Request #2 finished.
- Another signed-in request started (Request #3). Request #3 completed its authentication step at this time.
- Back in the background thread, the controller finished the authentication step by writing a session cookie to the cookie jar that was in the Rack environment. At this point, it is the cookie jar for Request #3!
- The user received the response for Request #3. But the cookie jar was updated with the session cookie from Request #2, meaning the user is now authenticated as the user from Request #2.
In summary, if an exception occurred at just the right time and if concurrent request processing happened in just the right sequence across multiple requests, we ended up replacing the session in one response with a session from an earlier response. Returning the incorrect cookie only happened for the session cookie header and as we noticed before, the rest of the response body, such as the HTML, was all still based on the user who was previously authenticated. This behavior lined up with what we saw in our request logs and we were able to clearly identify all of the pieces that made up the root cause of this race condition.
This bug required very specific conditions: a background thread, shared exception context between the main thread and the background thread, callbacks in the exception context, reusing the env object between requests, and our particular authentication system. This complexity is a reminder of many of the points presented in How Complex Systems Fail and how multiple failures are required to cause a bug like this one.
Taking action
After identifying the root cause, we immediately prioritized eliminating two of the conditions that were essential in triggering this bug. First, we removed the new background thread introduced in the previously mentioned performance re-architecture. By knowing exactly what was added for this work, it was easy to revert. The change to remove this thread was deployed to production on March 5. With this change, we knew that the conditions required for the race condition could no longer be met and that our immediate risk of returning incorrect sessions was mitigated.
After we deployed the change to remove the background thread, we followed up by creating a patch for Unicorn to remove environment sharing. This patch was deployed on March 8 and further hardens the isolation between requests, even if thread safety issues occur.
In addition to fixing the underlying bug, we took action to make sure we identified affected user sessions. We examined our logging data for patterns consistent with incorrectly returned sessions. We then manually reviewed the logs matching the pattern to determine whether a session had in fact been incorrectly returned from one user to another.
As a final step, we decided to take a further preventative action to ensure the safety of our users’ data and revoked all active user sessions on GitHub.com. Considering the rarity of conditions required for this race condition, we knew that there was a very small chance of this bug occurring. While our log analysis, conducted from March 5 through March 8, confirmed that this was a rare issue, it could not rule out the possibility that a session had been incorrectly returned but then never used. This was not a risk we were willing to take, given the potential impact of even one of these incorrectly returned sessions being used.
With these two fixes in place and the revocation of sessions complete, we were confident that no new cases of the wrong session being returned could occur and that the impact of the bug had been mitigated.
Continuing work
While the immediate risk has been mitigated, we worked with the maintainer of Unicorn to upstream the change to make new requests allocate their own environment hashes. If Unicorn uses new hashes for each environment, it removes the possibility of one request mistakenly getting a hold of an object that can affect the next request. This is additional hardening that will help prevent similar thread safety bugs from turning into security vulnerabilities for other users of Unicorn. We want to sincerely thank the Unicorn maintainers for the collaboration and discussion on this issue.
Another step that we are taking is to remove the callbacks for our exception logging context. These callbacks were useful to delay execution and to avoid paying the performance overhead when not needed. The downside is that the callback also makes debugging race conditions more difficult and could potentially retain references to requests long since finished. Handling exceptions with simpler code allows us to use these routines in a safer manner now and in the future. Additionally, we are working to simplify and limit the code paths where the session cookie is managed.
Lastly, we’re looking at also improving the thread safety across our codebase in areas such as exception handling and instrumentation. We don’t want to just fix this specific bug, we want to ensure that this class of issues can’t happen again in the future.
Wrapping up
Threaded code can be very hard to reason about and debug, especially in a codebase where threads have not been used extensively in the past. For now, we’ve stopped using long-running threads in our Rails processes. We’re taking this as an opportunity to make our code more robust for various threading contexts and to provide further protections and a thread-safe architecture to use in the future.
Taking a step back, a bug such as this is not only challenging from a technical perspective in how to identify complex interactions between multiple threads, deferred callbacks, and object sharing, but it is also a test of an organization’s ability to respond to a problem with an ambiguous cause and risk. A well-developed product security incident response team and process combined with a collaborative team of subject matter experts across our support, security, and engineering teams enabled us to quickly triage, validate, and assess the potential risk of this issue and drive prioritization across the company. This prioritization accelerated our efforts in log analysis, review of recent changes across our code and infrastructure, and ultimately the identification of the underlying issues that led to the bug.
With a clear understanding of the problem, we could then focus on shipping the correct mitigations to limit the impact to our customers. The knowledge we gained through this process allowed us to work with stakeholders across the company to confidently make the decision of logging all users out of GitHub.com. We have gained a better understanding of our “complex systems” and we will continue to use this as an opportunity to build in safeguards to prevent issues like this from happening again.
Written by

Related posts

How to catch GitHub Actions workflow injections before attackers do
Strengthen your repositories against actions workflow injections — one of the most common vulnerabilities.
Modeling CORS frameworks with CodeQL to find security vulnerabilities
Discover how to increase the coverage of your CodeQL CORS security by modeling developer headers and frameworks.

CVE-2025-53367: An exploitable out-of-bounds write in DjVuLibre
DjVuLibre has a vulnerability that could enable an attacker to gain code execution on a Linux Desktop system when the user tries to open a crafted document.