Reducing flaky builds by 18x
Part of the Building GitHub blog series. It’s four o’clock in the afternoon as you push the last tweak to your branch. Your teammate already reviewed and approved your pull request…

Part of the Building GitHub blog series.
It’s four o’clock in the afternoon as you push the last tweak to your branch. Your teammate already reviewed and approved your pull request and now all that’s left is to wait for CI. But, fifteen minutes later, your commit goes red. Surprised and a bit annoyed because the last five commits were green, you take a closer look only to find a failing test unrelated to your changes. When you run the test locally, it passes.
Half an hour later, after running the test again and again locally without a single failure and retrying a still-red CI, you’re no closer to deploying your code. As the clock ticks past five, you retry CI once more. But this time, something is different: it’s green!
You deploy, merge your pull request, and, an hour later than expected, close your laptop for the day.
This is the cost of a flaky test. They’re puzzling, frustrating, and waste your time. And try as we might to stop them, they’re about as common as a developer who brews pour-over coffee every morning (read: very).
Bonus points if you can guess what caused the test to fail.
How far we’ve come
Earlier this year in our monolith, 1 in 11 commits had at least one red build caused by a flaky test, or about 9 percent of commits. If you were trying to deploy something with a handful of commits, there was a good chance you’d need to retry the build or spend time diagnosing a failure, even if your code was fine. This slowed us down.
Six weeks ago, after introducing a system to manage flaky tests, the percentage of commits with flaky builds dropped to less than half a percent, or 1 in 200 commits.
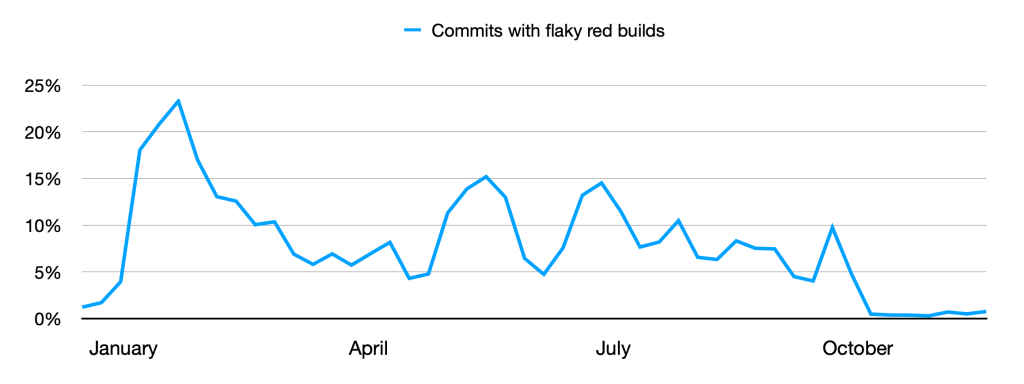
This is an 18x improvement and the lowest rate of flaky builds since we began tracking flaky tests in 2016.
So, how does it work?

Say you just merged a test that would fail once every 1,000 builds. It didn’t fail during development or review but a few hours later, the test fails on your teammate’s branch.
When this failure occurs, the new system inspects it and finds it to be flaky. After ensuring the test passes when run against the same code, it keeps the build green. And it happens quickly: unless your teammate is watching closely, they won’t notice.
But your flaky test is still out there, failing on other branches. Every time it does, the system keeps track of where it happened and how it failed, each time learning more about the failure. If it continues to affect developers, the system identifies it as high impact: it’s time for a human to investigate. Using test failure history and git blame, the system finds the commit most likely to have introduced the problem—your commit—and assigns an issue to you.
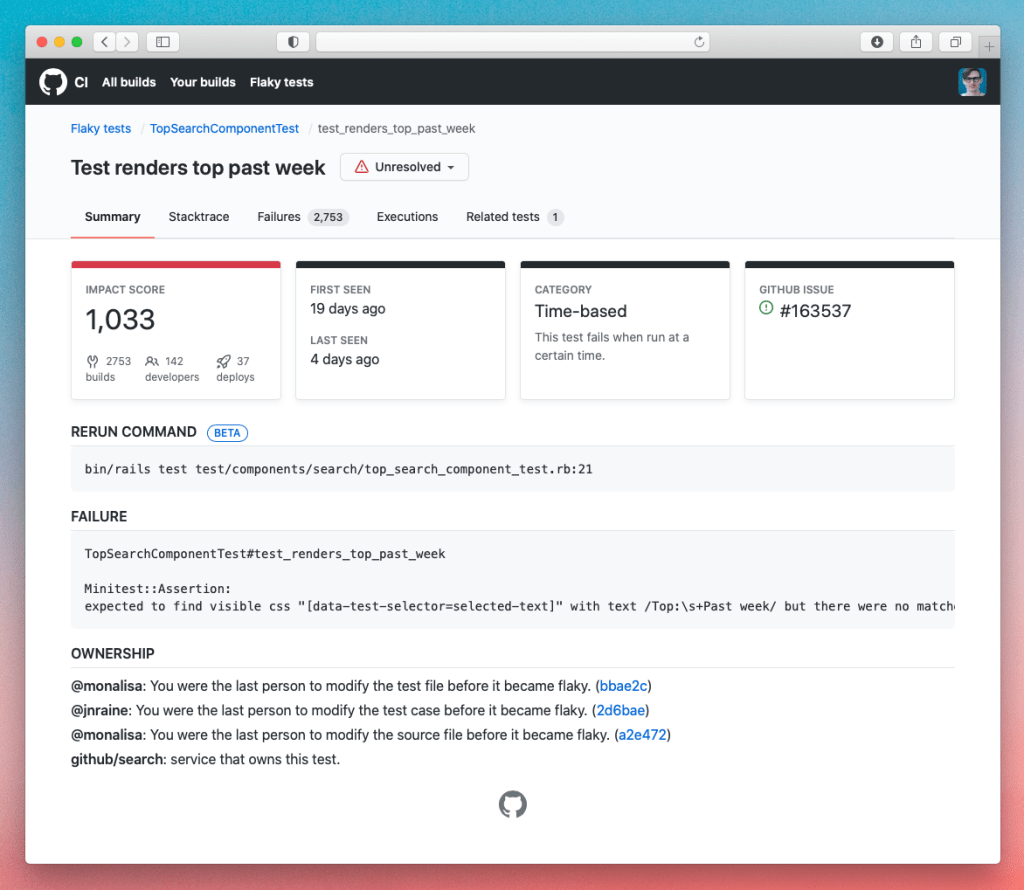
Screenshot of GitHub’s internal CI tooling.
From there, you can see information about the failure, including what may have caused it, where it failed, and who else might be responsible. After some poking around, you find the problem and merge a fix.
The system noticed a problem, contained it, and delegated it the right person. In short, the only person bothered by a flaky test is the person who wrote it.
# This ain't a blocker
def test_fails_one_in_a_thousand
assert rand(1000).zero?
end
How it works
When we set out to build this new system, our intent wasn’t to fix every flaky test or to stop developers from introducing new flaky tests. Such goals, if not impossible, seemed impractical. Similar to telling a developer to never write another bug, it would be much more costly and only slightly less flaky. Rather, we set out to manage the inevitability of flaky tests.
Focusing on what matters
When inspecting the history of failures in our monolith, we found that about a quarter of our tests had failed flaky across three or more branches in the past two years. But as we filtered by occurence, we learned that the flakiness was not evenly distributed: most flaky test failed fewer than ten times and only 0.4 percent of flaky tests failed 100 times or more.
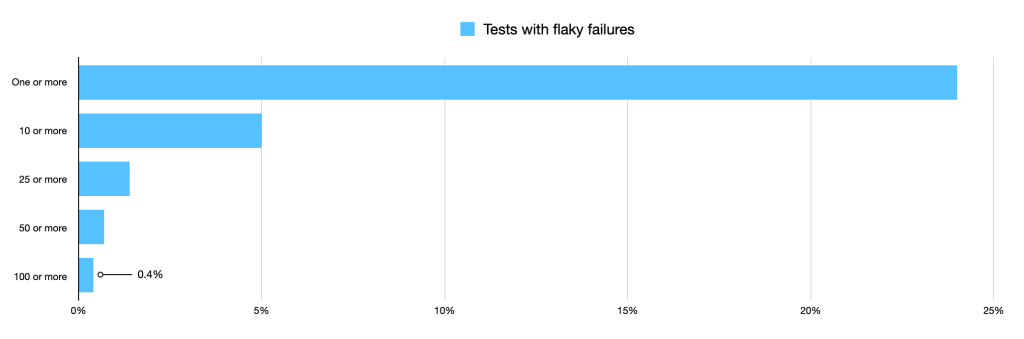
This made one thing clear: not every flaky failure should be investigated.
Instead, by focusing on this top 0.4 percent, we could make the most of our time. So which tests were in this group?
Automating flake detection
We define a “flaky” test result as a test that exhibits both a passing and a failing result with the same code. –John Micco, Google
Since 2016, our CI has been able to detect whether a test failure is flaky using two complementary approaches:
- Same code, different results. Once a build finishes, CI checks for other builds run against the same code using the root git tree hash. If another build had different results—for example, a test failed on the first build but passed on the second—the test failure was marked as flaky. While this approach was accurate, it only worked if a build was retried.
- Retry tests that fail. When a test failed, it was retried again later within the same build. This could be used on every build at minimal cost. If the test passed when rerun, it was marked as flaky. However, certain types of flaky tests couldn’t be detected with this approach, such as a time-based flaky test. (If your test failed because it was a leap year, rerunning it two minutes later won’t help.)
Unfortunately, these approaches were only able to identify 25 percent of the flaky failures, counting on developers to find the rest. Before delegating flaky test detection to CI, we needed an approach that was as good or better than a person.
Making it better
We decided to iterate on the test retry approach by rerunning the test three times, each in a scenario targeting a common cause of flakiness.
- Retry in the same process. This retry attempts to replicate the same conditions in which the test failed: same Ruby VM, same database, same host. If the test passes under the same conditions, it is likely caused by randomness in the code or a race condition.
- Retry in the same process, shifted into the future. This retry attempts to replicate the same conditions with one exception: time. If the test passes when run in the future, as simulated by test helpers, it is likely caused by an incorrect assumption about time (e.g., “there are 28 days in February”).
- Retry on a different host. This attempts to run the same code in a completely separate environment: different Ruby VM, different database, different host. If the test passes under these conditions but fails in the other two retries, it is likely caused by test order-dependence or some other shared state.
Using this approach, we are able to automatically identify 90 percent of flaky failures.
Further, because we kept a history of how a test would fail, we were also able to estimate the cause of flakiness: chance, time-based, or order-dependent. When it came time to fix a test, this gave the developer a headstart.
Measuring impact
Once we could accurately detect flaky failures, we needed a way to quantify impact to automate prioritization.
To do this, we used information tracked with every test failure: build, branch, author, commit, and more. Using this information, a flaky test is given an impact score based on how many times it has failed as well as how many branches, developers, and deploys were affected by it. The higher the score, the more important the flaky test.
Once the score exceeds a certain threshold, an issue is automatically opened and assigned to the people who most recently modified either the test files or associated code prior to the test becoming flaky. To help jog the memory of those assigned, a link to the commit that may have introduced the problem is added to the issue.
Teams can also view flaky tests by impact, CODEOWNER, or suite, giving insight into the test suite and giving developers a TODO list for problem areas.
Closing
By reducing the number of flaky builds by 18x, the new system makes CI more trustworthy and red builds more meaningful. If your pull request has a failure, it’s a sign you need to change something, not a sign you should hit Rebuild. When it comes time to deploy, you can be sure that your build won’t go red late in the day because a test doesn’t take into account daylight saving time.
This keeps us moving, even when we make mistakes.
Written by

Related posts
Continuous AI for accessibility: How GitHub transforms feedback into inclusion
AI automates triage for accessibility feedback, allowing us to focus on fixing barriers—turning a chaotic backlog into continuous, rapid resolutions.
How we rebuilt the search architecture for high availability in GitHub Enterprise Server
Here’s how we made the search experience better, faster, and more resilient for GHES customers.
From pixels to characters: The engineering behind GitHub Copilot CLI’s animated ASCII banner
Learn how GitHub built an accessible, multi-terminal-safe ASCII animation for the Copilot CLI using custom tooling, ANSI color roles, and advanced terminal engineering.