Extending GitOps to reliability-as-code with GitHub and StackPulse
This is a partner post by Leonid Belkind, the Co-Founder and CTO at StackPulse Over the past decade, engineering-led practices have replaced traditional IT operations across the software development lifecycle.…

This is a partner post by Leonid Belkind, the Co-Founder and CTO at StackPulse
Over the past decade, engineering-led practices have replaced traditional IT operations across the software development lifecycle. This has allowed developers to build, test and deploy software services faster than ever before possible. Consider the following examples:
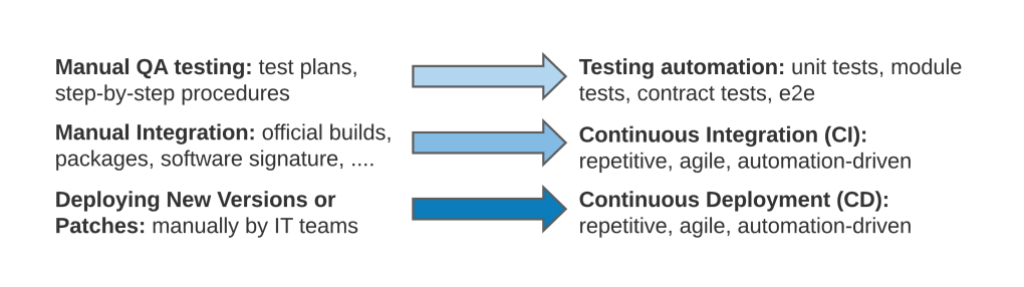
In each instance, a mostly manual process has been replaced with automation, removing bottlenecks and increasing deployment velocity. But when it comes to ensuring the reliability of software services in production, the process is still predominantly manual. Even in the most advanced technological organizations, when a production monitoring system produces an alert, what follows is mostly manual process of going through the following steps:
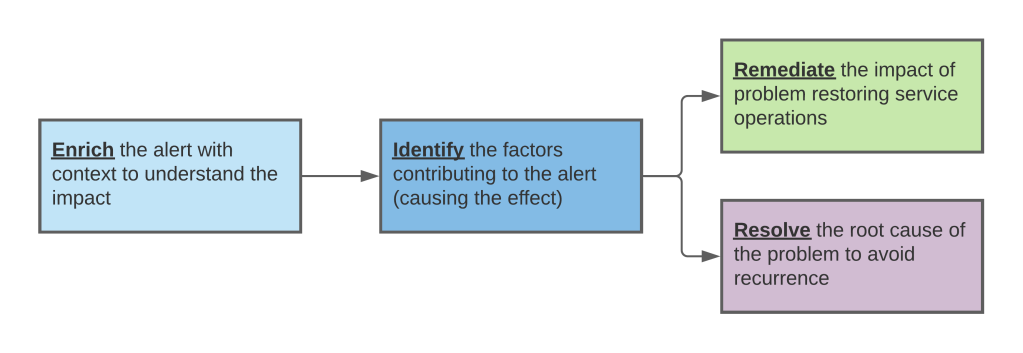
Additionally, throughout the above steps, there is always a matter of communicating the current state and the planned steps/time-lines to relevant stakeholders, inviting additional stakeholders to participate in the process, and so on.
Turning operations into code
StackPulse is a platform that allows defining the above processes and steps as code—to an extent similar to defining testing or deployment procedures as one. The code, leveraging software engineering best practices, can be modular, generic, with clear interfaces between modules, allowing its developers to model operational processes the same way they would do it with business logic. It allows the operational process to be subjected to versioning, testing and review cycles, ensuring that it “delivers on its promise” when being executed in production.
Let’s take a concrete example for an operational process—every time we receive an alert on a database server being slower than usual to respond to requests, we would start handling it by taking the following actions:
- Understand which database server is responsible for originating the alert.
- Check if all database requests are equally slow or only specific ones and group them by source, data type, operation, etc.
- Check if the services impacted by the database slowness are failing to deliver their responses according to their expectations and which business processes are impacted by it.
Similarly, we could define the following steps of remediating and resolving various issues and creating well-defined processes both for generic remediations and for handling very specific situations.
We could also approach describing the above mentioned steps as a process defined similarly to the below:
apiVersion: stackpulse.io/v1
kind: Playbook
metadata:
name: enrich-and-diagnose-database-alerts
description: This playbook enriches alerts related to database services and tries to identify most common sources of possible problems
parameters:
- name: database_server
type: var
description: Address of the database server
steps:
# Retrieve general information about the database server
- name: stackpulse/general_db_info
id: get_db_info
env:
DATABASE: '{{ $.params.database_server }}'
AUTH: '{{ secret "database_access_key" }}'
# Get a breakdown of database requests latency for the past 30 minutes
- name: stackpulse/db_requests_latency_analysis
id: get_db_latency
env:
DATABASE: '{{ $.params.database_server }}'
AUTH: '{{ secret "database_access_key" }}'
TIME: "30m
* * *The above code is an expression of an operational process, consisting of well-defined steps each receiving arguments and performing a certain action. In this case, the actions are taken during the enrichment phase of the incident, but the principle is not limited in any way to this stage.
When building the platform that would allow expressing processes as code it was important for us to maintain some important basic principles:
- Building such processes as code should be very easy and should allow focusing on the logic of the process
- Expressing logical connections between various steps should be possible, in order to translate multi-step processes into as code equivalents
- The result should be portable between various environments to allow re-use
By turning the definition of our operational processes into a specialized version of software, we can now subject it to the same software development lifecycle principles already adopted by the organization to ensure high quality and efficient delivery.
Enabling SDLC for reliability
The moment our processes become another form of software code, leveraging an existing infrastructure that is in place for managing other forms of software can ensure that developing, maintaining and reviewing them becomes yet another pillar in software development.
For example, every GitHub repository containing business logic modules, in addition to containing the automated tests and deployment logic for these modules, can now add the representation of enrichment, diagnostics and remediation processes required to operationalize the relevant module.
These processes can rely on generic components provided as a shared infrastructure or be completely unique. Modifying these processes can be done in branches, where merging them into production will take a form of pull requests and subsequent GitHub Actions pipelines. Versioning of the processes can be clearly tracked via the repositories, requests for changes can be submitted via issues, and pace of changes can be seen via Insights. Just as with any other form of software code.
Some of these processes may remain private, whereas others, related to operationalizing common open source components or libraries can be shared with peers, with the help of public repositories, enabling collaboration and driving to operational excellence not only within a single organization, but across the whole industry.
To sum up, turning operational processes into code allows developers to leverage practices of agile development, continuous integration/deployment and GitOps to manage the processes ensuring reliability of their services—taking the next evolutionary step in the adoption of “You build it, you run it” principle and guaranteeing meeting SLOs.
- Sample processes can be found in the StackPulse public playbooks repository
- GitHub Action enabling GitOps flows can be found in the GitHub Actions Marketplace
- Get started with the free edition of StackPulse today
Tags:
Written by

Related posts
GitHub recognized as a Leader in the Gartner® Magic Quadrant™ for Enterprise AI Coding Agents for the third year in a row
We are committed to empowering every developer by building an open, secure, and AI-powered platform that defines the future of software development.
Improving token efficiency in GitHub Agentic Workflows
Agentic workflows that run on every pull request can quietly accumulate large API bills. Here’s how we instrumented our own production workflows, found the inefficiencies, and built agents to fix them.
Automate repository tasks with GitHub Agentic Workflows
Discover GitHub Agentic Workflows, now in technical preview. Build automations using coding agents in GitHub Actions to handle triage, documentation, code quality, and more.