Invest in tools students can grow with: GitHub and RStudio for data science at Duke University
Data science is a melting pot of disciplines: students from Anthropology to Political Science to Education all sign up for the same course. It’s a challenge to keep the material…

Data science is a melting pot of disciplines: students from Anthropology to Political Science to Education all sign up for the same course. It’s a challenge to keep the material engaging for everyone.
At the same time, teachers want the next generation of data scientists to be able to analyze any dataset they come across in the future with the same level of rigor used in the classroom. That outcome requires a consistent level of training, across diverse datasets.
Mine Çetinkaya-Rundel, Director of Undergraduate Studies and an Associate Professor at Duke University, tackles these problems head-on. She quite literally wrote the book on the subject, and her open, online course Master Statistics with R certifies thousands of students a year. She edits the Citizen Statistician blog and offers the annual Duke DataFest, a hackathon for working with data.
Her data science course emphasizes “reproducible computation”, a documented process of how data is treated in order to replicate the results in the future. She meets that learning goal using R Markdown and R Studio, as well as by requiring students to incrementally commit their changes using Git and GitHub.
Students learn the concept and the real-world tool, at the same time
Some instructional products have a high learning curve in-and-of themselves. Çetinkaya-Rundel would rather students learn a language in the discipline that they can later build upon:
They learn a limited bit of R syntax that allows them to analyze and visualize data in R. While the goal of the course is not to make each student a proficient R programmer, they learn enough R to be able to build on in their second or third classes. Teaching software designed to be used only in an introductory class would not have this benefit.

Editing an R Markdown file in RStudio by Chester Ismay, MIT License
She wants her students to ship their first visualization project quickly and get started “like a knife through butter” without errors. To bootstrap their efforts quickly, she has them access RStudio Pro using her department’s server.
Best practices for scaffolding collaboration
Sta112FS introduces Git on day one to help students learn about version control gradually and in increments. Her GitHub structure is one organization for the course, one repository per team, and one per assignment. She recommends starting out with an individual assignment first, so students can get used to Git’s mental model before adding the complexity of collaboration.
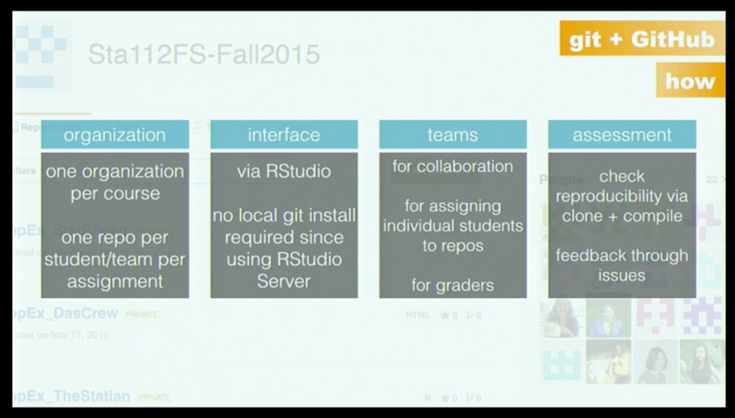

Mine has students access their projects through RStudio, which she integrates with Git. These slides are from her talk, A first-year undergraduate data science course.
On group projects, Mine creates one repository per team, and everyone on the team can push. Knowing that students will encounter merge conflicts when they’re working asynchronously, she provokes the error messages early on in the semester.
In the first exercise, students clone a demo repository and are asked to edit the README in two tools, first on GitHub and then again in the RStudio editor. The conflicting changes throw an error, which she teaches students to resolve calmly, and by reading the messages.
I show them how I would resolve [the conflict], and then they do the same thing… I tried to create a situation in the classroom that could be frustrating for them later, and say, “This is about to happen. It’s important to read the message that it sends you, and this is how you would resolve it.”
The setup pays off in engagement and curiosity
For Mine’s course, using a computation tool prompts students to engage with data directly—an important pedagogical choice to make their analysis both personal and real. There’s a freedom in exploring and tinkering with the real-world tool that professionals use.
Using a computational tool means that you can give the dataset to the students, and they can play around with it. They might be playing around with it in a way that you have designed the assignment or the assessment, but still it gives them the flexibility to look at another variable, make a different plot, than what was assigned for them to do.
Git and GitHub expertise after students leave the classroom
While she keeps student repositories private, merely using GitHub gives her students an edge later in their careers. They can also choose to make their repositories public after they are done with the course.
A lot of students have said to me later, even first-year undergraduates, that using GitHub has helped them a lot when they went for an internship or a research position interview.
They are able to say, “Oh, I already have worked with GitHub. I’m familiar with it. I know how it works.” So I think they are at least able to put that on their CVs and go into a situation where there’s a research or data analysis team and say, “Yeah, sure. I am actually familiar with the same tools that you use.”
Creating RStudio projects from GitHub repositories
To see an example of Git and RStudio in action, check out this tutorial from Dr. Nicholas Reich at UMASS-Amherst:
This is a post in our “Teacher Spotlight” series, where we share the different ways teachers use GitHub in their classrooms. Check out the other posts:
- GitHub Issues and user testing as authentic assessment at the University of Victoria featuring Alexey Zagalsky
- GitHub Classroom for AP Computer Science at Naperville North High School, featuring Geoff Schmit
- Real-time feedback for students using continuous integration tools, featuring Omar Shaikh
- How CS50 at Harvard uses GitHub to teach computer science, featuring David Malan
Join this week’s discussion in the community forum: What are your favorite Statistics/R/ GitHub Resources?
Written by

Related posts
Transitioning as a Hubber
How GitHub’s culture and benefits helped me be the best version of myself.

I automated my job (and it made me a better leader)
Explore how my day as a senior leader looks now that I use 40 automations to help, and learn more about some of my favorites.

GitHub for Beginners: Answers to some common questions
Find the answers to some of the most common GitHub-related questions.