Integrating Git in Atom
Perform common Git operations without leaving the editor: stage changes, make commits, create and switch branches, resolve merge conflicts, and more.
The Atom team has been working to bring the power of Git and GitHub as close to your cursor as possible. With today’s release of the GitHub package for Atom, you can now perform common Git operations without leaving the editor: stage changes, make commits, create and switch branches, resolve merge conflicts, and more.
In this post, we’ll look at the evolution of how the Atom GitHub package interacts with the .git folder in your project.
Interacting with Git
GitHub is a core contributor to a library called libgit2, which is a reentrant C implementation of Git’s core methods and is used to power the backend of GitHub.com via Ruby bindings. Our initial approach to the development of this new Atom package used Nodegit, a Node module that provides native bindings to libgit2.
Months into development we started to question whether this was the optimal approach for our Atom integration. libgit2 is a powerful library that implements the core data structures and algorithms of the Git version control system, but it intentionally implements only a subset of the system. While it is very effective as a technology that powers the backend of GitHub.com, our use case is sufficiently different and more akin to the Git command-line experience.
Compare what we had to do with Nodegit/libgit2 versus shelling out:
Nodegit/libgit2
- Read the current index file
- Update the files that have changed
- Create a tree with this state
- Write the updated index back to disk
- Manually run pre-commit hooks
- Create the new commit with the tree
- Manually sign the commit if necessary
- Update the currently active branch to point to the commit
- Manually run post-commit hook
Shelling out
- Run
git commit, the command-line tool made for our exact use case
Shelling out to Git simplifies development, gives us access to the full set of commands, options, and formatting that Git core provides, and enables us to use all of the latest Git features without having to reimplement custom logic or wait for support in libgit2. For these reasons and more, we made the switch.
Reboot to shelling out
We bundled a minimal version of Git for Mac, Windows, and Linux into a package called dugite-native and created a lightweight library called dugite for making Node execFile calls. Bundling Git makes package installation easier for the user and gives us full control over the Git API we are interacting with.
As much as possible, we keep your Git data in Atom in sync with the actual state of your local repo to allow for maximal flexibility. You can partially stage a file in Atom, switch to the command line and find the state of your repo exactly as you’d expect. Additionally, any changes you make outside of Atom will be detected by a file watcher and the Git data in your editor will be refreshed automatically.
Overall, the transition from Nodegit to shelling out went pretty well. However, there were noticeable performance tradeoffs and overhead costs associated with spawning a new process every time we asked for Git data.
Performance concerns and optimizations
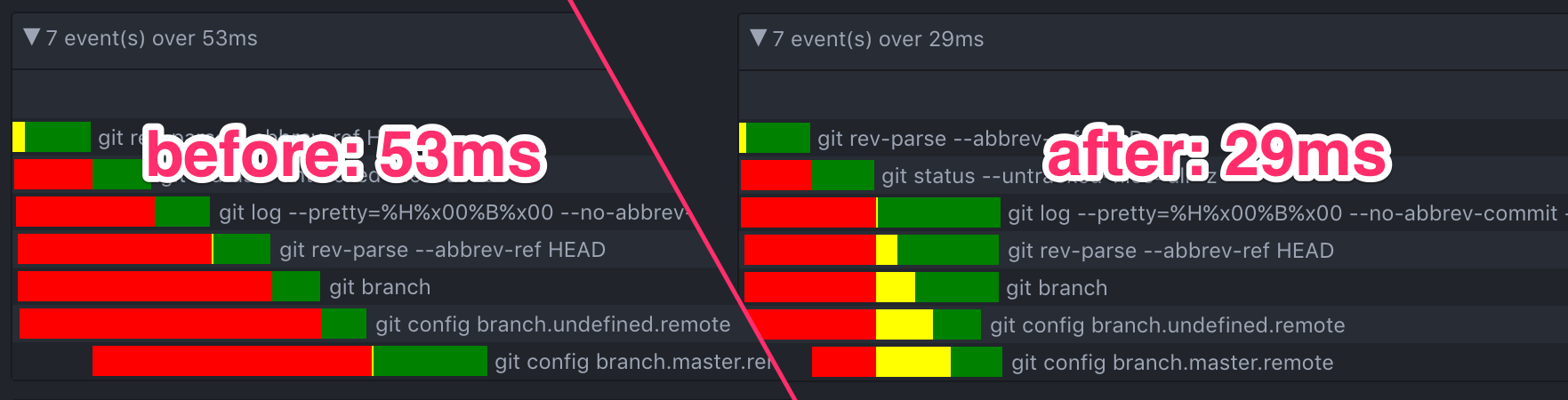
Recent Atom releases have delivered numerous performance improvements, and we wanted this new package to demonstrate our continued focus on responsiveness. After core functionality was in place, we introduced a series of optimizations. To inform and measure progress on this front, we created a custom waterfall view to visualize the time spent shelling out to Git; the red section shows the time an operation spent waiting in the queue for its turn to run, while the yellow and green represent the time the operation took to actually execute.
Here’s what it looked like before and after we parallelized read operations based on the number of cores on a user’s computer:
We also noticed that for larger repos we would get file-watching update events in several batches, each causing a model update to be scheduled. A merge with conflicts in github/github, the GitHub.com codebase, would queue up 12 updates. To address this we redesigned our ModelObserver to never schedule more than a single pending fetch if new update requests come in while a fetch is in progress, preventing ModelObserver update backlogs.

Aggressive caching and selectively invalidating cached repository state reduced the number of times we shell out to Git so that we avoid the performance penalty of launching a new process:
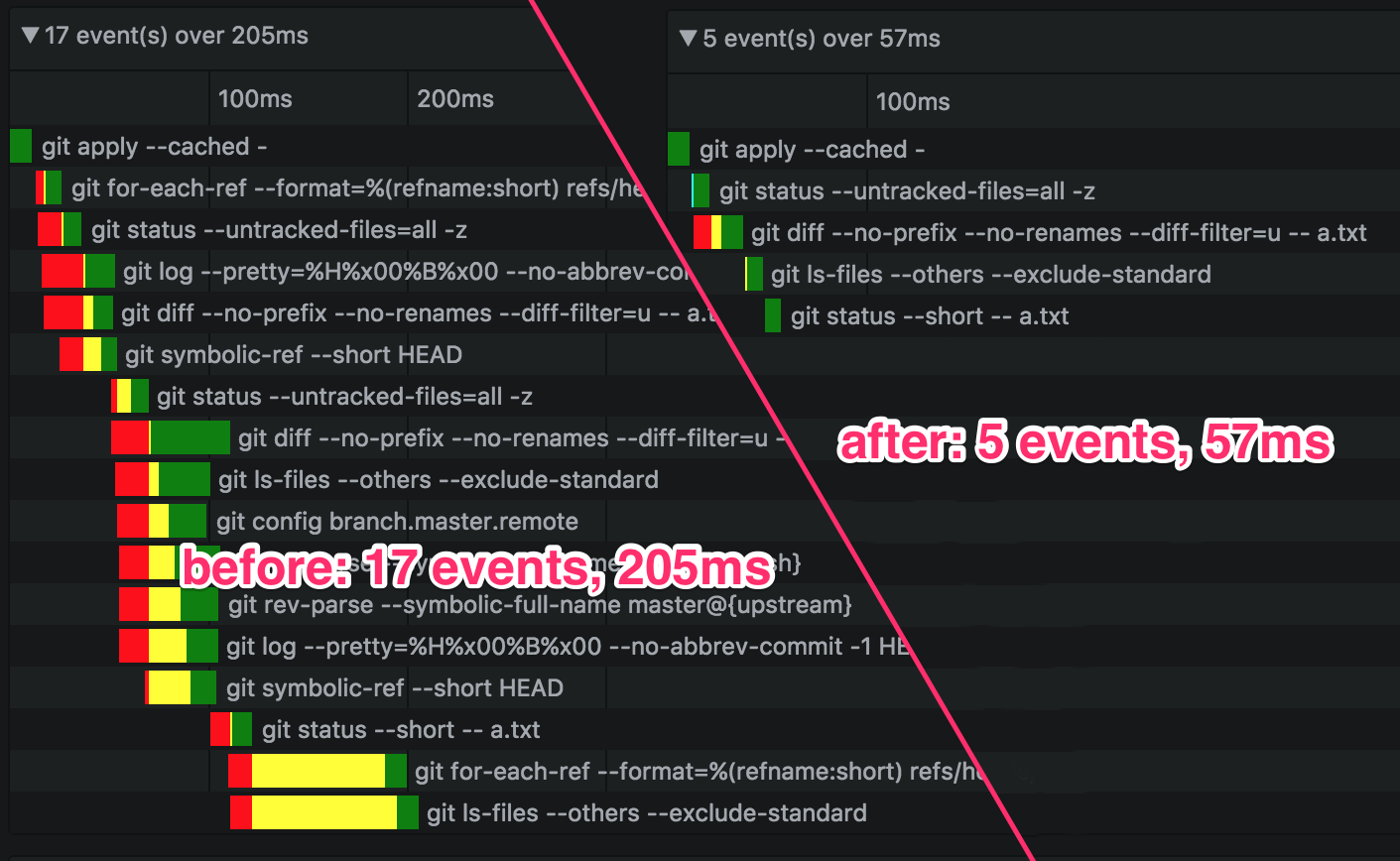
Even though we spawn subprocesses asynchronously, there is still a small synchronous overhead to shelling out to Git. Normally, this is no more than a couple milliseconds. On rare occasions, however, the application would get into a strange state, and this time would begin to grow; this overhead is represented in the waterfall views above by the yellow sections. The additional time spent in synchronous code would block the UI thread long enough to degrade the user experience. The issue would persist until the Atom window was refreshed.

After investigating the root cause of this issue, we realized that a proper fix for it would have involved changing Node or libuv. Since our launch date was looming on the horizon, we needed a more immediate solution and made the decision to work around the problem by making Git calls in a separate process. This would keep the main thread free and prevent locking the UI when this issue arises.
Shelling out in a dedicated side process
Our first approach used forked Node processes, but benchmarking revealed that IPC time grows quadratically relative to message size, which could become an issue when reading large diffs from stdout. This issue seems to be fixed in future versions of Node, but again, time was of the essence and we couldn’t afford to wait. Thankfully, IPC times using Electron renderer processes were much more reasonable, so our short term solution involved using a dedicated renderer process to run Git commands.
We introduced a WorkerManager which creates a Worker that wraps a RendererProcess which shells out to Git and sends results back over IPC. If the renderer process is not yet ready, we fall back to shelling out in process. We track a running average of the time it takes to make a spawn call and if this exceeds a specified threshold, the WorkerManager creates a new Worker and routes all new Git data requests to it. With this approach, if the long spawn call issue manifests, users will experience no freezing due to a blocked main thread. At worst, they may experience slower UI updates, but once a new renderer process is up the spawn times should drop back down and normal responsiveness should be restored.
As with most decisions, there are tradeoffs. Here we prevent indefinite locking of the UI, but there is now extra time spent in IPC and overhead costs associated with creating new Electron renderer processes. In the timeline below, the pink represents the IPC time associated with each Git command.

Once we upgrade Atom to Electron v1.6.x in the next release cycle, we’ll be able to re-implement this system using Chromium Web Workers with Node integration. Using the SharedArrayBuffer object, we can read shared memory and bypass IPC, cutting down overall operation time. And using native Web Workers rather than Electron Renderer Processes will reduce the overhead associated with these side processes and save on computing resources for shelling out to Git.
Continuing the vision for Atom
In addition to more performance improvements, you can look forward to more Git features, UI/UX improvements, and more comprehensive and in-depth GitHub integration.
As developers, much of our work is powered by a few key tools that enable us to write software and collaborate. We spend most of our days in our editors, periodically pausing to take version control snapshots of our code, and soliciting input and feedback from our colleagues. It’s every developer’s dream to be able to do all of these things with minimal friction and maximal ease. With these new integrations the Atom team is working to make those dreams more of a reality.
Want to help the Atom team make developers’ lives easier? We’d love for you to join us. Keep an eye out for a job posting coming soon!
Authors



Written by

Related posts
6 security settings every GitHub maintainer should enable this week
These six free settings will not make your project unhackable. Nothing will. What they will do is close the easy doors. Turn these on, and your project will be meaningfully harder to attack than it was before.
How GitHub maintains compliance for open source dependencies
Explore how the Open Source Program Office uses GitHub’s new license compliance product to manage open source dependencies at scale.

Highlights from Git 2.55
The open source Git project just released Git 2.55. Here is GitHub’s look at some of the most interesting features and changes introduced since last time.