GLB part 2: HAProxy zero-downtime, zero-delay reloads with multibinder
As part of the design of GLB, we set out to solve a few of the common issues found when using HAProxy at scale.
Recently we introduced GLB, the GitHub Load Balancer that powers GitHub.com. The GLB proxy tier, which handles TCP connection and TLS termination is powered by HAProxy, a reliable and high performance TCP and HTTP proxy daemon. As part of the design of GLB, we set out to solve a few of the common issues found when using HAProxy at scale.
Prior to GLB, each host ran a single monolithic instance of HAProxy for all our public services, with frontends for each external IP set, and backends for each backing service. With the number of services we run, this became unwieldy, our configuration was over one thousand lines long with many interdependent ACLs and no modularization. Migrating to GLB we decided to split the configuration per-service and support running multiple isolated load balancer instances on a single machine. Additionally, we wanted to be able to update a single HAProxy configuration easily without any downtime, additional latency on connections or disrupting any other HAProxy instance on the host. Today we are releasing our solution to this problem, multibinder.
HAProxy almost-safe reloads
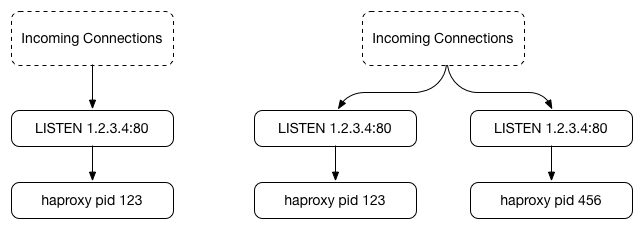
HAProxy uses the SO_REUSEPORT socket option, which allows multiple processes to create LISTEN sockets on the same IP/port combination. The Linux kernel then balances new connections between all available LISTEN sockets. In this diagram, we see the initial stage of an HAProxy reload starting with a single process (left) and then causing a second process to start (right) which binds to the same IP and port, but with a different socket:
This works great so far, until the original process terminates. HAProxy sends a signal to the original process stating that the new process is now accept()ing and handling connections (left), which causes it to stop accepting new connections and close its own socket before eventually exiting once all connections complete (right):
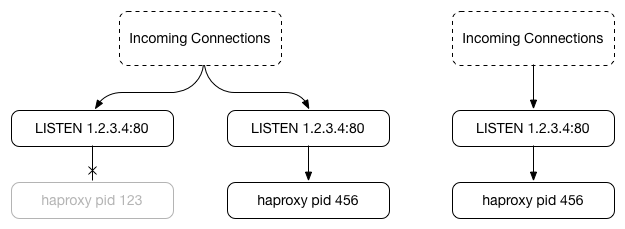
Unfortunately there’s a small period between when this process last calls accept() and when it calls close() where the kernel will still route some new connections to the original socket. The code then blindly continues to close the socket, and all connections that were queued up in that LISTEN socket get discarded (because accept() is never called for them):

For small scale sites, the chance of a new connection arriving in the few microseconds between these calls is very low. Unfortunately at the scale we run HAProxy, a customer impacting number of connections would hit this issue each and every time we reload HAProxy. Previously we used the official solution offered by HAProxy, dropping SYN packets during this small window, causing the client to retry the SYN packet shortly afterwards. Other potential solutions to the same problem include using tc qdisc to stall the SYN packets as they come in, and then un-stall the queue once the reload is complete. During development of GLB, we weren’t satisfied with either solution and sought out one without any queue delays and sharing of the same LISTEN socket.
Supporting zero-downtime, zero-delay reloads
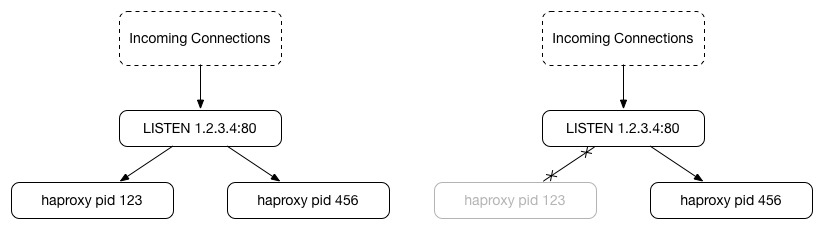
The way other services typically support zero-downtime reloads is to share a LISTEN socket, usually by having a parent process that holds the socket open and fork()s the service when it needs to reload, leaving the socket open for the new process to consume. This creates a slightly different situation, where the kernel has a single LISTEN socket and clients are queued for accept() by either process. The file descriptors in each process may be different, but they will point to the same in-kernel socket structure.
In this scenario, a new process would be started that inherits the same LISTEN socket (left), and when the original pid stops calling accept(), connections remain queued for the new process to process because the kernel LISTEN socket and queue are shared (right):
Unfortunately, HAProxy doesn’t support this method directly. We considered patching HAProxy to add built-in support but found that the architecture of HAProxy favours process isolation and non-dynamic configuration, making it a non-trivial architectural change. Instead, we created multibinder to solve this problem generically for any daemon that needs zero-downtime reload capabilities, and integrated it with HAProxy by using a few tricks with existing HAProxy configuration directives to get the same result.
Multibinder is similar to other file-descriptor sharing services such as einhorn, except that it runs as an isolated service and process tree on the system, managed by your usual process manager. The actual service, in this case HAProxy, runs separately as another service, rather than as a child process. When HAProxy is started, a small wrapper script calls out to multibinder and requests the existing LISTEN socket to be sent using Ancillary Data over an UNIX Domain Socket. The flow looks something like the following:
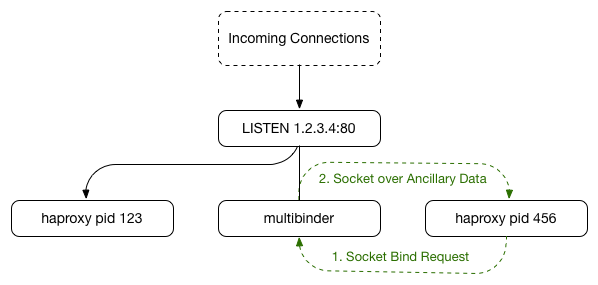
Once the socket is provided to the HAProxy wrapper, it leaves the LISTEN socket in the file descriptor table and writes out the HAProxy configuration file from an ERB template, injecting the file descriptors using file descriptor binds like fd@N (where N is the file descriptor received from multibinder), then calls exec() to launch HAProxy which uses the provided file descriptor rather than creating a new socket, thus inheriting the same LISTEN socket. From here, we get the ideal setup where the original HAProxy process can stop calling accept() and connections simply queue up for the new process to handle.
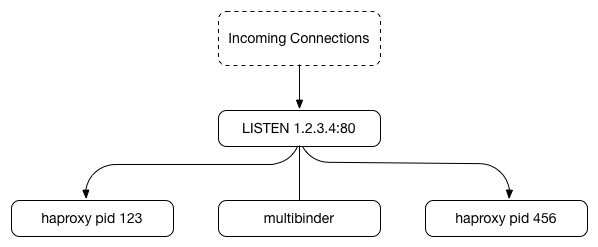
Example & multiple instances
Along with the release of multibinder, we’re also providing examples of running multiple HAProxy instances with multibinder leveraging systemd service templates. Following these instructions you can launch a set of HAProxy servers using separate configuration files, each using the same system-wide multibinder instance to request their binds and having true zero-downtime, zero-delay reloads.
Authors


Written by

Related posts

Still a developer. Just outside. Our latest GitHub Shop collection is here.
The ESC collection lets you escape the confines of your desk and get out into the sun where good ideas are bound to happen.
Take your local GitHub sessions anywhere
Kick off work in VS Code or the CLI, finish it from your phone. Remote control for GitHub Copilot sessions is now generally available on github.com and GitHub Mobile.

GitHub availability report: April 2026
In April, we experienced 10 incidents that resulted in degraded performance across GitHub services.